HyperAI
Command Palette
Search for a command to run...
MuseTalk 高品質リップシンクモデルデモ
日付
1年前
サイズ
2.41 GB
MuseTalk の機能は次のとおりです。
- リアルタイム: リアルタイム環境で実行でき、1 秒あたり 30 フレームを超える処理速度に達し、リップシンクの滑らかさを保証します。
- 高品質な同期:潜在空間修復手法により、顔の特徴を維持しながら、入力音声に合わせて口の形状を調整し、高品質なリップシンクを実現します。
- MuseV と連携: MuseTalk は、バーチャル ヒューマン ビデオを生成できるビデオ生成フレームワークである MuseV モデルで使用できます。
- オープンソース: MuseTalk のコードは、コミュニティへの貢献とさらなる開発を促進するためにオープンソースになっています。
MuseTalk はリップシンク生成に優れており、正確で一貫したリップシンクを生成でき、特に実写ビデオの生成に優れています。 EMO、AniPortrait、Vlogger、Microsoft の VASA-1 などの他の製品と比較した場合にも利点があります。
エフェクト例
モデルフレームワーク
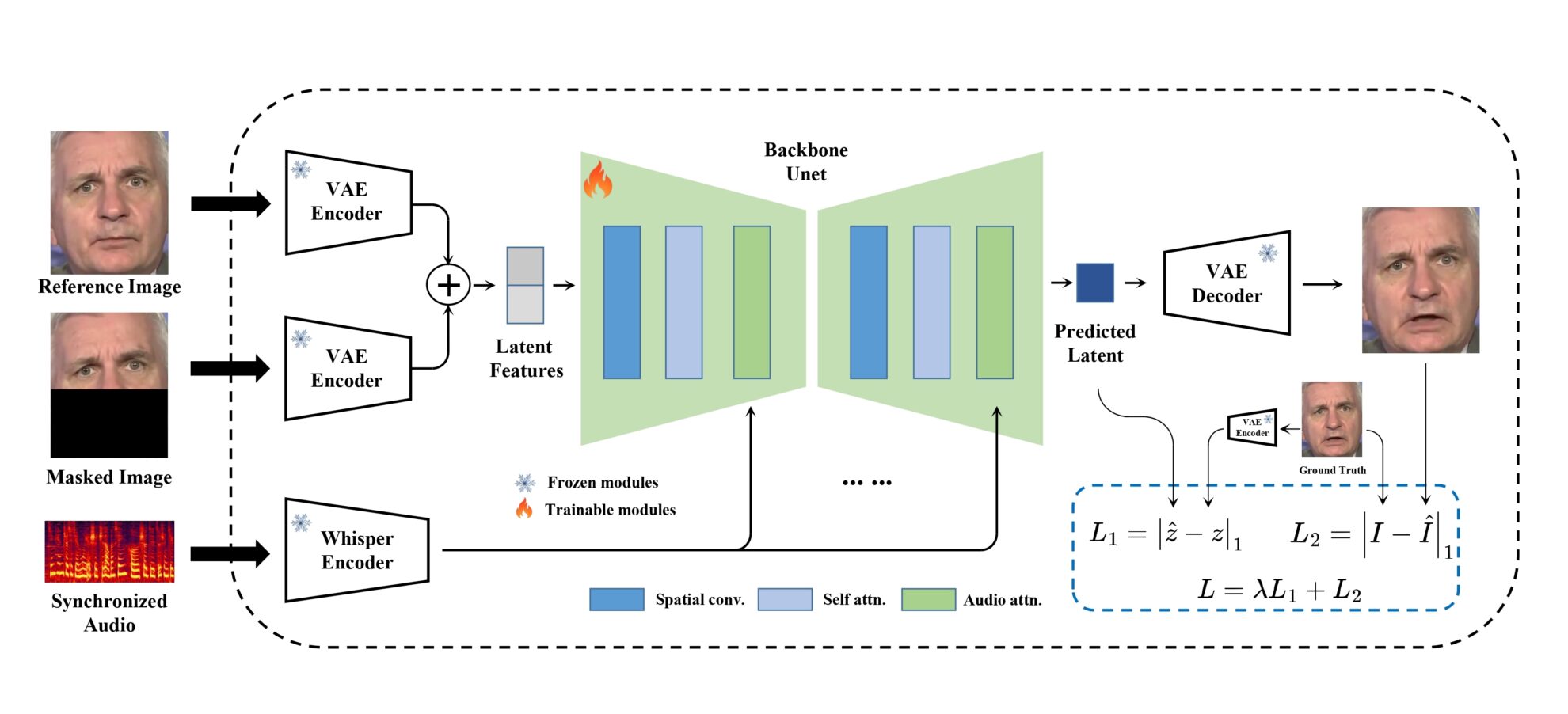
MuseTalk トレーニングは、フリーズされた VAE によって画像がエンコードされる潜在空間で実行されます。オーディオは、凍結されたささやき声の小さなモデルによってエンコードされます。生成ネットワークのアーキテクチャは、stable-diffusion-v1-4 の UNet から借用されており、クロスアテンションを通じてオーディオの埋め込みが画像の埋め込みと融合されます。
ステップの実行
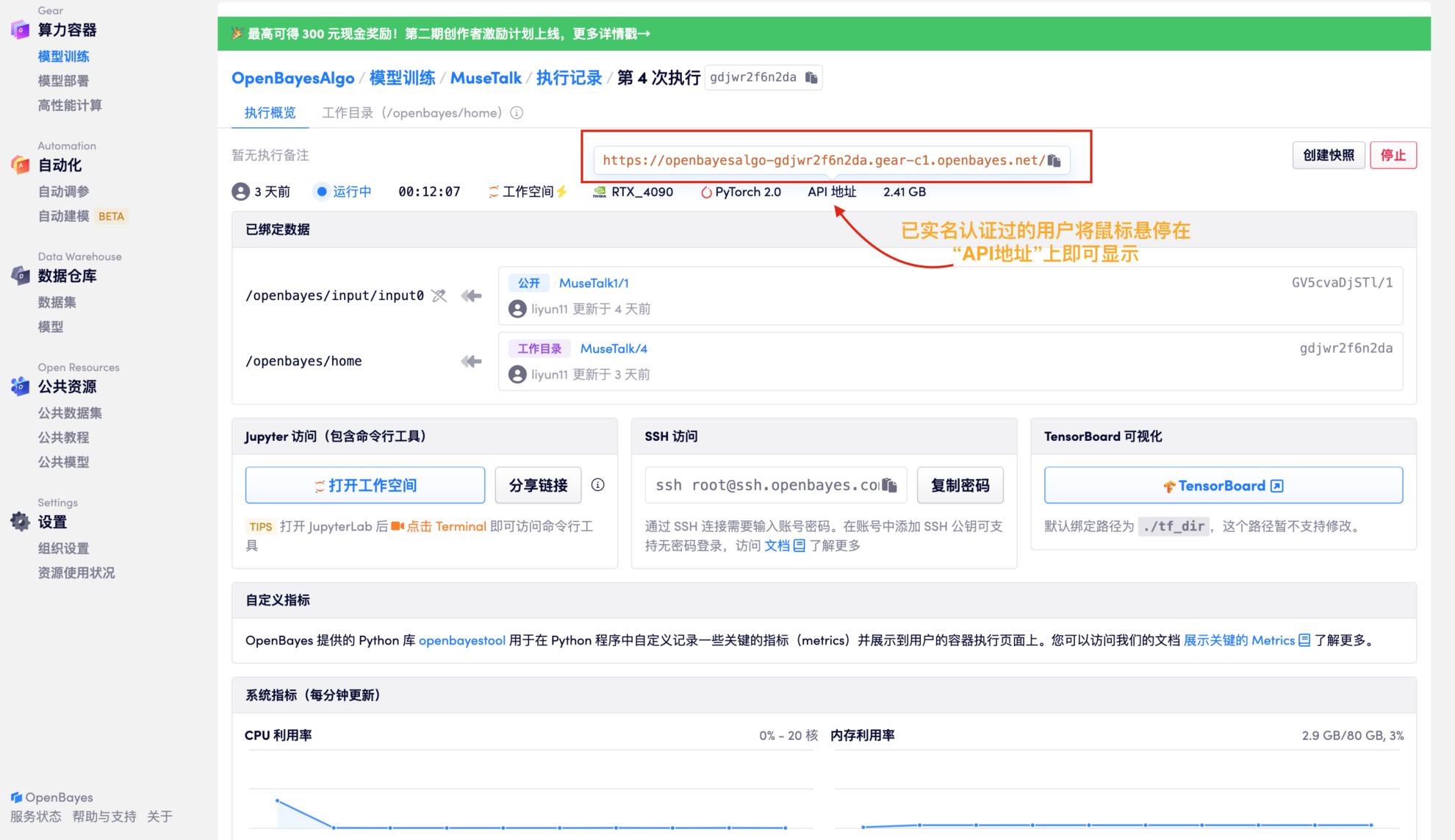
1. プロジェクトの右上隅にある「クローン」をクリックし、「次へ」をクリックして次の手順を完了します: 基本情報 > 計算能力の選択 > レビューおよびその他の手順。最後に、「続行」をクリックして、個人コンテナでプロジェクトを開きます。
2. リソースの割り当てが完了したら、API アドレスを直接コピーし、任意の URL に貼り付けます (実名認証が必要であり、この手順でワークスペースを開く必要はありません)。
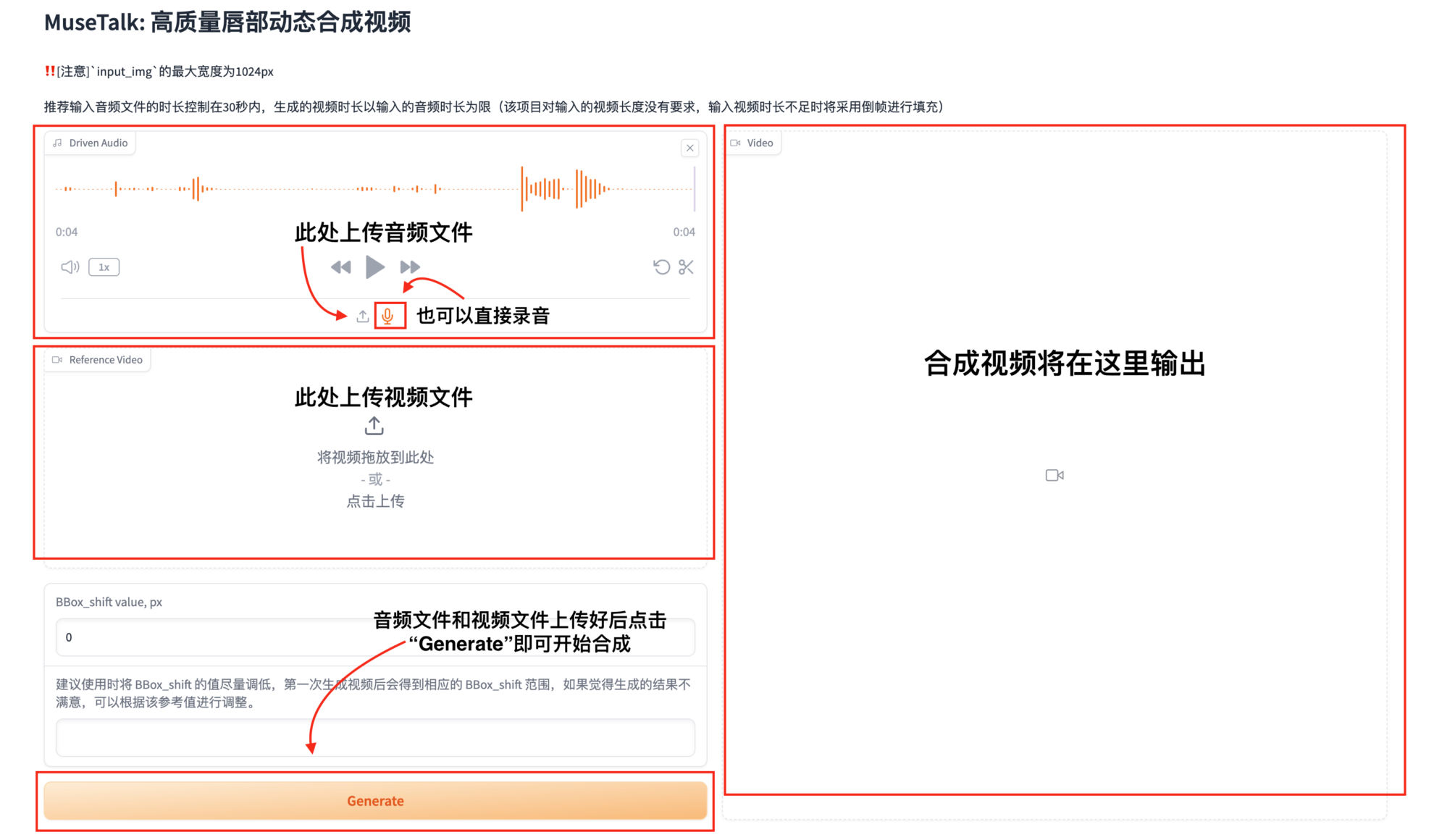
3. 合成用のオーディオ ファイルとビデオ ファイルをアップロードします
テスト済み: 17 秒の音声ファイルを生成するには約 3 分、約 1 分の音声ファイルを生成するには約 6 分かかります。
-|MuseTalk 顔と口の形状は入力音声に応じて変更でき、顔領域のサイズは 256 x 256 が望ましいです。同時に MuseTalk 顔領域の中心点の提案を変更することもサポートされており、生成された結果に大きな影響を与えます。
-|現在 MuseTalk 中国語、英語、日本語など多言語の音声入力に対応。
-|最終的に生成されるビデオの長さは、オーディオの長さの影響を受けるものとします。
このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。