Command Palette
Search for a command to run...
ブレイン・コンピューター・インターフェースの分野における新たなマイルストーン: 思考が語り、機械が解釈する
ニューラル ネットワークを使用して、人が話すときに対応する脳領域で神経信号をデコードし、リカレント ニューラル ネットワークを使用して信号を音声に合成することは、言語障害を持つ患者が言語コミュニケーションの問題を解決するのに役立ちます。
「読心術」は本当に実現するかもしれない。
ほとんどの人にとって、話すことは普通のことです。しかし、世界には脳卒中、外傷性脳損傷、パーキンソン病、多発性硬化症、筋萎縮性側索硬化症(ALS またはルー・ゲーリッグ病)などの神経変性疾患に苦しんでいる人がたくさんいます。話す能力の喪失は元に戻せません。
科学者たちは人体の機能を回復し、神経を修復するために熱心に研究を続けており、ブレイン・コンピューター・インターフェース(BCI)は重要な分野です。
ブレイン コンピューター インターフェイスとは、人間または動物の脳と外部デバイスの間に作成される直接接続を指し、脳とデバイス間の情報交換を可能にします。
しかし、ブレイン・コンピュータ・インターフェースは常に遠い概念だったようです。本日、トップ学術誌「Nature」に論文が掲載されました。話された文章のニューラルデコードからの音声合成」(「話し言葉のニューラル復号化のための音声合成」)を読むと、ブレイン・コンピューター・インターフェースの分野の研究が大きく前進したことがわかります。
言語障害を持つ人々のジレンマ
実際、ブレイン・コンピューター・インターフェースの研究は40年以上も続けられています。しかし、これまでのところ最も成功し広く使用されている臨床応用は、人工内耳などの感覚回復技術のみです。
今日に至るまで、重度の言語障害を持つ人の中には、自分の考えを一言一句表現するために補助器具を使用している人もいます。
これらの支援装置は、非常に微妙な目や顔の筋肉の動きを追跡し、患者の動きに基づいて単語を綴ることができます。
物理学者のホーキング博士はかつてそのような装置を車椅子に取り付けました。

当時、ホーキング博士は赤外線で感知した筋肉の動きを頼りに命令を出し、コンピューターのカーソルで読み取った文字を確認し、思い通りの言葉を書いていた。その後、テキスト読み上げ装置を使用して単語を「読み上げ」ます。これらのブラックテクノロジーの助けを借りて、私たちは彼の著書「A Brief History of Time」を見ることができます。
しかし、そのような装置では、テキストや合成音声の生成は、手間がかかりエラーが発生しやすいだけでなく、非常に時間がかかります。通常、1 分あたり最大 10 ワードが許可されます。ホーキング博士は当時すでに非常に早口だったが、綴ることができたのは 15 ~ 20 単語だけだった。自然な音声は 1 分あたり 100 ~ 150 ワードに達します。
さらに、この方法は、オペレータ自身の身体運動能力によって大きく制限されます。
これらの問題を解決するために、ブレイン・コンピュータ・インターフェースの分野では、大脳皮質の対応する電気信号を音声に直接解釈する方法が研究されてきました。
ニューラルネットワークが脳信号を解釈して音声を合成する
現在、この問題はブレークスルーに達しています。
カリフォルニア大学サンフランシスコ校の脳神経外科教授エドワード・チャン氏らは、今回発表した論文「Speech Synthesis for Neural Decoding of Spoken Sentences」の中でこの手法を提案した。作成されたブレイン コンピューター インターフェイスは、人が話すときに生成される神経信号をデコードし、音声に合成することができます。このシステムは 1 分あたり 150 語を生成できますが、これは人間の通常の発話速度に近い速度です。

研究チームは、治療中のてんかん患者5人を募集し、数百の文章を声に出して話すように依頼し、同時に高密度脳波(ECoG)信号を記録し、脳の言語生成中枢である腹側の神経活動を追跡した。感覚運動野領域。
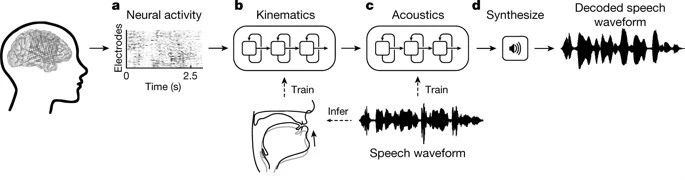
使用リカレント ニューラル ネットワーク (RNN)研究者らは収集した神経信号を2段階で解読した。
最初のステップ、彼らは神経信号を発声器官の働きを表す信号に変換し、顎、喉頭、唇、舌の動きに関連する脳信号が含まれます。
2 番目のステップでは、デコードされた発声器官の動きに基づいて、信号が話し言葉や文章に変換されます。

解読プロセスでは、研究者らはまず、患者が話したときに脳の 3 つの領域の表面にある連続的な電子写真信号を解読しました。これらの電子写真信号は侵襲的電極によって記録されました。
デコード後、調音器官の 33 個の運動特徴指標が取得され、これらの運動特徴指標は 32 個の音声パラメータ (ピッチ、発声などを含む) にデコードされ、最終的にこれらのパラメータに基づいて音声音波が合成されます。
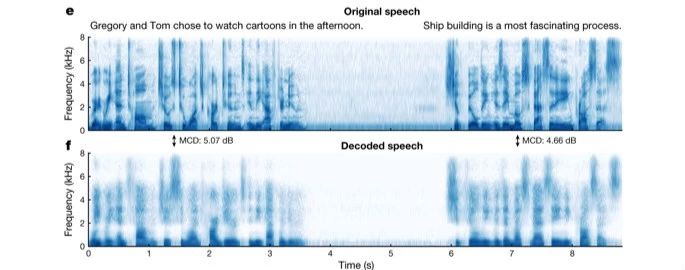
合成音声が実際の音声をどの程度正確に再現しているかを分析するために、研究者らは元の音声と合成音声の音響特性を比較し、ニューラルネットワークによってデコードされた音声が患者が説明した元の文章の個々の音素をかなり完全に再現していることを発見した。 、音素間の自然な接続と休止も同様です。
その後、研究者らはクラウドソーシングを利用して、ネチズンがデコーダーによって合成された音声を識別できるようにした。最終的に、聞き手は合成された音声コンテンツを再び話すことになります。成功率は70%に近いです。
さらに研究者らは、声を出さずに音声を合成するデコーダーの能力をテストした。試験者は最初に文を話し、次に同じ文を静かに(動きはありますが音は出さずに)暗唱します。結果は、黙読アクションに対してデコーダによって合成された音声スペクトルが、同じ文の音声スペクトルと類似していることを示しています。
マイルストーン: 課題と期待が共存する
「この研究は、個人の脳活動に基づいて完全な音声文を生成できることを初めて示しました。これは興味深いことです。これはすでに私たちの手の届くところにある技術であり、私たちはそれを構築できるはずです」とエドワード・チャン氏は語った。言語喪失患者のためのシステムは臨床的に実現可能な装置です。」
この論文の筆頭著者であるゴパラ・アヌマンチパリ氏は、「神経障害を持つ人々を支援するこの重要なマイルストーンの一環として、神経科学、言語学、機械学習の専門知識を提供できることを誇りに思う」と付け加えた。
もちろん、100%音声合成のブレイン・コンピューター・インターフェースによる音声インタラクションを真に達成するには、患者が電極を取り付ける侵襲的手術を受け入れることができるかどうか、実験での脳波が実際の患者の脳波と同じかどうかなど、まだ多くの課題があります。等
しかし、この研究からわかることは、音声合成の脳とコンピューターのインターフェイスは、もはや概念ではありません。
将来的には、言語障害を持つ患者ができるだけ早く「話す」能力を取り戻し、自分の感情を表現できるようになることが期待されています。


