Command Palette
Search for a command to run...
建築的特徴からエコシステム構築まで、Muxi Dong Zhaohuaは国産GPUにおけるTVMの応用実践を深く分析する

7月5日、HyperAI主催の第7回Meet AI Compiler Technology Salonが盛況のうちに終了しました。GPUアーキテクチャの根底にあるイノベーションからクロスハードウェアコンパイルエコシステムのトップレベル設計、シングルチップ演算の最適化からマルチノード分散コンパイルのブレークスルーまで…AIコンパイル分野の実務家と研究者が一堂に会し、この最先端の技術の饗宴が繰り広げられました。会場は人で溢れ、活気あふれる交流の雰囲気に包まれました。
WeChatパブリックアカウント「HyperAI Super Neuro」をフォローし、キーワード「0705 AI Compiler」に返信すると、認定講師の講演PPTを入手できます。
このイベントでは、AMDのアーキテクトである張寧氏がAMD GPUプラットフォームにおけるTritonコンパイラの性能最適化の秘密を詳細に分析し、Pythonコードで高性能GPUカーネルを簡単に制御する方法を明らかにしました。Muxi Integrated Circuitのディレクターである董兆華氏は、国産GPUにおけるTVMアプリケーションの実践的な経験を持ち寄り、独立チップとオープンソースのコンパイルフレームワークとの衝突の火花を見せました。ByteDanceの研究者である鄭寸氏は、Triton分散の謎を解き明かし、Pythonが分散通信の性能上限をいかにして覆すかを共有しました。北京大学の王磊博士が持ち込んだTileLangは、演算子開発の効率限界を再定義します。




基調講演「Muxi GPUでのTVMアプリケーション実践」では、Muxi Integrated CircuitのシニアディレクターであるDong Zhaohua氏は、同社のGPU製品の技術的特徴、TVMコンパイラ適応ソリューション、実際の応用事例、エコシステム構築ビジョンを紹介しました。これは、高性能コンピューティングと AI の分野における国産 GPU の技術的進歩と応用の可能性を実証しました。
HyperAIは、董兆華教授の講演を、本来の趣旨を損なうことなく編集・要約しました。以下は講演の書き起こしです。
Muxi GPUの紹介
Muxi GPUは現在、Nシリーズ、Cシリーズ、Gシリーズなど複数の製品ラインを擁し、AIのトレーニングや推論から科学計算まで、幅広い用途をカバーしています。多層ソフトウェアスタックを構築することで、主流のフレームワークとのシームレスな統合を実現しています。ソフトウェアスタックの中核モジュールであるコンパイラは、ユーザーフレンドリーなプログラミングインターフェースを提供し、上位アプリケーションの最適化、異なるマシンアーキテクチャに応じたマシンコードを生成し、GPUに渡して実行させる役割を担っています。エンジニアによる綿密な調整を経て、その性能は国際的に先進的なレベルに達し、業界の主流コンピューティングライブラリとの適合関係も構築されています。
Muxi GPU には豊富な命令レベルの関数インターフェースがあります。当社が独自に開発したMACA Cインターフェースは、C言語の拡張を基盤とし、特定分野の文法要素を統合し、主要メーカーの基盤プログラミングインターフェースと機能的に同等であるため、開発者は移行と適応を迅速に完了できます。同時に、Python、Triton、Fortranといった多様なプログラミングインターフェースを提供し、OpenACCやOpenCLといった並列プログラミング標準をサポートし、自動並列化コード生成の効率に優れています。
また、Muxi GPU は GPGPU (汎用グラフィックス プロセッシング ユニット) アーキテクチャを採用しています。LLVM ベースのコンパイル システムは、高級言語から低レベルのマシン コードまでプロセス全体の最適化をサポートし、開発効率とハードウェア パフォーマンスの両方を考慮し、高性能なソフトウェア スタックを提供します。
Muxi GPU での TVM 適応
オープンソースのディープラーニングコンパイラであるTVMは、ディープラーニングモデルを様々なハードウェアで効率的に実行できるコードに変換できます。Muxiチームは、自社GPUの特性に基づいて包括的なTVM適応ソリューションを構築し、モデル定義からハードウェア実行までの全プロセス最適化を実現しました。
コンパイラアーキテクチャの観点からは完全なサポートが実現されています。そして理論的には、4 つのコア レベルに接続できます。
C++インターフェースの適応については、解決策としてMACA言語への変換を検討しています。このプロセスは非常に困難であり、ツールベースの自動変換の実装にはいくつかの課題があります。
コード抽象度が高いほど、クロスレベル適応が容易になります。また、LLVMに接続する際には、バージョン互換性の問題に注意する必要があります。LLVMには多くのバージョンが存在するため、特定のバージョンへの適応は対応するバージョンのサポート状況に依存し、バージョンの不一致によって異常なコンパイルプロセスが発生する可能性があります。
Muxi Arch の GPU 適応に関しては:
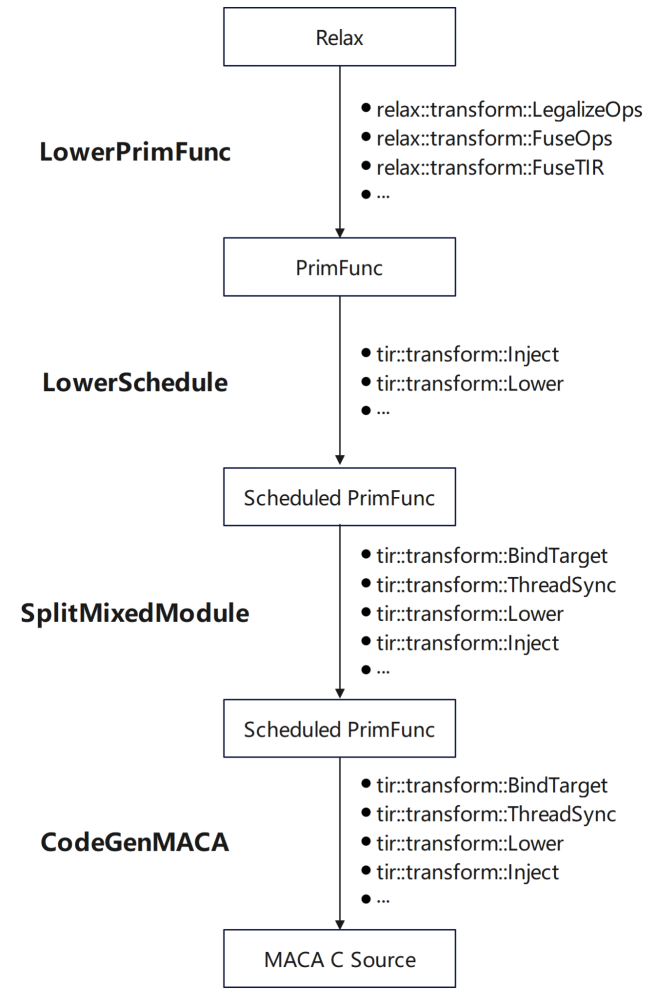
tvm.Target は MACA ターゲットを追加し、各ステージのサポートを追加します。まず、一般的な GPU プロセスを再利用するために、transform/lower に MACA ターゲットのパイプラインを追加します。次に、チューニング ステージに MACA ターゲットのスケジュール ルールを追加します。最後に、CodeGenMACA のサポートを追加し、MACAC コードをコンパイルします。
さらに、MACA デバイスと MACA ランタイム API の使用が tvm.Device に追加され、MACA デバイスでのメモリ操作や実行時のカーネルの起動などが含まれます。
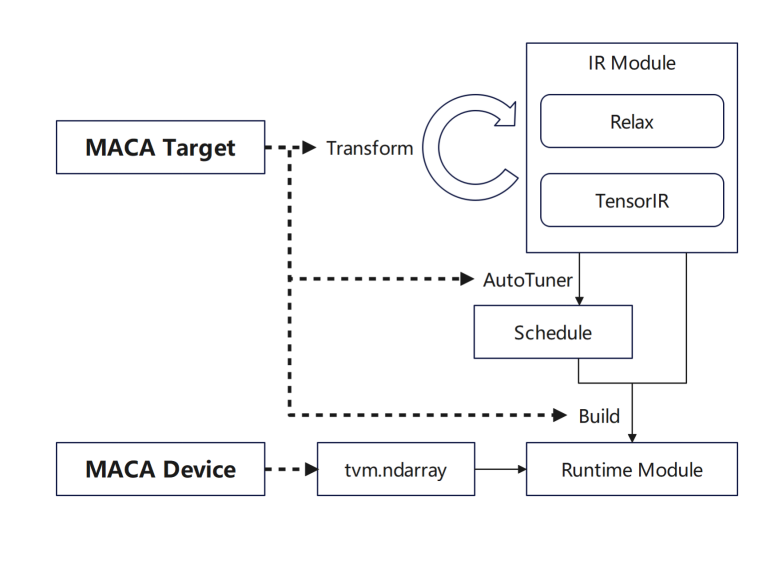
現在、当社の多くの製品は TVM レベルでサブデバイスをサポートしており、バックエンドはサブデバイスに基づいてさまざまな製品の最適化アクションを実行します。異なる製品では、コンパイラはデバイス タイプの違いに基づいて対応する適応ソリューションを自動的に選択します。同時に、バッチ コンパイルのシナリオでは、さまざまなアーキテクチャに対して固定の選択構成を作成しようとしています。一般的なコンパイルフェーズでは、コンパイラは特定の構成に基づいて、さまざまなアーキテクチャの関数関連のコンパイル ルールを動的に調整します。
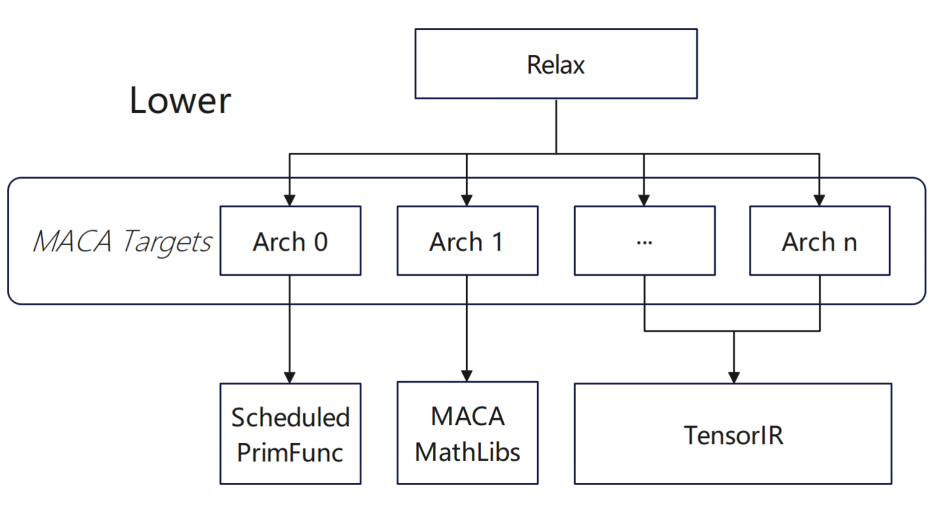
オペレータの適応に関しては、主に次のような上位レベルの構成を行いました。
* 下位スケジュールでは、TIRスケジュールプリミティブを介してPrimFuncにスケジュールを追加します。
* 分割混合モジュールにターゲットやその他の情報を追加し、maca組み込みを注入し、MACAの同期命令を追加します。
* CodeGenMACA の場合は、MACA が依存するヘッダー ファイルをインクルードし、tir.mma 関連命令から maca wmma api の使用を生成し、異なるタイプの変数を宣言して使用します。
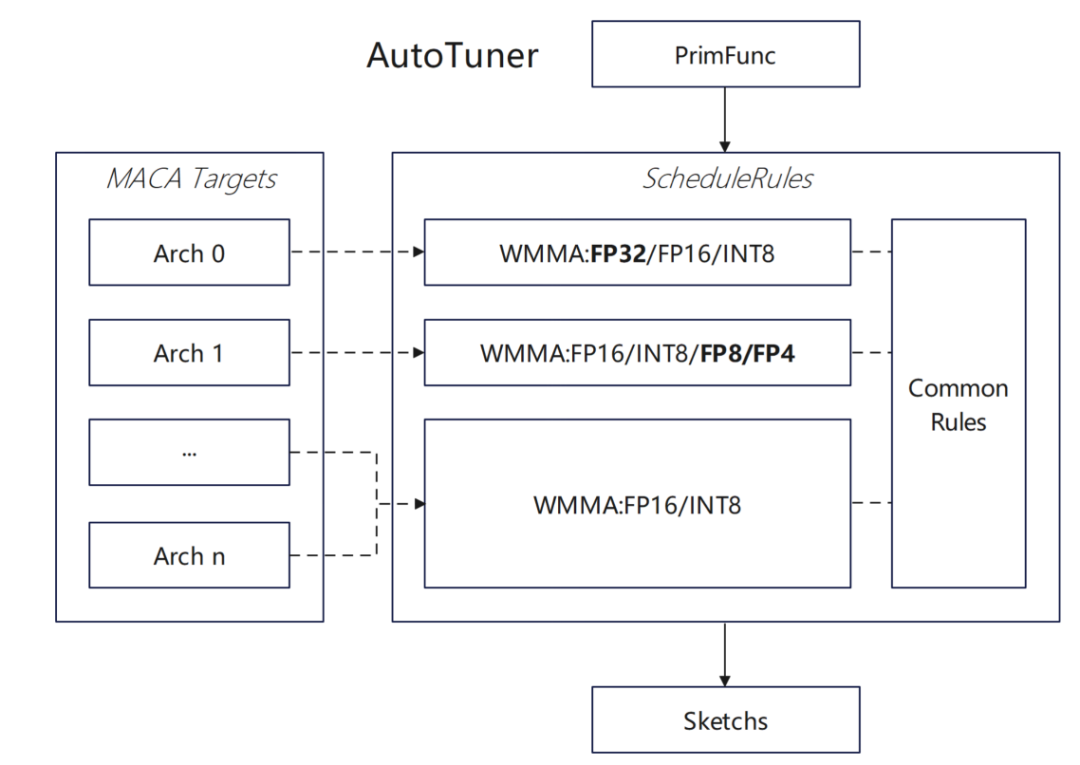
適応プロセスでは、より良いパフォーマンスを実現するために、その特性に基づいて特別な処理を実行しました。
* チューニング中にテンソライズを有効にできません: conv2d 演算子パラメータ グループが 1 ではなく、MACA 演算子ライブラリの実装が TOPI で直接使用されています。
* onnxモデルインポート後のカスタマイズされた演算子:Multi Head AttentionV1演算子は、MACA onnxランタイムで高度に最適化されています。演算子の呼び出しはcontribにカプセル化されているため、TVMはonnxモデルをインポートした後、手動で最適化された高性能演算子実装を直接使用できます。
私たちにとって、ベンダーカスタムの最適化演算子は、Python および MAC A で実装される可能性が高くなります。
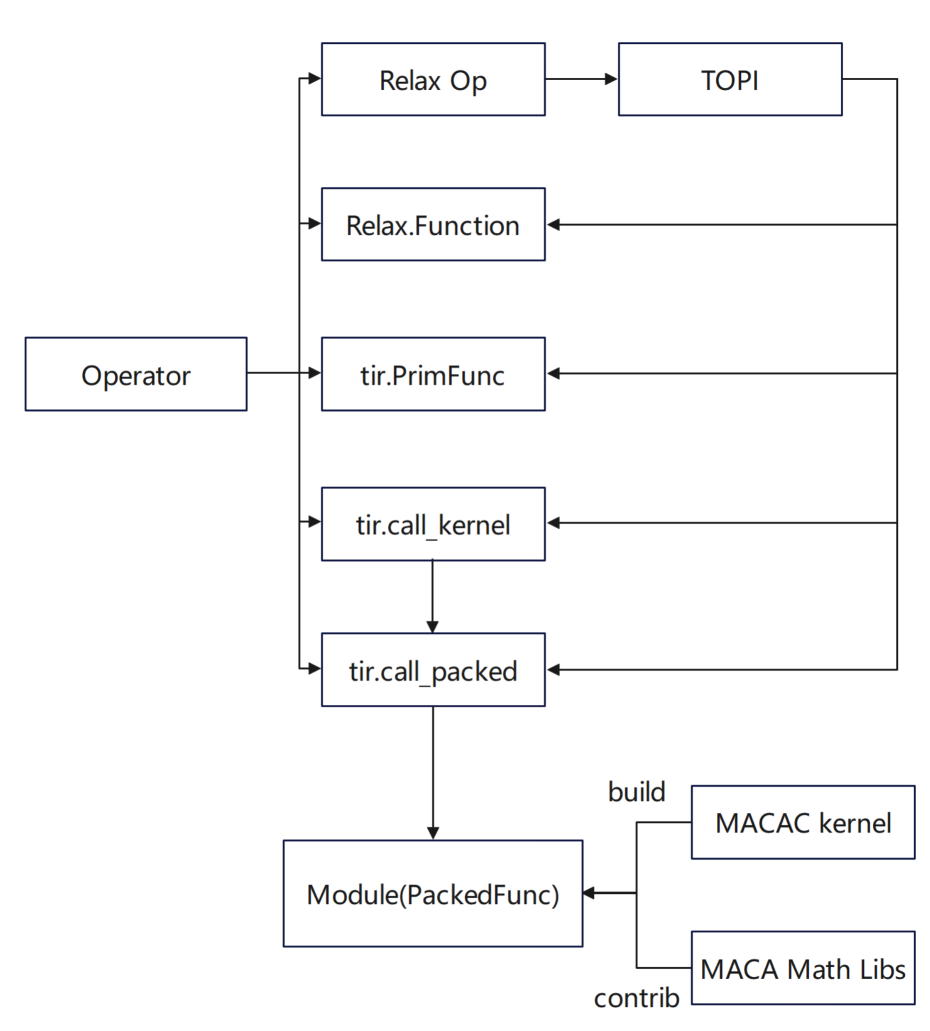
* Pythonインターフェースでは、Relax.Functionは基本演算子を組み合わせて定義されます。tir.PrimFuncはtirを使用して演算子の実装を定義し、必要に応じてスケジュールを追加します。
* MACA C インターフェースでは、 tir.call_packed が高性能演算子ライブラリの実装をカプセル化して使用します。tir.call_kernel は、MACA C で実装されたカーネル コードを使用し、TVM スタックを通じて PackedFunc 呼び出しにコンパイルします。
さらに、Muxi GPUのハードウェア特性を最大限に発揮するために、チームは TVM スケジューリング アルゴリズムを徹底的に最適化しました。
* MACAターゲットのWMMA float32型のサポートを追加しました:
まず、MACA で float32 タイプの wmma API をサポートし、MACA ScheduleRules に float32 タイプの自動テンソライズ ルールを追加して、TVM がハードウェア WMMA を自動的に識別して使用できるようにします。また、dlight 最適化フレームワークに対応する float32 テンソライズ最適化を追加して、行列演算の効率を向上させます。
* 非同期コピーがスケジューリング アルゴリズムに与える影響を評価します。
1 つのグループをロードして 1 つのグループを計算することから、次のデータ グループを非同期にロードして現在のデータ グループを同期的に計算することまで、複数の wmma 計算を最適化し、パイプラインの効率を改善し、MACA ScheduleRules でソフトウェア パイプラインの最適化ロジックを有効にし、MACA ターゲットの非同期コピー命令の挿入とコード生成を追加します。
新しいデータ型をサポートするための試みもいくつか行いました。DataType システムで MACA ターゲット適応を有効にします。MACA ScheduleRules で Float8 型の自動テンソライズ ロジックをサポートし、TVM の Float8 などのカスタム データ型のサポートを拡張します。CodeGenMACA で Float8 型変換と演算コード生成のサポートを実装し、maca_half_t.h で関連する演算定義を補足します。
Muxi GPU上のTVMアプリケーション
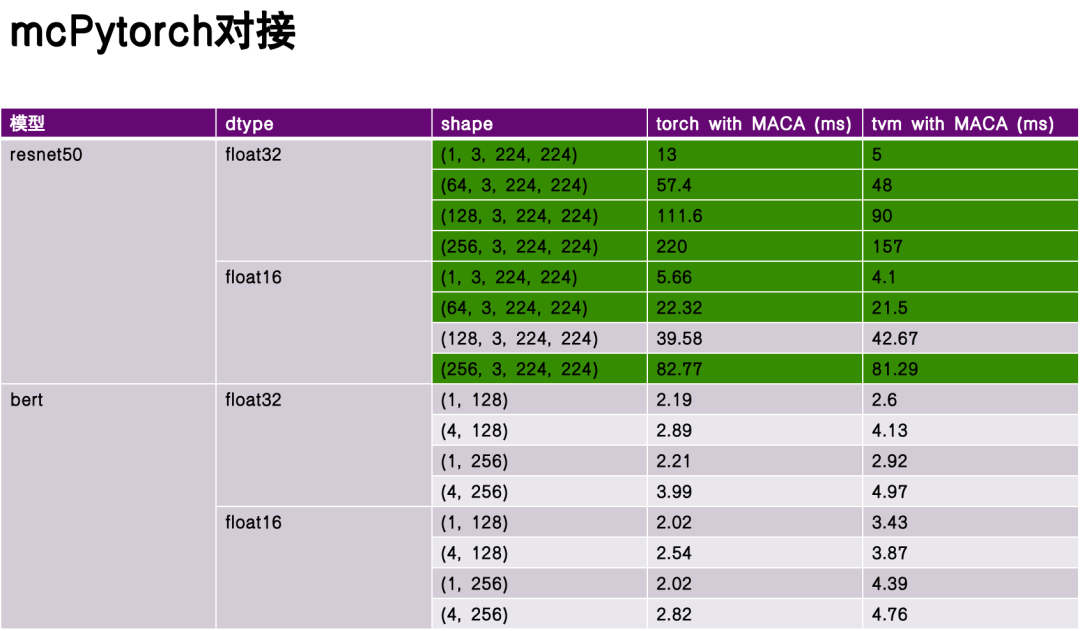
フレームワーク設計に関しては、チームは 2 つのアクセス方法を実装しました。1 つは、Torch モデルを直接インポートして Relay フロントエンドで実行する方法であり、もう 1 つは、torch.compile を使用して TVM をバックエンドとして使用する方法です。上位フレームワークと基盤となるハードウェア間の効率的な接続を実現します。
パフォーマンス評価フェーズでは、ベンチマーク モデルとして ReseNet50 と Bert を選択し、深い最適化を行わない Torch と TVM のコンパイルおよび実行のパフォーマンスを比較しました。実験データによれば、TVM はいくつかの面で大きな利点があり、いくつかのシナリオではそのパフォーマンスがトーチを上回っています。これは、TVM 中間表現 (IR) の柔軟性と、ハードウェア特性に合わせた最適化によるものです。
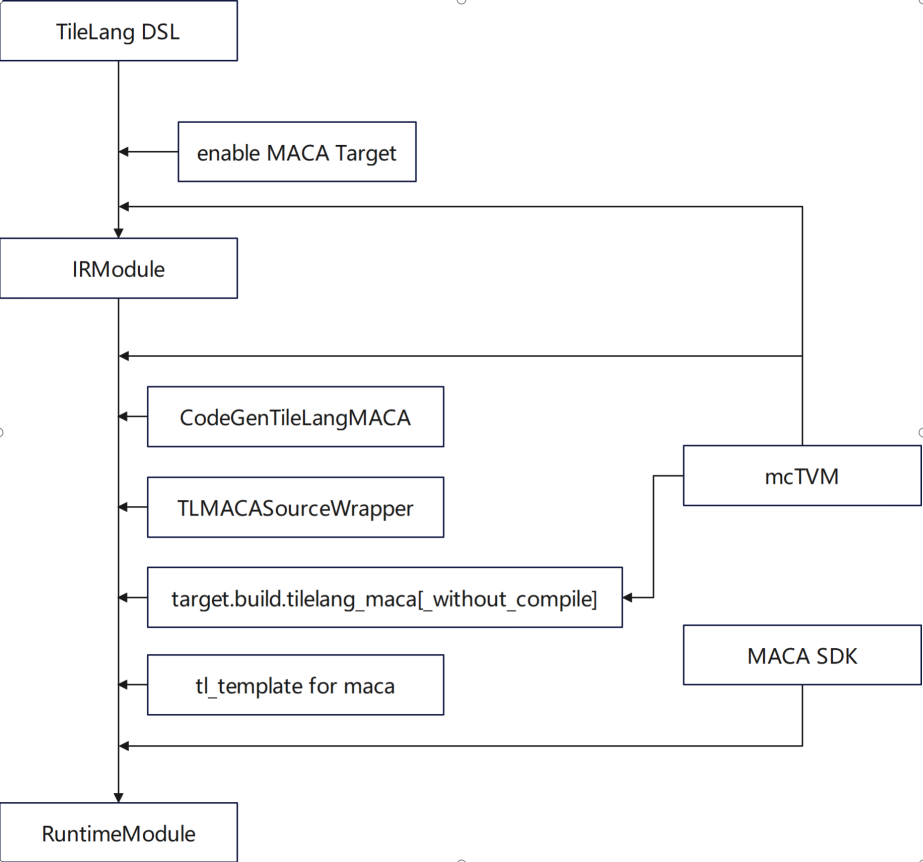
TileLang は、TVM エコシステムのドメイン固有言語 (DSL) であり、テンソル コンピューティングの洗練された最適化に重点を置いています。私たちのチームは、以下の側面において徹底的な機能適応を実施しました。* MACA ターゲットの使用をサポート * MACA C カーネル コードを生成するために CodeGenTileLangMACA を追加 * 依存関係として mcTVM を置き換えて使用 * libgen、アダプタ、ラッパーに MACA ターゲットの処理ロジックを追加 * tl_template で gemm を使用して MACA ターゲット定義を追加
最適化の点では、作業は主に tl_template での gemm の実装と、Muxi GPU の特性に適応するアルゴリズムの実装を中心に展開されます。
ベンダーとコミュニティ間の相互作用という点では、TileLang の設計と開発は、次の 3 つの主要原則のバランスを取る必要があります。
言語設計の観点から言えば、最初に解決すべきことは、抽象化と高パフォーマンスのバランスです。具体的には、複数のコンピューティングユニットを扱う場合、コンパイラは柔軟な戦略選択メカニズムを提供する必要があります。つまり、基盤となるハードウェア特性を深く理解している開発者が具体的なコード生成パスを指定できるようにすると同時に、一般の開発者が基盤の詳細を意識することなく、抽象インターフェースを通じて効率的なプログラミングを実現できるようにする必要があります。このバランスこそが、DSLであるTileLangが設計段階で重視すべき中核的な要素です。
第二に、ベンダーのカスタマイズされた構成と DSL の標準化を考慮する必要があります。コンパイラは、例えば、ループアンローリングレベルや継承圧力といった基本的なコンパイル戦略をパラメータを通して調整し、より優れたコード生成結果を得ることができるなど、マルチレベルの最適化オプション設定をサポートする必要があります。同時に、様々なハードウェアアーキテクチャに対して、コンパイラはターゲットを絞った最適化のヒントやアノテーションメカニズムを提供することで、開発者がハードウェア特性に応じて最適なコンパイルパスを選択し、開発効率を向上させることを支援する必要があります。
三番目、製品世代間のインターフェースの連続性を確保する必要があります。コンパイラと言語ツールチェーンの反復プロセスにおいては、インターフェース設計の後方互換性を確保する必要があります。つまり、現在のバージョンのコンパイルロジックと生成コードは、次世代のハードウェア製品でも引き続き効果的に動作し、アーキテクチャの反復に伴うコード再構築コストを回避できるということです。この継続性はエコシステム構築の基盤であり、非互換性による「減算的」な損失ではなく、コンパイラツールチェーン機能の「加算的」な蓄積を実現します。同時に、ユーザーの学習コストと移行コストを削減し、使用上の混乱を回避することができます。
課題と機会
最後に、業界の現在の発展が直面している課題と機会についてお話ししたいと思います。課題は主に以下の側面に反映されます。
1 つ目は、フレームワークとアプリケーション ベースのアルゴリズムが急速に変化することです。ディープラーニングなどの分野の急速な発展に伴い、上位フレームワークやアルゴリズムの更新サイクルは短縮し続けており、機能とパフォーマンスの向上はコンパイラの適応にプレッシャーをもたらしています。コンパイラコミュニティは、新しい演算子や新しいコンピューティングモデルのサポートニーズに迅速に対応するために、効率的な適応メカニズムを確立する必要があります。
第二に、ハードウェア アーキテクチャは進化し続けています。現在、コンパイラは一部のGPUアーキテクチャの機能をサポートできます。将来、新しいハードウェアアーキテクチャ機能が登場した場合、コンパイラは異機種ハードウェア機能にも対応できる必要があります。
3 つ目は、プログラミング パラダイムが進化し続けていることです。従来の C/C++ から新興の関数型プログラミングや異種プログラミング モデルに至るまで、Python に関連するエコシステムのチェーンをどのように定義するかが大きな課題です。
最終的には、精度、パフォーマンス、電力消費のバランスです。実際のアプリケーションでは、コンパイラはコードのパフォーマンスだけでなく、ハードウェアの消費電力にも注意を払う必要があります。ハードウェアの消費電力も同様に重要です。これらの要素は、後続の命令選択やアーキテクチャ設計に関係します。
未来、私たちはコミュニティと共同で建設を行いたいと思っています:
オープンソース戦略としては、FlashMLAなどの主要なコンピューティングモジュールを含む、フレームワークと演算子ライブラリのコアコンポーネントを公開する予定です。オープンソースモデルを通じて、コンパイラツールチェーンの反復的な最適化を促進し、エコシステムのスケール効果を形成します。
第二に、業界内のアプリケーション、フレームワーク、演算子ライブラリ、コンパイラ、ハードウェアアーキテクチャ間の協力の機会が拡大することを期待しています。定期的な技術交流(業界フォーラムなど)を通じて、コンパイル最適化の難しさや演算子スケジューリング戦略といった中核的な課題に焦点を当て、分野横断的な協力を促進し、技術革新を探求していきます。
Muxiはエコシステムの共同構築にも注力しています。その構築活動には、コンパイラツールチェーンに関する開発者からのフィードバックや問題報告を受け付ける技術コミュニティフォーラムの構築、オペレーターやフレームワークを対象としたテーマ別コンペティションの開催、ベンチマークの提供、そしてコミュニティと共同で分野固有のテストスイートとベンチマークを構築することなどが含まれます。








