Command Palette
Search for a command to run...
トレーニングパフォーマンスが大幅に向上しました。BytedanceのZheng Size氏が、大規模モデルのための効率的な分散通信とコンピューティング統合を実現するTriton分散フレームワークについて説明します。

2025年、HyperAIが主催するMeet AI Complierテクノロジーサロンは7回目を迎えました。コミュニティパートナーや多くの業界専門家の支援を受け、北京、上海、深圳など各地に拠点を設け、開発者や愛好家のためのコミュニケーションプラットフォームを提供し、先端技術の謎を解き明かし、最前線の開発者からの応用フィードバックに耳を傾け、技術実装の実践経験を共有し、多角的な視点から革新的な思考に耳を傾けています。
WeChatパブリックアカウント「HyperAI Super Neuro」をフォローし、キーワード「0705 AI Compiler」に返信すると、認定講師の講演PPTを入手できます。




基調講演「Triton分散:高性能通信のためのネイティブPythonプログラミング」では、バイトダンスのシードリサーチサイエンティスト、鄭 サイズ氏大規模モデルのトレーニングにおける Triton 分散の通信効率とクロスプラットフォーム適応性の飛躍的な進歩、および Python プログラミングを通じて通信とコンピューティングの高度な統合を実現する方法について詳細に分析します。共有後、会場はすぐに質問のピークを迎え、FLUXフレームワーク、Tileプログラミングモデル、AllGatherとReduceScatterの最適化など、細部にわたる議論が尽きることなく続きました。議論は核心的な技術的難しさと実践経験に焦点を当て、理論と応用の融合を効果的に促進しました。
HyperAIは、鄭サイズ氏の講演を、本来の意図を損なうことなく編集・要約しました。以下は講演の書き起こしです。
分散トレーニングの真の課題
大規模モデルの急速な進化の文脈では、訓練と推論の両方が分散システムは欠かせないものとなっています。私たちはこの方向でコンパイラレベルの調査も実施し、プロジェクトをオープンソース化して Triton-Distributed と名付けました。
現在主流のハードウェア相互接続方式には、NVLink、PCIe、クロスノードネットワーク通信などがあります。理想的な条件下では、H100のNVLink単方向帯域幅は450GB/sに達しますが、国内の多くの導入では、単方向帯域幅が約200GB/sにとどまるH800が主流であり、全体的な通信能力とトポロジの複雑さが大幅に軽減されます。プロジェクトで私たちが直面した明らかな課題は、帯域幅の不足と非対称通信トポロジによって引き起こされるシステム パフォーマンスのボトルネックでした。
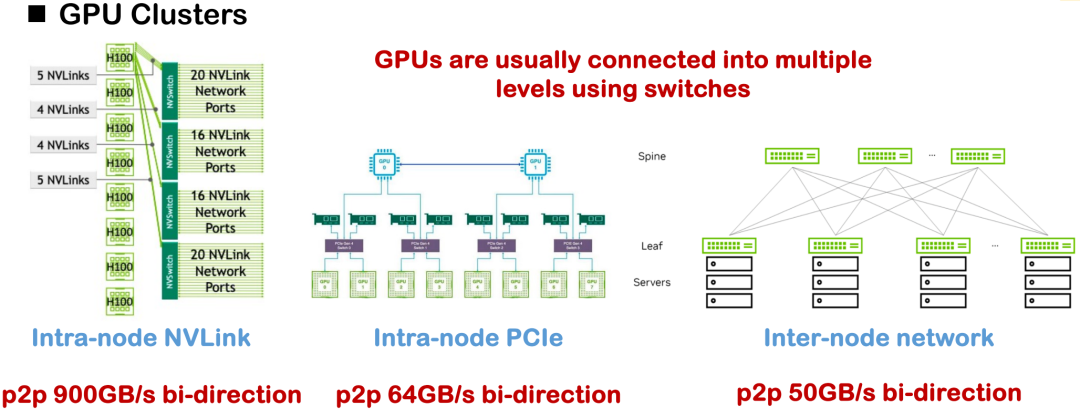
こうした状況を踏まえると、初期の分散最適化は、テンソル並列、パイプライン並列、データ並列といった戦略を含む、多数の手動で実装された通信演算子に依存することが多く、これらはすべて、基盤となる通信ロジックを慎重に記述する必要がありました。NCCLやROCm CCLといった通信ライブラリを呼び出すのが一般的な方法ですが、このようなソリューションは汎用性と移植性に欠け、開発コストと保守コストが高くなる場合が多くありました。
既存システムのボトルネックを分析したところ、次の 3 つの重要な事実が明らかになりました。
事実1: ハードウェア帯域幅は限られており、通信遅延がボトルネックになる
一つ目は、基本的なハードウェア条件によってもたらされる制限です。H100を用いて大規模モデルを学習する場合、計算遅延は通信遅延よりも大幅に大きくなることが多いため、計算と通信の重複スケジューリングに特別な注意を払う必要はありません。しかし、現在のH800環境では、通信遅延が大幅に長くなります。いくつかのシナリオでは、学習時間のほぼ半分が通信遅延によって消費され、全体的なMSU(モデルスケール使用率)が大幅に低下することが評価されています。通信と計算の重複が最適化されていない場合、システムは深刻なリソース浪費の問題に直面することになります。
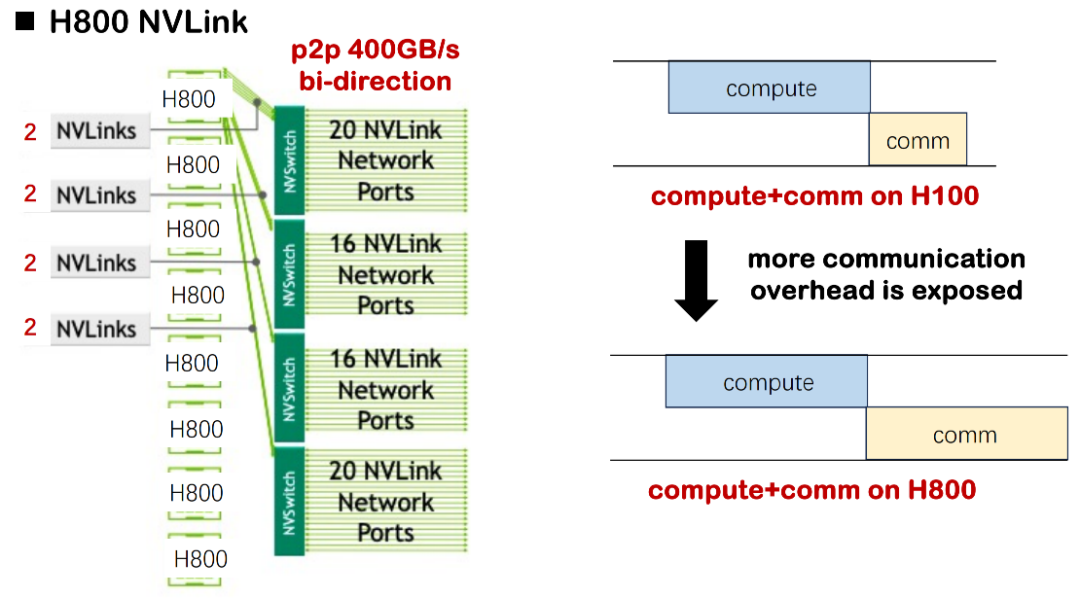
中小規模のケースでは、この損失は許容範囲内ですが、MegaScale や DeepSeek のトレーニング実践のように、モデルが数千枚のカードに拡張されると、累積リソース損失は数百万ドル、あるいは数千万ドルに達し、企業にとって非常に現実的なコスト圧力となります。
推論シナリオでも同様です。DeepSeekの初期の推論導入では、最大320枚のカードが使用されました。その後の圧縮と最適化にもかかわらず、通信遅延は依然として分散システムの避けられない中核的な問題です。そのため、プログラムレベルで通信と計算を効果的にスケジュールし、全体的な効率を向上させることは、私たちが真摯に取り組むべき重要な課題となっています。
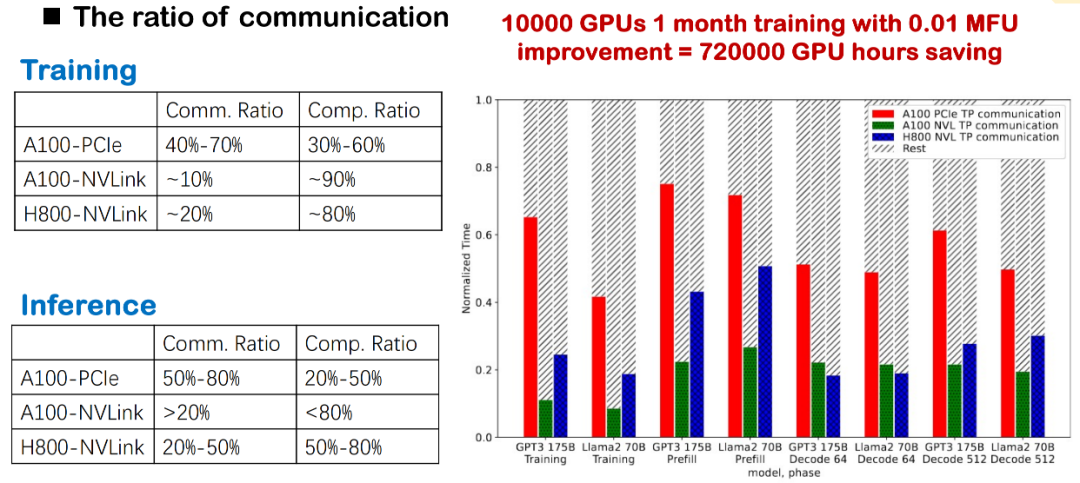
事実2: 高い通信オーバーヘッドはMFUのパフォーマンスに直接影響する
現在の大規模モデルの学習と推論において、通信オーバーヘッドは常に大きなボトルネックとなっています。基盤層がNVLink、PCIe、あるいは異なる世代のGPU(A100やH800など)のいずれを使用していても、通信の割合が非常に高いことが観察されています。特に実際の国内展開では、帯域幅の制限がより顕著であるため、通信遅延が全体的な効率を直接的に低下させます。
大規模モデルの学習において、この高頻度のカード間通信はシステムのMFUを大幅に削減します。したがって、通信オーバーヘッドの最適化は、学習と推論のパフォーマンスを向上させるための重要な改善点であり、私たちの重点領域の一つでもあります。
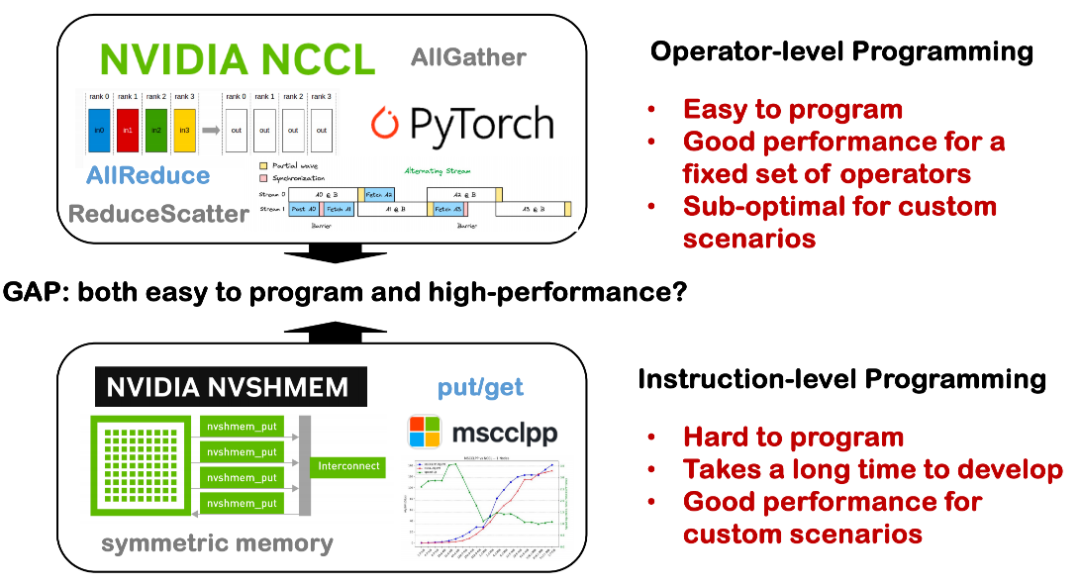
事実3: プログラミング性とパフォーマンスのギャップ
現在、分散システムにおけるプログラミング性とパフォーマンスの間には依然として大きなギャップが存在します。かつては、シングルカードコンパイラの最適化機能、例えばシングルカードで優れたパフォーマンスを実現する方法などに重点が置かれていましたが、複数のカードを搭載した単一マシン、あるいはノードをまたぐ分散システムに拡張すると、状況はより複雑になります。
一方で、分散通信にはNCCL、MPI、トポロジなど、多くの基盤となる技術的詳細が関係しており、これらは様々な専用ライブラリに散在しているため、利用の敷居が高いという問題があります。多くの場合、開発者は通信ロジックを手動で実装し、計算や同期を手動でスケジュールする必要があり、開発コストとエラー率の上昇につながります。一方、複雑な通信スケジューリングや分散環境におけるオペレータの最適化を自動で処理できるツールがあれば、開発者の開発敷居を大幅に下げ、分散システムの可用性と保守性を向上させることができます。これは、Triton-Distributedで解決したい課題の一つです。
上記の 3 つの実際的な問題に基づいて、Triton-Distributed では次の 3 つの中核的な方向性を提案しました。
まず、通信とコンピューティングの重複メカニズムを促進します。通信のオーバーヘッドがますます顕著になる分散シナリオでは、システム全体の効率を向上させるために、コンピューティングと通信の並列ウィンドウを可能な限りスケジュールしたいと考えています。
第二に、大規模モデルの計算モードと通信モードを深く統合し、適応させる必要があります。たとえば、AllReduce や Broadcast などの一般的な通信パターンをモデル内のコンピューティング パターンと統合して、同期待機を減らし、実行パスを圧縮しようとします。
最後に、これらの最適化は、開発者が高度にカスタマイズされた CUDA 実装を手動で記述するのではなく、コンパイラによって実行されるべきだと考えています。分散システムの開発をより抽象的かつ効率的にすることが、私たちが目指す方向性です。
Triton分散アーキテクチャ分析:高性能通信のためのネイティブPython
分散学習においてオーバーラップを実現したいのですが、実装は容易ではありません。概念的には、オーバーラップとは、複数のストリームを介して計算と通信を同時に実行し、通信遅延を隠蔽することを意味します。これは、演算子間に依存関係がないシナリオでは比較的容易ですが、Tensor Parallel(TP)やExpert Parallel(EP)では、AllGatherが完了するまでGEMMを実行できません。この2つはクリティカルパス上にあるため、オーバーラップは非常に困難です。
現在、一般的な手法としては、まずタスクを複数のマイクロバッチに分割し、バッチの独立性を保ちながらオーバーラップを実現する方法、次に単一バッチ内をより細かい粒度(タイル粒度など)で分割し、カーネル融合によって並列効果を実現する方法などがあります。Fluxでは、このタイプの分割およびスケジューリングメカニズムも検討しました。同時に、大規模モデルのトレーニングにおける通信モードは非常に複雑です。例えば、DeepSeekはMoEを実行する際に、帯域幅と負荷分散を考慮してAll-to-All通信をカスタマイズする必要があります。例えば、低遅延推論や量子化のシナリオでは、NCCLなどの汎用ライブラリでは性能要件を満たすのが難しく、多くの場合、手書きの通信カーネルが必要となり、カスタマイズコストが増加します。
したがって、私たちは複雑なモデル構造と多様なハードウェア環境に対応し、繰り返しの手動実装による開発負担を回避するために、通信とコンピューティングの融合の最適化機能はコンパイラ層で実行する必要があります。
2層通信プリミティブ抽象化
私たちのコンパイラ設計では、上位層の最適化表現能力と基礎となる展開の実現可能性の両方を考慮して、2 層通信プリミティブの抽象構造を採用しました。
最初のレイヤーは比較的高レベルのプリミティブであり、主にタイル粒度での計算スケジューリングを完了し、通信用の抽象インターフェースを提供します。ランク間のプッシュ/ゲット操作を通信の抽象化として使用し、タグ識別メカニズムを通じて各通信動作を区別することで、スケジューラがデータフローと依存関係を追跡しやすくなります。
2 番目の層は基盤となる実装に近いため、Open Shared Memory 標準 (OpenSHMEM) に似たプリミティブ システムを使用します。このレイヤーは主に、既存の通信ライブラリまたはハードウェア バックエンドにマッピングして、実際の通信動作を実装するために使用されます。
また、マルチランクのシナリオでは、ランク間の同期のためのバリアと信号制御メカニズムも導入する必要があります。たとえば、データが書き込まれたことを他のランクに通知する必要がある場合や、特定のランクのデータの準備が整うのを待機している場合、このタイプの同期信号は非常に重要です。

コンパイラアーキテクチャとセマンティックモデリング
コンパイルスタックに関しては、全体的なプロセスは依然としてオリジナルのTritonコンパイルフレームワークに基づいています。Tritonはソースコードから始めて、まずユーザーコードを抽象構文木(AST)に変換し、次にそれをTriton IRに変換します。私たちが構築したTriton-Distributedでは、オリジナルの Triton IR が拡張され、分散セマンティクス用の新しい IR レイヤーが追加されました。この分散IRは、waitやnotifyといった同期操作のセマンティックモデリングを導入し、ランク間の通信依存関係を記述します。同時に、OpenSHMEMが低レベルの通信呼び出しをサポートするためのセマンティックインターフェースセットも設計します。
実際のコード生成フェーズでは、これらのセマンティクスを基盤となる通信ライブラリへの外部呼び出しにマッピングできます。これらの呼び出しを、LLVM中間層を介してOpenSHMEMが提供するライブラリのビットコード版(ソースコードではなく)に直接リンクすることで、ランク間での効率的な共有メモリ通信を実現します。この手法は、Tritonがソースコードから外部ライブラリへの直接アクセスをサポートしていないという制限を回避し、共有メモリ関連の呼び出しがシンボル解決を完了し、コンパイル中にスムーズにリンクできるようにします。
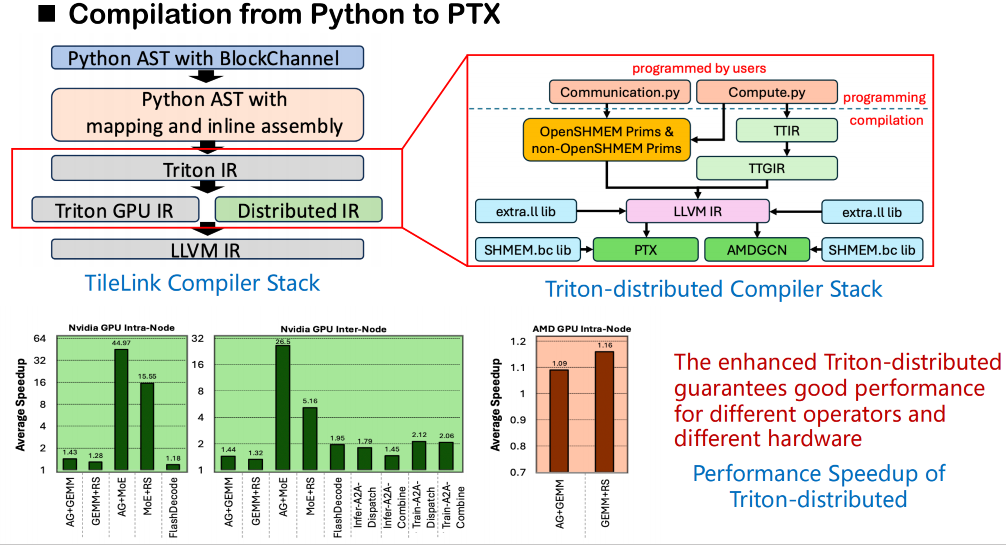
高レベルプリミティブと低レベル実行間のマッピングメカニズム
Triton-distributed では、高レベルの抽象化と低レベルの制御をカバーする通信プリミティブのシステムを設計しました。consumer_tile_wait を例に挙げると、開発者は待機するタイルIDを宣言するだけで、システムは現在の演算子セマンティクス(AllGatherなど)に基づいて通信対象の具体的なランクとオフセットを自動的に推測し、同期ロジックを完成させます。高レベルプリミティブによって特定のデータソースと信号伝送の詳細が保護されるため、開発効率が向上します。
対照的に、低レベルプリミティブはよりきめ細かな制御機能を提供します。開発者は、シグナルポインタ、スコープ(GPUまたはシステム)、メモリセマンティクス(取得、解放など)、期待値を手動で指定する必要があります。このメカニズムはより複雑ですが、通信レイテンシとスケジューリング精度に対する要件が非常に高いシナリオに適しています。
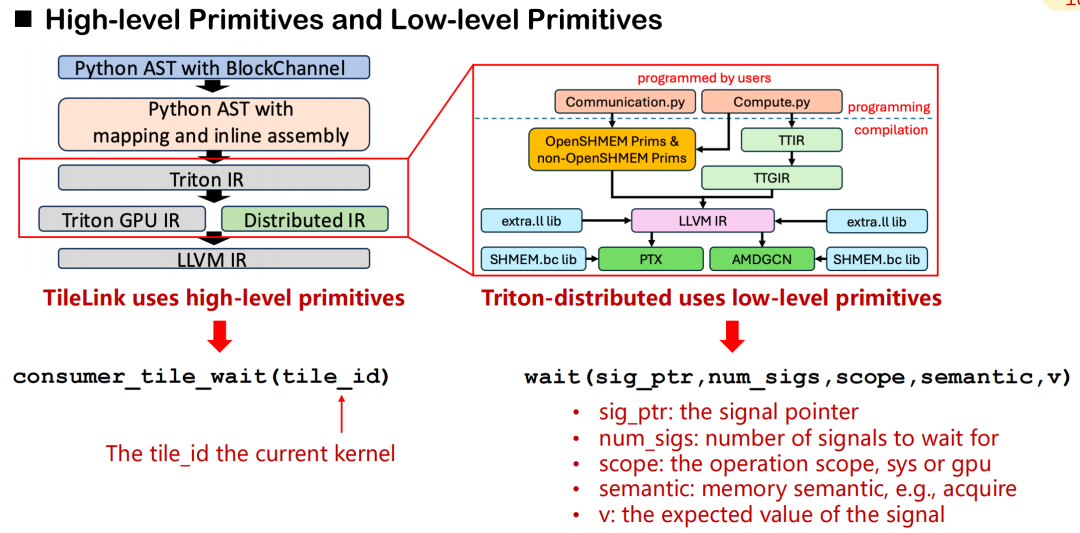
高水準プリミティブは、信号制御とデータ制御の2つのカテゴリーに大別できます。信号制御のセマンティクスでは、主に、プロデューサー、コンシューマー、ピアの 3 種類のロールを定義します。同期は読み取り信号と書き込み信号を介して実現されます。これは分散通信におけるハンドシェイク機構に似ています。データ転送に関しては、Triton-distributed はプッシュとプルという2つのプリミティブを提供します。これらは、リモートカードへのデータのアクティブ送信、またはリモートカードからローカルカードへのデータのプルに対応します。
すべての低レベル通信プリミティブはOpenSHMEM標準に準拠しており、現在NVSHMEMとROCSHMEMをサポートしています。高レベルプリミティブと低レベルプリミティブの間には明確なマッピング関係があり、コンパイラは簡潔なインターフェースを低レベルの同期および転送命令に自動的に変換します。このメカニズムにより、Triton 分散は、通信スケジューリングの高パフォーマンス機能を維持するだけでなく、分散プログラミングの複雑さも大幅に軽減します。
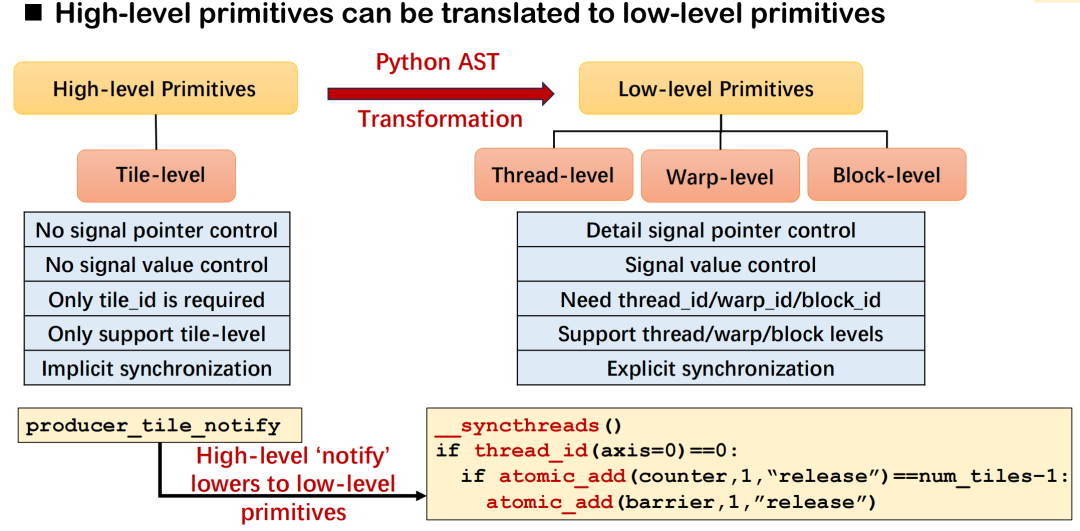
Triton分散型では、高水準通信プリミティブ(notifyやwaitなど)の設計目標は、カード間同期要件を簡潔なセマンティクスで記述することであり、コンパイラはそれらを対応する基盤実行ロジックに変換する役割を担います。notifyを例に挙げると、itとwaitは同期セマンティクスのペアを形成します。前者は通知の送信に使用され、後者はデータ準備の完了を待機するために使用されます。開発者はタイルIDを指定するだけで、システムはオペレータの種類と通信トポロジに基づいて、通信対象や信号オフセットなどの基盤の詳細を自動的に推測できます。
具体的な基盤実装は、デプロイメント環境によって異なります。例えば、8つのGPUを使用するシナリオでは、この種の同期はスレッド内で_syncthreads()とatomic_ddによって実現できます。一方、複数マシンにまたがるデプロイメントでは、NVSHMEMやROCSHMEMが提供するsignal_upなどのプリミティブを利用して同等の操作を実行します。これらのメカニズムは、高レベルのセマンティクスと低レベルのプリミティブ間のマッピング関係を構成し、優れた汎用性とスケーラビリティを備えています。
GEMM ReduceScatter通信シナリオを例に挙げてみましょう。システムには4つのGPUがあり、各タイルのターゲット位置は事前に計算されたメタ情報(タイル割り当てや各ランクのバリア番号など)によって決定されます。開発者は、Tritonで記述されたGEMMカーネルにnotify文を追加するだけで、ReduceScatterカーネルはwait文を使用して同期的にデータを受信します。
プロセス全体はPythonで表現でき、デュアルストリーム起動のカーネルモードもサポートしています。これにより、通信ロジックが明確になり、スケジューリングが容易になります。このメカニズムは、カード間通信プログラミングの表現力を向上させるだけでなく、基盤となる実装の複雑さを大幅に軽減し、大規模分散モデルの効率的な学習と推論のための強力な基本機能サポートを提供します。
多次元オーバーラッピング最適化:スケジューリング機構からトポロジー認識まで
Triton-distributedは比較的簡潔な高水準通信プリミティブインターフェースを提供していますが、カーネルの実際の記述と最適化のプロセスには依然として一定の技術的障壁が存在します。プリミティブ設計は優れた表現力を備えているものの、真に柔軟に適用し、深く最適化できるユーザーの数は依然として限られていることが観察されています。本質的に、通信の最適化は依然としてエンジニアリングの経験とスケジューリングの理解に大きく依存するタスクであり、現状では開発者が手動で制御する必要があります。この問題について、いくつかの主要な最適化パスをまとめました。以下は、Triton-distributedにおける典型的な実装戦略です。
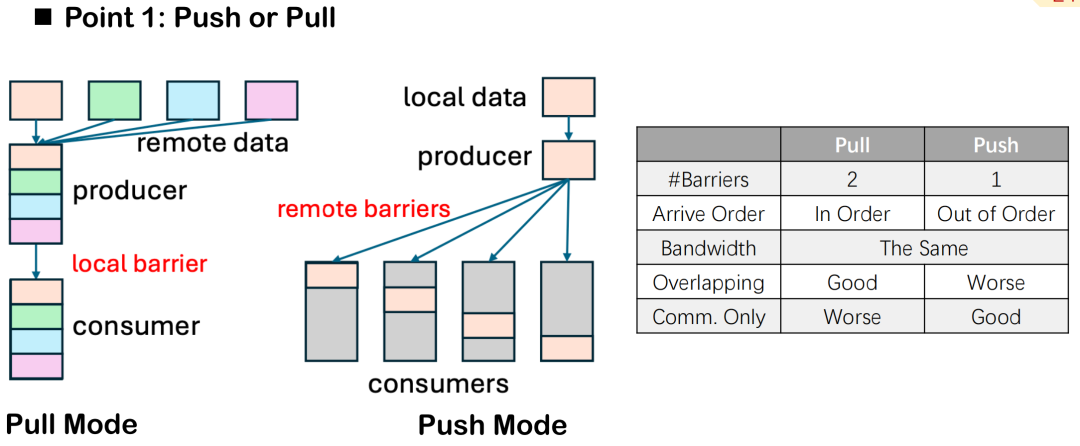
プッシュ vs. プル: データフローの方向とバリア数の制御
通信と計算の重複最適化では、Triton 分散では、プッシュとプルという 2 つのデータ転送方法が提供されます。両者の意味的な違いは「能動的な送信」と「受動的なプル」の方向だけですが、実際の分散実行においては、パフォーマンスとスケジューリング制御能力に明らかな違いがあります。
バリアの数を例に挙げると、プルモードでは通常2つのバリアが必要です。1つは、相手側がプルする前にローカルデータが準備されていることを確認するためのバリア、もう1つは、通信サイクル全体を通してローカルタスクによるデータの変更を防ぎ、データの不整合や読み書きの競合を防ぐためのバリアです。プッシュモードでは、データがリモートエンドに書き込まれた後、1つのバリアを設定するだけですべてのデバイスを同期できるため、全体的な制御が簡素化されます。
しかし、プルモードにも利点があります。ローカルノードがデータのプル順序を能動的に制御できるため、通信のタイミングと計算の重複をより正確にスケジュールできます。重複効果を最大化し、通信と計算の並列性を実現したい場合、プルモードはより柔軟な選択肢となります。
一般に、主な目的がオーバーラップの改善である場合は、プル モードが推奨されます。別の AllGather カーネルや ReduceScatter カーネルなどの純粋な通信タスクでは、シンプルでオーバーヘッドが低いため、プッシュ モードの方が一般的です。
スウィズリングスケジューリング:データの局所性に基づいて順序を動的に調整する
通信と計算のオーバーラップは、プリミティブの選択だけでなく、スケジューリング戦略にも依存します。中でも、Swizzlingはトポロジ認識に基づくスケジューリング最適化手法であり、カード間コンピューティングにおける実行アイドル状態の削減を目的としています。分散の観点から見ると、各GPUカードは独立した実行ユニットと見なすことができます。各カードは初期状態で異なるデータフラグメントを保持しているため、すべてのカードが同じタイルインデックスから計算を開始すると、一部のランクはデータの準備ができるまで待機する必要があり、実行フェーズで長いアイドル期間が発生し、全体的な計算効率が低下します。
Swizzlingの核となる考え方は次のとおりです。開始計算オフセットは、各カード上の既存のローカル データの場所に基づいて動的に調整されます。例えば、AllGatherシナリオでは、各カードは自身のデータの処理を優先し、同時にリモートタイルからのプルを開始することで、通信と計算の同時スケジューリングを実現します。すべてのカードがタイル0から処理を開始する場合、ランク0のみが即座に計算を開始でき、残りのランクはデータ待ちによるシリアル遅延が発生します。
マシン間ReduceScatterシナリオのようなより複雑な状況では、Swizzling戦略はネットワークトポロジと組み合わせて設計する必要があります。2つのノードを例にとると、合理的なスケジューリング方法は、もう一方のノードが必要とするデータの計算を優先し、マシン間ポイントツーポイント通信をできるだけ早くトリガーし、送信プロセス中にローカルノードが必要とするデータを並列計算することで、通信と計算の重複効果を最大化することです。
現在、この種のスケジューリング最適化は、コンパイラが一般的な最適化において主要なパフォーマンスパスを犠牲にすることを避けるため、依然としてプログラマーによって制御されています。また、Swizzlingなどの詳細を理解することは、開発者にとって一定のハードルであることも認識しています。今後は、より実践的なケースとテンプレートコードを提供することで、開発者が分散オペレータ開発モデルをより迅速に習得し、オープンで効率的なTriton分散プログラミングエコシステムを段階的に構築できるよう支援したいと考えています。

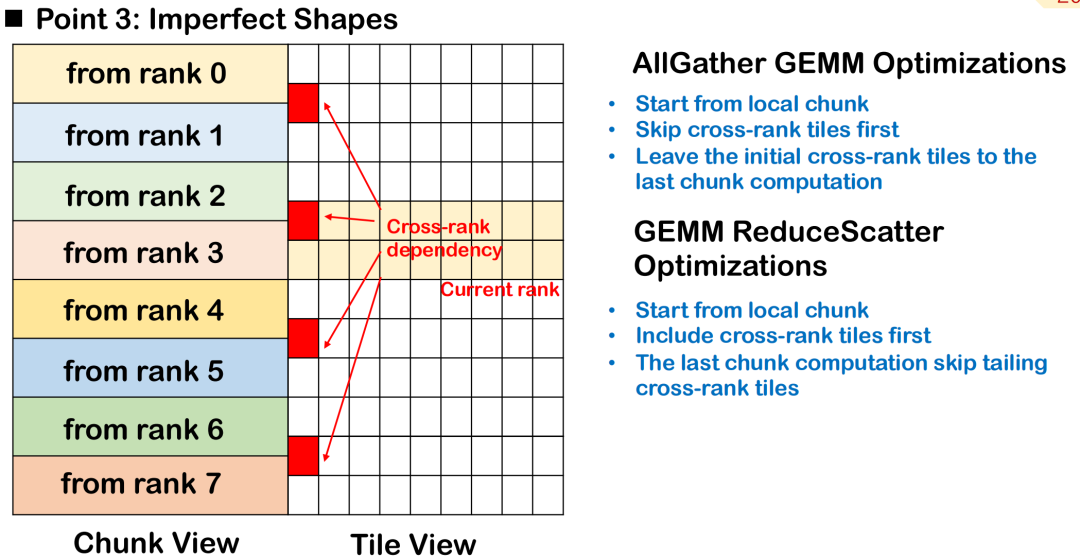
不完全なブロックスケジューリング: ランクタイル間の処理優先順位
実際の大規模モデルのトレーニングおよび推論のシナリオでは、特にトークンの長さが固定されていない場合、演算子の入力形状は不規則になることが多く、タイル ブロックを整然と均一に保つことが困難です。この不完全なタイリングにより、一部のタイルが複数のランクにまたがり、同じタイルのデータが複数のデバイスに分散され、スケジュールと同期の複雑さが増します。
AllGather GEMMを例に挙げると、あるタイルにローカルデータとリモートデータの両方が含まれているとします。このタイルから計算を開始すると、リモートデータが最初に送信されるまで待機する必要があり、これにより追加のバブルが発生し、計算全体の並列性に影響を及ぼします。より良いアプローチは、このクロスランクタイルをスキップし、完全にローカルで利用可能なデータの処理を優先し、リモート入力を待機するタイルを最後に実行するようにスケジュールすることで、通信と計算のオーバーラップを最大限にすることです。
ReduceScatterシナリオでは、スケジューリング順序を逆にする必要があります。ランク間タイルの計算結果はできるだけ早くリモートエンドに送信する必要があるため、リモートノードが依存するタイルを優先し、マシン間データ転送をできるだけ早く完了させ、リモートへの依存を減らすことが最善の戦略です。
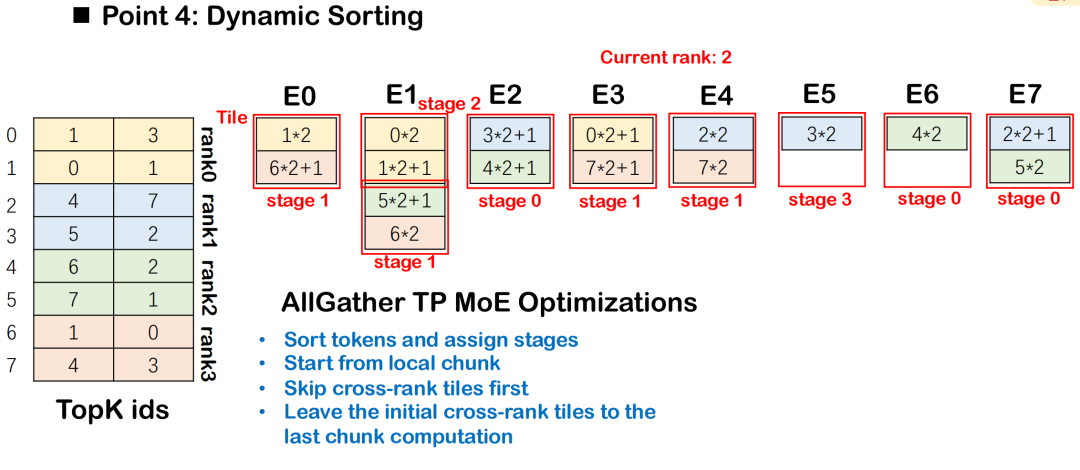
MoEによる動的ソート戦略
MoE(Mixture-of-Experts)モデルでは、ルーティング結果に基づいてトークンを複数のエキスパートに分配する必要があり、通常はAll-to-All通信とグループGEMM計算が伴います。通信とコンピューティングの重複効率を向上させるため、Triton-distributedではダイナミックソーティングを導入しています。ダイナミックソーティングは、通信データへの依存度に応じてコンピューティングタスクを段階的にスケジュールし、データ依存度の低いタスクを優先します。
この順序付けにより、各ステージの計算を可能な限り低い通信ブロックで開始できるようになり、All-to-All と Group GEMM 間のオーバーラップが改善されます。全体的なスケジュールは、データ依存性が最も少ないタイルから開始され、複雑な依存性を持つタイルに徐々に拡張され、実行の同時実行性が最大化されます。
ハードウェアベースの通信アクセラレーション
Triton-distributed は、特定のハードウェア機能と組み合わせた通信の最適化もサポートします。特にNVSwitchアーキテクチャを使用する場合、内蔵のSHARPアクセラレータを使用して低レイテンシの通信計算を実行できます。このモジュールは、BroadcastやAllReduceなどの操作をスイッチチップ内で完了させることで、伝送パスにおけるデータ集約の高速化を実現し、レイテンシと帯域幅の消費を削減します。関連命令はTriton-distributedに統合されており、対応するハードウェアを持つユーザーはそれらを直接呼び出すことで、より効率的な通信カーネルを構築できます。
AOT コンパイルの最適化: 推論のレイテンシのオーバーヘッドを削減
Triton-distributed は AOT (Ahead-of-Time) メカニズムを導入します。これは、推論シナリオにおける極めてレイテンシに敏感な要件に特化して最適化されています。Triton はデフォルトで JIT (Just-In-Time コンパイル) コンパイル方式を使用するため、関数の初回実行時には大きなコンパイルおよびキャッシュのオーバーヘッドが発生します。
AOTメカニズムにより、ユーザーは関数を実行前にバイトコードにプリコンパイルし、推論フェーズで直接ロードして実行することができます。これにより、JITコンパイルプロセスを回避し、コンパイルとキャッシュによる遅延を効果的に削減できます。これに基づき、Triton-distributedはAOTメカニズムを拡張し、分散環境におけるAOTコンパイルとデプロイメントをサポートすることで、分散推論のパフォーマンスをさらに向上させました。
パフォーマンス測定とケース再現
私たちは、NVIDIA H800、AMD GPU、8 カード GPU、およびクロスマシン クラスターを網羅したマルチプラットフォームおよびマルチタスク シナリオでの Triton 分散のパフォーマンスの包括的なテストを実施し、PyTorch や Flux などの主流の分散実装ソリューションと比較しました。
8枚のGPUカードでは、Triton 分散は、AG GEMM および GEMM RS タスクで PyTorch 実装と比較して大幅な高速化を実現します。手動で最適化されたFluxソリューションと比較しても、Swizzlingスケジューリング、通信オフロード、AOTコンパイルといった複数の最適化により、優れたパフォーマンスを実現しています。同時に、AMDプラットフォーム上のPyTorch + RCCLの組み合わせと比較すると、全体的な加速はわずかに小さいものの、大幅な最適化も実現しています。主な制限は、テストハードウェアの計算能力の低さと、スイッチなしのトポロジに起因しています。
AllReduceタスクでは、私たちがテストしたハードウェア構成では、小さいメッセージから大きいメッセージまでさまざまなメッセージ サイズで、Triton 分散型は NCCL に比べて大幅に高速化され、平均で約 1.6 倍の高速化が見られました。Attentionシナリオでは、主にgather-KV型のAttention演算をテストしました。PyTorch Touchのネイティブ実装と比較すると、8枚のGPUカード上でTriton-distributedのパフォーマンスは約5倍向上しました。また、オープンソースのRing Attention実装と比較しても約2倍の向上が見られました。
クロスマシンテスト:AG GEMM は 1.3 倍、GEMM RS は 1.4 倍高速で、Flux よりわずかに低くなりますが、形状の柔軟性とスケーラビリティの点でより多くの利点があります。高速推論シナリオにおいて、単一トークンのデコードもテストしました。1Mトークンのコンテキストでレイテンシは20~30マイクロ秒以内に制御され、NVLinkおよびPCIeと互換性があります。
さらに、DeepEPの分散スケジューリングロジックを再現し、主にAll-to-Allルーティングとコンテキスト分散戦略を整合させました。64枚未満のカードを使用するシナリオでは、Triton分散のパフォーマンスはDeepEPとほぼ同じで、一部の構成では若干の改善が見られました。
最後に、Qwen-32Bをベースにしたプリフィルおよびデコードデモも提供しており、8枚のGPUカードへの展開と動作をサポートしています。実際のテストでは、推論の高速化効果が約1.2倍になることが示されています。
オープンな分散コンパイルエコシステムの構築
当社は現在、カスタマイズされた重複シナリオという課題に直面しており、これまでは主に手動による最適化に頼って解決してきましたが、これは労力とコストがかかっていました。私たちはTriton分散フレームワークを提案し、オープンソース化しました。Triton をベースに実装されていますが、各企業がどのようなコンパイラや基盤となる通信ライブラリを使用していても、統合してオープンな分散エコシステムを構築できます。
この分野は中国のみならず世界でもまだ比較的空白地帯です。私たちはコミュニティの力を活用し、より多くの開発者の参加を促し、構文設計、パフォーマンス最適化、あるいはより多くの種類のハードウェアデバイスへのサポートなど、様々な分野で技術進歩を共に促進したいと考えています。最終的に良好なパフォーマンスを達成し、関連する事例はすべてオープンソース化されました。積極的にコミュニケーションのための問題を提起していただき、より多くのパートナーがより良い未来を築くために私たちと一緒になることを期待しています。








