Command Palette
Search for a command to run...
ICML 2025に選ばれたMeta/Cambridge/MITは、周期的および非周期的原子システムの統一的な生成を初めて実現する全原子拡散トランスフォーマーフレームワークを提案しました。
今日の科学研究と産業応用の最前線において、原子システムの三次元構造の生成モデリングは破壊的な可能性を示しており、新しい分子や材料のリバースデザインの展望を根本から変えることが期待されています。精密な構造予測から柔軟な条件付き生成まで、最先端の拡散モデルとフローマッチングモデルは、バイオ分子分析、新素材の研究開発、構造に基づく医薬品設計といった重要なタスクにおいて登場し、研究者が技術的ボトルネックを打破するための中核的なツールとなっています。
しかし、この急成長分野の背後には、重要な問題が常に技術の飛躍を制限してきました。それは、既存のモデルがシステム間の普遍性を欠いていることです。すべての原子系は、その三次元構造と相互作用を決定する際に同一の物理原理に従いますが、小分子、生体分子、結晶、そしてそれらの複合系のモデリングは長らく「分割統治」の状態にありました。ほとんどの拡散モデルは、特定の系に固有の特性に大きく依存しており、カテゴリデータ(原子の種類など)と連続データ(三次元座標など)が絡み合った複雑な積多様体上でのマルチモーダル生成を必要とします。そのため、異なる系間でのモデルの互換性が困難になっています。
具体的なシナリオを例に挙げてみましょう。小分子のde novo生成は、原子の種類(分類)と3次元座標(連続)という2つの独立した拡散プロセスに分割する必要があります。ノイズ除去モデルはこれら2つの共進化法則を学習する必要がありますが、中間状態の歪みによりサンプリング効率が低下することがよくあります。生体分子のモデリングでは、回転多様体の追加導入が必要であり、原子群を剛体として扱います。結晶や材料の拡散プロセスは周期特性と互換性があり、原子の種類、分数座標、格子定数などの多次元パラメータで構成される結合多様体上で実行される必要があります。これらの違いにより、システム間統合モデリングは、この分野において長年未解決の課題となっています。
この文脈では、Meta Basic Artificial Intelligence Research (FAIR)、ケンブリッジ大学、マサチューセッツ工科大学の共同研究チームが、画期的なソリューションである All-atom Diffusion Transformer (ADiT) を提案しました。
Transformerに基づく統合潜在拡散フレームワークとして、ADiTの核となる利点は、周期系と非周期系の間のモデリング障壁を打ち破ることです。全原子統合潜在表現とTransformer潜在拡散という2つの主要なイノベーションにより、単一モデルによる分子と結晶の生成を実現します。この設計は帰納的バイアスをほとんど導入しないため、オートエンコーダと拡散モデルは、従来の等価拡散モデルと比較して、学習と推論においてはるかに効率的です。同じハードウェア条件下では、10,000サンプルの生成時間が2.5時間から20分未満に短縮されます。さらに重要なのは、モデルパラメータを5億に拡張した場合、パフォーマンスが予測どおりに線形に向上することです。この機能は、生成化学の普遍的な基本モデルを構築するための重要な基盤となり、原子システムモデリングの普遍性と大規模応用におけるマイルストーンとなります。
関連研究成果は、「全原子拡散トランスフォーマー:分子と材料の統合生成モデリング」というタイトルで ICML 2025 に選出されました。
研究のハイライト:
* ADiTは周期的材料と非周期的分子システムの生成モデルを統合した最初のモデルです。
* ADiTは全原子の統一潜在表現に依存し、潜在拡散にTransformerを使用するため、生成プロセスが効果的に簡素化され、誘導バイアスがほとんどありません。
* ADiTは優れたスケーラビリティと効率性を備えており、そのトレーニングと推論の速度は等変拡散モデルをはるかに上回っています。
用紙のアドレス:
AIフロンティアに関するその他の論文:
https://go.hyper.ai/owxf6
データセット: 周期的なものから非周期的なものまで、複数の分野の実験データをカバー
この研究では、研究チームはまず実験を行うためにいくつかの代表的なデータセットを選択しました。
* MP20データセット、Materials Project からの 45,231 個の準安定結晶構造が含まれており、単位セルに最大 20 個の原子があり、89 種類の異なる要素をカバーし、周期的な材料システムを適切に表現できます。
* QM9データセット、これは、最大 9 個の重原子 (C、N、O、F) と水素原子を含む 130,000 個の安定した小さな有機分子で構成されており、非周期的分子系の典型的な代表例です。
* GEOM-DRUGSデータセット、最大 180 個の原子を含む 430,000 個の大きな有機分子。
* QMOFデータセット、14,000 個の金属有機構造体が含まれています。
で、MP20 と QM9 は異なるタイプの原子システムに対応します。これは、周期的および非周期的システムにおけるモデルの共同トレーニングの基礎を提供し、研究チームは以前の研究方法に従ってデータを分割し、他のモデルとの比較における公平性を確保しました。GEOM-DRUGSとQMOFは、モデルテストの範囲をさらに拡大し、モデルの一般化能力をより包括的にテストできます。
ADiT: デュアルコアのアイデアに基づく統合原子システム生成モデルの構築
潜在拡散モデルとしての ADiT のコア設計は、周期的および非周期的な原子システムの統一された生成モデリングを実現するための 2 つの重要なアイデアを中心に展開されています。
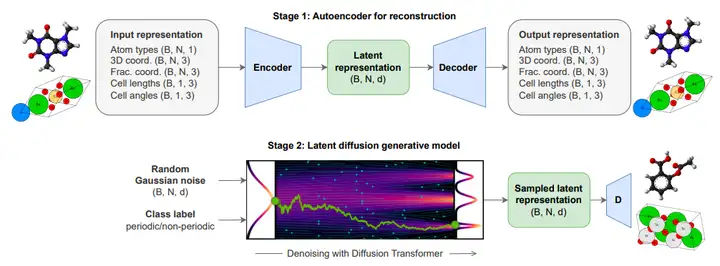
最初の鍵となるアイデアは、全原子の統一潜在表現である。研究チームは、周期的原子系と非周期的原子系の両方を三次元空間における原子の集合として捉え、各原子のカテゴリ属性(原子の種類など)と連続属性(三次元座標など)を含む統一的な表現を開発した。変分オートエンコーダ(VAE)を用いて原子全体の再構成を行うことで、エンコーダーは、分子と結晶を共有潜在空間に埋め込むことができます。これは、さまざまな種類の原子システムを統一的に扱うための基本的な枠組みを提供します。
2 番目の重要なアイデアは、潜在的拡散に Transformer を使用することです。VAEエンコーダによって構築された潜在空間に、研究チームは拡散トランスフォーマー(DiT)を導入して生成モデリングを実行した。推論プロセスでは、分類器を使用しないブートストラッピング技術の助けを借りて、新しい潜在変数をサンプリングできます。これらの潜在変数は、VAE デコーダーを通じて有効な分子または結晶に再構築することができ、潜在空間から実際の原子システムへの変換が完了します。
これら 2 つの核となる考え方に基づいて、ADiT の実験方法は 2 つの段階に分かれており、順序立てて進行します。
第一段階では、研究者らは再構築用のオートエンコーダを構築した。VAE を通じて、分子と材料の完全な原子表現が共同で再構築され、共有潜在空間を学習して構築します。これは、さまざまな原子システムの統一されたモデリングの前提条件であり、後続の生成プロセスの基礎となります。
第2段階では、研究者らは潜在拡散生成モデルを構築しました。DiTは潜在空間から新しいサンプルを生成するために用いられ、分類器の指示なしに有効な分子または結晶にデコードされます。この潜在拡散設計の大きな利点は、分類と連続属性の処理の複雑さがオートエンコーダに転送されるため、潜在空間における生成プロセスがより単純化され、よりスケーラブルになり、異なる原子系を処理する際のモデルの効率と適応性が効果的に向上することです。
ADiT 結晶および分子生成におけるトップクラスのパフォーマンス
ADiT のパフォーマンス上の利点を十分に強調するために、研究チームは複数の種類のベースライン モデルを選択し、対象を比較しました。結晶形成の分野では、比較オブジェクトには、CDVAE、DiffCSP、FlowMM などの多峰性積多様体に基づく等価拡散およびフロー マッチング モデル、および非等価拡散モデル UniMat と 2 段階フレームワーク FlowLLM が含まれます。分子生成の分野では、ADiTは、等変拡散モデル、GeoLDM、Symphonyといった他のモデルと比較されます。これらの分野における先進的なベースラインモデルとの体系的な比較を通じて、ADiTの性能上の優位性が明確に示されます。
具体的な実験結果から、ADiT は、結晶生成タスクと分子生成タスクの両方で SOTA レベルを達成します。結晶生成に関しては、ADiTで生成された結晶は、有効性、安定性、独自性、新規性といった主要な指標において優れた成績を収めました。分子生成タスクでは、ADiTは10,000個の分子サンプルにおける有効性と独自性においてトップクラスにランクインしました。
ADiTの共同トレーニングメカニズムは、パフォーマンスの大幅な向上ももたらします。実験データによると、QM9 と MP20 の両方のデータセットでトレーニングされた ADiT は、材料生成タスクと分子生成タスクの両方で、1 つのデータセットのみでトレーニングされたバージョンよりも優れたパフォーマンスを発揮します。
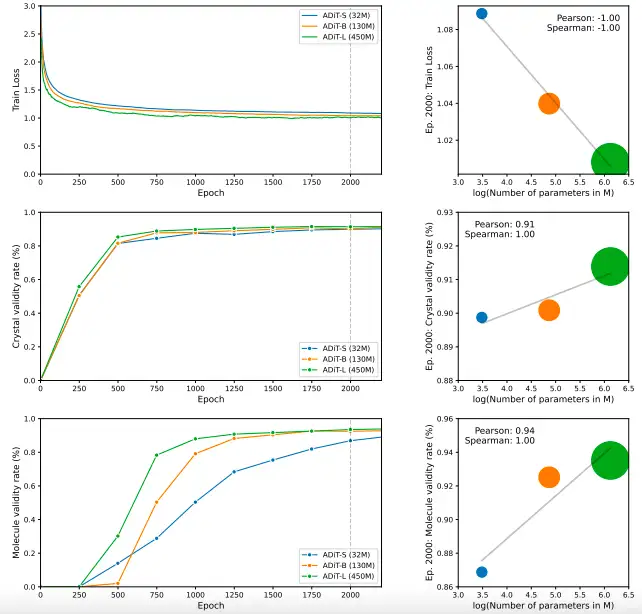
モデル規模の拡大は、ADiTの性能向上に大きく寄与すると予測されます。下図に示すように、DiTデノイザーのパラメータ数が3,200万(ADiT-S、青)から1億3,000万(ADiT-B、オレンジ)、そして4億5,000万(ADiT-L、緑)へと増加すると、約13万サンプルの中規模データセットにおいても、拡散学習損失が減少し続け、有効性比が着実に向上し、顕著なスケール効果を示しています。モデル規模と性能の間にはこのような強い相関関係があり、モデルパラメータとデータ量を拡大することで、ADiTのさらなる飛躍的進歩が期待できます。
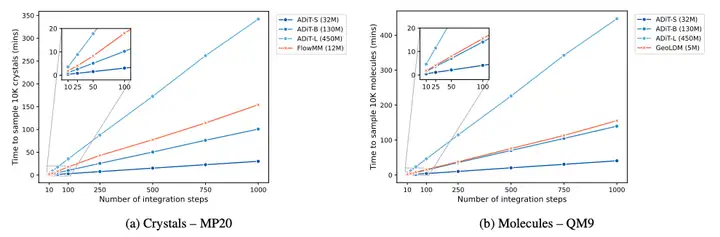
効率の面では、ADiT は等価拡散モデルに比べて速度面で大きな利点を示します。下図に示すように、NVIDIA V100 GPUで10,000サンプルを生成する場合、標準的なTransformerベースのADiTは、計算負荷の高い等変ネットワークを使用するFlowMMやGeoLDMよりも、積分ステップ数に関してはるかに優れたスケーラビリティを示します。ADiT-Bは等変ベースラインの100倍のパラメータサイズを持つにもかかわらず、推論速度は依然として高速であり、スケーラビリティにおけるTransformerアーキテクチャの優位性を浮き彫りにしています。
さらに、ADiTの大規模システムにおけるスケーラビリティが実証されています。最大180個の原子を含む43万個の分子を含むGEOM-DRUGS分子データセットでは、ADiT は、有効性と PoseBusters メトリックの点で、最先端の等価拡散およびフロー マッチング モデルと同等のパフォーマンスを発揮します。注目すべきは、ADiT は標準の Transformer アーキテクチャに基づいており、分子誘導バイアスをほとんど導入せず、原子結合の明示的な予測を必要としないにもかかわらず、等価モデルに匹敵するパフォーマンスを達成でき、その設計の汎用性と幅広い適用性をさらに実証していることです。
産業界と研究機関が協力して、原子システムの3次元構造の生成における画期的なイノベーションを推進します。
実際、原子システムの3次元構造の生成モデリングという最先端の研究分野では、学界と産業界がたゆまぬ努力を重ね、多くの顕著な成果を上げています。
学問の世界では、カリフォルニア大学バークレー校、マイクロソフトリサーチ、ジェネンテックの研究チームが、PLAIDと呼ばれるマルチモーダルタンパク質生成法を発表しました。この方法は、事前トレーニング済みの重みの構造情報を巧みに活用して DiT によるノイズ除去タスクを実行し、さまざまな長さのタンパク質の構造品質と多様性の分析において他のベンチマーク方法よりも優れたパフォーマンスを発揮します。
ビジネス界もこの分野を積極的に模索し、イノベーションを通じて発展を推進しています。中国の生成AIタンパク質設計イノベーション企業BioGeoは、世界初の万能タンパク質基本モデル「GeoFlow V2」をリリースした。タンパク質構造予測と設計の課題を一挙に解決するために、統一された原子拡散モデルアーキテクチャが構築されました。抗体および抗原抗体複合体の構造予測において、GeoFlow V2は並外れた精度と速度で類似製品をリードしています。ByteDanceがリリースしたSeedance 1.0は、変分オートエンコーダと拡散トランスフォーマーを組み合わせた技術ソリューションを用いて、高速かつ効率的なAIビデオ生成を実現するという異なるアプローチを採用しています。その高速性は、リアルタイム制作やインタラクティブアプリケーションに新たな可能性をもたらし、商用アプリケーション分野における幅広い可能性を示唆しています。
学術界におけるこれらの科学的ブレークスルーと産業界における革新的な実践は、原子系三次元構造生成モデリング分野の発展を共同で促進しています。技術の継続的な進歩に伴い、この分野は新材料研究開発や医薬品設計など、様々な分野でより大きな役割を果たし、世界的な科学的課題や産業課題の解決を力強く支えていくでしょう。
参考記事:
1.https://mp.weixin.qq.com/s/oF3-y7z8u1XpEtjd4q1u4w
2.https://mp.weixin.qq.com/s/tK0-








