Command Palette
Search for a command to run...
Google DeepMind は、約 15,000 種をカバーし、生物音響分類および検出の新たな最先端技術を確立した Perch 2.0 をリリースしました。

生物音響学は、生物学と生態学を繋ぐ重要なツールとして、生物多様性の保全とモニタリングにおいて重要な役割を果たしています。初期の研究では、テンプレートマッチングなどの従来の信号処理手法が用いられていましたが、複雑な自然音響環境と大規模データを扱う上で、非効率性と精度の不足により、徐々に限界が露呈していきました。
近年、人工知能(AI)技術の爆発的な成長により、ディープラーニングなどの手法が従来の手法に取って代わり、生物音響イベントの検出と分類における中核的なツールとなっています。例えば、大規模なラベル付き鳥類音響データで学習したBirdNETモデルは、鳥類の声紋認識において優れた性能を示し、異なる種の鳴き声を正確に区別するだけでなく、ある程度の個体識別も可能にしています。さらに、Perch 1.0などのモデルは、継続的な最適化と反復を通じて生物音響学の分野で豊富な成果を積み重ね、生物多様性の監視と保全に確固たる技術的支援を提供しています。
数日前、Google DeepMindとGoogle Researchが共同で立ち上げたPerch 2.0は、生物音響研究を新たな高みへと導くPerch 2.0は、種の分類をトレーニングの中核タスクとしています。鳥類以外のグループからのトレーニングデータをより多く取り入れるだけでなく、新たなデータ拡張戦略とトレーニング目標も採用しています。このモデルは、2 つの権威ある生物音響ベンチマークである BirdSET と BEANS において現在の SOTA を更新しました。強力なパフォーマンスの可能性と幅広い応用の可能性を実証しています。
関連する研究結果は、「Perch 2.0: The Bittern Lesson for Bioacoustics」というタイトルで、arXiv にプレプリントとして公開されました。
用紙のアドレス:
https://arxiv.org/abs/2508.04665
公式アカウントをフォローし、「Bioacoustics」と返信すると、完全なPDFが手に入ります。
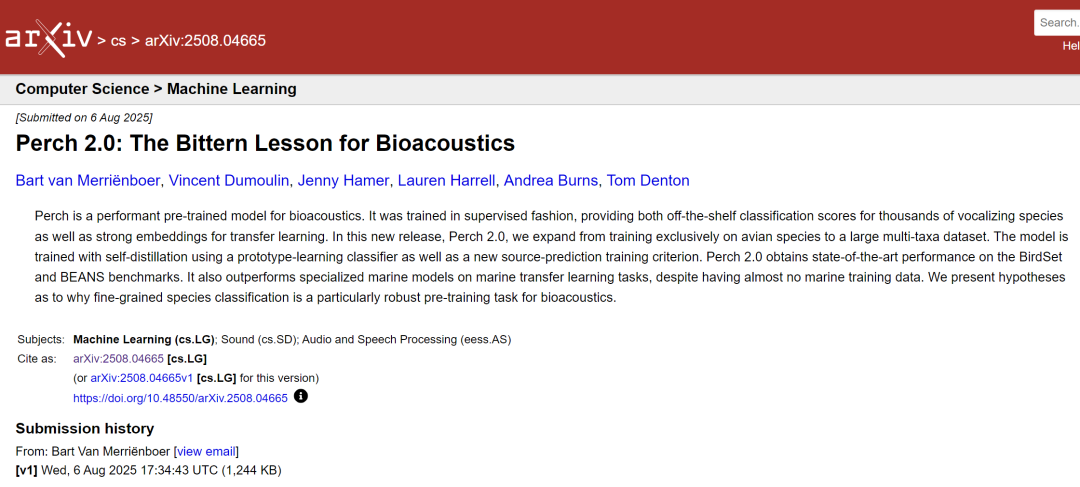
データセット: トレーニングデータの構築と評価ベンチマーク
この研究では、モデルのトレーニング用に、Xeno-Canto、iNaturalist、Tierstimmenarchiv、FSD50K の 4 つのラベル付きオーディオ データセットを統合しました。これらは、モデル学習の基盤となるデータ基盤を形成します。下表に示すように、Xeno-CantoとiNaturalistは大規模な市民科学リポジトリです。前者は公開APIを介してアクセスでき、後者はGBIFプラットフォームで研究グレードとラベル付けされた音声から生成されます。どちらも鳥類やその他の生物の音響録音を多数収録しています。ベルリン自然史博物館の動物音声アーカイブであるTierstimmenarchivも、生物音響学に重点を置いています。最後に、FSD50Kは、鳥類以外の様々な音声を補完しています。
これら 4 つのデータ カテゴリには、合計 14,795 のカテゴリが含まれます。このうち14,597件は種に関するもので、残りの198件は種に関連しない音響イベントでした。この豊富なカテゴリカバレッジは、生物音響信号のディープラーニングを保証するだけでなく、鳥類以外の音響データを含めることでモデルの適用範囲を拡大します。ただし、最初の3つのデータセットは異なる種分類システムを使用していたため、研究チームはカテゴリ名を手動でマッピングして統合し、選択されたスペクトログラムパラメータでは表現できないコウモリの録音を除外することで、データの一貫性と適用性を確保しました。
異なるデータソースの記録時間は非常に異なる(1秒未満から1時間以上、ほとんどが5秒から150秒)ことを考慮し、モデルは5秒のクリップを入力として固定します。研究チームは、2 つのウィンドウ選択戦略を設計しました。ランダムウィンドウ戦略では、録音を選択する際にランダムに5秒間をインターセプトします。これには対象種が音を発していない区間が含まれる場合があり、ラベルノイズが多少発生する可能性がありますが、通常は許容範囲内です。エネルギーピーク戦略はPerch 1.0の考え方に基づき、ウェーブレット変換を用いて録音の中で最もエネルギーが強い6秒間の領域を選択します。次に、この領域から5秒間をランダムに選択することで、「高エネルギー領域には対象種の音が含まれている可能性が高い」という仮定に基づき、サンプルの妥当性を向上させます。この方法は、BirdNET などのモデルの検出器設計ロジックと一致しており、有効な音響信号をより正確にキャプチャできます。
複雑な音響環境へのモデルの適応性をさらに向上させるために、研究チームはミックスアップのデータ拡張バリアントを採用しました。複数のオーディオ ウィンドウをミックスして複合信号を生成します。まず、ベータ二項分布からサンプリングすることで混合オーディオ信号の数を決定し、次に対称ディリクレ分布を用いて重みをサンプリングします。選択された複数の信号は重み付け加算され、ゲインが正規化されます。
オリジナルのMixupとは異なり、この手法では、ワンホットベクトルではなくマルチホットターゲットベクトルの加重平均を用いることで、ウィンドウ内のすべての音(音量に関わらず)を高い信頼性で識別できます。関連パラメータをハイパーパラメータとして調整することで、モデルの重複音の識別能力を高め、分類精度を向上させることができます。
モデル評価は、BirdSet と BEANS という 2 つの信頼できるベンチマークに基づいています。 BirdSetには、アメリカ本土、ハワイ、ペルー、コロンビアの6つの完全アノテーション付きサウンドスケープデータセットが含まれています。評価中に微調整は行われず、プロトタイプ学習分類器の出力が直接使用されます。BEANSは12のクロスカテゴリテストタスク(鳥類、陸生および海生哺乳類、無尾類、昆虫を含む)をカバーしています。線形プローブとプロトタイププローブの学習には、そのトレーニングセットのみが使用され、埋め込みネットワークも調整されていません。
Perch 2.0: 高性能バイオ音響事前トレーニングモデル
Perch 2.0 モデル アーキテクチャは、フロントエンド、埋め込みモデル、および出力ヘッドのセットで構成されます。これらの部品は連携して動作し、音声信号から種の識別までの完全なプロセスを実現します。
で、フロントエンドは、生のオーディオをモデルが処理できる特徴形式に変換する役割を担います。32kHzでサンプリングされたモノラルオーディオを受信し、5秒間のセグメント(160,000個のサンプリングポイントを含む)に対して、20msのウィンドウ長と10msのジャンプ長で処理することにより、60Hzから16kHzの周波数範囲をカバーする500フレームとフレームあたり128のメルバンドを含むログメルスペクトログラムを生成し、その後の分析のための基本機能を提供します。
埋め込みネットワークはEfficientNet-B3アーキテクチャを採用しているこれは1億2000万パラメータの畳み込み残差ネットワークであり、深さ方向に分離可能な畳み込み設計を用いることでパラメータ効率を最大化しています。Perchの以前のバージョンで使用されていた7800万パラメータのEfficientNet-B1と比較すると、学習データの増加に合わせて規模が大きくなっています。
埋め込みネットワークを通した処理の後、(5, 3, 1536)の形状を持つ空間埋め込みが得られます(次元はそれぞれ時間、周波数、特徴チャネルに対応します)。空間次元の平均を取ることで、1536次元のグローバル埋め込みが得られ、これが後続の分類の核となる特徴となります。
出力ヘッドは、特定の予測および学習タスクを担当します。このシステムは3つの部分から構成されています。線形分類器は、グローバル埋め込みを14,795次元のカテゴリ空間に投影し、トレーニングを通じて、異なる種の埋め込みを線形に分離できるようにすることで、新しいタスクに適応する際の線形検出効果を向上させます。プロトタイプ学習分類器は、空間埋め込みを入力として、カテゴリごとに4つのプロトタイプを学習し、最大活性化を持つプロトタイプを予測に使用します。この設計は、生物音響学の分野のAudioProtoPNetから派生したものです。音源予測ヘッドは、グローバル埋め込みに基づいてオーディオクリップの元の録音音源を予測する線形分類器です。トレーニングセットには150万件以上の音源録音が含まれているため、ランク512の低ランク投影を通じて効率的な計算を実現し、自己教師あり音源予測損失の学習に役立ちます。
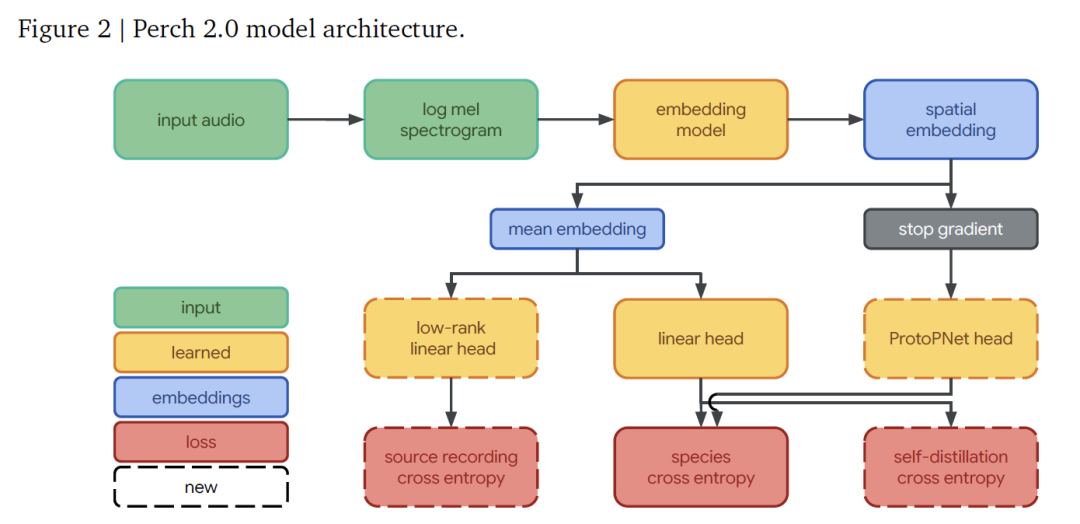
モデルトレーニングは、次の 3 つの独立した目標を通じてエンドツーエンドで最適化されます。
* 種の分類のためのクロスエントロピーは、線形分類器にソフトマックス活性化とクロスエントロピー損失を使用し、ターゲットカテゴリに均一な重みを割り当てます。
自己蒸留メカニズムでは、プロトタイプ学習分類器は「教師」として機能し、その予測によって「生徒」線形分類器をガイドしながら、直交損失を通じてプロトタイプの差を最大化し、勾配は埋め込みネットワークに逆伝播されません。
* ソース予測は自己教師型の目標として使用され、元の録音をトレーニング用の独立したカテゴリとして扱い、モデルが顕著な特徴を捉えるようにします。
トレーニングは 2 つのフェーズに分かれています。最初のフェーズでは、プロトタイプ学習分類器のトレーニング (自己蒸留なし、最大 300,000 ステップ) に重点を置き、2 番目のフェーズでは自己蒸留を有効にしました (最大 400,000 ステップ)。どちらのフェーズでも Adam オプティマイザーが使用されました。
ハイパーパラメータの選択は Vizier アルゴリズムに依存します。第一段階では、学習率、ドロップアウト率などを探索し、2回のスクリーニングを経て最適モデルを決定します。第二段階では、自己蒸留損失の重みを増加させながら探索を継続します。2つのウィンドウサンプリング法は、全体を通して使用されます。
結果は、第1段階では2~5個の信号を混合し、ソース予測の損失の重みを0.1~0.9に設定する傾向があることを示しています。一方、自己蒸留段階では学習率が小さく、混合率が少なく、自己蒸留損失に1.5~4.5という高い重みを割り当てる傾向があります。これらのパラメータは、モデルの性能を支えています。
Perch 2.0の一般化能力の評価:ベースラインパフォーマンスと実用的価値
Perch 2.0の評価は、一般化能力に焦点を当て、鳥類のサウンドスケープ(訓練録音とは大きく異なる)や種識別以外のタスク(鳴き声の種類の識別など)におけるパフォーマンス、そしてコウモリや海洋哺乳類といった鳥類以外のグループへの適用能力を検証しました。実務家はラベル付けされたデータが少量、あるいは全くない場合が多いことを考慮し、評価の核となる原則は、「凍結された組み込みネットワーク」の有効性を検証することです。つまり、一度に特徴を抽出することで、クラスタリングや小サンプル学習などの新しいタスクに迅速に適応できます。
モデル選択フェーズでは、次の 3 つの側面から実用性を検証します。
* ROC-AUC を使用して、完全に注釈が付けられた鳥類データセットですぐに使用できる種の予測機能を評価する、事前トレーニング済みの分類器のパフォーマンス。
* コサイン距離を使用してクラスタリングと検索パフォーマンスを測定する 1 つのサンプル取得。
* 線形移行、小規模サンプルのシナリオをシミュレートして適応性をテストします。
これらのタスクのスコアは幾何平均によって計算され、19 個のサブデータセットの最終結果はモデルの実際の使いやすさを反映します。
BirdSet と BEANS の 2 つのベンチマークに基づいて、この調査の評価結果を次の表に示します。Perch 2.0 は多くの指標で優れたパフォーマンスを発揮しますが、特に ROC-AUC は現在最高です。また、微調整は必要ありません。ランダム ウィンドウとエネルギー ピーク ウィンドウのトレーニング戦略は同様のパフォーマンスを発揮します。これは、自己蒸留によってラベル ノイズの影響が軽減されると考えられます。
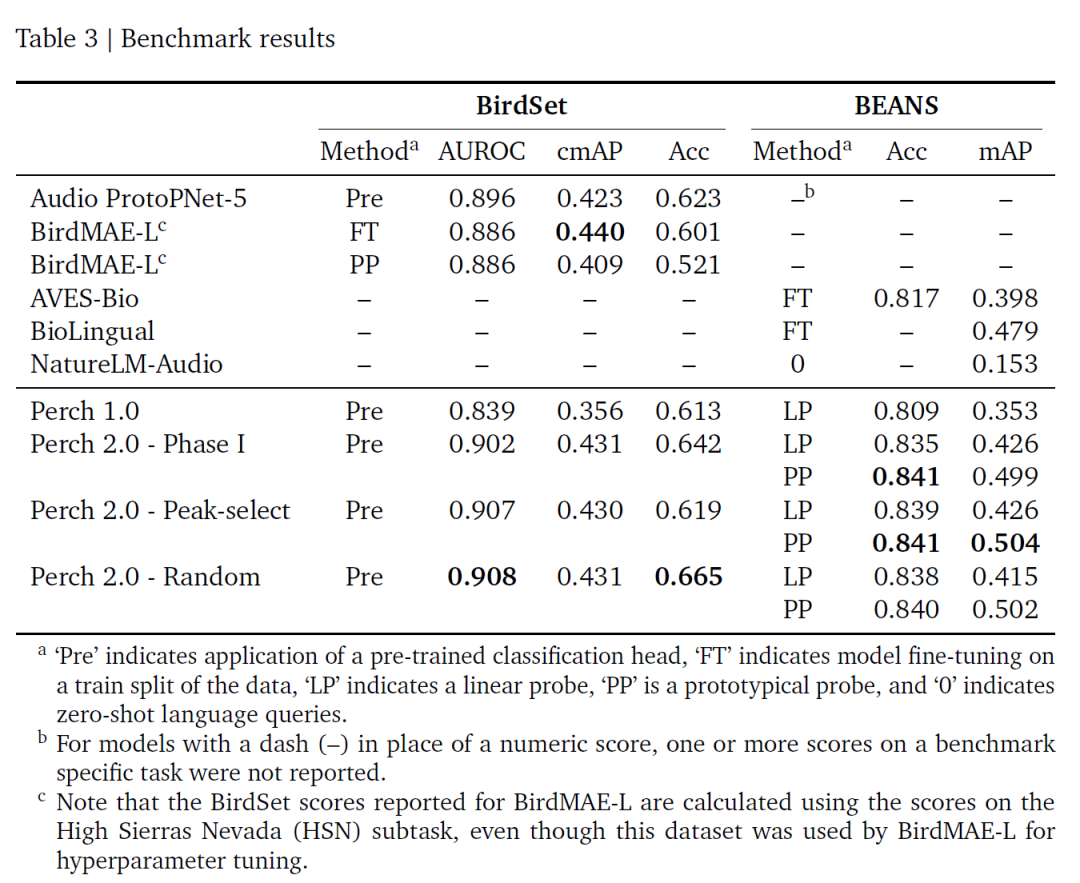
全体的に、Perch 2.0は教師あり学習に基づいており、生物音響特性と密接に関連しています。Perch 2.0の画期的な進歩は、高品質の転移学習には超大規模モデルは必要ありません。データ拡張と補助的な目的を組み合わせた、微調整された教師ありモデルで優れたパフォーマンスを発揮できます。固定埋め込み設計(繰り返しの微調整が不要)により、大規模データ処理のコストが削減され、アジャイルモデリングが可能になります。この分野の今後の方向性としては、現実的な評価ベンチマークの構築、メタデータを用いた新しいタスクの開発、半教師あり学習の検討などが挙げられます。
生物音響学と人工知能の交差点
生物音響学と人工知能の交差点では、カテゴリ間転移学習、自己教師ターゲット設計、固定埋め込みネットワーク最適化などの研究方向が、世界中の学界やビジネス界で広範な探究を引き起こしてきました。
ケンブリッジ大学のチームが開発したコサイン距離仮想敵対的トレーニング (CD-VAT) 技術は、一貫性の正規化を通じて音響埋め込みの識別可能性を向上させます。大規模音声認識タスクにおいて、32.51%TP3Tの同等のエラー率改善を達成した。音声認識における半教師あり学習の新しいパラダイムを提供します。
MITとCETIはマッコウクジラの声紋研究で協力しています。機械学習により、リズム、拍子、トレモロ、装飾音からなる「音のアルファベット」を分離します。彼らのコミュニケーションシステムの複雑さは予想をはるかに超えるものであることが明らかになった。東カリブ海のマッコウクジラの仲間だけでも、少なくとも143の識別可能な発声の組み合わせがあり、その情報伝達能力は人間の言語の基本構造さえも超えている。
* 詳細はこちらをクリック:MIT/CETIチームが機械学習を用いてマッコウクジラの発音アルファベットを分離!人間の言語システムに非常に類似しており、情報伝達能力も高い
ETH チューリッヒが開発した光音響イメージング技術は、マイクロカプセルに酸化鉄ナノ粒子を充填することで音響回折限界を突破します。深部組織微小血管の超解像イメージングを実現(解像度最大20ミクロン)これは、脳科学および腫瘍研究におけるマルチパラメータ動的モニタリングの可能性を示しています。
同時に、オープンソース プロジェクト BirdNET は、世界中で 1 億 5000 万件の録音を蓄積しています。生態モニタリングのベンチマークツールとなっています。軽量版のBirdNET-Liteは、Raspberry Piなどのエッジデバイス上でリアルタイムに動作し、6,000種以上の鳥類の識別をサポートし、生物多様性研究のための低コストなソリューションを提供します。
日本のHylable社が日比谷公園に導入したAI鳥の鳴き声認識システムは、マルチマイクアレイとDNNを組み合わせている。95% 以上の精度で、音源の位置と種の識別を同時に出力します。その技術的枠組みは、都市緑地の生態学的評価やバリアフリー施設の構築といった分野にも広がっています。
注目すべきはGoogle DeepMind の Project Zoonomia は、240 種の哺乳類のゲノムと音響データを統合して、種を超えた音響の共通性の進化のメカニズムを調査しています。この研究では、イヌの喜びの吠え声の倍音エネルギー分布(第3-5倍音エネルギー比0.78±0.12)が、イルカの社会的なホイッスル(0.81±0.09)と高い相同性を示すことが明らかになりました。この分子生物学的相関は、種間モデルの移行の基盤となるだけでなく、「生物学に着想を得たAI」のための新たなモデリング手法、すなわち進化樹情報を組み込みネットワーク学習に組み込むことで、従来の生物音響モデルの限界を打ち破る可能性を示唆しています。
これらの探究は、生物音響学と人工知能の融合に新たな次元をもたらしています。学術研究の深遠さと産業応用の幅広さが融合することで、かつては熱帯雨林の樹冠や深海のサンゴ礁に隠れていた生命のシグナルがより明確に捉えられ、解釈されるようになり、最終的には絶滅危惧種を保護するための行動指針や、都市と自然の調和のとれた共存のためのインテリジェントなソリューションへと発展していくでしょう。
参考リンク:
1.https://mp.weixin.qq.com/s/ZWBg8zAQq0nSRapqDeETsQ
2.https://mp.weixin.qq.com/s/UdGi6iSW-j_kcAaSsGW3-A
3.https://mp.weixin.qq.com/s/57sXpOs7vRhmopPubXTSXQ
対応するQRコードをスキャンすると、詳細な解釈レポートを含む、2023年から2024年までの分野別の高品質なAI4S論文にアクセスできます⬇️









