Command Palette
Search for a command to run...
効率的な導入のためのビジョン トランスフォーマー (Vit) の定量化: 戦略とベスト プラクティス
このチュートリアルでは、pytorch バージョン 2.0 とシングル カード 4090 の使用を推奨します。使いやすいように、使用するモデルはチュートリアルにダウンロードされています。順番に実行してください。
1. はじめに
先進的なコンピュータ ビジョン システムに対する需要が業界全体で急増し続ける中、ビジョン トランスフォーマーの導入が研究者や実務者にとって注目を集めています。ただし、これらのモデルの可能性を最大限に発揮するには、そのアーキテクチャを深く理解する必要があります。さらに、これらのモデルを効果的に導入するための最適化戦略を開発することも同様に重要です。
この記事は、Vision Transformer の概要を提供し、そのアーキテクチャ、主要なコンポーネント、およびそれらをユニークなものにする基本を詳しく説明することを目的としています。この記事の最後では、モデルをよりコンパクトにして展開を容易にするためのコードのデモを通じて、いくつかの最適化戦略について説明します。
2.ビタミンの概要
ViT は、主に画像分類とターゲット検出に使用される特殊なタイプのニューラル ネットワークです。 ViT の精度は従来の CNN の精度を上回っています。これに寄与する主な要因は、ViT が Transformer アーキテクチャに基づいていることです。このアーキテクチャは今何ですか?
2017 年に、バスワニらは、 「必要なのは注意力だけです」Transformer ニューラル ネットワーク アーキテクチャは、 で紹介されています。このネットワークは、リカレント ニューラル ネットワーク (RNN) によく似たエンコーダーとデコーダーの構造を使用します。このモデルでは、入力にはタイムスタンプの概念がありません。すべての単語が同時に渡され、単語の埋め込みも同時に決定されます。
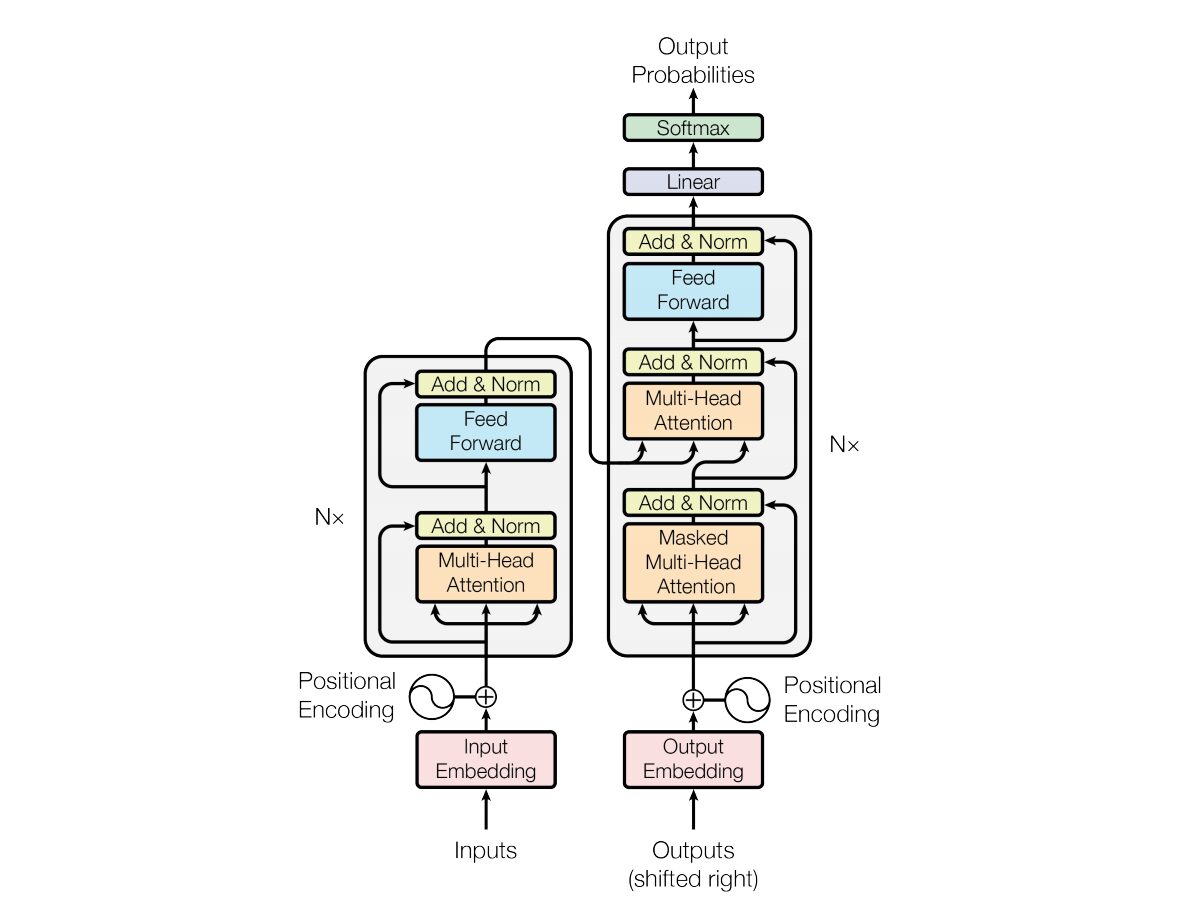
このタイプのニューラル ネットワーク アーキテクチャは、自己注意と呼ばれるメカニズムに依存しています。
以下は、Transformer アーキテクチャの主要コンポーネントの概要です。
- 入力エンベディング: 入力エンベディングは、入力をトランスフォーマーに渡す最初のステップです。入力埋め込みとは、入力トークンまたは単語をモデルに入力できる固定サイズのベクトルに変換するプロセスを指します。この埋め込みステップは、単語間の意味関係を捉える方法で離散トークン表現を連続ベクトル表現に変換するため、非常に重要です。この埋め込みステップでは単語をベクトルにマッピングしますが、同じ単語が異なる文では異なる意味をもつ場合があります。ここで位置エンコーダが登場します。
- 位置エンコーディング: Transformer 自体はシーケンス内の要素の順序を理解できないため、位置エンコーディングが入力埋め込みに追加され、シーケンス内の要素の位置に関する情報をモデルに提供します。つまり、位置埋め込みでは、文内の単語の位置に基づいてコンテキストであるベクトルが得られます。元の論文では、サイン関数とコサイン関数を使用してこのベクトルを生成しています。この情報はエンコーダ ブロックに渡されます。
- エンコーダーとデコーダーの構造: Transformer は主に、機械翻訳などのシーケンス間のタスクに使用されます。エンコーダとデコーダで構成されます。エンコーダは入力シーケンスを処理し、デコーダは出力シーケンスを生成します。
- マルチヘッド セルフ アテンション: セルフ アテンションにより、モデルは予測を行うときに、入力シーケンスのさまざまな部分に異なる重み付けを行うことができます。 Transformer の主な革新は、複数のアテンション ヘッドを使用することで、モデルが入力のさまざまな側面に同時に焦点を当てることができるようになります。各注意ヘッドは、さまざまなパターンに焦点を当てるように訓練されています。
- スケーリングされたドット積アテンション: アテンション メカニズムは、入力シーケンスと学習可能な重みのベクトルのドット積を介して、一連のアテンション スコアを計算します。これらのスコアはスケーリングされ、softmax 関数に渡されて、注意の重みが取得されます。これらのアテンションの重みを使用した入力シーケンスの重み付けされた合計が、アテンション メカニズムの出力です。
- フィードフォワード ニューラル ネットワーク: アテンション層の後に、通常、各エンコーダーおよびデコーダー ブロックには、活性化関数 (ReLu など) を備えたフィードフォワード ニューラル ネットワークが含まれます。ネットワークはシーケンス内の各位置に独立して適用されます。
- 層の正規化と残留接続: 層の正規化と残留接続は、トレーニングを安定させるために使用されます。エンコーダおよびデコーダの各サブレイヤ (アテンションまたはフィードフォワード) にはレイヤ正規化があり、各サブレイヤの出力は残留接続を介して渡されます。
- エンコーダとデコーダのスタック: エンコーダとデコーダは、互いに積み重ねられた複数の同一のレイヤーで構成されます。レイヤーの数はハイパーパラメーターです。
- デコーダでのマスクされたセルフ アテンション: トレーニング中に、デコーダでセルフ アテンション メカニズムが変更され、将来のトークンに焦点を当てないようになります。これはマスキング技術を使用して行われ、各位置がその前の位置のみを処理できるようにします。
- 最終線形層およびソフトマックス層: デコーダ スタックの出力は、出力シーケンスを生成するために (たとえば、線形層とそれに続くソフトマックス アクティベーションを使用して) 最終予測確率に変換されます。
3. Vision Transformer アーキテクチャを理解する
CNN は、画像分類タスクに最適なソリューションと考えられています。事前トレーニングされたデータセットが十分に大きい場合、ViT はそのようなタスクにおいて常に CNN を上回ります。 ViT は、ImageNet 上で Transformer エンコーダーのトレーニングに成功することで重要な成果を達成し、よく知られている畳み込みアーキテクチャと比較して優れた結果を実証しました。
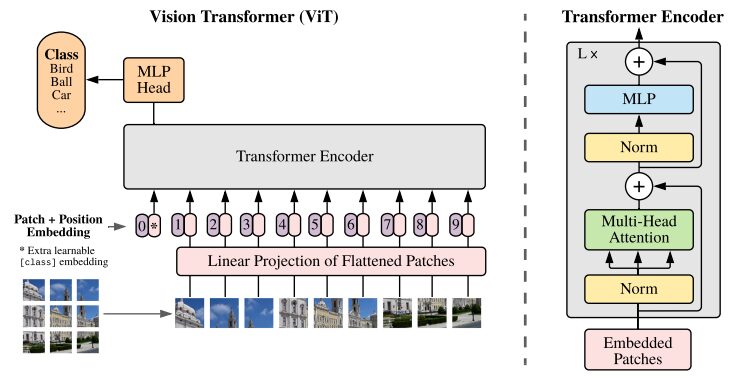
元の研究論文からの ViT アーキテクチャの図
Transformers モデルは通常、エンコーダー/デコーダーに順次渡される画像と単語を処理します。 ViT の簡単な概要は次のとおりです。
- パッチ抽出: イメージは一連のパッチとして Transformer エンコーダーに供給されます。パッチとは、画像の小さな長方形の部分を指し、通常はサイズが 16×16 ピクセルです。

- 画像を重複しないブロック (通常は 16×16 グリッド) に分割した後、各ブロックはその特徴を表すベクトルに変換されます。これらの特徴は通常、画像分類に必要な重要な特徴を識別するように訓練された畳み込みニューラル ネットワーク (CNN) を利用して抽出されます。
- 線形埋め込み: これらの抽出されたパッチは、平面ベクトルに線形に埋め込まれます。これらのベクトルは、フラット パッチの線形投影とも呼ばれる、Transformer への入力シーケンスとして扱われます。
- Transformer エンコーダ: 埋め込まれたパッチ ベクトルは、Transformer エンコーダ レイヤー スタックを介して渡されます。各エンコーダ層はセルフアテンション メカニズムとフィードフォワード ニューラル ネットワークで構成されます。
- セルフ アテンション メカニズム: セルフ アテンション メカニズムにより、モデルは画像内の異なるパッチ間の関係をキャプチャできるようになり、長距離の依存関係や関係を学習できるようになります。 Transformer のアテンション メカニズムにより、モデルはローカルおよびグローバルのコンテキスト情報をキャプチャできるようになり、さまざまなビジョン タスクを効果的に実行できるようになります。
- 位置エンコーディング: Transformer 自体はパッチ間の空間関係を理解していないため、位置エンコーディングが入力エンベディングに追加され、元の画像内のパッチの位置に関する情報が提供されます。
- 複数のエンコーダー レイヤー: ViT は通常、複数の Transformer エンコーダー レイヤーを使用して、入力画像から階層的で抽象的な特徴をキャプチャします。
- グローバル平均プーリング: Transformer エンコーダーの出力は通常、さまざまなパッチからの情報を固定サイズの表現に集約するグローバル平均プーリングの対象となります。
- 分類ヘッド: マージされた表現は分類ヘッド (通常は 1 つ以上の完全に接続されたレイヤーで構成されます) に供給され、特定のコンピューター ビジョン タスク (画像分類など) の最終出力が生成されます。
オリジナルをチェックすることを強くお勧めします研究論文、ViT アーキテクチャをより深く理解するために。
4. 使用方法
pre_ViT.ipynb では、次のコードにアクセスして実行できます。 ! ! !
4.1 事前トレーニングされた ViT モデルを使用して画像を分類する
事前トレーニングされた ViT モデルは、有名な ImageNet-21k (1,400 万の画像と 21,000 のカテゴリを含むデータセット) を使用して事前トレーニングされ、100 万の画像と 1,000 のカテゴリを含む ImageNet データセットで微調整されています。
デモ:
- プラットフォームを初めて起動するときは、次の 2 つのライブラリが欠落しています。依存関係をインストールするには pip を使用します。依存関係をインストールするときに、追加のパラメーターを追加します。これにより、インストールされた依存関係がコンテナーのワークスペースに保存されます。次回の再起動後も無効になりません。
!pip install --user -q transformers timm- Transformer ライブラリから必要なクラスをインポートします。 ViTFeatureExtractor は画像から特徴を抽出するために使用され、ViTForImageClassification は画像分類用の事前トレーニングされた ViT モデルです。
from transformers import ViTFeatureExtractor, ViTForImageClassification
from PIL import Image as img
from IPython.display import Image, display
FILE_NAME = '/notebooks/football-1419954_640.jpg'
display(Image(FILE_NAME, width = 700, height = 400))
#预测图片的地址
image_path = "./pic/football.jpg"
image_array = img.open(image_path)
#Vit 模型地址
vision_encoder_decoder_model_name_or_path = "./my_model/"
#加载 ViT 特征转化 and 预训练模型
#feature_extractor = ViTFeatureExtractor.from_pretrained(vision_encoder_decoder_model_name_or_path)
#model = ViTForImageClassification.from_pretrained(vision_encoder_decoder_model_name_or_path)
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch16-224')
model = ViTForImageClassification.from_pretrained('google/vit-base-patch16-224')
#使用 Vit 特征提取器处理输入图像,专为 ViT 模型的格式
inputs = feature_extractor(images = image_array,
return_tensors="pt")
#预训练模型处理输入并生成输出 logits,代表模型对不同类别的预测。
outputs = model(**inputs)
#创建一个变量来存储预测类的索引。
logits = outputs.logits
# 查找具有最高 Logit 分数的类的索引
predicted_class_idx = logits.argmax(-1).item()
print(predicted_class_idx)
#805
print("Predicted class:", model.config.id2label[predicted_class_idx])
#预测种类:足球コードの内訳:
- ViTFeatureExtractor.from_pretrained: 入力画像を ViT モデルに適した形式に変換する役割を果たします。
- ViTForImageClassification.from_pretrained: 画像分類用に事前トレーニングされた ViT モデルを読み込みます。
- feature_extractor: ViT 特徴抽出機能を使用して入力画像を処理し、ViT モデルに適した形式に変換します。
- モデル: 事前トレーニングされたモデルは入力を処理し、さまざまなカテゴリに対するモデルの予測を表す出力ロジットを生成します。次のステップは、最も高い Logit スコアを持つクラスのインデックスを見つけることです。予測されたクラスのインデックスを格納する変数を作成します。
- model.config.id2label[predicted_class_idx]: 予測されたクラス インデックスを対応するラベルにマッピングします。
4.2 DeiT を使用した画像の分類
DeiT は、利用可能なデータとリソースが限られている場合でも、コンピューター ビジョン タスクへの Transformers の適用が成功していることを示しています。
from PIL import Image
import torch
import timm
import requests
import torchvision.transforms as transforms
from timm.data.constants import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
print(torch.__version__)
# should be 1.8.0
#从 DeiT 存储库加载名为 “deit_base_patch16_224” 的预训练 DeiT 模型。
model = torch.hub.load('facebookresearch/deit:main', 'deit_base_patch16_224', pretrained=True)
#将模型设置为评估模式,这在使用预训练模型进行推理时非常重要。
model.eval()
#定义一系列应用于图像的变换。例如调整大小、中心裁剪、将图像转换为 PyTorch 张量、使用 ImageNet 数据常用的平均值和标准差值对图像进行归一化。
transform = transforms.Compose([
transforms.Resize(256, interpolation=3),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD),
])
#从 URL 下载图像并对其进行转换。或者直接从本地上传
#Image.open(requests.get("https://images.rawpixel.com/image_png_800/czNmcy1wcml2YXRlL3Jhd3BpeGVsX2ltYWdlcy93ZWJzaXRlX2NvbnRlbnQvcHUyMzMxNjM2LWltYWdlLTAxLXJtNTAzXzMtbDBqOXFrNnEucG5n.png", stream=True).raw)
img = Image.open("./pic/football.jpg")
#None 模拟大小为 1 的批次
img = transform(img)[None,]
#模型的推理、预测
out = model(img)
clsidx = torch.argmax(out)
#打印预测类别的索引。
print(clsidx.item())コードの内訳:
- ライブラリのインストール: 最初に必要な手順は、必要なライブラリをインストールすることです。理解を深めるために、これらのライブラリを研究することを強くお勧めします。
- 事前トレーニングされたモデルをロードします:model=torch.hub.load('facebookresearch/deit:main', 'deit_base_patch16_224', pretrained=True) 「deit_base_patch16_224」という名前の事前トレーニングされた DeiT モデルを DeiT リポジトリからロードします。
- モデルを評価モードに設定します。model.eval(): モデルを評価モードに設定します。これは、推論に事前トレーニングされたモデルを使用する場合に非常に重要です。
- 画像変換: 画像に適用する一連の変換を定義します。例には、サイズ変更、中央のトリミング、画像の PyTorch テンソルへの変換、ImageNet データで一般的に使用される平均値と標準偏差値を使用した画像の正規化などが含まれます。画像をダウンロードして変換する: 次のステップでは、URL から画像をダウンロードして変換します。パラメーター [None,] を追加すると、バッチ サイズ 1 をシミュレートするための追加のディメンションが追加されます。
- モデルの推論と予測: out = model(img) により、前処理された画像を DeiT モデルを通じて推論できるようになります。 clsidx = torch.argmax(out) は、最も高い確率でクラスのインデックスを見つけます。次に、予測されたクラスのインデックスを出力します。
4.3 定量的モデル
モデルのサイズを削減するには、量子化が適用されます。このプロセスにより、モデルの精度に影響を与えることなくサイズが縮小されます。
#将量化后端指定为 “qnnpack” 。 QNNPACK(Quantized Neural Network PACKage)是 Facebook 开发的低精度量化神经网络推理库
backend = "qnnpack"
model.qconfig = torch.quantization.get_default_qconfig(backend)
torch.backends.quantized.engine = backend
#推理过程中量化模型的权重,并 qconfig_spec 指定量化应仅应用于线性(全连接)层。使用的量化数据类型是 torch.qint8(8 位整数量化)
quantized_model = torch.quantization.quantize_dynamic(model, qconfig_spec={torch.nn.Linear}, dtype=torch.qint8)
scripted_quantized_model = torch.jit.script(quantized_model)
#模型保存到名为 “fbdeit_scripted_quantized.pt” 的文件
scripted_quantized_model.save("fbdeit_scripted_quantized.pt")コードの内訳:
- torch.quantization.quantize_dynamic(model, qconfig_spec={torch.nn.Linear}, dtype=torch.qint8)
- qconfig_spec は、量子化が線形 (完全に接続された) レイヤーにのみ適用されるように指定します。使用される量子化データ型は torch.qint8 (8 ビット整数量子化) です。
4.4 最適化モデル
optimize_for_mobile 関数は、特にモバイル展開向けに最適化し、結果の最適化モデルをファイルに保存します。
from torch.utils.mobile_optimizer import optimize_for_mobile
optimized_scripted_quantized_model = optimize_for_mobile(scripted_quantized_model)
optimized_scripted_quantized_model.save("fbdeit_optimized_scripted_quantized.pt")
# 使用优化模型进行预测
out = optimized_scripted_quantized_model(img)
clsidx = torch.argmax(out)
print(clsidx.item())4.5 ライト版
これは、PyTorch Lite をサポートするモバイルまたはエッジ デバイスにモデルをデプロイし、そのようなデバイスのランタイム環境の互換性と効率を確保するために重要です。
optimized_scripted_quantized_model._save_for_lite_interpreter("fbdeit_optimized_scripted_quantized_lite.ptl")
ptl = torch.jit.load("fbdeit_optimized_scripted_quantized_lite.ptl")4.6 推論速度の比較
さまざまなモデル バリアントの推論速度を比較するには、提供されたコードを実行します。
with torch.autograd.profiler.profile(use_cuda=False) as prof1:
out = model(img)
with torch.autograd.profiler.profile(use_cuda=False) as prof2:
out = scripted_quantized_model(img)
with torch.autograd.profiler.profile(use_cuda=False) as prof3:
out = optimized_scripted_quantized_model(img)
with torch.autograd.profiler.profile(use_cuda=False) as prof4:
out = ptl(img)
print("original model: {:.2f}ms".format(prof1.self_cpu_time_total/1000))
print("scripted & quantized model: {:.2f}ms".format(prof2.self_cpu_time_total/1000))
print("scripted & quantized & optimized model: {:.2f}ms".format(prof3.self_cpu_time_total/1000))
print("lite model: {:.2f}ms".format(prof4.self_cpu_time_total/1000))
上記のコードは、pre_ViT.ipynb でアクセスして実行できます。 ! ! !
結論と感想
この記事には、Visual Transformer の使用を開始し、Paperspace コンソールを使用してモデルを探索するために必要なものがすべて含まれています。このモデルの重要なアプリケーションの 1 つである画像認識を検討します。 ViT の比較と簡単な説明のために、Transformer アーキテクチャも含めます。
Vision Transformer の論文では、CNN の代替として有望でシンプルなモデルが紹介されています。 ILSVRC の ImageNet とそのスーパーセット ImageNet-21M で事前トレーニングされたこのモデルは、Oxford-IIIT Pets、Oxford Flowers、Google Brain の JFT-300M などの一般的な画像分類データセットで最先端のベンチマークに達します。
要約すると、ビジョン トランスフォーマー (ViT) と DeiT は、コンピューター ビジョンの分野における大きな進歩を表しています。 ViT は、従来の畳み込み手法に挑戦する、注意ベースのアーキテクチャによる画像理解における Transformer モデルの有効性を実証します。
特に DeiT は、知識の蒸留を導入することで、ViT が直面する課題にさらに取り組んでいます。 DeiT は、教師と生徒のトレーニング パラダイムを活用することで、大幅に削減されたラベル付きデータで競争力のあるパフォーマンスを達成できる可能性を実証しており、大規模なデータセットがすぐに利用できないシナリオでは価値のあるソリューションとなります。
この分野の研究が進化し続けるにつれて、これらのイノベーションはより効率的で強力なモデルへの道を切り開き、コンピューター ビジョン アプリケーションの将来に刺激的な可能性をもたらします。