Command Palette
Search for a command to run...
ギブス拡散を使用したブラインド画像ノイズ低減
ギブス拡散に基づくブラインド画像ノイズ除去

チュートリアルの紹介
GDiff(ギブス拡散法の略)は、信号とノイズパラメータの事後サンプリング問題に対処するベイジアンブラインドノイズ除去手法です。この手法は、事前学習済みの拡散モデル(信号の事前分布を定義する)を用いたサンプリングステップとハミルトンモンテカルロサンプラーを交互に用いるギブスサンプラーに基づいています。本論文では、自然画像のノイズ除去と宇宙論(宇宙マイクロ波背景放射解析)への応用について紹介します。本論文の結果は以下のとおりです。 ノイズを聞く: ギブス拡散によるブラインドノイズ除去
公式ドキュメントには、クリアなオリジナル画像を渡し、ノイズを重ね合わせて、非ブラインドノイズ除去とブラインドノイズ除去の比較を実行するというテスト方法のみが記載されています。
効果実証
公式エフェクトデモでは、鮮明なオリジナル画像を渡し、その上に特定のパラメーターのノイズを重ねて、ブラインドノイズ除去を実行します。
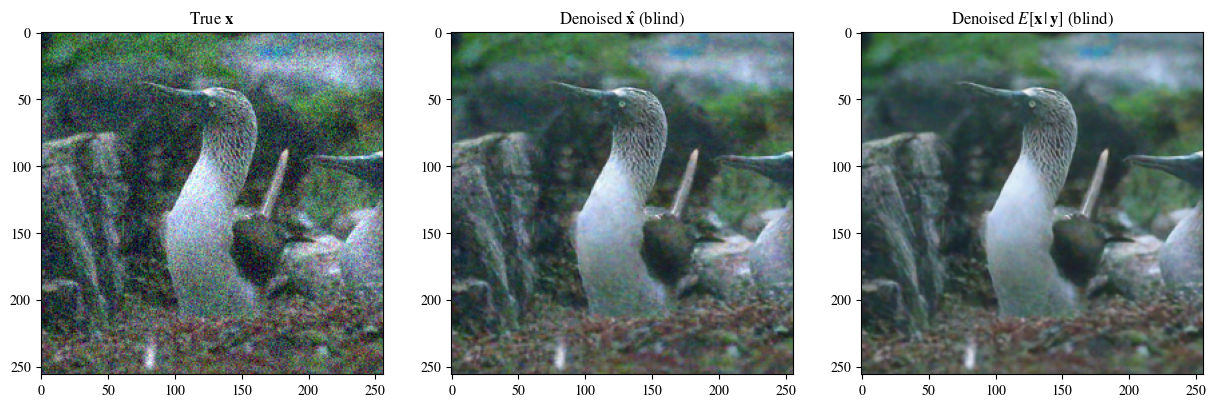
次の図は左から右に、ノイズを重ね合わせた後の画像、元の画像、ブラインドノイズ除去効果の画像、ノイズ除去の事後平均です。

ブラインドノイズ除去と非ブラインドノイズ除去の概要
ブラインドノイズ除去とノンブラインドノイズ除去は、画像処理および信号処理における 2 つのノイズ除去方法です。それらの主な違いは、ノイズ情報の予測の程度です。
ブラインドノイズ除去
定義: ブラインドノイズ除去とは、ノイズ特性やノイズモデルを知らずにノイズを除去することを指します。この方法は、ノイズに関する事前の知識に依存せず、画像または信号自体の情報を使用してノイズを除去します。
特徴:
- ノイズ モデルに依存しない: ノイズの種類、分布、強度を知る必要はありません。
- 強力な適応性: さまざまなタイプのノイズおよび信号環境に適用できます。
- 高い複雑さ: ノイズ モデルの助けがなければ、ブラインド ノイズ除去には通常、より複雑なアルゴリズムとより多くのコンピューティング リソースが必要になります。
非ブラインドノイズ除去
定義: 非ブラインドノイズ除去は、ノイズ特性またはノイズモデルがわかっている場合のノイズ除去を指します。この方法では、ノイズに関する事前の知識を利用してノイズ除去プロセスを最適化します。
特徴:
- ノイズモデルによる:ノイズの種類、分布、強度などの特性を事前に理解する必要があります。
- 効果の向上: ノイズ モデルがわかっている場合は、特定のノイズ タイプに合わせて最適化して、より優れたノイズ除去効果を得ることができます。
- 適用範囲の制限: ノイズの種類が異なれば、異なるモデルとパラメータが必要となり、適用範囲はブラインドノイズ除去よりも狭くなります。
チュートリアルの実行方法
このチュートリアルは 2 つの部分に分かれており、最初の部分は「ぼやけた画像のブラインドノイズ除去」で、start.ipynb ファイル (つまり、このファイル) で実行できます。 2 2 番目の部分は、「ノイズとノイズを重ね合わせた鮮明な画像と、ノイズとノイズ除去を重ね合わせた鮮明な画像」です。これは test.ipynb ファイルで実行されます。これは公式ドキュメントを簡略化したもので、重ね合わせた鮮明な画像を渡すために使用できます。ノイズを使用してブラインド除去を比較します。ノイズモデルと非ブラインドノイズ除去の違いを示します。
カスタム イメージを使用する場合は、イメージをアップロードし、処理する必要があるイメージのパスを変更して、順番に実行するだけです。 (画像名は英語である必要があります)
パート 1: ぼやけた画像のブラインドノイズ除去 (start.ipynb)
必要なパッケージをインポートする
import sys, time
import torch
import numpy as np
import matplotlib.pyplot as plt
import corner
import arviz as az
from PIL import Image
sys.path.append('..')
from gdiff.data import ImageDataset, get_colored_noise_2d
from gdiff.model import load_model
import gdiff.hmc_utils as iut
from gdiff.utils import ssim, psnr, plot_power_spectrum, plot_list_of_images
plt.rcParams.update(
{
'text.usetex': False,
'font.family': 'stixgeneral',
'mathtext.fontset': 'stix',
}
)画像読み込みと前処理機能、使用方法は公式ドキュメントdata.pyより
#图片读取与预处理,方法来自官方文档 data.py
def readimg(filename):
from torchvision import transforms
img=Image.open(filename)
trans = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(256),
transforms.RandomHorizontalFlip(),
transforms.ToTensor()])
img=trans(img)
return img以下はデータセットを読み取る正式な方法ですが、このドキュメントでは使用されていません。ユーザーは、独自のデータ セットをフォルダーに配置し、わずかな変更を加えてバッチ処理を実行できます (フォルダー名は、データ フォルダー内の指定されたものからのみ選択できます)。
#
# PARAMETERS 官方数据读取与噪声参数,模型选择
#
# Dataset and sample 读取官方数据集
dataset_name = "CBSD68" # Choices among "imagenet_train", "imagenet_val", "CBSD68", "McMaster", "Kodak24"
dataset = ImageDataset(dataset_name, data_dir='./data')
sample_id = 0 # np.random.randint(len(dataset))
# Noise 准备叠在在清晰图片上的噪声
phi_true = -0.4 # Spectral index -> between -1 and 1 (\varphi in the paper)
sigma_true = 0.1 # Noise level
# Device
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Model 选择模型,有 5000 与 10000 步迭代模型可选
diffusion_steps = 5000 # Number of diffusion steps: 5000 or 10000
model = load_model(diffusion_steps=diffusion_steps,
device=device,
root_dir='./model_checkpoints')
model.eval()
# Inference
num_chains = 4 # Number of HMC chains
n_it_gibbs = 50 # Number of Gibbs iterations after burn-in
n_it_burnin = 25 # Number of burn-in iterations次に、ノイズ除去が必要な画像を読み込みます。たとえば、このチュートリアルで使用する画像はホーム ディレクトリにある '3_noisy.png' で、img=readimg('3_noisy) でパスを '3_noisy.png' に直接変更します。 .png') ' 以上です
A6000シングルカードの場合、1枚の画像の処理に数分かかります
#
# DENOISING 在此处读入的图片为高噪声图,在此处进行降噪处理
#
# 读取自己的高噪声图片,用于去噪
img=readimg('3_noisy.png')
x = img.to(device).unsqueeze(0)
# Our DDPM has discrete timestepping -> we get the time step closest to the chosen noise level
sigma_true_timestep, sigma_true = model.get_closest_timestep(torch.tensor([sigma_true]), ret_sigma=True)
alpha_bar_t = model.alpha_bar_t[sigma_true_timestep.cpu()].reshape(-1, 1, 1, 1).to(device)
print(f"Time step corresponding to noise level {sigma_true.item():.3f}: {sigma_true_timestep.item()}")
yt = torch.sqrt(alpha_bar_t) * x # Noisy image normalized for the diffusion model 归一化图像
# Non-blind denoising (for reference) 非盲去噪 即已知噪声参数的情况下去噪
print("Denoising in non-blind setting...")
t0 = time.time()
x_hat_nonblind = model.denoise_samples_batch_time(yt,
sigma_true_timestep.unsqueeze(0),
phi_ps=phi_true)
t1 = time.time()
print(f"Non-blind denoising took {t1-t0:.2f} seconds")
# Blind denoising with GDiff 基于 GDiff 的盲去噪
print("Denoising in blind setting (GDiff)...")
t0 = time.time()
phi_hat_blind, x_hat_blind = model.blind_denoising(x, yt,
num_chains_per_sample=num_chains,
n_it_gibbs=n_it_gibbs,
n_it_burnin=n_it_burnin)
t1 = time.time()
print(f"Blind denoising took {t1-t0:.2f} seconds")
# Denoised posterior mean estimate 去噪的后验均值估计
x_hat_blind_pmean = x_hat_blind[:, n_it_burnin:].mean(dim=(0, 1))ノイズ レベル 0.100 に対応するタイム ステップ: 134 非ブラインド設定でのノイズ除去... 非ブラインドノイズ除去には 4.48 秒かかりました ブラインド設定 (GDiff) でのノイズ除去...
0% | 0/75
300 回の反復を使用してステップ サイズを調整する ステップ サイズは次のように固定されます: tensor([0.0179, 0.0181, 0.0179, 0.0194], device='cuda:0')
100%|██████████| 75/75 [08:52<00:00、7.10秒/it]
ブラインドノイズ除去には 532.30 秒かかりました
#
# Plot of a reconstruction 展示结果 顺序为:原始图片 非盲去噪 盲去噪 去噪的后验均值
#
data = [x[0],
x_hat_blind[0, -1],
x_hat_blind_pmean]
data = [d.to(device) for d in data]
labels_base = [r"True $\mathbf{x}$",
r"Denoised $\hat{\mathbf{x}}$ (blind)",
r"Denoised $E[\mathbf{x}\,|\,\mathbf{y}]$ (blind)"]
labels = [labels_base[0] ,
labels_base[1] ,
labels_base[2] ]
plot_list_of_images(data, labels)
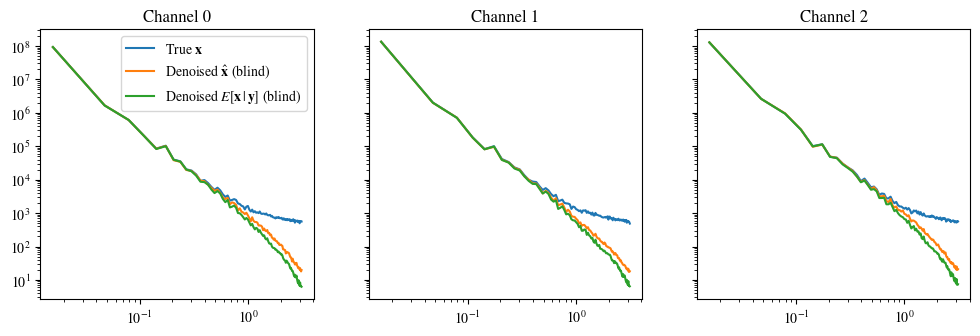
plot_power_spectrum(data, labels_base, figsize=(12, 3.5))入力データを RGB データ (浮動小数点の場合は [0..1]、整数の場合は [0..255]) を使用して imshow の有効な範囲にクリッピングします。