Command Palette
Search for a command to run...
学校に戻らないでください、先生のルーチンはすべて賢いです。

超神経質で
今日は国際教師の日であり、友人の輪には教師へのあらゆる種類の祝福が溢れています。しかし、もし彼らが今の中学生の「悲惨な」生活環境を知っていたら、彼らがどう感じるかは分かりません。
最近、杭州第 11 中学校が試験導入した Smart Eye システムは、教室に複数のカメラを設置し、顔認識技術の助けを借りて授業中の生徒の表情や動作を 6 種類と 7 種類の教室行動を収集しました。生徒たちの教室での表情。

世間を騒がせたこの指導システムは「スマート教室行動管理システム」、略して「ウィズダム・アイズ」と呼ばれている。
学生を正確に捉えるという読む、立ち上がる、手を上げる、テーブルにもたれる、聞く、書くなど6つの行動を生徒の表情と組み合わせて分析中立、幸せ、悲しみ、怒り、怖がり、嫌悪感、驚き 7つの感情。
Intelligent Eyes - 授業中に小さなレポートを作成するのが好きな生徒
この情報をシステムが簡単に処理すると、Aとして授業をよく聞く、Bとして横になって寝る、Cとして質問に答えるといった一連のコードが生成され、これを使って生徒のステータスを判断します。授業をよく聞いているなどの条件が良い場合はポイントが増加し、授業中に寝ているなどの条件が悪い場合はポイントが減少します。
このデータは授業後に教師に直接送信されるため、教師は授業の効果や生徒の反応を理解できます。
教師はこれを使用して指導方法を最適化し、学校も教師の指導の質を判断するために使用できます。ただし、カメラの存在により生徒が多少不快になるのは当然のことです。
懸念されているプライバシーやデータ漏えいの問題については、このシステムで生成されたデータ情報を閲覧する権利を持つのは教師と学校幹部のみで、それ以外の教師や部外者は閲覧する権利を持たないという。

(上の赤丸が顔認証装置、下が情報を収集するカメラ)
ハードウェア部分は回転可能なカメラと顔認識装置で構成されており、各教室に 3 台ほどあり、30 秒ごとにスキャンされます。
すべてのカメラは行動情報を収集するためにのみ使用され、監視や記録には使用されません。プライバシーやデータ漏洩の問題はありません。
第 11 中学校では、今年度、すべての教室にこのシステムを導入する予定です。このシステムは、授業中の生徒の感情を観察できるだけでなく、顔認識を使用して出席状況を確認することもできます。ただし、このシステムはまだ初期段階にあり、感情認識の精度を向上させるために学習するためのより多くのデータが必要です。
将来的には、学校内のすべてのカードスワイプ活動を顔スワイプに置き換え、国内初のカードのないキャンパスを建設する予定です。これは隣のアリババの父親からインスピレーションを得たものなのでしょうか。
教室のモニタリングは良いことかもしれない
杭州第 11 中学校はハイテクをキャンパスに導入する最初の学校であるべきですが、私たちは同校が教育の質を向上させるために使用される感情認識をリアルタイムの監視ツールとして使用しないことも望んでいます。結局のところ、キャンパスが公共の場所であっても、すべての学生は一定の制限内である程度の個人的なプライバシーを保持する必要があります。
結局のところ、Smart Eye システムが注目され議論を集めている理由は、学生が監視されていると人々が感じているからです。しかし、一方で考えてみてください。フイヤン氏はデータは保存も公開もされないと主張していますが、実際には伝統的な意味での教師の目に似ています。
したがって、最も重要なことは「ユーザー同意書」です。学校が今明確にしなければならないのは、Huiyan のビデオコンテンツの使用方法と許可の範囲です。
感情認識の技術的実装
機械が人間の感情を認識できることは事実となっていますが、膨大なトレーニング データとモデル構築の複雑さは多くの研究者をひるませています。
今回、大手 5 名が軽量の感情認識モデルを開発しました。このモデルは、トレーニング セットの分類を自動的に完了できるだけでなく、モデルの構築プロセスも非常にシンプルで、感情認識モデル作成の敷居を大幅に下げます。
感情認識は画像認識や顔認識などの技術に基づいており、人の身体的行動(表情認識、音声、姿勢など)を分析することで人間の感情状態を識別します。

人間の顔の感情の多様性
感情認識用のニューラルネットワークは医療や顧客分析などの分野で広く使用されていますが、ほとんどの感情認識モデルはまだ人間の感情を深く理解することができず、そのようなモデルの構築は非常にコストがかかり、開発が困難です。
軽量の感情認識モデル、それについて学ぶ
この問題を解決するために、フランスのオレンジ研究所とカーン・ノルマンディー大学 (UNICAEN) の 5 人のエンジニアが共同で論文を発表しました。 「視聴覚感情の学習に関するオッカムのかみそりのような見解」。
彼らの論文では、オーディオビジュアル感情認識 (つまり、感情認識にオーディオとビデオを使用する) に基づいた軽量ディープ ニューラル ネットワーク モデルを提案しました。このモデルはトレーニングが容易で、トレーニング セットを自動的に分類でき、精度が高く、小さいトレーニング セットでも優れたパフォーマンスを実現するとされています。
この論文で提案されているモデルは次のとおりですオッカムの剃刀、AFEW データセットに基づいてトレーニングされました。複数の処理層 (それぞれ特徴抽出、分析などに使用) を通じて、音声とビデオの前処理と特徴分析が同時に行われ、最終的にこの 2 つを組み合わせて感情認識結果が出力されます。
「Acted Facial Expressions In The Wild」の略である AFEW は、感情認識モデルのトレーニングと EmotiW シリーズの感情認識チャレンジ用のテスト データを提供する表情認識データ コレクションです。
すべてのデータは、映画やテレビドラマの表情を編集したビデオクリップであり、「喜び、驚き、嫌悪、怒り、恐怖、悲しみ」の 6 つの基本的な表情と、中立的な表情が含まれています。
モデルが AFEW のトレーニング データをより適切に識別できるようにするために、5 人の開発者はモデルにいくつかの革新も加えました。
1) 転移学習と低次元空間埋め込みにより、特徴量の次元を削減し、モデル分析プロセスを簡素化します。
2) 画像の各フレームにスコアを付けてサンプリングを実行し、トレーニング セットのサイズを削減します。
3) 単純なフレーム選択メカニズムを使用して画像シーケンスに重みを付けます。
4) さまざまな形式の特徴融合が予測段階で実行されます。つまり、ビデオとオーディオが別々に処理されてから融合されます。
この一連のイノベーションにより、データセットの特性を特徴付けるパラメーターの数が大幅に削減されると同時に、モデルのトレーニング プロセスが簡素化され、感情認識の精度が向上します。 2018 年の感情認識コンテスト EmotiW (Emotion Recognition In The Wild Challenge) では、このモデルの認識精度は 60.64% に達し、4 位にランクされました。
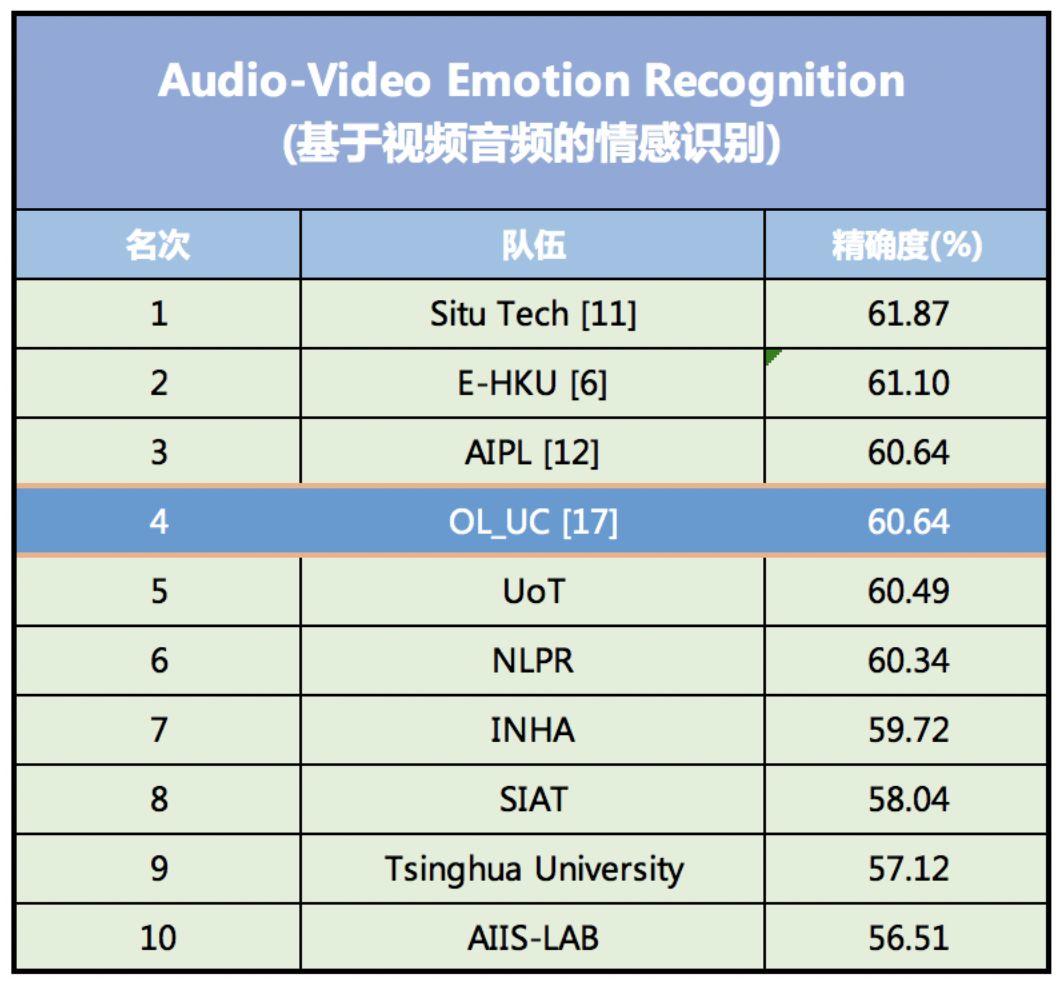
2018 EmotiW 視聴覚感情認識モデル精度ランキング、このモデルは 4 位にランクされました
このうち、トップの感情認識モデルは国内AI金融テクノロジー企業SEEK TRUTHが開発したもので、精度は61.87%だった。 2 位のモデルはカリフォルニアの AI スタートアップ企業 DeepAI によって開発され、精度は 61.10% でした。
モデルはトレーニング セットにラベルを自動的に追加できます
他の感情認識モデルと比較して、このモデルの最大の利点は、モデルの構築と訓練が非常に難しいことです。これにより、コンピューターがボディランゲージを含む人間の微表情を認識しやすくなります。
現在、ほとんどの感情認識モデルは、映画やテレビドラマの登場人物の表情を通じて学習されています。第一に、取得コストが低く、第二に、表現が豊富です。

ただし、これらのデータはトレーニングセットに入力される際には分類されていない(つまり、各ビデオに感情ラベルが追加されている)ため、トレーニング前に手動または他の方法で分類する必要があります。トレーニングセットの歪みを容易に引き起こす可能性があります。
Frédéric Jurie らが開発した視聴覚感情認識モデルは、モデルで使用するためにディープ ニューラル ネットワークを通じてトレーニング セット内の表現を自動的に分類できます。
これにより、モデルのトレーニングの難易度が軽減されると同時に、認識精度も向上します。
このモデルは、今日のますます複雑化するニューラル ネットワーク モデルとは対照的に、軽量のニューラル ネットワーク モデルが良好な結果を達成でき、トレーニングが容易であることも証明しています。
将来的には、ビデオ以外の形式のデータをより適切に統合し、カテゴリが少ない、またはカテゴリがまったくないデータを識別する方法をさらに調査する予定です。
