Command Palette
Search for a command to run...
推論能力の飛躍!GLM-4.1V-Thinkingは認知知能の進化を促進します。500万通りのステップバイステップの思考データ例!MathX-5Mは数学的推論の新たな領域を切り開きます

現在、マルチモーダル大規模モデルは「知覚知能」から「認知知能」へと進化しています。これまでの研究では、視覚言語モデルの推論能力の向上が試みられてきましたが、その多くは特定の分野に限定されていました。関連研究は継続中ですが、汎用的なマルチモーダル推論モデルは未だに存在しません。
このような背景から、Zhipu AI と清華大学は共同で、一般的なマルチモーダル理解と推論を促進するために設計された視覚言語モデル (VLM) である GLM-4.1V-Thinking を提案しました。その中核となる革新は、「カリキュラム サンプリングによる強化学習 (RLCS)」戦略にあります。100億パラメータレベルで視覚言語モデルとして最高のパフォーマンスを達成するだけでなく、リストのタスクのうち 18 個では、Qwen-2.5-VL-72B のパラメーターは同じか、8 倍以上です。また、マルチモーダル モデルの動的認知機能の飛躍的な向上も実現し、受動的な「画像認識」から能動的な「思考」へとアップグレードすることで、軽量展開の利点を維持しながら推論の問題点を解決します。
現在、HyperAI公式サイトでは「GLM-4.1V-Thinking:スケーラブルな強化学習による多用途マルチモーダル推論」チュートリアルを公開していますので、ぜひお試しください。
GLM-4.1V-Thinking: スケーラブルな強化学習による多用途マルチモーダル推論
オンラインでの使用:https://go.hyper.ai/B3Vzs
7月7日から7月11日まで、hyper.ai公式サイトが更新されます。
* 高品質の公開データセット: 10
* 質の高いチュートリアルの選択: 7
* 今週のおすすめ論文:5
* コミュニティ記事の解釈:5件
* 人気のある百科事典のエントリ: 5
* 7月に締め切りを迎えるトップカンファレンス:4
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
VisDroneは、ターゲット検出、オブジェクト追跡、画像セグメンテーションといったコンピュータービジョンタスクの開発と評価を支援するために設計された、ドローンによる視覚ターゲット検出・追跡の大規模ベンチマークデータセットです。このデータセットには、中国の様々な都市の都市部および郊外環境でドローンを用いて収集された高解像度の画像と動画が含まれており、6つのカテゴリ(人、車両、建物、動物など)をカバーしています。
直接使用します:https://go.hyper.ai/hQ5lh

MathXは、思考能力を向上させるための指示ベースのモデルチューニングと既存モデルの微調整を目的として設計された数学的推論データセットです。このデータセットは、現在までに公開されている数学的推論データコーパスとしては最大規模かつ最も包括的なもので、厳選された500万点のステップバイステップの思考データ例が含まれており、各データ例には問題文、詳細な推論プロセス、検証済みの正解が含まれています。
直接使用します:https://go.hyper.ai/h0eLq
Fruit Classificationは、果物の認識と分類のための機械学習および深層学習モデルの学習用に設計された果物分類画像データセットです。このデータセットは101種の果物をカバーしており、各カテゴリには学習用に約400枚、検証用に約50枚、テスト用に約50枚の画像が含まれています。
直接使用します:https://go.hyper.ai/a8gfG

Dog Breeds Imageは、様々な犬種の画像を含む犬種画像データセットです。犬種分類モデルの学習と評価を支援するために設計されています。このデータセットには、100種類以上の犬種(テリア、ハウンド、マスティフ、スパニエル、ビションフリーゼなど)の数千枚(17,000枚以上)の画像が含まれており、犬種認識システムの開発に役立てられています。
直接使用します:https://go.hyper.ai/DoFA3

Mushroomは、キノコの種認識データセットです。このデータセットには、100種以上のキノコの画像が含まれています。データには、色、形、匂い、表面の質感など、各キノコの物理的特性が含まれており、有毒か食用かの注釈が付けられています。これらの画像は、キノコの様々な成長段階や生育条件における形態を示しており、きめ細かい分類タスクに最適です。
直接使用します:https://go.hyper.ai/ws0pi

6. Text-to-Image-2M テキスト画像変換トレーニングデータセット
Text-to-Image-2Mは、テキスト画像変換モデルの微調整用に設計された、高品質なテキストと画像のペアからなるデータセットです。このデータセットは約200万のサンプルを含み、2つのコアサブセット(data_512_2M(512×512解像度の画像200万枚とアノテーション)とdata_1024_10K(1024×1024解像度の高解像度画像1万枚とアノテーション))に分かれており、さまざまな精度要件を持つモデルトレーニングに柔軟なオプションを提供します。
直接使用します:https://go.hyper.ai/lTBaT
CIFAKEは、AI生成画像を識別するための合成データセットです。画像処理技術の堅牢性を高め、AI生成コンテンツの認識能力を向上させる上で重要な実用価値を持つ、二値分類画像データセットであり、特にニュース配信やソーシャルメディアモニタリングの分野において活用されています。このデータセットには、実画像6万枚とAI生成画像6万枚が含まれており、コンピュータービジョンモデルによるAI生成画像の識別能力を評価するために設計されています。
直接使用します:https://go.hyper.ai/wxeA3

II-Medical SFTは、医療推論タスクにおける大規模言語モデル(LLM)の教師ありファインチューニングを支援するために設計された、公開医療推論データセットです。このデータセットには約220万のサンプルが含まれており、複数のソースを持つ医療シナリオをカバーし、複雑な医療モデルのファインチューニングのニーズを満たしています。また、鑑別診断、エビデンスに基づく意思決定、患者とのコミュニケーション、ガイドラインに基づく治療計画といった重要な機能をモデルが開発するのを支援することを目的としています。
直接使用します:https://go.hyper.ai/TGMjl
交通標識検出は、自動運転、運転支援システム、スマートシティにおける交通標識認識研究に適した交通標識検出データセットです。このデータセットには、複数の国における様々なシーンを網羅し、明確にラベル付けされた約9,000枚の交通標識画像と約4,969枚のストリートビュー画像が含まれています。画像は複数のカテゴリに分類され、トレーニングセット、検証セット、テストセットに分かれており、正確な境界ボックスアノテーションを提供します。
直接使用します:https://go.hyper.ai/VfwUw

10. UniMateメカニカルメタマテリアルベンチマークデータセット
UniMateデータセットは、15,000個のサンプルを含む機械的メタマテリアルのベンチマークデータセットです。各サンプルには、低密度(ρ=0.1)から中密度(ρ=0.5)までのシナリオを網羅した、3次元トポロジカル構造、密度情報、およびそれに対応する均質化された機械的特性が含まれています。トポロジカル構造は、立方対称性と周期性を満たしています。
直接使用します:https://go.hyper.ai/1ki2l
選択された公開チュートリアル
今週は、質の高い公開チュートリアルを3種類まとめました
*大規模モデル展開チュートリアル: 1
*AI for Scienceチュートリアル:2
*マルチモーダルチュートリアル: 4
大規模モデルの展開チュートリアル
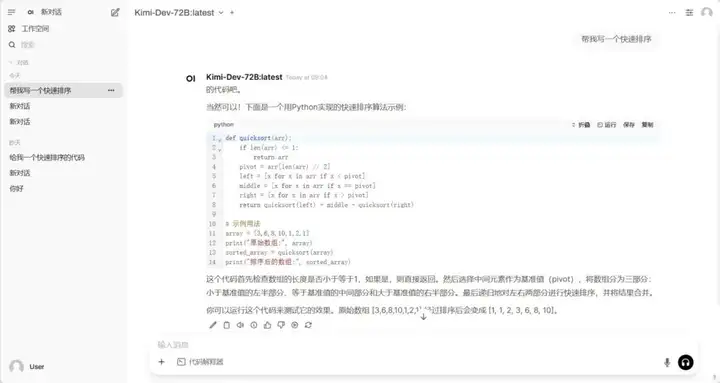
1. Ollama+Open WebUI は Kim-Dev-72B-GGUF をデプロイします
Kimi-Dev-72Bは、ソフトウェアエンジニアリングタスク向けに設計されたオープンソースの大規模言語モデルです。主に、コード修復、テストコード生成(TestWriter)、開発プロセスの自動化、開発ツールの統合などの機能を備えています。
オンラインで実行:https://go.hyper.ai/t6ps1
AI科学チュートリアル
1. Stateを使用して、さまざまな状況での細胞摂動反応を予測する
Stateモデルは、幹細胞、がん細胞、免疫細胞の薬剤、サイトカイン、または遺伝子介入に対する反応を予測できます。実験結果によると、このモデルは介入後のトランスクリプトーム変化の予測において、現在主流となっている手法よりも大幅に優れた性能を発揮することが示されています。
オンラインで実行:https://go.hyper.ai/4AM6P
HealthGPTは、異種知識適応技術を用いて医療用視覚理解・生成タスクのための統一フレームワークを実装した、医療用大規模視覚言語モデル(Med-LVLM)です。革新的な異種低ランク適応(H-LoRA)技術を用いて、視覚理解・生成タスクの知識を独立したプラグインに保存することで、タスク間の競合を回避します。
オンラインで実行:https://go.hyper.ai/KiBWB
マルチモーダルチュートリアル
1. GLM-4.1V-Thinking: スケーラブルな強化学習による多用途マルチモーダル推論
GLM-4.1V-Thinkingは、一般的なマルチモーダル理解と推論能力の向上を目的として設計された視覚言語モデル(VLM)です。強化学習とカリキュラムサンプリング(RLCS)を組み合わせることで、STEM問題解決、ビデオ理解、コンテンツ認識、プログラミング、共参照解決、GUIベースエージェント、長文文書理解など、多様なタスクにおける包括的な能力向上を実現します。
オンラインで実行:https://go.hyper.ai/qPF8a
EX-4Dは、単眼ビデオ入力から極限視点で高品質な4Dビデオを生成できる新しい4Dビデオ生成フレームワークです。このフレームワークは、独自のディープウォータープルーフメッシュ(DW-Mesh)表現をベースとしており、可視領域と遮蔽領域を明示的にモデル化することで、極端なカメラポーズ下でも幾何学的な一貫性を確保します。また、シミュレートされた遮蔽マスク戦略を用いて単眼ビデオに基づく効果的なトレーニングデータを生成するとともに、軽量なLoRAベースのビデオ拡散アダプターを用いて、物理的に一貫性があり時間的にもコヒーレントなビデオを合成します。EX-4Dは、極限視点において既存の手法を大幅に上回る性能を発揮し、4Dビデオ生成のための新たなソリューションを提供します。
オンラインで実行:https://go.hyper.ai/WyAPN

3. MonSter: 単眼の奥行きと立体視の可能性を解き放つ
MonSterは、単眼深度とステレオマッチングを2つのブランチに統合し、反復的に相互に改善するアーキテクチャを採用しています。この反復的な相互改善により、MonSterは粗いオブジェクトレベルの構造からピクセルレベルのジオメトリへと進化し、ステレオマッチングの潜在能力を最大限に引き出します。
オンラインで実行:https://go.hyper.ai/a9Ekd
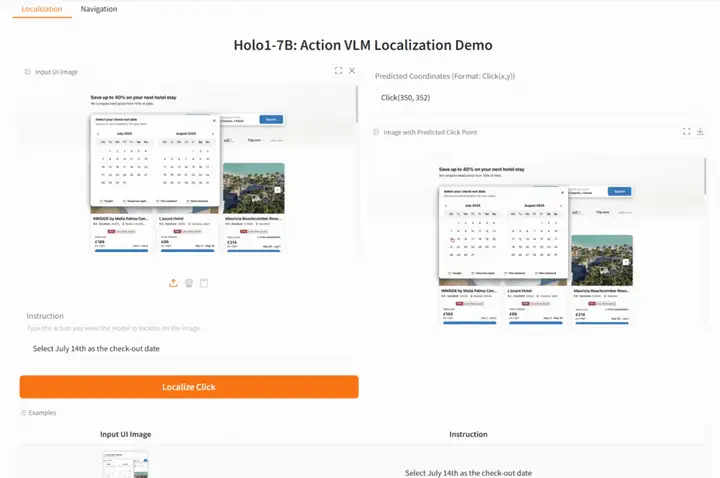
4. Holo1-7B: UI要素の自然言語による正確な配置
Holo1-7Bは、Surfer-Hウェブエージェントシステム用のアクション視覚言語モデル(VLM)です。人間のユーザーのようにウェブインターフェースと対話するように設計されています。より広範なエージェントアーキテクチャの一部として、Holo1はポリシーモデル、ローカリゼーションモデル、検証モデルとして機能し、エージェントがデジタル環境を理解し操作するのを支援します。
オンラインで実行:https://go.hyper.ai/6oQuF

今週のおすすめ紙
本稿では、メモリを管理可能なシステムリソースとして扱うメモリオペレーティングシステムであるMemOSを提案する。MemOSは、プレーンテキスト、アクティベーションベース、パラメータレベルのメモリ表現、スケジューリング、進化を統合し、コスト効率の高い保存と検索を可能にする。MemCubeは基本ユニットとして、メモリコンテンツとそのメタデータ(起源やバージョン情報など)をカプセル化する。MemCubeは時間の経過とともに結合、移行、融合が可能であり、異なる種類のメモリ間の柔軟な変換や、検索とパラメータベース学習の橋渡しを可能にする。MemOSは、LLMに制御性、可塑性、進化性をもたらすメモリ中心のシステムフレームワークを確立し、LLMの継続的学習とパーソナライズされたモデリングの基盤を築く。
論文リンク:https://go.hyper.ai/PgtHH
本論文では、重みの更新を単一の低ランク行列とその転置行列の分解として表現することで、低ランク適応を再定義する新しい手法SingLoRAを提案する。このシンプルな設計は、行列間のスケールの衝突を本質的に排除し、最適化プロセスの安定性を確保し、パラメータ数を約半分に削減する。研究者らは、無限幅ニューラルネットワークの枠組みの中でSingLoRAを解析し、その設計が特徴学習の安定性を本質的に保証することを示し、広範な実験を通じてこれらの利点を検証した。
論文リンク:https://go.hyper.ai/kUu4u
3.マスク言語モデリングを使用してエンコーダを事前トレーニングする必要がありますか?
因果言語モデル(CLM)で事前学習されたデコーダーモデルは、エンコーダータスクに効果的に再利用できることが研究で示されていますが、パフォーマンス向上の理由は明らかではありません。本論文では、大規模かつ慎重に制御された一連の事前学習アブレーション実験を通じてこの問題を検証し、2段階学習戦略(最初にCLMを適用し、次にMLMを適用する)が、固定された計算リソース予算の下で最高のパフォーマンスを達成できることを実験的に実証します。この戦略は、既存の大規模言語モデルエコシステムから事前学習されたCLMモデルを初期化することで、より魅力的になります。
論文リンク:https://go.hyper.ai/eN7kf
潜在的推論の研究を促進するため、本論文は、新興分野である潜在的推論の包括的な概観を提供する。推論のための計算マトリックスとしてのニューラルネットワーク層の基本的な役割を探り、様々な潜在的推論手法を研究し、先進的なパラダイム(マスク拡散モデルによって実現される無制限の深さの潜在的推論など)を議論することにより、潜在的推論の概念的枠組みを明らかにし、LLM認知の最先端における研究の将来の方向性を示すことを目指す。
論文リンク:https://go.hyper.ai/kIuD8
5.エージェントKB: エージェントによる問題解決のためのクロスドメインエクスペリエンスの活用
本論文では、階層的なエクスペリエンスフレームワークであるAgent KBを紹介します。Agent KBは、新しいReason-Retrieve-Refineパイプラインを通じて、複雑なエージェントの問題解決を可能にします。私たちの研究結果は、Agent KBがモジュール式でフレームワークに依存しないインフラストラクチャを提供することを示しており、エージェントが過去の経験から学習し、成功した戦略を新しいタスクに一般化することを可能にします。
論文リンク:https://go.hyper.ai/2wJPd
AIフロンティアに関するその他の論文:https://go.hyper.ai/iSYSZ
コミュニティ記事の解釈
1. 銭学森の「霊界」予言は現実になった!上海交通大学、上海体育大学、清華大学などが世界初のVRスポーツ介入システム「REVERIE」を開発し、10代の若者の脳・心身の健康を改善
上海交通大学の研究チームは、上海体育大学および清華大学と共同で、過体重または肥満の青少年の体重管理を目的とした世界初のVRインテリジェントスポーツ介入システム「Spirit Realm(スピリット・レルム)」を開発しました。深層強化学習を駆動するTransformerアーキテクチャに基づく仮想コーチツインエージェントを使用し、安全で没入感のあるスポーツ指導を提供します。バイオメカニクス性能と運動心拍数反応は、現実世界の同種のスポーツと大きな差はありません。
レポート全体を表示します。https://go.hyper.ai/Q3KKv
2. AIレビューに特化?論文には隠れた肯定的なフィードバックが隠されている。謝彩寧氏はAI時代の科学研究倫理の進化に注目するよう呼びかける
最近、世界14大学の研究論文に、AI査読者に肯定的なレビューを与えるよう誘導する隠された指示が埋め込まれていたことが発覚しました。この報告書は学術界で激しい議論を巻き起こし、AI査読者の利用に伴うリスクと倫理的課題への関心を高めました。謝賽寧氏率いる研究チームの論文も肯定的なコメントを隠蔽していると非難され、謝氏は長文の論文を発表し、AI時代における科学研究倫理の進化に注目するよう呼びかけました。
レポート全体を表示します。https://go.hyper.ai/LZ0TJ
3. シンガポール国立大学は、多次元電子医療記録データに基づくきめ細かな患者コホートモデリングを実施し、入院期間予測の精度が16.3%向上しました。
シンガポール国立大学と浙江大学は共同で革新的なNeuralCohort法を提案しました。この手法は、EHRデータの表現学習に新たな道を開き、EHRデータの潜在能力を最大限引き出しました。この手法は、従来の電子健康記録分析研究では十分に検討されていなかった重要な要素である、ローカルなコホート内情報とグローバルなコホート間情報を同時に活用しました。
レポート全体を表示します。https://go.hyper.ai/1b8lG
4. AMD AIアーキテクト張寧:AMD Tritonコンパイラを多角的に分析し、オープンソースエコシステムの構築を支援する
第7回2025 Meet AIコンパイラ技術サロンが7月5日、北京中関村で盛況のうちに閉幕しました。AMDのAIアーキテクトである張寧氏は、「オープンソースコミュニティへの支援、AMD Tritonコンパイラの分析」と題した講演を行いました。張氏は、同社のオープンソースコミュニティへの技術的貢献に焦点を当て、AMD Tritonコンパイラのコア技術、基盤となるアーキテクチャサポート、そしてエコシステム構築の成果を体系的に解説し、開発者に高性能GPUプログラミングとコンパイラ最適化の深い理解のための包括的な視点を提供しました。本稿は、張寧氏の講演のハイライトを抜粋したものです。
レポート全体を表示します。https://go.hyper.ai/jJLD8
5. オンラインチュートリアル: 1文で画像を正確に編集します。FLUX.1 Kontextは、画像編集/スタイル転送/テキスト編集/文字一貫性編集を実現できます。
ソーシャルメディアとビジュアルコンテンツが主流の時代において、「写真編集」はデザインスキルから人々の日常のニーズへと進化を遂げました。便利で効率的なツールを求めるユーザーの欲求は尽きることがなく、「一言で写真編集」は技術の飛躍的な進歩とともに徐々に現実のものとなりつつあります。最近オープンソース化されたFLUX.1-Kontext-devは、わずか120億個のパラメータで、GPT-image-1などの多くのクローズドソースモデルに匹敵する高い性能を実現しました。
レポート全体を表示します。https://go.hyper.ai/EJIIa
人気のある百科事典の項目を厳選
1.ダルイー
2. 相互ソーティング融合 RRF
3. パレートフロント パレートフロント
4. 大規模マルチタスク言語理解MMLU
5. 対照学習
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。

主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!








