Command Palette
Search for a command to run...
David Baker 氏のチームは、大きなアップデートを発表しました。RFantibody により、特定のターゲットに対するカスタマイズされた抗体の開発が可能になり、VisualOverload により、視覚的理解の限界が押し広げられ、複雑なシーンの推論における新たな進歩がもたらされます。

抗体は現在のタンパク質治療薬の主力です。世界では160種類以上の抗体医薬品が承認されており、今後5年間で市場規模は4,450億米ドルに達すると予想されています。しかし、治療用抗体の開発は依然として主に動物の免疫化や大規模な抗体ライブラリからの候補分子のスクリーニングに依存しています。これらの方法は、時間と労力がかかるだけでなく、標的の特定のエピトープに一致する新しい抗体を正確に設計することが困難になることもよくあります。
これに基づいて、David Baker 氏のチームは、RFdiffusion に基づいて細かく最適化された新世代の抗体およびナノ抗体設計ツール RFantibody をリリースしました。このツールは、研究者やバイオテクノロジー技術者に効率的な de novo 設計手法を提供するために設計されており、ディープラーニングを使用して抗体構造 (特に CDR 領域) を生成し、ProteinMPNN を使用して配列を設計し、RF2 (RoseTTAFold2) を使用してそれらが予想される構造に折り畳まれることを確認します。
RF抗体は効率的なタンパク質設計ツールとして、生物医学研究、医薬品開発、ワクチン設計などの分野で広く使用されており、生物医学研究に新たなツールを提供しています。
HyperAI公式サイトにて「RFantibody:抗体・ナノボディ設計ツール」を公開しました。ぜひお試しください!
オンラインでの使用:https://go.hyper.ai/sO07A
9月15日から9月19日までのhyper.ai公式サイトの更新内容を簡単にご紹介します。
* 高品質の公開データセット: 10
* 質の高いチュートリアルの選択: 7
* 今週のおすすめ論文:5
* コミュニティ記事の解釈:5件
* 人気のある百科事典のエントリ: 5
* 9月に締め切りを迎えるトップカンファレンス:1
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
1. ConstructionSite 建設現場画像データセット
ConstructionSiteは、建設現場のシナリオを対象としたマルチモーダルベンチマークデータセットです。建設安全環境における視覚言語モデルの画像理解・推論能力を評価・向上するために設計されています。このデータセットは、複雑なシーンと多様なアノテーションを備え、実際の建設安全検査に近いデータで構成されています。画像キャプション作成、視覚的な質問応答、物体検出、視覚的自己位置推定、マルチモーダル推論といったタスクに適しています。
直接使用: https://go.hyper.ai/ZRy12
2. HTSC-2025大気圧高温超伝導ベンチマークデータセット
HTSC-2025は、常圧高温超伝導体の臨界温度を予測するためのベンチマークデータセットです。モデルに標準化され比較可能な試験サンプルを提供することで、超伝導予測の進歩と検証を促進することを目的としています。このデータセットは約140種類の物質を含み、処理しやすいようにJSON/Parquet形式で保存されています。
直接使用: https://go.hyper.ai/G2bJB
3. VisualOverload シーン画像理解データセット
VisualOverloadは、シーン画像理解を評価するためのデータセットです。複雑なシーンの詳細を外部知識に依存せずに視覚的に理解し、推論するモデルの能力をテストするために設計されています。このデータセットには、複数の登場人物、アクション、サブプロット、複雑な背景が描かれていることが多い、高解像度のパブリックドメインの絵画から構成される2,720の質問と回答のペアが含まれています。
直接使用: https://go.hyper.ai/Acce1

4. WebExplorer-QA情報検索質問応答データセット
WebExplorer-QAは、情報検索およびウェブ閲覧タスクのためのデータセットです。複雑な多段階推論と長距離ウェブナビゲーションにおけるモデル性能の向上を目指し、難易度の高いクエリと回答のペアを体系的に生成します。情報検索、マルチホップ/複雑な文脈推論、長文脈プロンプト処理、ツール呼び出し、ウェブナビゲーションといったネットワークエージェントや大規模言語モデルの学習と評価に適しています。
直接使用する:https://go.hyper.ai/I58Ry
5. AnonyRAG 古典小説質問応答データセット
AnonyRAGは、テンセントYoutuラボ、モナシュ大学、香港理工大学によって公開された、エンティティ匿名化タスクのための質問応答データセットです。エンティティが匿名化された場合、検索拡張生成(RAG)システムが証拠を得るために検索に依存しているかどうかを評価することを目的としています。
直接使用: https://go.hyper.ai/jzqD9
6. RxnBench有機化学質問応答データセット
RxnBenchは、マルチモーダル化学反応画像理解のための視覚的質問応答データセットです。化学反応画像理解、マルチモーダル推論、科学的質問応答といったタスクにおける視覚言語モデルの能力を評価することを目的としています。このデータセットには、有機化学反応理解に関する多肢選択式問題が1,525問収録されており、中国語と英語の両方で利用可能です。
直接使用: https://go.hyper.ai/Utkdo
7. SceneSplat-7K 屋内シーン 3D レンダリング データセット
SceneSplat-7は、屋内シーンを対象とした最大規模かつ最高品質の3Dガウススプラット(3DGS)データセットです。実際の屋内3Dシーンにおける視覚言語事前学習済みモデルの理解および意味的推論能力の向上を目指しています。
直接アクセス: https://go.hyper.ai/HISAa
8. SSTQA 半構造化表形式質問応答データセット
SSTQAは、上海交通大学がサイモンフレーザー大学、清華大学などの機関と共同で公開した、半構造化表形式の質問応答タスクのベンチマークデータセットです。このデータセットは、実際の表の複雑なレイアウト(結合セル、階層型ヘッダー、多階層ネストなど)に対する大規模言語モデルと表形式の質問応答システムの理解能力と回答能力をテストすることを目的としています。
直接使用: https://go.hyper.ai/JoZyB
9. OmniSpatial パノラマ空間推論ベンチマークデータセット
OmniSpatialは、パノラマ空間推論のための包括的かつ挑戦的な標準化ベンチマークデータセットであり、視覚言語モデルにおける空間理解の評価におけるギャップを埋めるために設計されています。特にインテリジェントナビゲーション、拡張現実/仮想現実、複雑なシーン理解といったアプリケーションにおいて、大規模なマルチモーダルモデルの空間推論能力のトレーニングと評価に適しています。
直接使用: https://go.hyper.ai/a6ep8
10. 都市問題 都市問題画像データセット
Urban Issuesは、自動ビジョンシステムやマシンビジョンシステムが都市環境における公共インフラや環境問題を識別できるように設計された、公開画像分類データセットです。このデータセットの画像はカテゴリ別に整理されており、各画像には単一のクラスがラベル付けされ、さまざまな背景、照明、視野角条件下で提示されています。
直接使用: https://go.hyper.ai/2id2J

選択された公開チュートリアル
1. HiDream-E1.1: コマンドベースの画像エディタ
HiDream-E1.1モデルは、Zhixiang Futureがリリースしたオープンソースの画像編集モデルです。独自のSparse Diffusion Transformerアーキテクチャに基づき、メガピクセル解像度をサポートし、MITオープンソースライセンスの下でライセンスされています。このモデルは、「話す、変える」という自然言語による画像編集機能を実装しています。ユーザーは、専門的なソフトウェアスキルを必要とせず、シンプルな言語コマンドで、色調整、スタイルの転送、要素の追加と削除といった複雑なタスクを実行できます。
オンラインで実行: https://go.hyper.ai/P9C3R
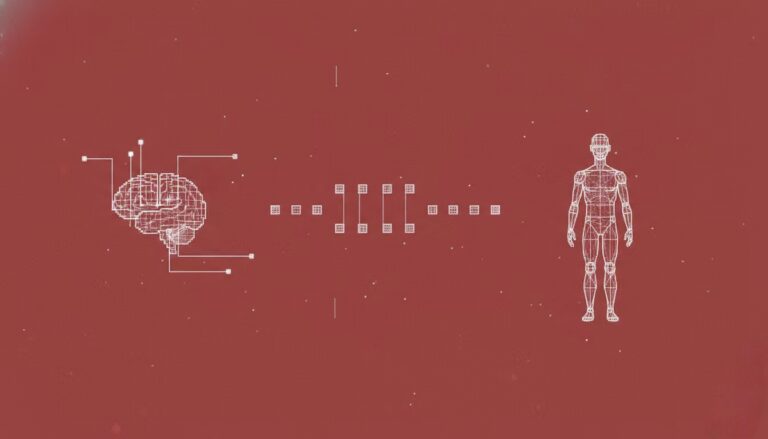
2. RFantibody: 抗体およびナノボディ設計ツール
RFdiffusion2は、David Baker氏のチームによって開発された抗体およびナノボディ設計ツールです。研究者やバイオテクノロジーエンジニアに効率的なde novo設計アプローチを提供することを目的としています。このツールの中核となるのは、ディープラーニング技術を活用し、抗体の構造情報を用いて3次元構造とアミノ酸配列を予測・設計することで、特定の標的を標的とするカスタマイズされた抗体の開発を可能にすることです。
オンラインで実行: https://go.hyper.ai/sO07A
3. FastVLM: 超高速視覚言語モデル
FastVLMは、Appleチームによって開発された高効率なビジュアル言語モデル(VLM)です。高解像度画像処理の効率とパフォーマンスを向上させます。このモデルには、新しいハイブリッドビジョンエンコーダFastViTHDが組み込まれており、ビジュアルトークンの数を効果的に削減し、エンコード時間を大幅に短縮します。
オンラインで実行: https://go.hyper.ai/xg8wa
4. SEED-X-PPO-7B: 強化学習による多言語翻訳モデルの最適化
SEED-X-PPO-7Bは、ByteDance Seedチームがリリースした次世代多言語翻訳モデルです。近似ポリシー最適化(PPO)強化学習アルゴリズムを用いた反復最適化に基づき、言語間シナリオにおける高精度な意味転移のニーズに応えることを主な目標としています。このモデルは、少数言語への適応、文化的文脈の復元、長文テキストの一貫性確保といった従来の翻訳モデルの限界を克服し、中国語、英語、ドイツ語を含む28の主要言語間の翻訳をサポートします。
オンラインで実行: https://go.hyper.ai/aw5oS
5. SRPO: AI スタイルの画像生成に別れを告げましょう。
SRPOは、テンセント・フンユアン・チーム、香港中文大学深圳校理学院、清華大学深圳国際大学院が共同で開発したテキスト画像生成モデルです。報酬信号をテキスト条件付き信号として設計することで、報酬のオンライン調整が可能になり、オフラインでの報酬微調整への依存を軽減します。
オンラインで実行: https://go.hyper.ai/8OQxS

6. ERNIE-4.5-21B-A3B-Thinking: 軽量モデル推論機能のアップグレード
ERNIE-4.5-21B-A3B-Thinkingは、百度文心易言チームがリリースした推論モデルの軽量版「思考バージョン」です。このモデルは、専門家混合(MoE)アーキテクチャを採用し、総パラメータサイズは21Bで、各トークンは3Bのパラメータをアクティブ化します。命令の微調整と強化学習によって訓練されます。
オンラインで実行: https://go.hyper.ai/bQmlo
7. RFdiffusion2: タンパク質設計ツール
RFdiffusion2は、ワシントン大学タンパク質設計研究所が公開したディープラーニングによるタンパク質設計モデルです。このモデルは、シンプルな化学反応記述に基づいてカスタマイズされた活性部位を持つ酵素骨格を生成するだけでなく、触媒設計における従来の技術的ボトルネックを大幅に克服し、プラスチック分解などの重要なアプリケーションに強力な技術サポートを提供します。
オンラインで実行: https://go.hyper.ai/9YInD
💡安定拡散チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] にメモし、グループに参加してさまざまな技術的な問題について話し合い、アプリケーションの効果を共有してください。

今週のおすすめ紙
1. OmniWorld: 4D世界モデリングのためのマルチドメイン・マルチモーダルデータセット
本稿では、4次元世界のモデリングを目的として設計された大規模、マルチドメイン、マルチモーダルなデータセット「OmniWorld」を紹介します。このデータセットは、新たに収集されたOmniWorld-Gameデータセットと、厳選された公開データセットで構成されており、様々な応用シナリオを網羅しています。
論文リンク: https://go.hyper.ai/SbW2Y
2. WebWeaver: オープンエンドの深い研究のための動的なアウトラインによるWeb規模の証拠の構造化
本論文では、人間の研究プロセスを模倣するように設計された、新しいデュアルエージェントフレームワーク「WebWeaver」を提案する。プランニングエージェントは動的なループ構造で動作し、エビデンスの収集とアウトラインの精緻化を反復的に織り交ぜることで、エビデンスメモリに接続された包括的でソースベースの構造化されたアウトラインを作成する。その後、ライティングエージェントは階層的な検索とライティングプロセスを実行し、セクションごとにレポートの構築を完了する。
論文リンク: https://go.hyper.ai/lqMvM
3. 継続的な事前トレーニングによるエージェントのスケーリング
本論文では、堅牢なエージェントベースモデルの構築を目指し、ディープラーニングエージェントの学習プロセスにエージェント継続事前学習(Agentic CPT)を統合することを初めて提案しています。このアプローチに基づき、研究者らはAgentFounderと呼ばれるディープラーニングエージェントモデルを開発しました。
論文リンク: https://go.hyper.ai/6lyWG
4. WebSailor-V2: 合成データとスケーラブルな強化学習による独自エージェントとのギャップの解消
本論文では、構造化サンプリングと情報ファジー化によって、不確実性の高い新規タスクを生成する包括的な学習後手法「WebSailor」を提案する。この手法は、RFTコールドスタート戦略を採用し、高効率なエージェントベース強化学習学習アルゴリズムである繰り返しサンプリングポリシー最適化(DUPO)と組み合わせる。この統合プロセスにより、WebSailorは複雑な情報検索タスクにおいて既存のオープンソースエージェントを大幅に上回り、プロプライエタリエージェントの性能に迫り、能力差を効果的に縮める。
論文リンク: https://go.hyper.ai/biWLb
5. Hala 技術レポート: アラビア語中心の教育・翻訳モデルの大規模構築
本稿では、アラビア語を中心とした教育・翻訳モデル群であるHalaを紹介します。独自の翻訳微調整パイプラインを基盤とするHalaは、アラビア語のコアベンチマークにおいて、「ナノ」(20億パラメータ以下)と「スモール」(70億~90億パラメータ)の両カテゴリで最先端のパフォーマンスを達成し、ベースラインモデルを大幅に上回ります。
論文リンク: https://go.hyper.ai/KI73S
AIフロンティアに関するその他の論文:https://go.hyper.ai/iSYSZ
コミュニティ記事の解釈
1. IJCAI 2025 | 7データセット検証:scSiameseCluは教師なし単一細胞クラスタリングタスクでSOTAパフォーマンスを達成
中国科学院、東北農業大学、マカオ大学、吉林大学の研究チームは共同で、シングルセルRNA-seqデータの解釈に用いる新たなツインクラスタリングフレームワーク「scSiameseClu」を提案しました。scSiameseCluは、表現の崩壊の問題を効果的に軽減し、より明確な細胞集団の分類を実現し、scRNA-seqデータ解析のための強力なツールを提供します。
レポート全文はこちら:https://go.hyper.ai/hyDFA
2. オンラインチュートリアル | Tencent Hunyuan-MT-7BがACL機械翻訳コンテストで30言語で優勝、33言語をサポート
2025年9月、テンセントのHunyuanチームは軽量翻訳モデルHunyuan-MT-7Bをリリースしました。このモデルは33言語と5つの華人系言語・方言間の翻訳に対応し、わずか70億個のパラメータで効率的かつ正確な翻訳を実現しています。計算言語学会(ACL)のWMT2025コンペティションでは、このモデルは31言語部門のうち30言語部門で1位を獲得し、驚異的なパフォーマンスを達成しました。
レポート全文はこちら:https://go.hyper.ai/y2X2L
3. 400%により精度が向上!インドモンスーン予測モデルは36の気象観測所に基づいており、都市レベルでの詳細な予測が可能になりました。
近年、ムンバイでは異常降雨の頻度と強度が著しく増加しています。従来の地球規模の予測システムは解像度が不十分なため、局所的な気象パターンを捉えることが困難です。この問題に対処するため、インド工科大学(IIT)ボンベイ校はメリーランド大学と共同で、畳み込みニューラルネットワークと転移学習に基づく予測モデルを開発し、異常降雨の早期予測を可能にしました。
レポート全文はこちら:https://go.hyper.ai/wYsSk
4. トレーニング費用は294,000ドルでした。DeepSeek-R1はNature誌の表紙を飾り、権威ある学術誌の査読を通過した初の主流の大規模モデルとなり、好評を博しました。
DeepSeek-R1の研究成果はNature誌の表紙を飾り、世界中の学術界で熱い議論を巻き起こしました。Nature誌への掲載の意義は、この権威あるジャーナルによる査読にあります。
レポート全文はこちら:https://go.hyper.ai/B12hL
5. Google DeepMind は、AI を使用して 3 つの流体方程式における新たな不安定な特異点を発見し、ミレニアム賞獲得に向けて新たな進歩を遂げました。
Google DeepMindは、ニューヨーク大学、スタンフォード大学、ブラウン大学などの研究機関の研究者と協力し、機械学習フレームワークと高精度のガウス・ニュートン最適化装置に基づいて、初めて3つの異なる流体方程式における新たな不安定特異点を体系的に発見し、爆発率と不安定性順序を結び付ける単純な経験的漸近式を明らかにした。
完全なレポートを見る: https://go.hyper.ai/hq5og
人気のある百科事典の項目を厳選
1. DALL-E
2. 相互ソート融合RRF
3. パレートフロント
4. 大規模マルチタスク言語理解MMLU
5. 対照学習
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。

主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!
HyperAIについて Hyper.ai
HyperAI(hyper.ai)は、中国をリードする人工知能とハイパフォーマンス・コンピューティングのコミュニティである。国内データサイエンス分野のインフラとなり、国内開発者に豊富で質の高い公共リソースを提供することに注力しています。
* 1800以上の公開データセットの国内高速ダウンロードノードを提供
* 600以上の古典的で人気のあるオンラインチュートリアルが含まれています
* 200 以上の AI4Science 論文ケースを解釈
* 600 以上の関連用語クエリをサポート
*Apache TVM の最初の完全な中国語ドキュメントを中国でホストします
学習の旅を始めるには、公式 Web サイトにアクセスしてください。