Command Palette
Search for a command to run...
「ブラインドスクリーニング」から「正確なポジショニング」まで、AlphaPPIMI フレームワークは一般化機能を大幅に向上させ、PPI インターフェースレギュレーターの予測パフォーマンスは既存の方法を上回ります。

生命の複雑な制御ネットワークにおいて、タンパク質間相互作用(PPI)は細胞内シグナル伝達、エネルギー代謝、そして遺伝子活性を調整し、正常な生命維持の基盤となっています。PPIは、健康状態における生理学的恒常性と、疾患時に生じる異常な変化の両方を維持する上で中心的な役割を果たしています。研究により、PPIの機能不全は、がん、神経変性疾患、そして様々な感染症と密接に関連していることが示されています。そのため、PPIを標的とした薬剤の開発は、新薬研究開発の重要な分野となっています。
初期の科学者は、MDM2-p53 などのタンパク質間の相互作用を研究し、そのような相互作用に介入することで疾患を治療できる可能性、特にこれまで標的とするのが困難だった疾患の標的に対する新しいアイデアを提供できることを確認しました。しかし、PPI の特殊性は、その相互作用界面が通常比較的平坦であり、小分子薬剤の埋め込みに適した明確な構造的特徴を欠いていることであり、これが薬剤開発に大きな課題をもたらしています。特に、新しく発見されたPPIや構造情報が限られているPPIの場合、その機能を制御できる分子を見つけるのはさらに困難です。
研究者たちは、PPIの界面は広く平坦であるにもかかわらず、「ホットスポット」と呼ばれる重要な領域がいくつか存在することを発見しました。これらの領域は相互作用において「スイッチ」のように機能し、医薬品設計の理想的なターゲットとなります。
人工知能技術、特に機械学習と深層学習の急速な発展により、PPIの医薬品開発プロセスは飛躍的に加速しました。潜在的なPPI阻害薬を効率的に同定する2P2IHUNTER、大規模な仮想スクリーニングを可能にするPPIMpred、制御分子を予測するだけでなく、COVID-19研究における実用的価値も示すSMMPPIなど、様々な革新的なアルゴリズムとツールが登場しています。しかし、大きな進歩にもかかわらず、課題は依然として残っています。類似性スクリーニングに大きく依存する従来の計算手法では、PPIインターフェースの複雑な相互作用特性を完全に捉えることが困難です。さらに、既存のモデルは異なるタンパク質タイプ間での一般化能力に限界があり、新規標的に対する医薬品開発の効率化を妨げています。
近年、Transformerベースの事前学習済み言語モデルが、上記の問題に対する新たなアイデアを提供してきました。これらのモデルは、多数のタンパク質配列から主要な特徴を自動的に学習し、よりインテリジェントに相互作用を予測することができます。
この方向性に基づき、中国石油大学と延世大学の共同研究チームは、複数の先進技術を統合し、AlphaPPIMIと呼ばれる新しいフレームワークを構築しました。このツールは、大規模な事前トレーニング済みモデルと適応型学習メカニズムを組み合わせて、「PPI インターフェースを特にターゲットとする調節因子を発見する」という中心的な課題に対処します。事前トレーニング済みの大規模モデルの利点を最大限に活用し、専用のクロスアテンションモジュールを通じて複雑な結合パターンを効果的にモデル化することで、さまざまな PPI ファミリーにわたるモデルの一般化能力が大幅に向上し、将来の PPI 標的薬の開発を強力にサポートします。
関連する研究結果は、「Alphappimi: PPI-モジュレーター相互作用を予測するための包括的なディープラーニングフレームワーク」というタイトルでJournal of Cheminformaticsに掲載されました。

用紙のアドレス:
https://jcheminf.biomedcentral.com/articles/10.1186/s13321-025-01077-2
公式アカウントをフォローし、「AlphaPPIMI」と返信すると、完全なPDFを入手できます。
AIフロンティアに関するその他の論文:
https://hyper.ai/papers
データセット: DLiPを中核としたPPIデータセットシステムの構築
この研究では、120 個の PPI とそれに対応する 12,605 個の固有の調節因子を含む DLiP データセットをトレーニング コアとして使用しました。また、タンパク質複合体の各ペアの配列、三次元構造、実験活性データも提供し、モデル構築を全面的にサポートします。
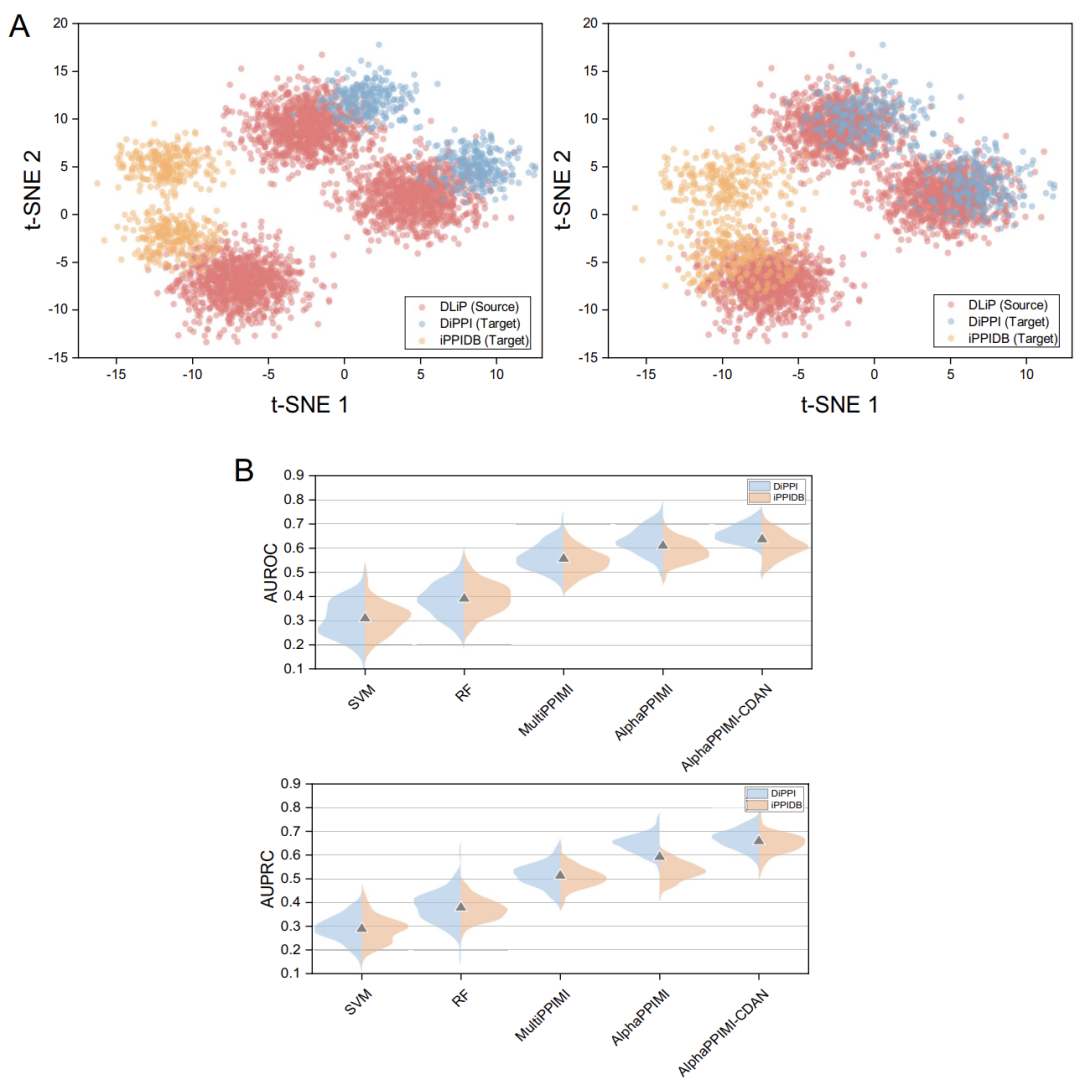
独立した検証を行うため、研究チームはDiPPIデータベースとiPPIDBデータベースから2つのベンチマークテストセットを構築しました。どちらのセットにも、実験的に検証されたインターフェースモジュレーターとその構造および結合情報が含まれています。データの収集にあたっては、3つの品質管理を実施しました。ヘテロ二量体PPIのみを保持すること、結合部位が不明瞭なサンプルを除外すること、そして対象をヒトPPIに限定することです。さらに、複数の標的に作用する化合物は、正確なアノテーションを保証するために分離しました。
2 つのベンチマーク セットの最終的な詳細は次のとおりです。DiPPI には、1,316 個の PPI ターゲットに対応する 201 個のレギュレーターが含まれています。各サンプルには分子構造、タンパク質配列、インターフェース構造、アクティブ タグが含まれます。iPPIDB は 2,203 個の調節因子と 34 個の PPI をカバーし、すべてのタンパク質配列は UniProt データベースからのものであるため、データの一貫性が保証されます。
2 つのベンチマーク セットの物理的および化学的特性を分析した結果、インターフェイスのターゲット特性と化学空間分布が大きく異なり、モデルの一般化の難易度が増すことが判明しました。ECFP4 分子フィンガープリントを計算すると、2 つのベンチマーク セット内の化合物の平均 Tanimoto 類似度が非常に低いこともわかりました。これは、これらの化合物の構造的多様性が比較的高いことを示しています。
本研究では、特定のPPIファミリーについて、他のPPIファミリーに選択的な調節因子を潜在的な不活性サンプルとして選択し、既知の活性調節因子と類似の構造を持つ分子を除外することで偽陰性のリスクを低減しました。陽性サンプルと陰性サンプルの数の不均衡を考慮し、研究チームは陰性サンプルをダウンサンプリングして、バランスの取れた数でデータセットを構築しました。その後の感度分析では、陽性サンプルと陰性サンプルの比率をどのように調整しても、モデルのパフォーマンスは非常に安定しており、比率に大きく依存しないことが示されました。検証済みの不活性化合物も存在しますが、それらは不均一に分布しており、含めることでデータバイアスを引き起こす可能性があるため、陰性サンプルセットには含めませんでした。
この方法の実用的応用価値を検証するために、研究チームはまた、ChemDiv データベースの「PPI 固有のライブラリ」をスクリーニングしました。このライブラリには、PPI の界面特性に合わせて特別に設計された 205,497 個の化合物が含まれています。この大規模な仮想スクリーニングにより、医薬品開発シナリオにおけるこの方法の実用性が実証されました。
AlphaPPIMIフレームワーク: マルチソース特徴抽出、双方向クロスアテンション、CDAN一般化最適化
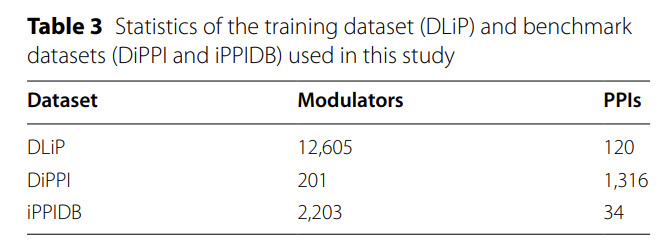
以下の図に示すように、この研究では、PPI と調節因子の結合関係を予測するための新しい計算フレームワーク、AlphaPPIMI が開発されました。このフレームワークは、インターフェース結合部位での相互作用をターゲットにすることに特に重点を置いて、Uni-Mol2、ESM2、ProTrans、ECFP、PFeature などの複数の高度なモジュールを統合し、効率的な表現学習を実現しながら PPI 関連の機能を包括的に抽出することを目指しています。
分子特性評価の段階では、研究チームは8400万のパラメータを持つUni-Mol2モデルを使用して、原子、化学結合、幾何学情報、分子指紋を統合しました。各モジュレーターについて768次元のグローバル特徴ベクトルが生成されました。研究チームはECFP4フィンガープリントも組み込んで、環状部分構造などの重要な化学情報を捕捉するための1,024次元のバイナリベクトルを生成しました。最終的に、これら2種類の特徴を組み合わせることで、分子トポロジー、3Dジオメトリ、化学部分構造を網羅する1,792次元の特徴ベクトルが生成され、界面結合予測のための信頼性の高いデータサポートが提供されました。
タンパク質の特徴抽出では、次の 3 つの補完的なアプローチが使用されます。Transformerアーキテクチャに基づくESM2-150Mモデルは、6,000万のUniRef50配列で学習され、界面形成に関連するアミノ酸配列の関係を特に捉えた640次元の特徴ベクトルを生成します。4,500万以上のタンパク質配列で学習されたProtTransモデルは、ESM2を補完する進化パターンを捉えた1,024次元の埋め込みベクトルを出力します。最後に、PFeature法は、19のカテゴリーの記述子を通じて、タンパク質の構造と物理化学的特性に関する情報を提供します。これら3つの手法を融合することで、タンパク質配列パターンと界面特有の特性を包括的にカバーする3,366次元のタンパク質表現が生成されます。
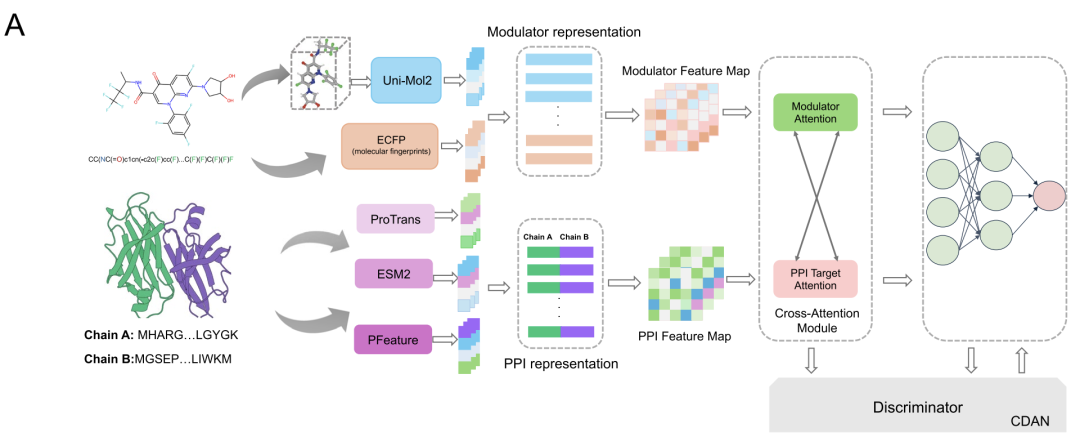
AlphaPPIMIは、タンパク質と調節因子間の複雑な相互作用をモデル化するために、下図に示す双方向のCross-Attentionモジュールを設計しました。このモジュールは、まず調節因子特徴行列FMとターゲット特徴行列FPに対して線形変換を行い、それらをAttentionサブモジュールに入力することで、キー値レベルでの双方向の情報交換を可能にします。PPI特徴は調節因子ソースのAttention重みを用いて最適化され、調節因子特徴はPPI駆動型Attentionメカニズムを用いて調整されます。残余接続と最大プーリング操作もモジュールに追加されます。各モダリティの固有情報を保持しながら、2 つのモダリティ間のインタラクション パターンを動的に学習し、最終的にインタラクションのより包括的な表現を出力できます。
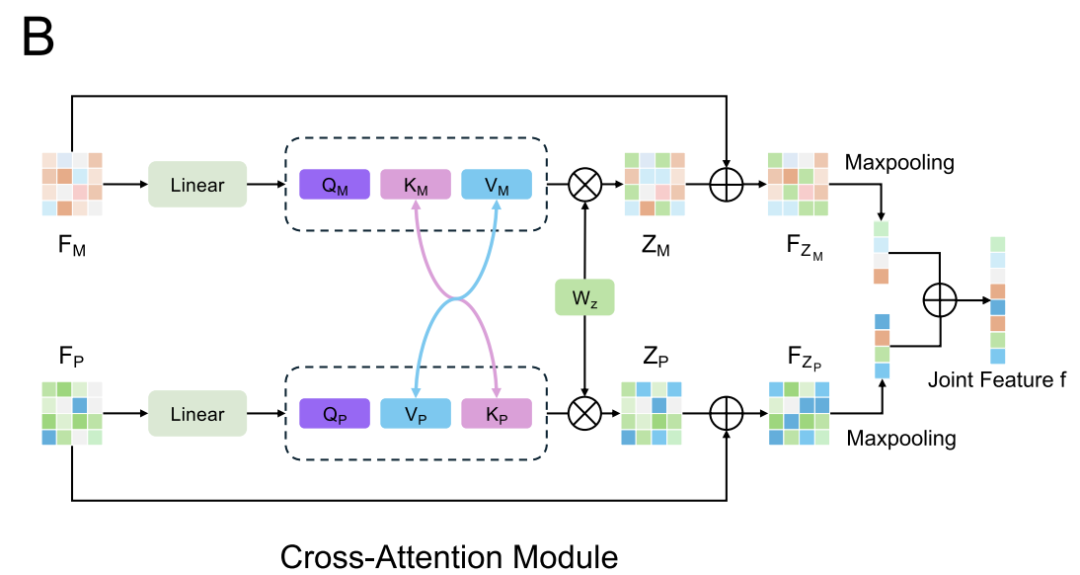
データセット間での特徴分布の違い(例えば、DiPPIはインターフェースをターゲットとしたモジュレーターに焦点を当てているのに対し、DLiPのような一般的なデータセットにはそのような情報が欠けている)を考慮し、AlphaPPIMIでは条件付きドメイン敵対ネットワーク(CDAN)も導入しています(下図参照)。CDANは、ドメイン識別器の条件として「特徴埋め込みと分類予測の結合表現」を用いることで、識別特徴を保持しながら、ソースドメインとターゲットドメイン間の分布整合を実現します。トレーニング プロセスでは、ミニマックス ゲームが採用されています。つまり、特徴エンコーダーとクロス アテンション モジュールはドメイン不変の表現を生成する役割を担い、識別器は特徴のソースを区別するために使用されます。このメカニズムにより、さまざまなタンパク質ファミリーにわたるモデルの一般化能力が大幅に向上し、新しいインターフェースをターゲットとした調節因子を特定するためのより堅牢なサポートが提供されます。
AlphaPPIMIのクロスドメイン一般化能力の評価と応用検証
PPI 調節因子の予測における AlphaPPIMI のドメイン間適応性をテストするために、研究チームは移行実験を設計しました。DLiP データセットは「ソース ドメイン」(モデルのトレーニングに使用されるデータ)と見なされ、DiPPI および iPPIDB データセットは「ターゲット ドメイン」(モデルの検証に使用されるデータ)と見なされます。
実験結果によると、ドメインシフトによってすべてのモデルのパフォーマンスは低下しますが、AlphaPPIMI はより堅牢です。DiPPIにおけるAUROCとAUPRCは、MultiPPIMIを大幅に上回っています。ドメイン間性能とドメイン内性能の差は、ドメイン適応戦略の必要性を浮き彫りにしています。下図に示すように、本研究ではさらに、条件付き特徴量アライメントによってドメイン間分布適応を実現するAlphaPPIMI-CDANアーキテクチャを提案しました。このモデルは、DiPPIおよびiPPIDBにおいてベースラインモデルを総合的に上回ります。従来のエッジアライメント手法とは異なり、この手法はカテゴリ条件付き分布に基づいて特徴量アライメントを誘導し、より識別性の高い表現を生成します。PPIドメインにおける微妙な機能差によって引き起こされる分布シフトに効果的に対処し、負の転移を緩和することで、ドメイン間予測の堅牢性と汎化性を向上させます。
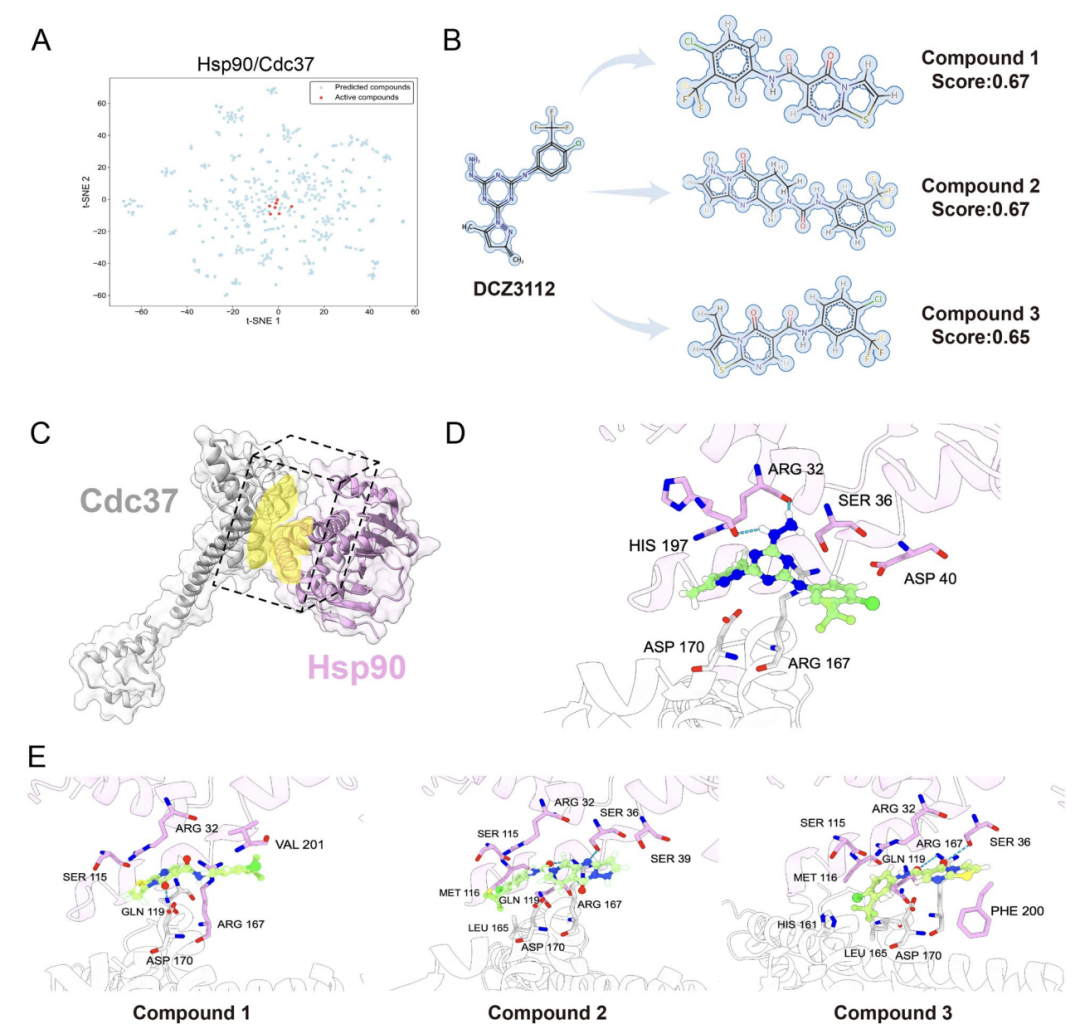
実用化検証では、明確な界面構造を持ち、抗がんの重要な標的であるHsp90-Cdc37 PPIも研究対象とした。下の図 A に示すように、AlphaPPIMI は ChemDiv ライブラリ内で予測スコアが 0.8 を超える化合物をスクリーニングしました。この化合物の化学空間は、既知の活性阻害剤の分布に近いものでした。下の図 B に示すように、研究者は検証済みの阻害剤 DCZ3112 を参照として使用し、構造類似性およびファーマコフォア分析によって 3 つの候補化合物をスクリーニングしました。下の図 D ~ E に示すように、分子ドッキングにより、これらの化合物は Arg32 や Ser36 などの主要な残基を持つ参照分子と同様の相互作用を形成でき、阻害能を高めることができることが示されました。
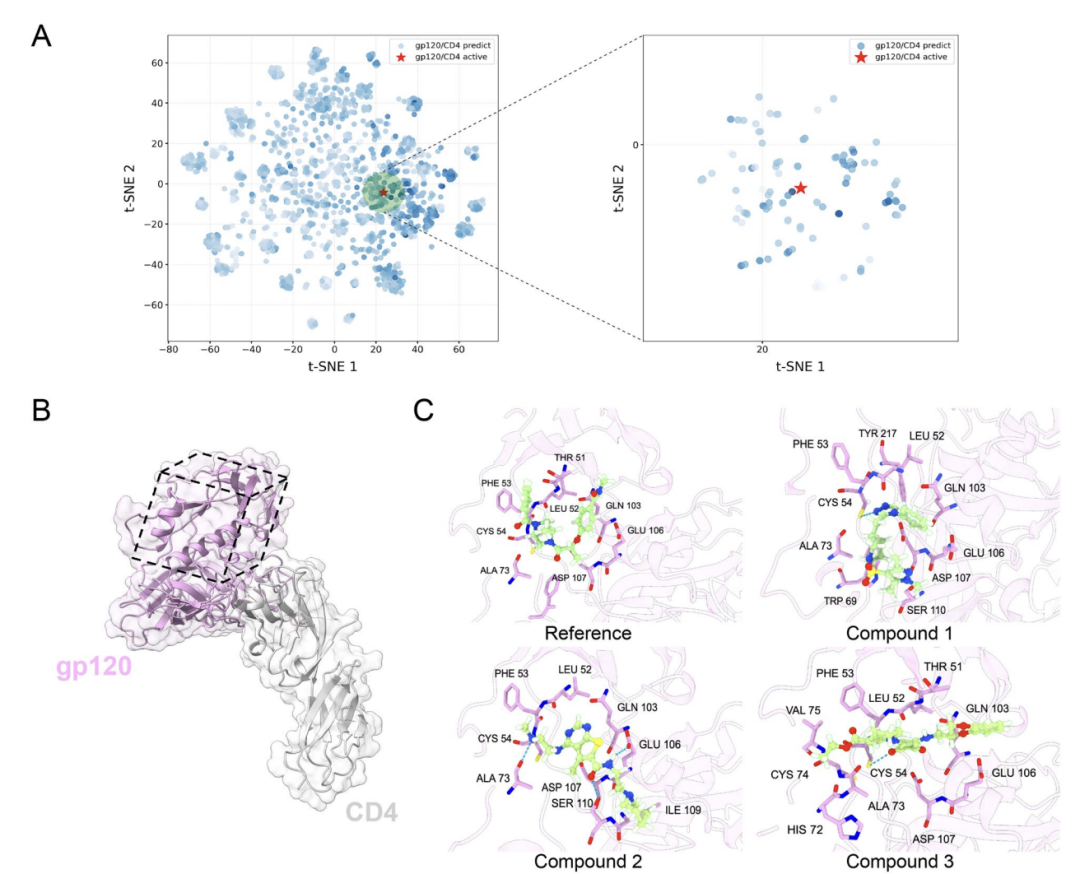
AlphaPPIMIを用いたアロステリックPPI調節薬のスクリーニングへの応用について、図Aに示すように、研究者らはHIV-1 gp120とCD4の相互作用を例に挙げました。AlphaPPIMIは、予測確率が0.8以上で、既知の活性阻害剤と化学空間が大きく重複する化合物をスクリーニングしました。図BCに示すように、非定型界面構造(PDB: 6L1Y)に基づく分子ドッキングの結果、候補化合物はTHR51、LEU52、PHE53などの重要な残基と相互作用できることが示されました。これは、AlphaPPIMIが創薬困難なPPIの界面を標的とするアロステリック阻害剤を発見できることを示しており、関連医薬品の開発に新たなアプローチを提供します。
産学連携によりPPI標的薬を基礎研究から臨床応用まで推進
PPI標的薬の研究開発においては、学界と産業界が緊密に協力し、この分野の基礎研究を徐々に臨床応用へと進めています。
学術の最前線では、多くの研究チームがより正確で効率的な PPI 予測およびターゲティング方法を研究しています。たとえば、スタンフォード大学のチームは、Biomni と呼ばれる汎用バイオメディカル AI エージェントを開発しました。このインテリジェントエージェントは、遺伝学、ゲノミクス、微生物学、薬理学、臨床医学など、複数の生物医学分野にまたがる複雑な研究タスクを自律的に完了することができます。Biomniの誕生は、生物医学研究におけるAIがツールの利用者から自律的な意思決定者へと移行することを意味します。分散した科学研究リソースを、実用的なインテリジェントエージェントベースの行動ユニットに統合することで、従来の研究プロセスにおける断片化されたボトルネックを克服するだけでなく、学際的、高スループット、自律的な科学的発見エンジンの出現を促進する可能性も秘めています。
もう一つの代表的な研究中山大学は、融合特徴抽出と新しい教師なし特徴選択メカニズムに基づく PPI 予測方法を提案しました。広範囲にわたる実験の結果、提案手法は種内相互作用と種間相互作用の両方をカバーする5つのデータセットにおいて良好なパフォーマンスを示し、既存の16の機械学習手法を大幅に上回る性能を示しました。本研究は、大規模なPPI予測タスクのための効率的で信頼性の高いフレームワークを提供するだけでなく、幅広い機能的適応性を示し、薬物間および薬物と食品の相互作用予測のための新たなソリューションを提供します。
産業への応用という点では、企業はこれらの学術的ブレークスルーを積極的に臨床へと導いています。例えば、中国のバイオ医薬品技術企業Adlai Nortyeがノバルティスからのグローバルライセンスに基づいて開発したAN2025(一般名:ブパルリシブ)は、PI3Kシグナル伝達経路を特異的に標的とする汎阻害剤です。現在、抗PD-1/PD-L1療法にもかかわらず病勢進行が認められた再発または転移性頭頸部扁平上皮がん患者を主な対象として、国際共同第III相臨床試験が進行中です。
もう一つの例は、フランスの著名な製薬会社イプセンが発売したイキルボ(エラフィブラノール)です。過去10年間で初めて承認されたPBC治療薬として、非腫瘍領域におけるPPI調節の臨床的価値を実証し、複雑な代謝性疾患に対する新たな治療パラダイムを提供しました。また、その承認はPPARファミリータンパク質相互作用ネットワークの詳細な研究を促進しました。
PPI標的薬分野における産学連携の深化は、科学研究成果の臨床価値への転換を加速させるだけでなく、新薬開発の効率と成功率を大幅に向上させました。マルチモーダルAI予測モデルから明確な臨床的ベネフィットを持つ候補薬まで、この学際的な連携はバイオメディカルイノベーションの道筋を再定義しつつあります。今後、より多くのデータとアルゴリズムの統合、そして機関間および学際的な連携の深化により、PPI標的薬は複雑な疾患の治療においてさらなるブレークスルーをもたらす可能性があります。
参考リンク:
1.https://mp.weixin.qq.com/s/ryYJ6T7qEjnjvkhBL4-dAA
2.https://mp.weixin.qq.com/s/7upIPYam1LR0TiGBYXmkOw
3.https://mp.weixin.qq.com/s/69GU1R5lXHdTLttlT8apyw








