Command Palette
Search for a command to run...
270Mの軽量モデル!Gemma-3-270M-ITは軽量な長文インタラクションに特化。クロスプラットフォームGUIエージェントの第一候補!AgentNetは200以上のウェブサイトをカバー

大規模モデルパラメータの規模が拡大し続けるにつれ、AI利用に対するユーザーの要求は徐々に多様化しています。一方では、複雑なタスクを処理するために高性能なモデルが求められ、他方では、低コンピューティング環境で軽量かつ実用的な会話体験を求めるようになっています。長文の会話や日常的なタスクのシナリオでは、従来の大規模モデルは、高い計算能力のサポートを必要とするだけでなく、応答の遅延、コンテキストの損失、一貫性のない生成の問題も発生しやすく、「使用可能で、使いやすく、適切に実行される」軽量モデルが緊急に対処する必要がある問題点となっています。
これを基に、Google は軽量命令微調整モデル Gemma-3-270M-IT をリリースしました。パラメータ数はわずか 2 億 7000 万個ですが、シングル カード 1GB のビデオ メモリ環境でスムーズに動作し、ローカル展開のハードルが大幅に下がります。また、32Kトークンのコンテキストウィンドウをサポートし、長文の会話やドキュメント処理にも対応します。日常的な質疑応答や単純なタスクに特化した微調整により、Gemma-3-270M-ITは軽量かつ効率的な操作性を維持しながら、会話インタラクションの実用性も両立しています。
Gemma-3-270M-ITは別の開発経路を示しています。「より大きく、より強く」という傾向に加えて、軽量かつ長いコンテキストのサポートにより、エッジ展開と包括的なアプリケーションに新たな可能性を提供します。
HyperAI Hyperneuron公式サイトで「vLLM + Open WebUI デプロイメント gemma-3-270m-it」機能が利用可能になりました。ぜひお試しください!
オンラインでの使用:https://go.hyper.ai/kBjw3
8月25日から8月29日までのhyper.ai公式サイトの更新内容を簡単にご紹介します。
* 高品質の公開データセット: 12
* 高品質なチュートリアルの選択: 4
* 今週のおすすめ論文:5
* コミュニティ記事の解釈:6件
* 人気のある百科事典のエントリ: 5
※9月締切:5日
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
1. Nemotron-Post-Training-Dataset-v2 トレーニング後データセット
Nemotron-Post-Training-Dataset-v2は、NVIDIAの既存の学習後コーパスを拡張したものです。このデータセットは、SFTとRLデータを5つのターゲット言語(スペイン語、フランス語、ドイツ語、イタリア語、日本語)に拡張し、数学、コーディング、STEM(科学、技術、工学、数学)、会話などのシナリオをカバーしています。
直接使用: https://go.hyper.ai/lSIjR
2. Nemotron-CC-v2 事前学習データセット
Nemotron-CC-v2は、2024年から2025年までのCommon Crawlスナップショット8つを元の英語ウェブページコーパスに追加し、グローバルな重複排除と英語フィルタリングを実行します。また、Qwen3-30B-A3Bを使用してウェブページのコンテンツを合成・再述し、多様な質問と回答を補足し、さらに15の言語に翻訳することで、多言語論理的推論と一般知識の事前トレーニングを強化します。
直接使用: https://go.hyper.ai/xRtbR
3.Nemotron-Pretraining-Dataset-sample サンプリングデータセット
Nemotron-Pretraining-Dataset-sample には、完全な SFT および事前トレーニング コーパスのさまざまなコンポーネントから選択された 10 個の代表的なサブセットが含まれており、レビューや簡単な実験に適した、高品質の質問応答データ、数学的に重点を置いた抽出、コード メタデータ、および SFT スタイルの指示データが含まれています。
直接使用: https://go.hyper.ai/xzwY5
4. Nemotron-Pretraining-Code-v1 コードデータセット
Nemotron-Pretraining-Code-v1は、GitHub上に構築された、大規模でキュレーションされたコードデータセットです。このデータセットは、多段階の重複排除、ライセンス適用、ヒューリスティックな品質チェックを経てフィルタリングされており、11のプログラミング言語におけるLLM生成のコード質問と回答のペアが含まれています。
直接使用する: https://go.hyper.ai/DRWAw
5. Nemotron-Pretraining-SFT-v1 教師あり微調整データセット
Nemotron-Pretraining-SFT-v1は、STEM、学術、論理的推論、多言語シナリオ向けに設計されています。高品質な数学および科学資料から生成され、大学院レベルの学術テキストと事前学習済みのSFTデータを組み合わせることで、数学、コーディング、一般知識、論理的推論など、さまざまなタスクを網羅する複雑な多肢選択式および分析問題(完全な回答/思考付き)を構築します。
直接使用: https://go.hyper.ai/g568w
6. Nemotron-CC-Math 数学事前学習データセット
Nemotron-CC-Mathは、数学に特化した高品質で大規模な事前学習済みデータセットです。1,330億トークンを含むこのデータセットは、方程式とコードの構造を維持しながら、数学コンテンツを編集可能なLaTeX形式に統合しています。これは、ウェブスケールで幅広い数学形式(ロングテール形式を含む)を確実にカバーする初のデータセットです。
直接使用: https://go.hyper.ai/aEGc4
7. Echo-4o-Image合成画像生成データセット
GPT-4oによって生成されたEcho-4o-Imageデータセットには、3つの異なるタスクタイプにわたる約179,000件の例が含まれています。複雑な命令実行(約68,000件)、超現実的なファンタジー生成(約38,000件)、および複数参照画像生成(約73,000件)です。各例は、1024×1024の解像度を持つ2×2の画像グリッドで構成されており、画像パス、特徴(属性/対象)、および生成されたプロンプトに関する構造化情報が含まれています。
直接使用: https://go.hyper.ai/uLJEh

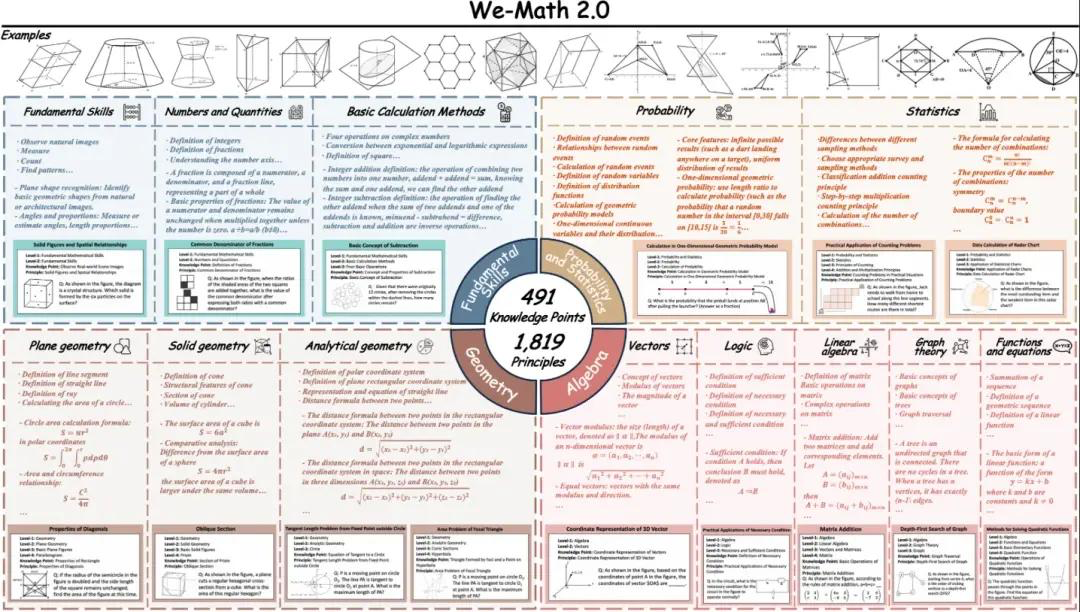
8. We-Math2.0 標準ビジュアル数学推論ベンチマークデータセット
We-Math2.0-Standardは、1,819の厳密に定義された原則を基盤とした統一的なラベル空間を構築します。各問題は原則に基づいて明示的にラベル付けされ、厳密にキュレーションされているため、全体として幅広くバランスの取れたカバレッジを実現し、特にこれまで十分に網羅されていなかった数学の分野や問題の種類を網羅しています。データセットは、問題ごとに複数の図と複数の設問を配置する二重の拡張設計を採用しています。
直接使用: https://go.hyper.ai/VlqK1
9. AgentNetデスクトップ操作タスクデータセット
AgentNetは、クロスプラットフォームのGUI操作エージェントと視覚・言語・行動モデルのサポートと評価を目的として設計された、初の大規模デスクトップコンピュータ使用エージェント軌跡データセットです。このデータセットには、Windows、macOS、Ubuntu、そして200以上のアプリケーションとウェブサイトにおける、22,600件の手作業でアノテーションが付けられたコンピュータ使用タスク軌跡が含まれています。シナリオは、オフィス、プロフェッショナル、日常生活、システム使用の4つのカテゴリーに分類されます。
直接使用: https://go.hyper.ai/3DGDs
10. WideSearch情報収集ベンチマークデータセット
WideSearchは、広域情報収集に特化した初のベンチマークデータセットです。このベンチマークは、実際のユーザークエリから厳選され、手作業でクレンジングされた200個の高品質な質問(英語100個、中国語100個)で構成されています。これらの質問は15以上の異なる分野から集められています。
直接使用: https://go.hyper.ai/36kKj
11. MCD マルチモーダルコード生成データセット
MCDには、約598,000件の高品質な例/ペアが収録されており、コマンドフォロー形式で整理されています。多様な入力形式(テキスト、画像、コード)と出力形式(コード、回答、説明)をカバーしているため、マルチモーダルなコード理解・生成タスクに適しています。データには、拡張HTMLコード、グラフ、質問と回答、アルゴリズムなどが含まれています。
直接使用: https://go.hyper.ai/yMPeD
12. Llama-Nemotron-Post-Training-Dataset トレーニング後のデータセット
Llama-Nemotron 学習後データセットは、学習後フェーズ(SFT や RL など)における Llama-Nemotron ファミリーモデルの数学、コード、一般推論、および指示追従能力を向上させるために設計された大規模な学習後データセットです。このデータセットは、教師ありファインチューニングフェーズと強化学習フェーズの両方のデータを統合しています。
直接使用: https://go.hyper.ai/Vk0Pk
選択された公開チュートリアル
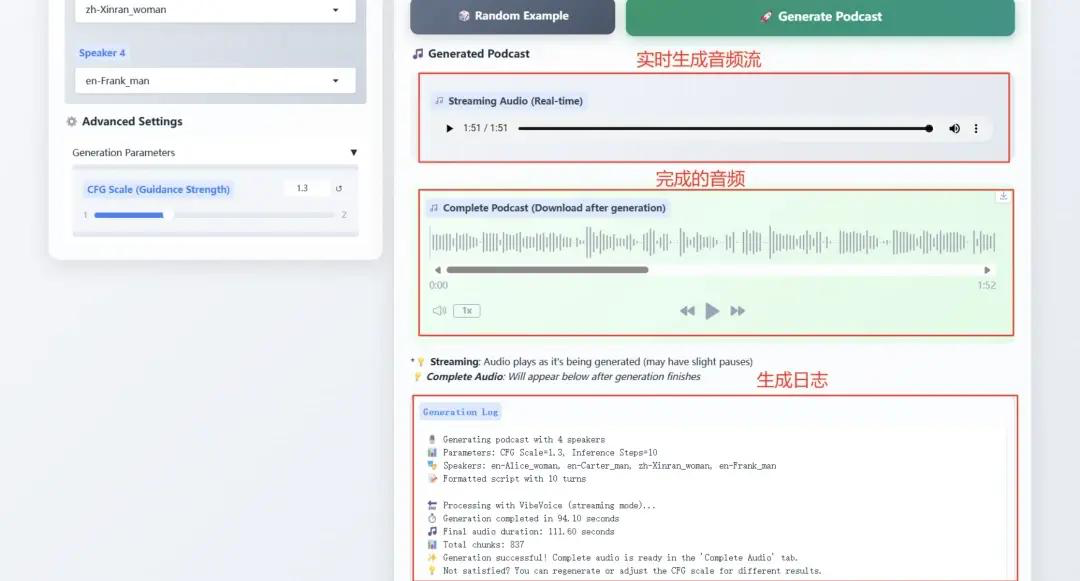
1. Microsoft VibeVoice-1.5B が TTS テクノロジーを再定義境界
VibeVoice-1.5Bは、ポッドキャストなど、表現力豊かな長編複数話者による会話音声を生成する新しいテキスト読み上げ(TTS)モデルです。VibeVoiceは、高い忠実度を維持しながら長い音声シーケンスを効率的に処理し、最大4人の異なる話者による最長90分の音声合成をサポートします。
オンライン操作:https://go.hyper.ai/Ofjb1
2. vLLM + Open WebUI で NVIDIA-Nemotron-Nano-9B-v2 をデプロイする
NVIDIA-Nemotron-Nano-9B-v2は、Mambaの効率的な長シーケンス処理とTransformerの強力なセマンティックモデリング機能を革新的に組み合わせ、わずか90億(9B)のパラメータで128Kの超長コンテキストサポートを実現します。その推論効率とエッジコンピューティングデバイス(RTX 4090クラスのGPUなど)におけるタスクパフォーマンスは、同じパラメータスケールを持つ最先端モデルに匹敵します。
オンラインで実行: https://go.hyper.ai/cVzPp
3. vLLM + オープン WebUI の導入 gemma-3-270m-it
gemma-3-270m-itは、2億7000万個のパラメータで構築されており、効率的な会話インタラクションと軽量なデプロイメントに重点を置いています。この軽量で効率的なモデルは、単一のグラフィックカードで1GB以上のグラフィックメモリしか必要としないため、エッジデバイスやリソースの限られたシナリオに適しています。このモデルはマルチターンの会話をサポートし、日常的な質疑応答や簡単なタスク指示に特化して最適化されています。テキスト生成と理解に重点を置き、3万2000トークンのコンテキストウィンドウをサポートすることで、長いテキスト会話にも対応できます。
オンラインで実行: https://go.hyper.ai/kBjw3

4. vLLM+Open WebUIデプロイメントSeed-OSS-36B-Instruct
Seed-OSS-36B-Instructは、12兆(12テラバイト)のトークンを学習に使用し、複数の主要なオープンソースベンチマークで優れたパフォーマンスを達成しました。その最も代表的な機能の一つは、ネイティブのロングコンテキスト機能です。最大コンテキスト長は51万2千トークンで、非常に長いドキュメントや推論チェーンをパフォーマンスを犠牲にすることなく処理できます。この長さは、OpenAIの最新のGPT-5モデルファミリーの2倍であり、約1,600ページのテキストに相当します。
オンラインで実行: https://go.hyper.ai/aKw9w

💡安定拡散チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] にメモし、グループに参加してさまざまな技術的な問題について話し合い、アプリケーションの効果を共有してください。

今週のおすすめ紙
1. Pass@1を超えて: 変分問題合成による自己プレイがRLVRを維持する
本論文では、大規模言語モデルにおける検証可能な報酬強化学習を改善するため、自己再生変分問題のための合成戦略を提案する。従来のRLVRはPass@1の性能を向上させるものの、エントロピー崩壊によって生成多様性が低下し、Pass@kの性能が制限される。SvSは、正解に基づいて等価な変分問題を合成することで、エントロピー崩壊を軽減し、訓練の多様性を維持する。
論文リンク: https://go.hyper.ai/IU71P
2. メモ: LLM を微調整せずに LLM エージェントを微調整する
本論文では、適応型大規模言語モデルエージェントのための、基盤となるLLMの微調整を必要としない新たな学習パラダイムを提案する。既存の手法には、しばしば2つの制約、すなわち、あまりにも硬直的であるか、あるいは計算コストが高いという制約がある。本研究チームは、メモリベースのオンライン強化学習を用いて、低コストの継続的適応を実現する。このプロセスをメモリ拡張型マルコフ決定過程(M-MDP)として定式化し、行動決定を導くニューラルケース選択戦略を導入する。
論文リンク: https://go.hyper.ai/sl9Yj
3. TreePO: ヒューリスティックなツリーベースモデリングによるポリシー最適化と有効性および推論効率のギャップの橋渡し
本論文では、シーケンス生成をツリー状の探索プロセスとして扱う自己誘導型ロールアウトアルゴリズムTreePOを提案する。TreePOは、動的なツリーサンプリング戦略と固定長セグメントのデコードから構成され、局所的な不確実性を利用して追加の分岐を生成する。共通プレフィックスにかかる計算オーバーヘッドを償却し、価値の低いパスを早期に除去することで、TreePOは探索の多様性を維持または向上させながら、各更新の計算負荷を効果的に軽減する。
論文リンク: https://go.hyper.ai/J8tKk
4. VibeVoice 技術レポート
本論文では、次トークン拡散法に基づいて複数話者の長文音声を生成する、新しい音声合成モデルVibeVoiceを提案します。VibeVoiceの連続音声トークナイザーは、Encodecと比較して80倍の圧縮率を実現し、音質を維持しながら長文シーケンスの処理効率を大幅に向上させます。このモデルは、64kのコンテキスト内で最大4人の話者による最大90分の会話音声の合成をサポートし、コミュニケーションの雰囲気を忠実に再現し、既存のオープンソースモデルや商用モデルを凌駕します。
論文リンク: https://go.hyper.ai/pokVi
5. CMPhysBench: 凝縮系物理学における大規模言語モデルを評価するためのベンチマーク
本論文では、凝縮物質物理学における大規模言語モデルの能力を評価するための新しいベンチマークであるCMPhysBenchを紹介します。CMPhysBenchは、磁性、超伝導、強相関系など、凝縮物質物理学の代表的なサブフィールドと基本的な理論的枠組みを網羅する、厳選された520以上の大学院レベルの問題で構成されています。
論文リンク: https://go.hyper.ai/uo8de
AIフロンティアに関するその他の論文:https://go.hyper.ai/iSYSZ
コミュニティ記事の解釈
1. 構造・配列・機能の関係性に基づくタンパク質言語モデルの分類の再定義:李明塵博士がタンパク質言語モデルを詳細に解説
上海交通大学が主催した第3回「AIバイオエンジニアリングサマースクール」では、上海交通大学自然科学研究所の洪亮研究グループの博士研究員である李明塵氏が「タンパク質とゲノムの基本モデル」をテーマに、タンパク質とゲノムの基本モデルにおける最新の研究の進歩と技術の進歩を参加者全員と共有しました。
レポート全文はこちら:https://go.hyper.ai/Ynjdj
2. MITチームは、任意の温度での小分子の溶解度を予測するために、元のモデルより50倍高速なFASTSOLVモデルを提案しました。
MITの研究チームは、ケミインフォマティクスツールと新しい有機溶媒溶解度データベースBigSolDBを組み合わせることで、FASTPROPおよびCHEMPROPモデルアーキテクチャを改良し、logSの直接回帰トレーニングにおいて、溶質分子と溶媒分子、そして温度パラメータを同時に入力できるようにしました。厳密な溶質外挿シナリオにおいて、最適化されたモデルは、Vermeireらが開発した最先端モデルと比較して、RMSEが2~3倍低減し、推論速度が50倍向上しました。
レポート全文はこちら:https://go.hyper.ai/cj9RX
3. 3,499ドルで販売されるNvidiaのJetson Thorは、ロボットと現実世界とのリアルタイムのインテリジェントなインタラクションを可能にする。
NVIDIAは、Jetson AGX Thor開発キットの正式リリースを発表しました。価格は3,499ドルからとなります。Thor T5000モジュールの生産モデルは、現在エンタープライズ顧客向けに提供されています。「ロボットの頭脳」と称されるJetson AGX Thorは、製造、物流、運輸、医療、農業、小売などの業界で数百万台のロボットの運用を支援することを目指しています。
レポート全文はこちら:https://go.hyper.ai/1XLXn
4. マルチモーダル モデルは、完全な結晶構造を必要とせずに材料特性を予測し、新しい材料と産業用途のマッチングを加速します。
カナダのトロント大学化学工学・応用化学学科の研究チームは、MOF合成後に得られる情報(PXRDと合成に使用された化学物質)を活用し、当初報告されていた用途とは異なる分野での可能性を持つMOFを特定するマルチモーダル機械学習手法を提案しました。この研究は、MOFの合成と応用シナリオの連携を加速させるものです。
レポート全文はこちら:https://go.hyper.ai/cqX1t
5. 科学データの可用性を向上させるために、中国科学院の張正徳氏のチームは、インテリジェントエージェントに基づく AI 対応のデータ処理および供給ソリューションを提案しました。
2025CCF全国高性能コンピューティング学術会議において、高能物理研究所コンピューティングセンターAI4S責任者の張正徳研究員は、大規模施設の科学データの現状、およびデータの注釈と供給におけるインテリジェントエージェントとマルチエージェントフレームワークの応用に基づき、データの効率的で高品質なAI対応構築計画を体系的に説明した。
レポート全文はこちら:https://go.hyper.ai/u7F9L
人気のある百科事典の項目を厳選
1. DALL-E
2. 相互ソート融合RRF
3. パレートフロント
4. 大規模マルチタスク言語理解MMLU
5. 対照学習
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。https://go.hyper.ai/wiki
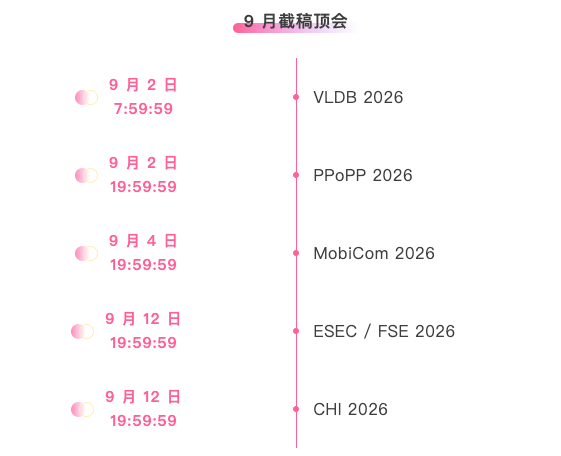
主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!








