Command Palette
Search for a command to run...
タイルレベルのプリミティブは自動推論メカニズムと統合されています。TileAIコミュニティの創始者は、TileLangのコアテクノロジーと利点を深く分析しています。

7月5日、第7回Meet AIコンパイラ技術サロンが北京で盛況のうちに終了しました。業界の専門家が最新の開発状況や実践・実装経験を共有し、大学の研究者が革新的な技術の実装パスと利点について詳細に説明しました。
で、TileAI コミュニティの創設者である Lei Wang 博士は、「現代の AI ワークロードにおけるプログラマビリティとパフォーマンスの橋渡し」と題した講演を行いました。革新的なオペレータ プログラミング言語 TileLang について、その中核となる設計コンセプトと技術的な利点を共有しながら、分かりやすく紹介します。
TileLangは、AIカーネルプログラミングの効率向上を目指し、スケジューリング空間(スレッドバインディング、レイアウト、テンソライズ、パイプラインを含む)をデータフローから分離し、カスタマイズ可能なアノテーションとプリミティブのセットにカプセル化します。このアプローチにより、ユーザーはカーネルデータフロー自体に集中でき、その他の最適化作業の大部分はコンパイラに任せることができます。
評価結果によると、TileLang は、複数の主要カーネルで業界をリードするパフォーマンスを実現します。統合されたブロックスレッド プログラミング パラダイムと透過的なスケジューリング機能を完全に実証し、現代の AI システム開発に必要なパフォーマンスと柔軟性を提供します。
HyperAIは、元の意図を損なうことなくスピーチを編集・要約しました。以下はスピーチの書き起こしです。
WeChatパブリックアカウント「HyperAI Super Neuro」をフォローし、キーワード「0705 AI Compiler」に返信すると、認定講師の講演PPTを入手できます。
「新しい DSL」がなぜ必要なのでしょうか?
この共有では主に、私たちのチームが 2025 年 1 月に GitHub でオープンソース化した AI ワークロード向けの新しい DSL TileLang を紹介します。
まず最初に、なぜ新しい DSL が必要なのかについてお話ししたいと思います。
個人的な視点から言うと、マイクロソフトでのインターンシップ中に、BitBLASという混合精度計算を研究するプロジェクトに参加しました。当時は主にTVM/Tensor IRをベースにしており、最終的には非常に良好な実験結果を得ることができました。しかし、メンテナンスの難しさなど、依然として多くの問題を抱えていることも分かりました。行列層の混合精度計算など、各演算子ごとに500行ものスケジュールプリミティブを記述しました。見た目はエレガントでしたが、しかし、このスケジュール コードを理解できるのは私だけであり、それを保守または拡張できる他の人を見つけるのは困難です。
さらに、Schedule IRに基づいて新しい要件や最適化を記述することが困難であることも分かりました。例えば、カーネル開発に携わっていた頃、プログラムの最適化を支援するために、Flash AttentionやLinear Attentionなど、3つのSchedule Primitivesを作成しました。これらの演算子はSchedule IRに基づいて記述するのが困難でした。そのため、当時は、プロジェクトがスケールし続ける場合、TIRの使用はうまく機能しない可能性があり、他の解決策が必要だと考えていました。
では、なぜトリトンではないのでしょうか?
トリトンも試してみましたが、しかし、高性能カーネルをカスタマイズするのは難しいと感じました。例えば、Dequantize演算子を記述する場合、各スレッドの動作を制御する必要があるかもしれません。高性能カーネル上で各スレッドのDequantizeをどのように実装するかは、依然として非常に難しい問題です。
2 番目は、バッファーを適切なメモリ スコープにキャッシュする方法です。例えば、一部のGPUでは、逆量子化のためにデータをレジスタにキャッシュしてから共有メモリに書き込む方が適していますが、他のGPUでは、それを直接共有メモリに書き戻す方が適しています。しかし、Tritonではこれを制御するのが困難です。
やっと、トリトンのインデックスは少し複雑だと思います。例えば、Tile を Local にキャッシュする必要がある場合、下の図の左側に示すコードを記述する必要がありますが、Tensor IR では右側に示すように添字を使用してインデックスを作成できるため、非常に優れていると思います。
これに基づいて、既存の DSL ではニーズを満たすことができないことがわかったので、より多くのバックエンドとカスタム演算子をサポートし、より優れたパフォーマンスを実現する革新的な DSL を作成したいと考えました。より良いパフォーマンスを実現するには、タイリングやパイプラインなどのさまざまな設計スペースを最適化する必要があります。この目的のために、私たちは TileLang プロジェクトを提案しました。
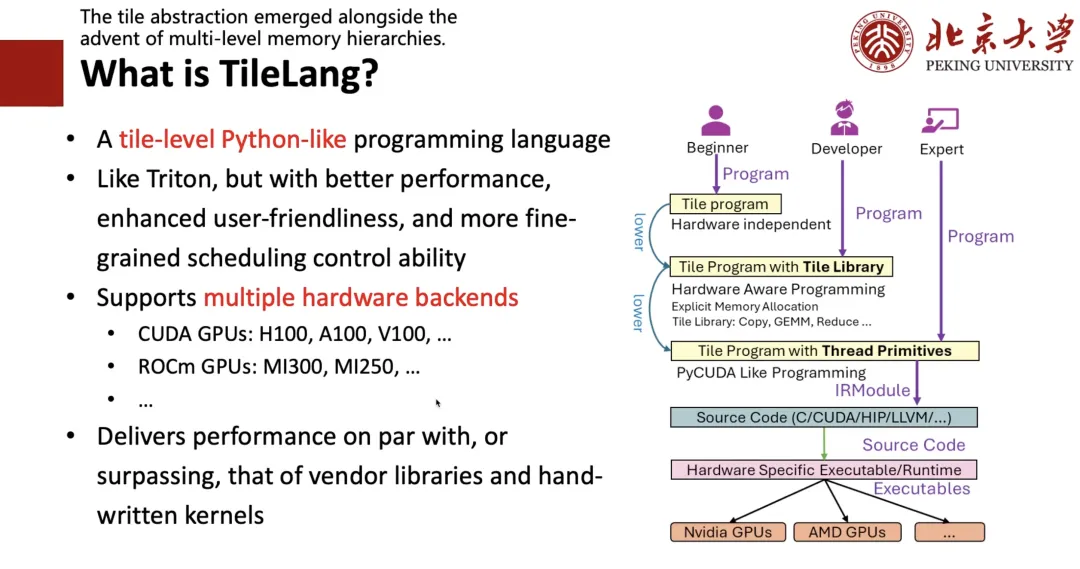
TileLang とは何ですか?
なぜ「タイル」なのか?
まず、タイルの概念が非常に重要であることがわかりました。ハードウェアがキャッシュ、レジスタ、共有メモリといった概念を持っている限り、高性能なプログラムを書く際には、計算ブロック、つまりタイルを考慮する必要があります。次に、誰もがPythonプログラムを書く傾向があるため、Tritonと同じくらい書きやすく、かつより優れたパフォーマンスを持つPythonライクなプログラミング言語を設計したいと考えています。
この目的のために、次の図の右側に示すフレームワークを設計しました。あなたが専門家なら、つまり、CUDA やハードウェアをよく知っていれば、低レベルのコードを直接記述することができます。開発者であれば、つまり、Triton を記述でき、Tile やレジスタなどの概念を理解できる場合は、Triton を記述するのと同じように Tile レベルのプログラムを作成できます。ハードウェアについて何も知らず、アルゴリズムしか知らない初心者の場合、次に、TRL を記述するような高レベルの式を記述し、Auto Schedule を使用してそれを対応するコードに下げることができます。
下の図に示すように、左側の Dequant Schedule は私が TIR を使用して記述したものですが、右側の TileLang の形式でシームレスに等価的に記述することができ、レベル 1 とレベル 2 の共存を実現しています。

次に、TileLang の設計で考慮すべき事項について紹介します。
下の図の左側は、DeepSeek MLAのTileLang実装で、コード行数は約50行です。このカーネルでは、GPUカーネル(カーネル関数)の起動時に、計算タスクを並列に実行するためにブロック(スレッドブロック)をいくつ指定する必要があるか、各ブロックにいくつのスレッドを割り当てるかなど、ユーザーが多くのことを管理する必要があることがわかります。これはタイル構成と呼ばれ、つまり、以下の各コードにはコンテキストがあります。ユーザーは、バッファがどのメモリスコープ上にあるかを制御する必要があり、共有メモリやレジスタのレイアウトをどうするかを決定する必要があり、パイプラインなどにも注意を払う必要があります。これらはすべて、コンパイラがユーザーの管理を支援する必要があります。

この目的のために、最適化空間を 2 つのカテゴリに分けます。1つは推論です。つまり、コンパイラはユーザーがより良いソリューションを導き出すことを直接支援します。一つは「おすすめ」つまり、推奨を通じてプランを選択するということです。
すべての最適化空間を考慮した後、元々 500 を超えるコード ブロックで構成されていた高性能 FlashMLA 実装を、95% のパフォーマンスを維持しながら、わずか 50 行の TileLang コードに圧縮しました。
次は一番下からTileLangを紹介します。
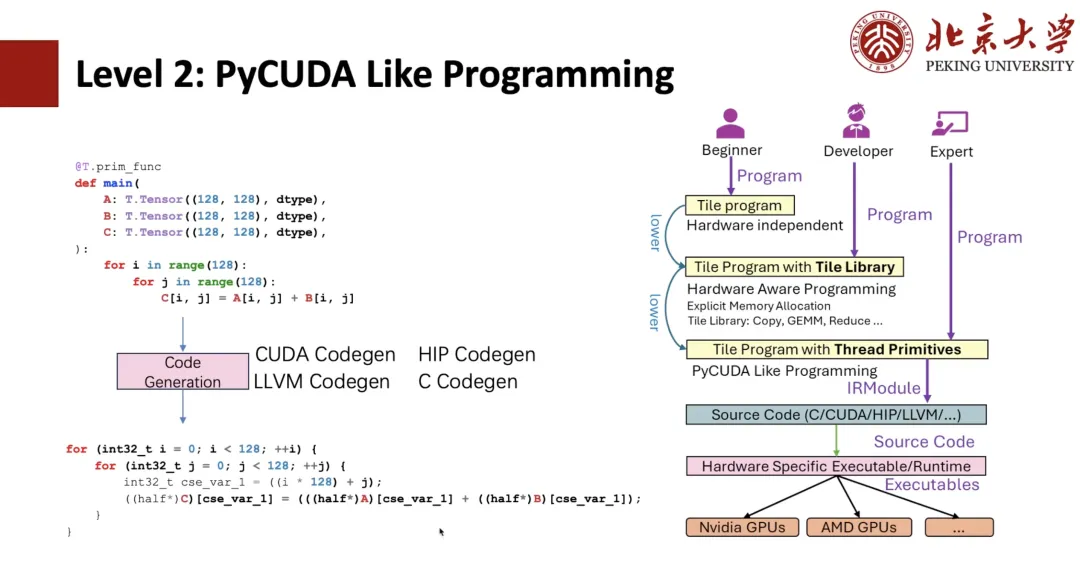
下の図に示すように、TIRに精通している学生であれば、これがTIR式であることが分かるはずです。そして、TIRに基づいたPyCUDAプログラミングが可能になります。例えば、Pythonで負のループを2つ記述した場合、TIR Codegenを使ってCUDA式に変換できます。
ベクトル化などのスレッドプリミティブを利用すれば、CUDAベクトル化を実装でき、さらにスレッドバインディングも実装できます。上記はすべてTIRが元々備えているプログラムであり、ユーザーはCUDAのようにプログラムを書くことができますが、Pythonで書くには依然として複雑です。
ユーザーの使い勝手を向上させるため、レベル1タイルライブラリの記述方法を提案した。例えば、128スレッドのカーネルコンテキストを作成し、Copyを「T.Parallel」でラップします。コンパイラの推論により、先ほど示したような高性能な形式が推論され、最終的にCUDAコードに変換されます。より「エレガント」にしたい場合は、「T.copy」と直接記述し、Copyを「T.Parallel」の式に直接展開することもできます。
T.Parallelは、コピーだけでなく複雑な計算も実行でき、ベクトル化やスレッドバインディングも自動的に実装できます。現在、コピーに加えて、Reduce、Fill、ClearなどのTileライブラリも提供しています。Tileライブラリをベースに、Tritonのような優れた演算子を記述できます。
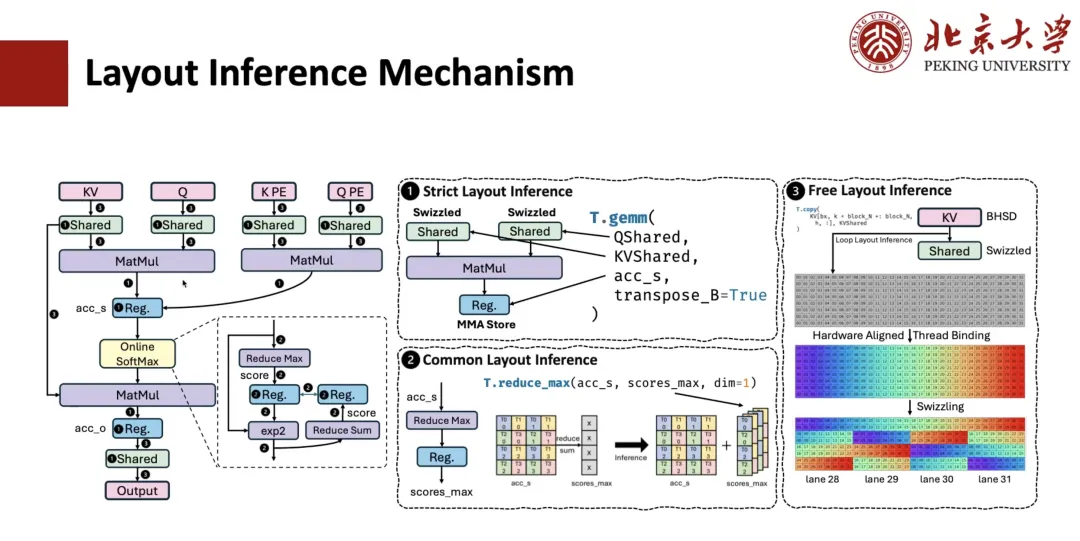
それで、「T.Parallel」を支える中核概念はメモリレイアウトです。
TileLangでは、A[i, k]などの高水準インターフェースを用いた多次元配列のインデックスをサポートしています。この高水準インデックスは、一連のソフトウェアおよびハードウェア抽象化層を経て、最終的に物理メモリアドレスに変換されます。このインデックス変換プロセスをモデル化するために、データがメモリ内でどのように整理され、マップされるかを記述するためにレイアウトを導入しました。
MLA 計算のためのレイアウト導出はどのように実装されますか?通常、このプロセスには 3 つのステップが含まれます。
最初のステップは、厳密なレイアウト推論です。例えば、行列乗算のような演算子はデータレイアウトに強い制約があり、指定されたレイアウトに従う必要があるため、それに接続されるレジスタのレイアウトも決定されます。共有メモリが関係し、この演算子がスピル演算を実行する必要があることが分かっている場合は、対応するメモリレイアウトも決定されます。
2 番目のステップは、共通レイアウト推論です。例えば、前のステップで決定されたレイアウトに接続された式については、そのレイアウトも決定する必要があります。例えば、accum_sからscope_maxへのreduce操作があるとします。ここで、QMSのレイアウトは行列層で指定されており、これに基づいてscope_maxのレイアウトを推測できます。このレベルの一般的な推論により、ほとんどの中間式のレイアウトを決定できます。
3 番目のステップは、フリーレイアウト推論です。つまり、残りのフリーレイアウトが推論されます。このレイアウトは強い制約がないため、通常はハードウェアに合わせたレイアウト推論戦略が採用され、アクセスモードとメモリスコープに基づいて最適なレイアウトソリューションが推論されます。
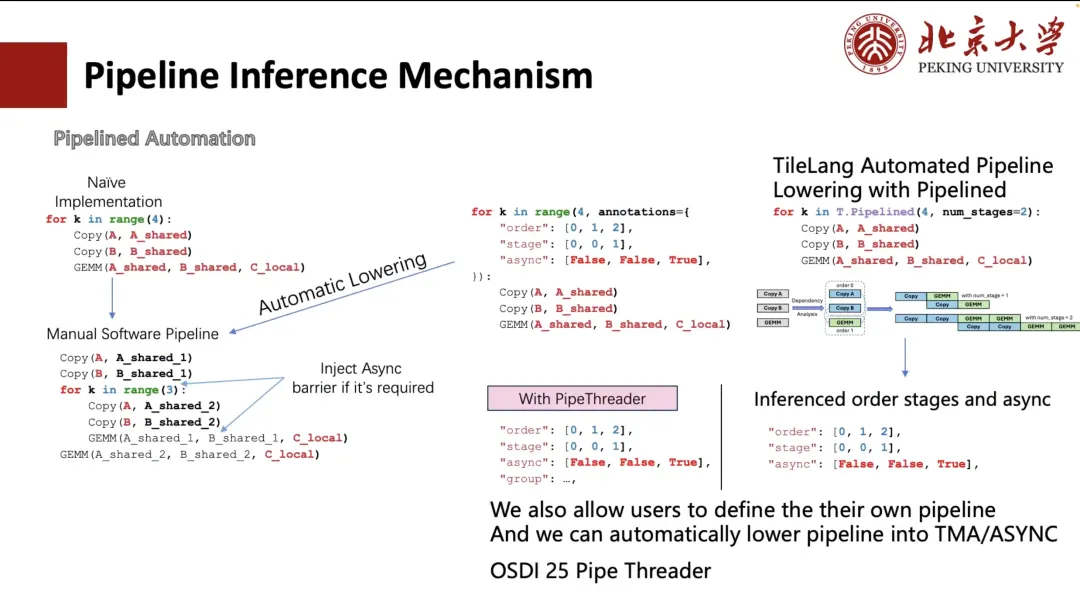
以下では、Pipeline がどのように派生を実行するかについて説明します。
通常、パイプラインは手動で拡張できますが、この記述方法は煩雑でユーザーフレンドリーではありません。そこでTVMは、アノテーションによってプロセスを簡素化する方法を検討しました。ユーザーはループの実行順序とスケジュールステージを指定するだけで済みます。TVM は、ループを手動での展開と同等の構造に自動的に変換できます (下の図の左下隅を参照)。
しかし、ユーザーにとって依然として複雑で面倒な作業です。そこで、TileLangではこれを「num_stage」に簡略化しました。ユーザーは「num_stage」の値を指定するだけで、システムは計算とスケジュールにおける依存関係を自動的に分析し、それに応じて分割します。実際、GPUや他のほとんどのデバイスでは、CopyとGEMMだけが真の非同期実行を実現できます。特にCopy操作は、ASYNCやTMAなどのメカニズムを通じて非同期転送をサポートできます。
したがって、スケジュールでは、コピー操作を別のステージに分割します。パイプライン全体にわたって適切なステージ分割を自動で導き出します。もちろん、左の図に示す2つのカスタム配置のように、ユーザーが手動でスケジュール方法を指定することもできます。
さらに、ハードウェア機能(A100およびH100のTMAモジュールなど)に基づいた自動レイアウト推論とスケジューリング最適化もサポートしています。この作業の一部は、今年のOSDI 25で発表予定のプロジェクト「Pipe Threader」から生まれました。
次に、指示の推論について説明します。
行列乗算を例に挙げると、「T.GEMM」で利用可能なハードウェア命令は数多く存在します。例えば、INT8精度であれば、DP4A命令を使用したり、TensorCoreベースのINT8実装を使用したりできます。また、各命令自体が複数の形状をサポートしているため、これらの実装の中から最適なタイル構成を選択することが重要な課題となります。
この目的のために、TileLang は次の 2 つの使用方法を提供します。
1 つ目は、TileLang を使用すると、ユーザーは PTX を呼び出して ASM を記述できるということです。しかし、この方法の欠点は、組み合わせ空間が広大であることです。すべてのPTXと互換性を持たせたい場合は、大量のコードを書く必要があり、レイアウトの管理も必要になります。しかし、この方法は非常に自由度が高く、個人的には非常に気に入っています。
しかし、現在は2番目の方法を使用しています。つまり、「T.GEMM」の次には、CUTE/CK-TILE などのタイル ライブラリが続きます。行列乗算によく用いられるタイルレベルのライブラリインターフェースを提供しますが、テンプレート展開のためにコンパイルに非常に長い時間がかかるという欠点があります。RTX 4090では、Flash Attentionのコンパイルに10秒かかることがあり、そのうち90%以上がテンプレート展開に費やされています。また、Pythonフロントエンドから大きく分離されていることも問題です。
そこで私たちは、タイル ライブラリは、今後私たちが注力する方向です。つまり、Tile のネイティブ構文を通じて、「T.GEMM」や「T.GEMMSP」などのさまざまな Tile レベルのライブラリがサポートされます。
将来の仕事の見通し
最後に、私たちのチームの今後の取り組みについていくつかご紹介したいと思います。
1 つ目は Tile Sight です。これは、大規模言語モデルにおける大規模で複雑なカーネル (FlashAttention や FlashMLA など) のパフォーマンス最適化を高速化するために特別に設計されています。これは、GPU、CPU、アクセラレータなどの複数のバックエンドに対して効率的なタイル構成(タイル戦略やスケジューリングヒントなど)を生成および評価することを目的とした軽量の自動チューニング フレームワークであり、開発者が優れたパフォーマンスのスケジューリング戦略を迅速に見つけ、手動チューニング時間を短縮するのに役立ちます。
上記のカスタムモデルをベースにすることで、MLAのような複雑なカーネルをユーザーが容易に記述できるようになります。カスタムモデルは、各キャッシュを対応する共有に配置するようユーザーに指示します。
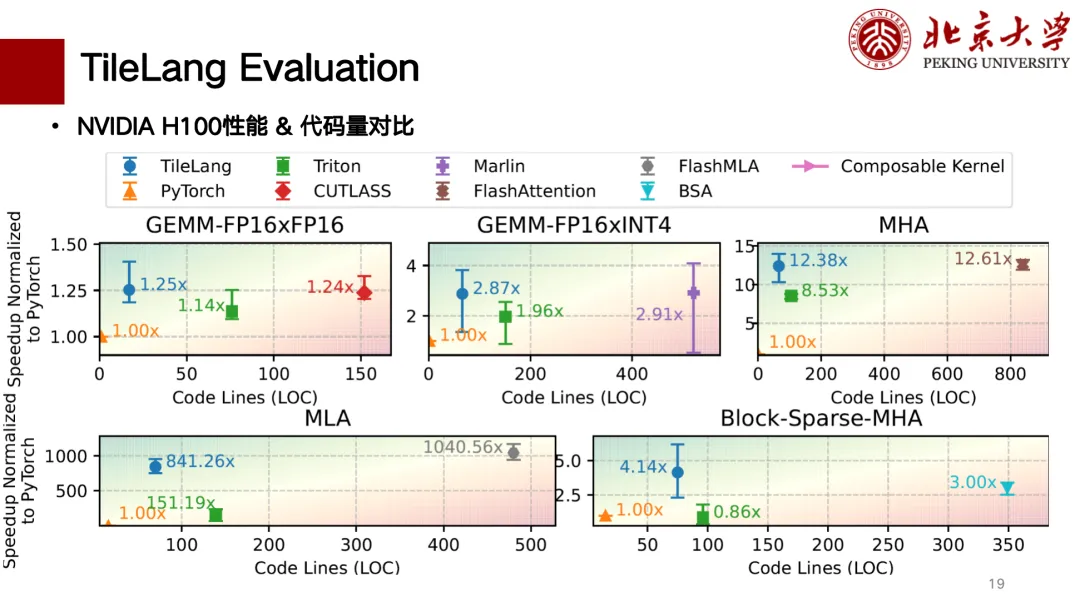
以下はTileLangの部分的なパフォーマンス評価です。主にHカードとAカードのサポートが完了しています。下の図は、コード行数とパフォーマンスの相関比較チャートです。左上に行くほどパフォーマンスが向上しています。その中でも、行列乗算において、TileLangはCUTLASSと同等のパフォーマンスを実現しています。また、MLA、Flash Attention、Block Sparseなどの演算子もCUTLASSと同等のパフォーマンスを実現しており、コード行数も比較的少なく、記述も比較的「クリーン」です。
TileLangエコシステムでは、既に一部のユーザーが利用しています。例えば、Microsoftの低精度大規模BitNetモデルのコア量子化演算子はTileLangをベースに開発されており、MicrosoftのBitBLASも完全にTileLangをベースにしています。国内チップのサポートに関しては、Suanneng TPUとAscend NPUにも一部サポートを提供しています。








