Command Palette
Search for a command to run...
アニメ版『三体問題』が制作開始 本当に2021年に公開されるのか?

最近、アニメーション版「三体問題」の公式予告編がステーションBで公開され、最終作が2021年に公開されることが発表されました。 3分間の短いビデオは何百万人もの人々の注目を集めました。 。今回の「三体問題」はどれくらい待てばいいのでしょうか?
今週、アニメ版「三体問題」の初の公式PV(プロモーションビデオプロモーションコンセプトフィルム)がStation Bにて公開されました。動画が公開されるやいなや、大きな人気と大量のクリック数を獲得しました。これまでのところ、このビデオはステーション B で約 1,000 万回再生されています。
アニメ『三体』初の公式PV
超人気の「三体問題」は映画化やテレビ化が難しかった
小説「三体問題」は、2006 年に初めて「サイエンス フィクション ワールド」で連載が始まりました。その素晴らしいストーリー、崇高な意図、壮大なテーマにより、すぐに何千人もの人々が求める SF の傑作となりました。
以来、三部作は次々と単行本が発売され、ザッカーバーグやオバマも絶賛し、2015年にはSF界最高の賞を受賞した。現代世界に影響を与えた中国の小説の一つ。

しかし、『三体問題』の映画化への道は非常に険しいようだ 映画版『三体問題』は2015年に撮影されたが、公開の知らせはない。
ストーリーの複雑さ、筋金入りのSF要素、そして想像力豊かなシーンはすべて非常に大きな挑戦です。
劇場版だけでは突破口が開けない今、アニメ化することで多くの制約を回避できるかもしれない。アニメーション自体も想像力に依存するため、絵やビジュアル表現に実用的な上限をあまり設けることなく、可能な限りワイルドに使用できます。
おそらくこの理由から、Bilibili は Trisolaris Universe と Yihua Kaitian を統合して、「Three-Body」のアニメーション版を作成するために協力し始めました。
アニメーションって、なぜ作るのがこんなに難しいのでしょうか?
近年のアニメ作品は良い作品が生まれるまでに時間がかかりました。
国内アニメを盛り上げた『大賢者の帰還』、8年かけて丁寧に磨き上げました、最終的に満足のいく答えを渡し、興行収入も9億5,600万を獲得しました。
「Nezha: The Devil Boy Comes into the World」の制作には 5 年の歳月と 1,600 人以上のスタッフがかかりました』は興行収入49億を稼ぎ出し、中国映画史上2番目に高い興行収入を記録した。

ハイクオリティアニメーションとは膨大なプロジェクトであり、大量のキャラクター画制作、絵コンテアニメーション描画、特撮制作という完全に「クールな仕事」である。わずか 10 秒のスクリーンショットを作成するには、複数のチームが数か月間懸命に取り組む必要がある場合があります。
幸いなことに、AI テクノロジーの発展により、アニメーション制作にある程度の助けがもたらされています。おそらく、いくつかの新しい AI テクノロジーは、より完璧な「三体」アニメーションを作成するためのより効率的な方法やアイデアを提供するのに役立つでしょう。
アニメーションを加速するブラックテクノロジー:絵が勝手に動く
熟練したアニメーターであれば、人間のイメージに合わせてキャラクターを構築することは難しくありませんが、必要に応じて動かすには多大な労力がかかる場合があります。
たとえば、2 次元アニメーションでの複数のモーション ショットの描画や、3 次元アニメーションでのモーション キャプチャ技術などです。しかし今では、AI が写真を自動的に「起こし」て、写真を動かすことができるようになりました。
ワシントン大学とフェイスブックの研究者らは少し前に、AIを利用して静止画像や絵画内の文字を3Dアニメーションに変換する研究を発表した。

このテクノロジーは、PyTorch フレームワーク上で開発された一連の深層学習モデルです。このソフトウェアは画像から人物をセグメント化し、その上に 3D メッシュをオーバーレイし、メッシュをアニメーション化して写真や絵画に命を吹き込みます。
既製のアルゴリズムを使用して、画像上で人物検出、2D 姿勢推定、人物セグメンテーションを実行します。次に、SMPL (Skinned Multiplayer Linear、3D キャラクター モデル) テンプレート モデルが 2D ポーズにフィットし、ノーマル マップとスキン マップとして画像に投影されます。
このステップの核心は、人物の輪郭と SMPL 輪郭の間のマッピングを見つけ、SMPL 法線/スキン マップを出力に渡し、モーションの法線マップを統合して深度マップを構築することです。
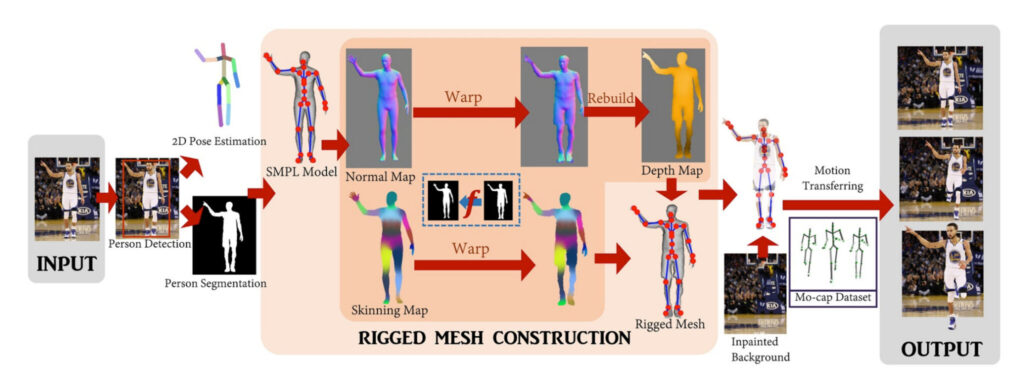
このプロセスを繰り返してモデルの背面図をシミュレートし、深度マップとスキン マップを組み合わせて完全なアセンブリ 3D メッシュを作成します。メッシュはさらにテクスチャ化され、復元された背景上でモーション キャプチャ シーケンスを使用して最終的にアニメーション化されました。
つまり、キャラクターの全身を正面から捉えた画像があれば、この技術を使えば動きのあるシーンを撮ることができるのです。単一の画像から仮想画像を再構築し、写真からキャラクターモデリングまでの技術的可能性を探ります。
アニメーションを高速化するブラックテクノロジー: テキストを自動的にアニメーションに変換します
翻案作品において、原作に忠実かつ操作を極力簡素化したい場合、テキストを利用して直接アニメーションを生成するのが最も理想的な方法と言えるでしょう。現時点では、AI テクノロジーは絶えず進歩しています。
2018 年、イリノイ大学とアレン人工知能研究所の研究者は、CRAFT (Composition, Retrieval, and Fusion Network) と呼ばれる AI モデルを開発しました。これは、「対応するアニメーション シーンは、 「フリントストーン」の素材。

最終的な AI モデルは、25,000 を超えるビデオ クリップでトレーニングされました。映像内の各ビデオは 3 秒、75 フレームの長さで、シーン内の登場人物とシーンの内容のラベルと注釈が付けられています。
AI モデルはビデオとテキストの説明を一致させることを学習し、一連のパラメーターを確立します。最後に、提供されたテキスト説明を、ビデオから学習したキャラクター、小道具、シーンの場所などを含む、アニメ シリーズのファン派生作品に変換できます。
これが単純な編集とつなぎ合わせであれば、現在の AI ではさらに多くのことができます。
今年4月、ディズニーとラトガース大学の科学者らは、AIモデル996スクリプトを与え、最終的にAIがテキストの説明に基づいてアニメーションを自動的に生成することを学習できるようにする論文を発表した。
AI がビデオからテキストを生成するには、テキストを「理解」し、対応するアニメーションを生成する必要があります。これを行うために、彼らは複数のモジュール式コンポーネントを備えたニューラル ネットワークを使用しました。
モデルは 3 つの部分で構成されます。1 つはスクリプト テキスト内のシーンを自動的に解析するスクリプト解析モジュールで、2 つ目は主要な説明文を抽出してアクション表現を調整する自然言語処理モジュールです。アクションを命令に変換し、アニメーションシーケンスに変換する生成モジュールです。
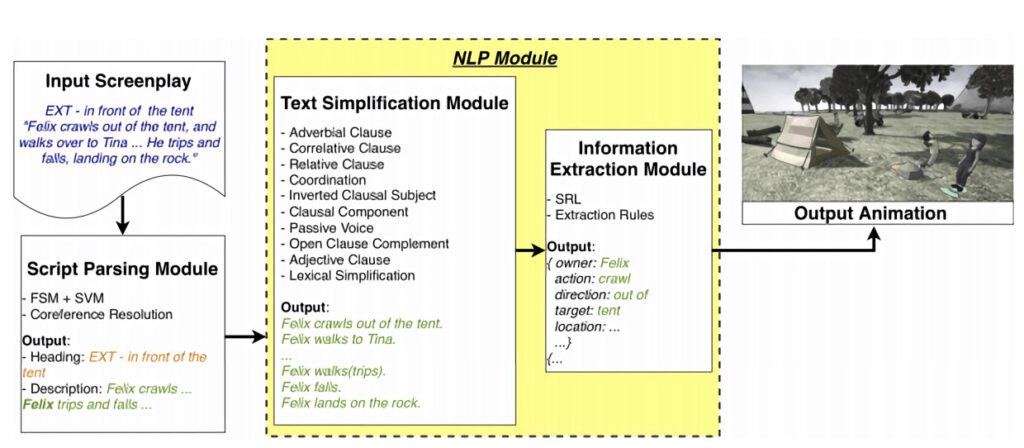
研究者らは、自由に入手できる映画の台本からシーンの説明を収集、整理した後、コーパスを作成しました。 これは、1,402,864 の文を含む 525,708 の記述で構成され、そのうち 920,817 には少なくとも 1 つのアクションが含まれています。
記述言語とビデオ間のマッピングを確立した後、スクリプトを入力することで簡単なアニメーション クリップを生成できます。テスト実験では、生成されたアニメーションの妥当性は 68% でした。
テクノロジーがより成熟していれば、適応プロセス中に発生する情報の逸脱は存在しなくなるでしょう。
2021年はアニメ『三体問題』でお待ちしております
これらの技術が「三体」アニメーション制作に活用されるまでにはまだ一定の距離があるが、これらの斬新なアイデアはアニメーション制作に新たな風をもたらすだろう。
現時点での観点からすれば、十分なデータとトレーニングがあれば、AI モデルがアニメーションの生成を学習できる日もそう遠くないはずです。
「Three-Body」アニメーションの話に戻りますが、Three-Body Universe と Yihua Kaitian の強力な制作チームと Bilibili の強力なサポートのおかげで、このアニメーションには多くのチップが追加されました。
2021年は雨でも晴れでもお待ちしております!

- 以上 -
