Command Palette
Search for a command to run...
YOLOv10:リアルタイムエンドツーエンドオブジェクト検出
YOLOv10:リアルタイムエンドツーエンドオブジェクト検出
概要
近年、YOLOモデルは、計算コストと検出性能の間に優れたバランスを実現していることから、リアルタイムオブジェクト検出分野における主要な枠組みとして登場し、広く採用されている。研究者たちはYOLOのアーキテクチャ設計、最適化目的、データ拡張戦略など多岐にわたる要素について検討を重ね、顕著な進展を遂げてきた。しかし、後処理において非最大値抑制(Non-Maximum Suppression: NMS)に依存している点は、YOLOのエンド・トゥ・エンド導入を阻害し、推論遅延に悪影響を及ぼす要因となっている。さらに、YOLOの各種モジュール設計には包括的かつ徹底的な検証が欠けており、顕著な計算リソースの無駄が生じ、モデルの性能を制限する要因となっている。その結果、効率性は最適化されておらず、さらなる性能向上の余地が大きく残されている。本研究では、後処理とモデルアーキテクチャの両面から、YOLOの性能と効率の境界をさらに前進させることを目的とする。そのために、NMSを不要とする訓練に適した「一貫した二重割り当て(Consistent Dual Assignments)」を提案し、競争力のある性能と低遅延の両立を実現した。さらに、効率性と精度の両面から最適化を図る包括的なモデル設計戦略を導入した。本戦略により、YOLOの各構成要素を効率性と精度の観点から包括的に最適化し、大幅な計算負荷の低減と性能の向上を達成した。本研究の成果として、リアルタイムエンド・トゥ・エンドオブジェクト検出に適した新世代YOLOシリーズ「YOLOv10」が開発された。広範な実験の結果、YOLOv10は様々なモデルスケールにおいて、最先端の性能と効率を実現した。例えば、COCOデータセットにおいて同等のAP(Average Precision)を達成した場合、YOLOv10-SはRT-DETR-R18に比べ1.8倍高速であり、パラメータ数とFLOPs(浮動小数点演算数)はそれぞれ2.8倍少ない。また、YOLOv9-Cと同等の性能を達成するYOLOv10-Bは、46%の遅延削減と25%のパラメータ削減を実現した。
One-sentence Summary
The authors from Tsinghua University propose YOLOv10, a new real-time end-to-end object detection framework that eliminates non-maximum suppression through consistent dual assignments and employs a holistic efficiency-accuracy driven design, achieving state-of-the-art speed, accuracy, and model compactness across scales, with YOLOv10-S being 1.8× faster than RT-DETR-R18 and YOLOv10-B reducing latency by 46% compared to YOLOv9-C.
Key Contributions
-
The paper addresses the inefficiency of YOLOs caused by reliance on non-maximum suppression (NMS) for post-processing, proposing a consistent dual assignments strategy that enables NMS-free training with one-to-one label assignment and a consistent matching metric, thereby achieving end-to-end deployment with low inference latency and competitive accuracy.
-
It introduces a holistic efficiency-accuracy driven model design strategy that systematically optimizes key components of YOLOs, including a lightweight classification head, spatial-channel decoupled downsampling, rank-guided block design, and an effective partial self-attention module, significantly reducing computational redundancy while enhancing model capability.
-
Extensive experiments on COCO demonstrate that YOLOv10 achieves state-of-the-art performance-efficiency trade-offs, with YOLOv10-S being 1.8× faster than RT-DETR-R18 at similar AP, and YOLOv10-B achieving 46% lower latency and 25% fewer parameters than YOLOv9-C at the same performance level.
Introduction
The authors leverage the widespread adoption of YOLO-based object detectors in real-time applications such as autonomous driving and robotics, where balancing accuracy and speed is critical. Prior YOLO variants rely on non-maximum suppression (NMS) for post-processing, which introduces latency, hinders end-to-end deployment, and creates sensitivity to hyperparameters. Additionally, architectural components in YOLOs have been optimized in isolation, leading to computational redundancy and suboptimal efficiency and performance. To address these issues, the authors introduce YOLOv10, a new generation of real-time end-to-end detectors. Their key contributions include a consistent dual assignments strategy that enables NMS-free training with one-to-many supervision during training and one-to-one inference, ensuring both high accuracy and low latency. They further propose a holistic efficiency-accuracy driven design that integrates lightweight classification heads, spatial-channel decoupled downsampling, rank-guided block design, large-kernel convolutions, and a partial self-attention module to reduce redundancy and enhance capability. As a result, YOLOv10 achieves state-of-the-art accuracy-efficiency trade-offs across multiple scales, outperforming prior models like YOLOv9 and RT-DETR in speed, parameter count, and FLOPs while maintaining or improving accuracy.
Method
The authors leverage a dual-head architecture to enable NMS-free training in YOLO models, addressing the trade-off between inference efficiency and performance. The framework, illustrated in the diagram below, consists of a shared backbone and a PAN (Path Aggregation Network) neck, which feed into two parallel detection heads. The first is a one-to-many head, which provides rich supervisory signals during training by assigning multiple positive predictions to each ground truth instance. The second is a one-to-one head, which assigns only a single prediction per ground truth, thereby eliminating the need for NMS post-processing during inference. Both heads share the same underlying network structure and optimization objectives, but they utilize different label assignment strategies. During training, the model is jointly optimized with both heads, allowing the backbone and neck to benefit from the abundant supervision of the one-to-many branch. During inference, the one-to-many head is discarded, and predictions are made solely by the one-to-one head, enabling end-to-end deployment without additional computational cost. This design ensures that the model can achieve high accuracy during training while maintaining high inference efficiency.
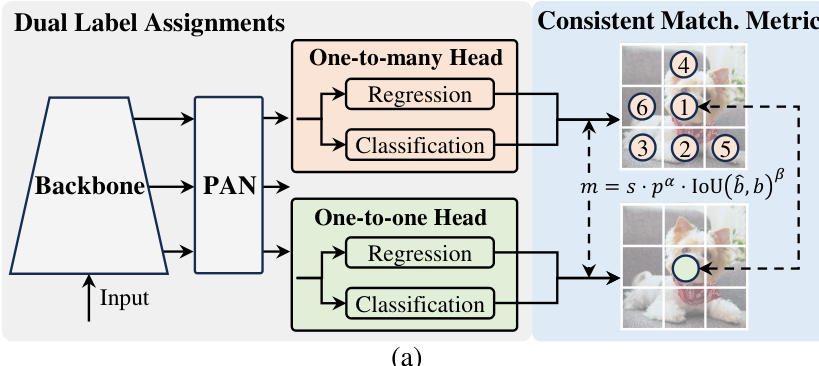
To ensure that the one-to-one head is optimized in a manner consistent with the one-to-many head, the authors introduce a consistent matching metric. This metric, defined as m=s⋅pα⋅IoU(b^,b)β, quantitatively assesses the concordance between a prediction and a ground truth instance, where p is the classification score, b^ and b are the predicted and ground truth bounding boxes, s is a spatial prior indicating if the anchor point is within the instance, and α and β are hyperparameters balancing the classification and regression tasks. The authors employ a uniform matching metric for both heads, setting the hyperparameters of the one-to-one head (αo2o,βo2o) to be proportional to those of the one-to-many head (αo2m,βo2m), specifically αo2o=r⋅αo2m and βo2o=r⋅βo2m. This ensures that the best positive sample for the one-to-many head is also the best for the one-to-one head, harmonizing the optimization of both branches and reducing the supervision gap. This consistency is crucial for the one-to-one head to learn high-quality predictions that are aligned with the superior performance of the one-to-many head.
Experiment
- YOLOv10 achieves state-of-the-art performance and end-to-end latency across all model scales, outperforming YOLOv8, YOLOv6, YOLOv9, YOLO-MS, Gold-YOLO, and RT-DETR. On COCO, YOLOv10-N/S achieve 1.5/2.0 AP gains over YOLOv6-3.0-N/S with 51%/61% fewer parameters and 41%/52% less computation; YOLOv10-L shows 68% fewer parameters and 32% lower latency than Gold-YOLO-L with 1.4% higher AP; YOLOv10-S/X are 1.8× and 1.3× faster than RT-DETR-R18/R101 at similar accuracy.
- Ablation studies confirm that NMS-free training with consistent dual assignments reduces end-to-end latency by 4.63ms for YOLOv10-S while maintaining 44.3% AP, and efficiency-driven design reduces parameters by 11.8M and FLOPs by 20.8 GFLOPs for YOLOv10-M with 0.65ms latency reduction.
- Consistent matching metric improves AP-latency trade-off by aligning supervision between one-to-many and one-to-one heads, eliminating the need for hyperparameter tuning.
- Accuracy-driven design with large-kernel convolution and partial self-attention (PSA) boosts YOLOv10-S by 0.4% and 1.4% AP with minimal latency overhead; PSA achieves 0.3% AP gain and 0.05ms latency reduction over transformer blocks.
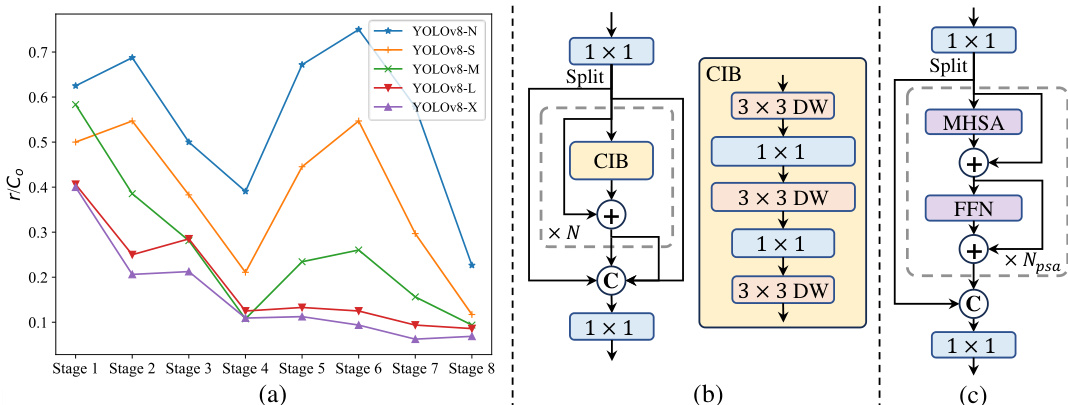
- Rank-guided block design enables efficient CIB integration in high-redundancy stages without performance loss, enhancing model efficiency.
- Training cost analysis shows YOLOv10 maintains high throughput despite 500 epochs, with only 18s/epoch additional overhead for NMS-free training, and outperforms competitors trained for 300 epochs.
- On CPU (OpenVINO), YOLOv10 demonstrates state-of-the-art performance-efficiency trade-offs.
- Visualization results confirm robust detection under challenging conditions, including low light, rotation, and dense object scenarios.
Results show that the dual label assignments and consistent matching metric significantly improve the AP-latency trade-off, with the best performance achieved when both are applied, resulting in 44.3% AP and 2.44ms latency. The ablation study further demonstrates that the efficiency-driven design reduces parameters and FLOPs while maintaining competitive performance, highlighting the effectiveness of the proposed architectural improvements.

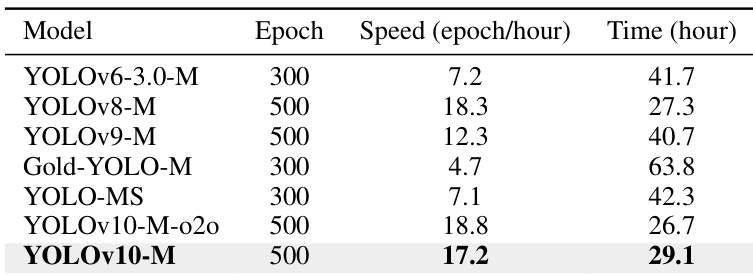
The authors compare the training efficiency of YOLOv10-M with other YOLO variants, showing that YOLOv10-M achieves a high training throughput of 17.2 epochs per hour, resulting in a total training time of 29.1 hours on 8 NVIDIA 3090 GPUs. This demonstrates that despite using 500 training epochs, YOLOv10 maintains an affordable training cost compared to other models.
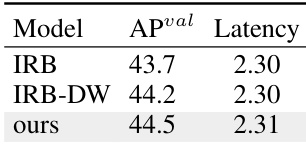
The authors use a comparison of different model variants to evaluate the effectiveness of their proposed Compact Inverted Block (CIB) design. Results show that their CIB-based model achieves a 0.8% AP improvement over IRB-DW while maintaining similar latency, demonstrating the effectiveness of their block design in enhancing performance without increasing computational cost.
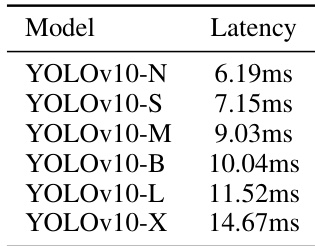
The authors present latency results for YOLOv10 models across different scales, showing that larger models have higher inference latencies. YOLOv10-N achieves the lowest latency at 6.19ms, while YOLOv10-X has the highest at 14.67ms, reflecting a clear trend of increasing latency with model size.
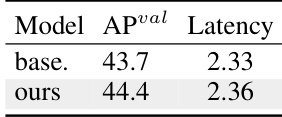
The authors use an ablation study to evaluate the impact of their proposed NMS-free training with consistent dual assignments on YOLOv10-S. Results show that this approach improves the model's AP from 43.7% to 44.4% while increasing latency by only 0.03ms, demonstrating a minimal trade-off between accuracy and speed.