Command Palette
Search for a command to run...
カスタムデータを使用した YOLOv8 のトレーニング
このチュートリアルでは、Ultralyticsの新モデルYOLOv8の新機能について解説し、YOLOv5と比較したアーキテクチャの変更点を詳細に解説します。さらに、バスケットボールデータセットで検出を行うためのPython API機能をテストすることで、新モデルのデモを行います。主にYOLOv8の原理を説明し、データセットの作成とラベル付け、モデルのトレーニング、そして入力されたビデオファイルやストリームへの適用方法を説明します。
物体検出は依然として AI テクノロジーの最も一般的で簡単な使用例の 1 つです。 YOLO ファミリのモデルは、Joseph Redman らの独創的な著作「You Only Look Once: Unified, Real-Time Object Detection」で 2016 年に最初のバージョンがリリースされて以来、先頭に立ってきました。これらの物体検出モデルは、DL モデルを使用して画像内のエンティティの被写体と位置のリアルタイム認識を実行する研究への道を開きます。
この記事では、これらのテクノロジーの基本を再検討し、Ultralytics の最新バージョン YOLOv8 の新機能について説明し、RoboFlow と Paperspace Gradient および新しい機能を使用してカスタム YOLOv8 モデルを微調整する手順を段階的に示します。ウルトラリティクス API。このチュートリアルが終了するまでに、ユーザーは YOLOv8 モデルをラベル付き画像のセットにすばやく簡単に適合できるようになります。
YOLOはどのように機能しますか?
まず、YOLO の基本的な動作原理について説明します。以下は、モデルの特徴の合計を分解した元の YOLO 論文からの短い引用です。
「単一の畳み込みネットワークで、複数の境界ボックスとそれらのクラス確率を同時に予測します。YOLOはフル画像で学習し、検出性能を直接最適化します。この統合モデルは、従来の物体検出手法に比べていくつかの利点があります。」
上で述べたように、モデルがこれらの特徴に基づいてトレーニングされていれば、画像内の複数のエンティティの位置を予測し、その被写体を識別することができます。画像をサイズ s * s の N 個のグリッドに分割することにより、これを 1 つのステージで実行します。これらの領域は同時に解析され、その中に含まれるオブジェクトが検出され、位置が特定されます。次に、モデルは各グリッドの境界ボックス座標 B を予測し、その中に含まれるオブジェクトのラベルと予測スコアを予測します。
これらすべてを組み合わせることで、物体分類、物体検出、画像セグメンテーションのタスクを実行できる技術が得られます。YOLOの基盤技術は変更されていないため、YOLOv8でも同様に機能すると推測できます。YOLOの仕組みをより詳細に知りたい場合は、YOLOv5とYOLOv7に関する以前の投稿、YOLOv6とYOLOv7のベンチマーク、そしてオリジナルのYOLO論文をご覧ください。
YOLOv8 の新機能は何ですか?
YOLOv8 はリリースされたばかりなので、このモデルをカバーする論文はまだ発行されていません。著者は近々公開する予定ですが、今のところは公式の投稿を信頼し、コミット履歴から変更を推測し、YOLOv5 と YOLOv8 の間の変更の範囲を自分で判断することしかできません。
によると正式リリース, YOLOv8は、新しいバックボーンネットワーク、アンカーフリー検出ヘッド、ロス機能を採用しています。 Github ユーザー RangeKing は、更新されたモデルのバックボーンとヘッダー構造を示し、YOLOv8 モデル インフラストラクチャの概要を共有しました。この図と比較すると、 YOLOv5 同様のチェックを比較するには、RangeKing の役職次の変更が確認されています。

C2f モジュール、画像ソース: RoboFlow (ソース)- 彼らは使用します
C2fモジュールを交換しましたC3モジュール。存在するC2fで、からBottleneck(残りの接続を備えた 2 つの 3×3convs) は連結されていますが、C3、最後のものだけが使用されますBottleneck出力。 (ソース)

- 彼らはいます
Backbone1 つを使用してください3x3 Convブロックは最初のブロックを置き換えます6x6 Conv - 彼らは2つを削除しました
Conv(YOLOv5 構成の 10 番目と 14 番目)

- 彼らはいます
Bottleneck1 つを使用してください3x3 Conv最初のものを置き換えた1x1 Conv - 代わりに分離されたヘッダーが使用され、削除されました。
objectness支店
YOLOv8 ペーパーがリリースされた後、もう一度チェックしてください。詳細を提供するためにこのセクションが更新されます。上記の変更の詳細な分析については、RoboFlow の記事を参照してください。 YOLOv8 リリースの。
アクセシビリティ
Github リポジトリをクローンして環境を手動で設定するという従来の方法に加えて、ユーザーは新しい Ultralytics API を使用してトレーニングと推論のために YOLOv8 にアクセスできるようになりました。以下をご確認ください トレーニングモデル API の設定の詳細については、セクションを参照してください。
アンカー境界ボックスがありません
Ultralytics パートナー RoboFlow のブログ投稿によると YOLOv8, YOLOv8 にはアンカーのない境界ボックスが追加されました。 YOLO の初期バージョンでは、オブジェクト検出プロセスを容易にするために、ユーザーはこれらのアンカー ボックスを手動で識別する必要がありました。これらの事前定義された境界ボックスは、所定のサイズと高さを持ち、データセット内の特定のオブジェクト クラスのスケールとアスペクト比をキャプチャします。これらの境界から予測されたオブジェクトまでのオフセットは、モデルがオブジェクトの位置をより適切に識別するのに役立ちます。
YOLOv8 では、これらのアンカー ボックスはオブジェクトの中心にあると自動的に予測されます。
トレーニングが終了する前にモザイク ブーストを停止する
トレーニングの各エポックで、YOLOv8 は、供給された画像のわずかに異なるバージョンを認識します。これらの変更は機能拡張と呼ばれます。そのうちの1人、モザイク強調は、4 つの画像を結合するプロセスであり、モデルに新しい位置にあるオブジェクトのアイデンティティを強制的に学習させ、オクルージョンによって相互に部分的にブロックし、周囲のピクセルに大きな変化をもたらします。トレーニング プロセス全体でこの種の拡張を使用すると、予測精度に悪影響を及ぼすことがわかっているため、トレーニングの最後の数エポック中に、YOLOv8 はこのプロセスを停止することができます。これにより、実行全体にスケールを適用することなく、最適なトレーニング パターンを実行できます。
効率と正確さ
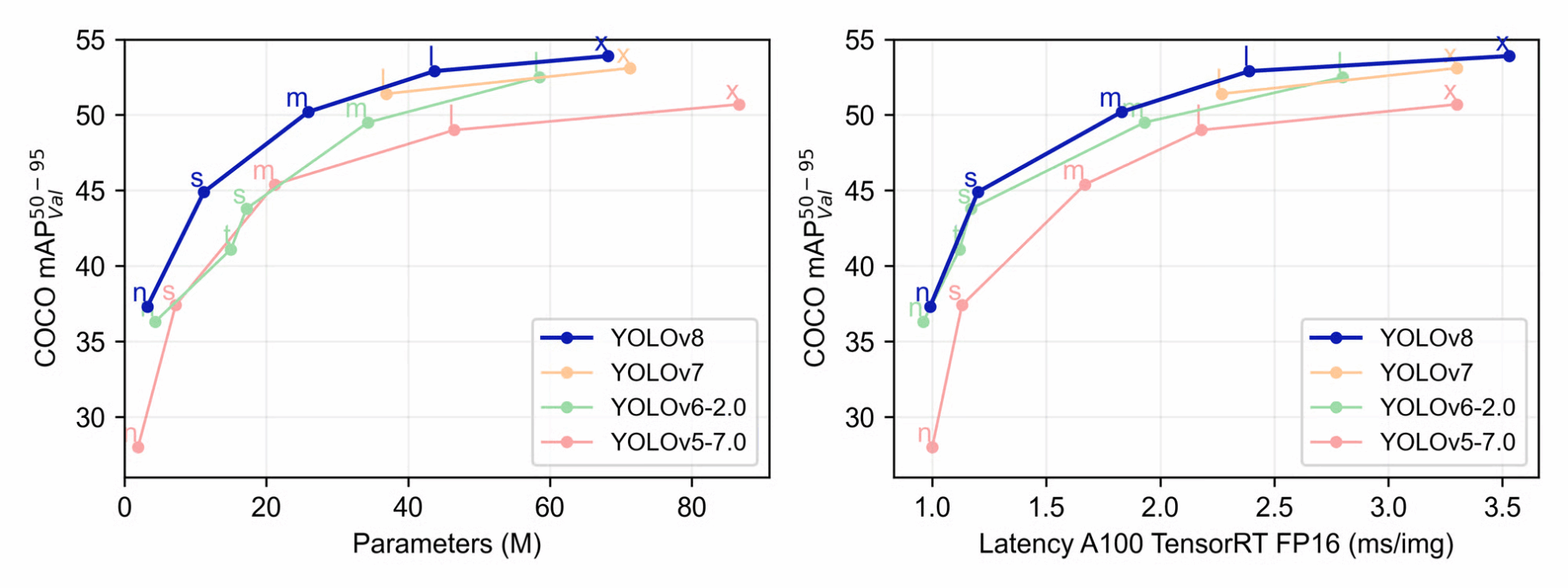
私たちがここにいる主な理由は、推論とトレーニング中のパフォーマンスの精度と効率を向上させることです。 Ultralytics の作成者は、YOLO の新しいバージョンを他のバージョンと比較するために使用できるいくつかの有用なサンプル データを提供してくれました。上のグラフからわかるように、トレーニング中の平均精度、サイズ、遅延の点で、YOLOv8 は YOLOv7、YOLOv6-2.0、および YOLOv5-7.0 よりも優れています。

それぞれの Github ページで、さまざまなサイズの YOLOv8 モデルの統計比較表を見つけることができます。上の表からわかるように、パラメータ、速度、FLOP のサイズが増加すると、mAP も増加します。最大の YOLOv5 モデル YOLOv5x の最大 mAP 値は 50.7 です。 mAP の 2.2 単位の増加は、能力の大幅な向上を表します。これはすべてのモデル サイズにわたって維持されており、以下に示すように、新しい YOLOv8 モデルは一貫して YOLOv5 を上回っています。

全体として、YOLOv8 は YOLOv5 や他の競合フレームワークよりも大幅に前進していることがわかります。
YOLOv8 の微調整
チュートリアルを実行します。OpenBayes でオンラインで実行を開始する
YOLOv8 モデルを微調整するプロセスは、データ セットの作成とラベル付け、モデルのトレーニング、モデルのデプロイの 3 つのステップに分けることができます。このチュートリアルでは、最初の 2 つの手順を詳しく説明し、受信ビデオ ファイルまたはストリームで新しいモデルを使用する方法を示します。
データセットをセットアップする
2つのモデルを比較するために使用したYOLOv7実験を再現するため、Roboflowのバスケットボールデータセットに戻ります。データセットの設定、ラベル付け、そしてRoboflowからノートブックへの取り込みに関する詳細な手順については、前回の記事の「カスタムデータセットの設定」セクションをご覧ください。
以前に作成したデータセットを使用しているので、後はデータを取り込むだけです。以下は、Notebook 環境にデータを取り込むために使用されるコマンドです。独自のラベル付きデータセットの場合は、同じプロセスを使用しますが、ワークスペースとプロジェクトの値を独自の値に置き換えて、同じ方法でデータセットにアクセスします。
以下のスクリプトを使用してノートブックのデモを実行する場合は、必ず API キーを自分のものに変更してください。
!pip install roboflow
from roboflow import Roboflow
rf = Roboflow(api_key="")
project = rf.workspace("james-skelton").project("ballhandler-basketball")
dataset = project.version(11).download("yolov8")
!mkdir datasets
!mv ballhandler-basketball-11/ datasets/トレーニングモデル
新しい Python API を使用すると、 ultralytics このライブラリは、Gradient Notebook 環境内ですべてを簡単に実行します。提供された構成とウェイトを使用して最初から構築します YOLOv8n モデル。次に、環境にロードしたばかりのデータセットを使用します。 model.train() 方法を微調整します。
from ultralytics import YOLO
# 加载模型
model = YOLO("yolov8n.yaml") # 从头构建新模型
model = YOLO("yolov8n.pt") # 加载预训练模型(建议用于训练)
# 使用模型
results = model.train(data="datasets/ballhandler-basketball-11/data.yaml", epochs=10) # 训练模型テストモデル
results = model.val() # 在验证集上评估模型性能私たちは使うことができます model.val() 方法 検証セットで評価する新しいモデルを設定します。これにより、モデルのパフォーマンスを示す優れた表が出力ウィンドウに出力されます。ここでは 10 エポックだけトレーニングしたため、50 ~ 95 という比較的低い mAP が予想されます。

そこからは、写真を簡単に送信できます。境界ボックス予測を出力し、これらのボックスを画像にオーバーレイして、「runs/detect/predict」フォルダーにアップロードします。
from ultralytics import YOLO
from PIL import Image
import cv2
# from PIL
im1 = Image.open("assets/samp.jpeg")
results = model.predict(source=im1, save=True) # 保存绘制的图像
print(results)
display(Image.open('runs/detect/predict/image0.jpg'))次のように、境界ボックスとそのラベルの予測を取得します。
[Ultralytics YOLO <class 'ultralytics.yolo.engine.results.Boxes'> masks
type: <class 'torch.Tensor'>
shape: torch.Size([6, 6])
dtype: torch.float32
+ tensor([[3.42000e+02, 2.00000e+01, 6.17000e+02, 8.38000e+02, 5.46525e-01, 1.00000e+00],
[1.18900e+03, 5.44000e+02, 1.32000e+03, 8.72000e+02, 5.41202e-01, 1.00000e+00],
[6.84000e+02, 2.70000e+01, 1.04400e+03, 8.55000e+02, 5.14879e-01, 0.00000e+00],
[3.59000e+02, 2.20000e+01, 6.16000e+02, 8.35000e+02, 4.31905e-01, 0.00000e+00],
[7.16000e+02, 2.90000e+01, 1.04400e+03, 8.58000e+02, 2.85891e-01, 1.00000e+00],
[3.88000e+02, 1.90000e+01, 6.06000e+02, 6.58000e+02, 2.53705e-01, 0.00000e+00]], device='cuda:0')]次に、以下の例に示すように、それらを画像に適用します。

ご覧のとおり、軽くトレーニングされたモデルは、1 つのコーナーを除いて、ピッチ上の選手とサイドラインの選手を識別できることを示しています。ほぼ確実にさらなるトレーニングが必要ですが、モデルがタスクを非常に早く理解できることが簡単にわかります。
モデルのトレーニングに満足したら、モデルを目的の形式にエクスポートできます。この場合、ONNX バージョンをエクスポートします。
success = model.export(format="onnx") # 将模型导出为 ONNX 格式要約する
このチュートリアルでは、Ultralytics の強力な新しいモデル YOLOv8 の新機能を調べ、YOLOv5 と比較したアーキテクチャの変更について洞察を深め、新しいモデルで Ballhandler データセットをテストすることで新しいモデルの Python API 機能をテストします。これが YOLO 物体検出モデルの微調整プロセスを簡素化する上で重要な進歩であることを示すことができ、試合の写真を使用して NBA ゲームでのボール保持を区別するモデルの能力を実証しました。