Command Palette
Search for a command to run...
AMD AIアーキテクト張寧氏:AMD Tritonコンパイラを多角的に分析し、オープンソースエコシステムの構築を支援する

7月5日、HyperAI主催の第7回Meet AIコンパイラ技術サロンが予定通り開催されました。真夏の猛暑にもかかわらず、会場は満員で、多くの参加者が立ち見で共有セッションに耳を傾けました。AMD、Muxi Integrated Circuits、ByteDance、北京大学などから多くの講師が交代で登壇し、ボトムレベルのコンパイルから実際の実装に至るまで、業界に関する深い洞察とトレンド分析を提供し、実用的な情報満載でした。
WeChatパブリックアカウント「HyperAI Super Neuro」をフォローし、キーワード「0705 AI Compiler」に返信すると、認定講師の講演PPTを入手できます。




高性能GPUカーネル開発を簡素化するために設計されたプログラミング言語であるTritonは、複雑な並列コンピューティングプログラミングを簡素化することで、LLM推論およびトレーニングフレームワークの重要なツールとなっています。Tritonの最大のメリットは、開発効率とハードウェア性能のバランスにあります。基盤となるハードウェアの詳細を公開することなく、コンパイラの最適化を通じてGPUコンピューティングパワーを解放できます。この機能により、Tritonはオープンソースコミュニティで急速に人気を博しました。
GPU分野のリーディングカンパニーとして、AMDはTriton言語のサポートを率先して進め、オープンソースコミュニティに関連コードを提供することで、Tritonエコシステムのベンダー間互換性を促進してきました。この動きは、AMDの高性能コンピューティング分野における技術的影響力を強化するだけでなく、オープンソースコラボレーションモデルを通じて、特に大規模モデルのトレーニングや推論シナリオにおいて、世界中の開発者により柔軟なGPUプログラミングオプションを提供し、コンピューティングパワーの最適化に向けた新たな道を切り開きます。
AMDのAIアーキテクトである張寧氏は、「オープンソースコミュニティのサポート、AMD Tritonコンパイラの分析」と題した講演で、AMD Tritonコンパイラのコアテクノロジー、基礎となるアーキテクチャサポート、エコシステム構築の成果を体系的に解説し、同社のオープンソースコミュニティへの技術的貢献に焦点を当てました。開発者に、高性能 GPU プログラミングとコンパイラの最適化を深く理解するための包括的な視点を提供します。
HyperAIは、張寧教授の講演を、本来の意図を損なうことなく編集・要約しました。以下は講演の書き起こしです。
Triton: 効率的なプログラミング、リアルタイムコンパイル、柔軟な反復処理
Triton は OpenAI によって提案され、高性能 GPU カーネルの開発を簡素化するために設計されたオープンソースのプログラミング言語およびコンパイラです。主流のLLM推論トレーニングフレームワークで広く利用されています。主な機能は以下のとおりです。
* 効率的なプログラミングによりカーネル開発が簡素化され、開発者は複雑な GPU の基礎となるアーキテクチャを深く理解することなく GPU コードを効率的に記述できるようになります。
* リアルタイム コンパイルは、ジャストインタイム コンパイルをサポートし、さまざまなハードウェアおよびタスク要件に適応するために GPU コードを動的に生成および最適化できます。
* ブロック プログラムとスカラー スレッドに基づく柔軟な反復空間構造により、反復空間の柔軟性が向上し、スパース操作の処理が容易になり、データの局所性が最適化されます。
従来のソリューションと比較して、Triton には次のような大きな利点があります。
初め、Tritonはオープンソースプロジェクトとして、Pythonベースのプログラミング環境を提供します。ユーザーは、基盤となるGPUアーキテクチャの詳細を意識することなく、Python Tritonコードを開発することでGPUカーネルを実装できます。これにより、AMD HIPなどの他のGPUプログラミング手法と比較して、開発の難易度が大幅に低減し、製品開発効率が大幅に向上します。Tritonのコンパイラは、GPUアーキテクチャの特性に基づいた様々な最適化戦略を用いて、Pythonコードを最適化されたGPUアセンブリコードに変換し、上位レベルのテンソル演算を基盤となるGPU命令に自動的にコンパイルすることで、GPU上でのコードの効率的な動作を保証します。
第二に、Tritonは優れたハードウェア互換性を備えています。理論上、同じコードセットをNVIDIAやAMDのGPU、そしてTritonをサポートする国内GPUなど、様々なハードウェアで実行できます。パフォーマンスと柔軟性の面では、PyTorchなどのプラットフォームよりも優れたパフォーマンスと最適化の柔軟性を提供し、CUDAと比較してGPU演算の詳細を隠蔽できるため、開発者はアルゴリズムの実装に集中できます。
PyTorch APIと比較して、コンピューティング操作の具体的な実装に重点を置いており、開発者はスレッドブロックの分割方法を柔軟に定義し、ブロック/タイルレベルのデータの読み書き操作や、ハードウェア関連のコンピューティングプリミティブの実行が可能です。特に、演算子の融合やパラメータチューニングといったパフォーマンス最適化戦略の開発に適しています。
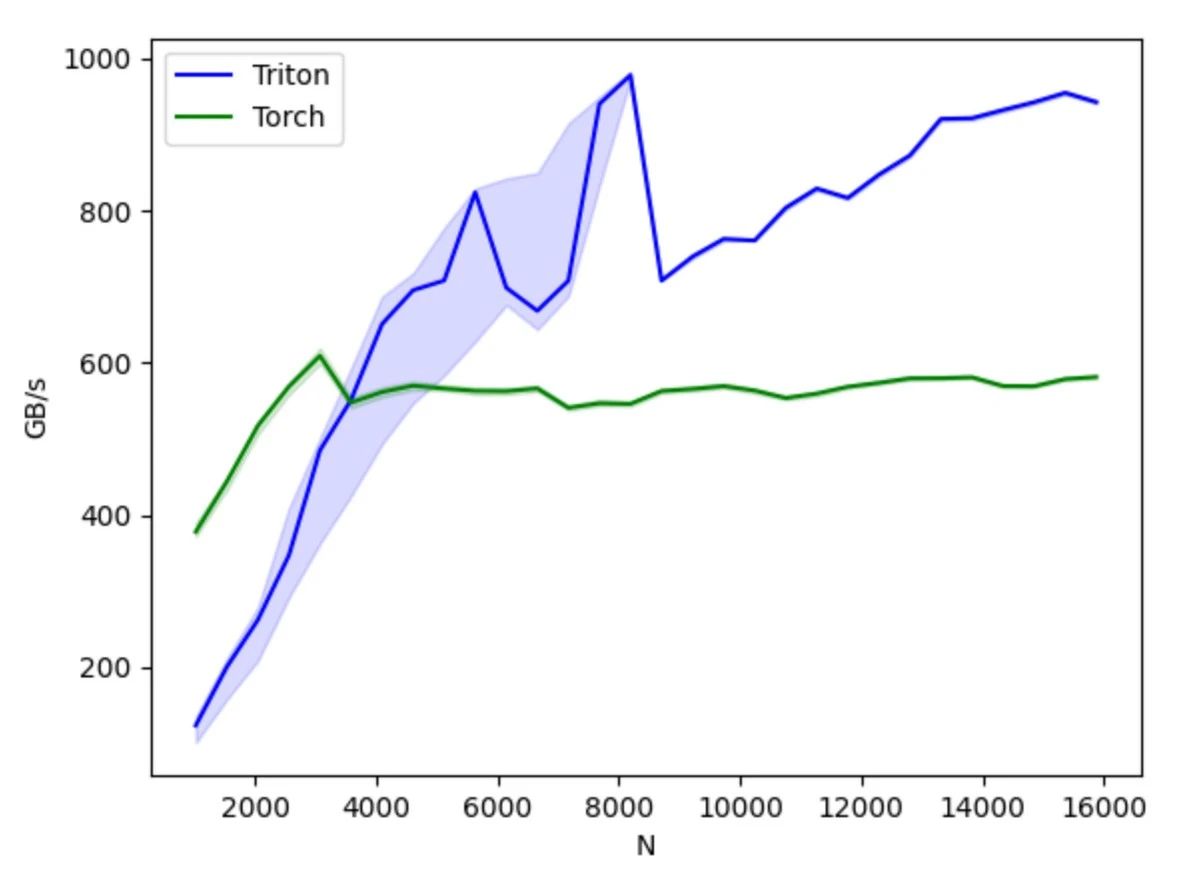
CUDAと比較して、Tritonはスレッドレベルの演算制御を隠蔽し、共有ストレージ、スレッド並列性、メモリアクセスの統合、テンソルレイアウトといった細部をコンパイラが自動的に処理することで、並列プログラミングモデルの難易度を軽減するとともに、GPUコード開発の効率性を向上させ、開発効率とプログラムパフォーマンスの効果的なバランスを実現します。開発者は、基盤となるハードウェアの詳細やプログラミングの最適化手法について過度に心配することなく、アルゴリズムの設計と実装に集中できます。シンプルな並列プログラミングの原則さえ理解していれば、より優れたパフォーマンスを持つGPUコードを迅速に開発できます。
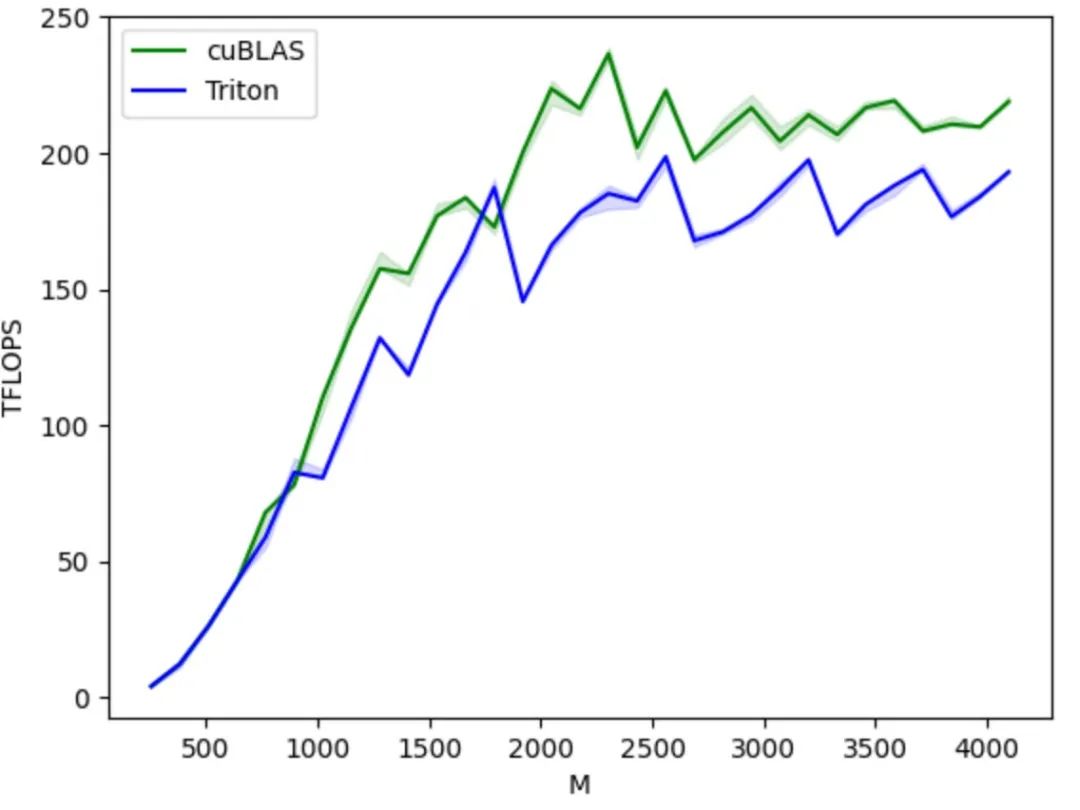
エコシステムの観点から見ると、TritonはPython言語環境をベースとし、PyTorchで定義されたテンソルデータ型を採用しているため、その機能はPyTorchエコシステムにシームレスに統合できます。また、クローズドなCUDAと比較して、Tritonのオープンソースコードとオープンエコシステムは、AIチップメーカーが自社チップへの移植を容易にし、オープンソースコミュニティを活用してツールチェーンを改善できるようにすることで、Tritonエコシステムの健全な発展を促進します。
AMD Triton コンパイラプロセス
Triton コンパイラは、次の図に示すように、フロントエンド モジュール、オプティマイザー モジュール、およびバックエンド マシン コード生成モジュールの 3 つの主要モジュールで構成されています。
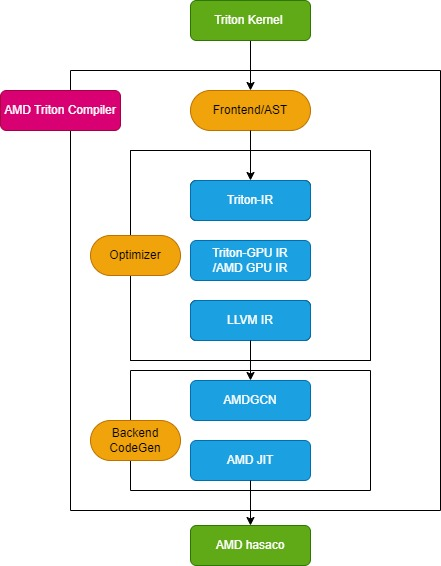
フロントエンドモジュール
フロントエンド モジュールは、Python Triton カーネル関数の抽象構文ツリー (AST) をトラバースして Triton 中間表現 (Triton-IR) を作成し、そのカーネル関数を Triton-IR に変換します。例えば、@triton.jit デコレータでマークされたカーネル関数 add_kernel は、このモジュール内で対応する IR に変換されます。JIT デコレータのエントリ関数は、まず TRITON_INTERPRET 環境変数の値をチェックします。この変数が True の場合、InterpretedFunction が呼び出され、Triton カーネルがインタープリタモードで実行されます。False の場合、JITFunction が実行され、Triton カーネルが実際のデバイス上でコンパイルおよび実行されます。
カーネルコンパイルのエントリポイントはTritonコンパイル関数です。この関数は、ターゲットデバイスとコンパイルオプション情報を指定して呼び出されます。このプロセスは、カーネルキャッシュマネージャを作成し、コンパイルパイプラインを開始し、カーネルメタデータを埋めます。さらに、AMDプラットフォーム用のTritonAMDGPUDialectなどのバックエンド固有の方言と、LLVM-IRコンパイルを処理するバックエンド固有のLLVMモジュールをロードします。すべての準備が整ったら、ast_to_ttir関数が呼び出され、カーネル用のTriton-IRファイルが生成されます。
オプティマイザーモジュール
オプティマイザー モジュールは、Triton-IR 最適化、Triton-GPU IR 最適化、LLVM-IR 最適化の 3 つのコア部分に分かれています。
* Triton-IR最適化
AMDプラットフォームでは、Triton-IR最適化パイプラインはmake_ttir関数によって定義されます。この段階では、ハードウェアに依存しない最適化が行われ、インライン展開、共通部分式の削除、正規化、デッドコードの削除、ループ不変コードの移動、ループアンローリングなどが含まれます。
* Triton-GPU IR最適化
AMDプラットフォームでは、GPUパフォーマンスを向上させるために、Triton-IR最適化プロセスがmake_ttgir関数によって定義されています。AMD GPUの特性と最適化の経験に基づき、次の図に示すように、独自の最適化プロセスも開発しました。
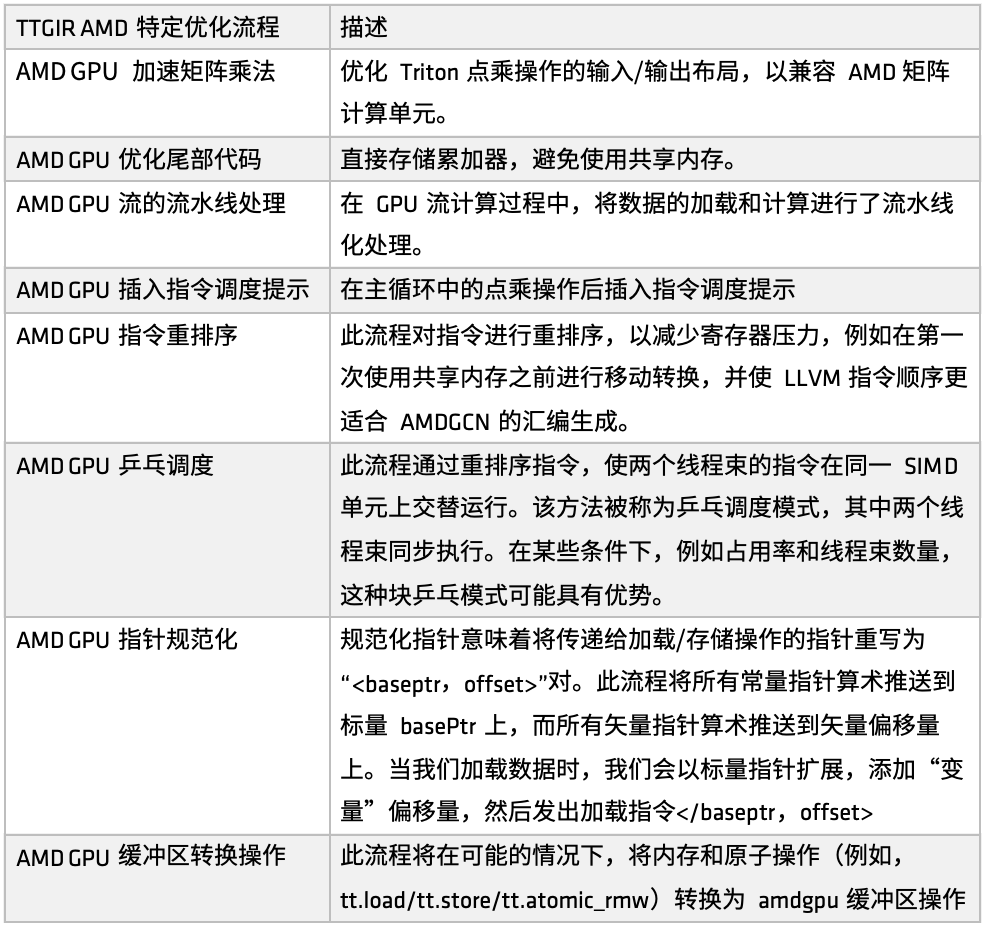
まず、AMD GPUの高速行列乗算、この最適化は、Tritonにおける点乗算演算の入出力レイアウトに焦点を当てており、AMDの行列演算ユニット(Matrixなど)との互換性を高めています。この最適化には、CDNAアーキテクチャのマッチング処理が大量に含まれており、これは実装全体の比較的大きな部分を占めています。AMDプラットフォーム上でTritonによって生成されたコードを徹底的に最適化したい場合、実装のこの部分に重点を置く価値があります。
第二に、尾の処理段階では、最適化戦略は、アキュムレータを直接保存することで、共有メモリの使用を回避し、共有メモリのアクセス圧力を軽減し、全体的な効率を向上させることです。
次に、GPU ストリーム コンピューティング プロセスにおいて、ロードとコンピューティングのパイプライン処理が導入されました。つまり、前のタスクの実行中に、対応するメモリを呼び出してデータをロードすることで、ロードと計算を並列実行するモードを形成します。このメカニズムは、多くのユーザーシナリオで良好な結果を達成しています。パイプライン最適化に基づき、命令スケジューリングヒントも導入され、計算ユニットまたはリモート操作の完了後に命令フローをガイドすることで、命令レベルでの応答効率が向上します。
その後、AMD はさまざまな目的のために複数の命令並べ替えセットを実装しました。レジスタ負荷の軽減、冗長なリソース割り当てと解放の回避、ロードと計算プロセス間の接続の最適化などが含まれます。並べ替えの一部はパイプライン メカニズムと密接に統合されており、他の部分は LLVM IR の命令順序を調整して AMDGCN アセンブリの生成ルールをより適切に満たすことに重点を置いています。
命令の並べ替えやスケジュールのヒントに加えて、また、別のスケジュール最適化戦略であるピンポン スケジュールも導入しました。循環スケジューリング メカニズムにより、2 つのスレッド ワープが同じ SIMD ユニット上で交互に実行され、アイドル状態と待機状態が回避され、コンピューティング リソースの使用率が向上します。
さらに、AMD はポインターの正規化とバッファー操作の変換においても最適化を行いました。この最適化の主な目的は、命令を特定のビジネス アプリケーションに効果的にマッピングし、より効率的なアトミック命令実行を実現することです。
これらの最適化プロセスは、まずTriton-IRをTriton-GPU IRに変換します。このプロセスでは、レイアウト情報がIRに埋め込まれます。次の図を例に挙げると、テンソルは#ブロックレイアウトの形式で表現されています。

別の Triton 行列乗算の例を試してみます。上記の最適化フローでは、AMD MFMA アクセラレータ用に設計された amd_mfma レイアウトを使用しながら、行列乗算の一般的な最適化ソリューションである共有メモリ アクセスを導入してパフォーマンスを向上させます。
やっと、実験検証では、より複雑な行列乗算行列レイヤーを例に挙げました。GPR(汎用レジスタ)マッピングを確認する過程で、MFMA、転置、共有メモリ呼び出しなど、多数のハードウェア関連命令が挿入されました。バンク競合の削減、スウィズル演算の適用、命令並べ替えとパイプライン処理戦略の組み合わせにより、これらの最適化はすべてTriton IR変換プロセス中に自動的に追加され、より強力なハードウェア適応性とパフォーマンス向上を実現します。

* LLVM-IR最適化
AMDプラットフォームでは、最適化プロセスはmake_llir関数によって定義されます。この関数は、IRレベルの最適化とAMD GPU LLVMコンパイラの設定という2つの部分から構成されます。IRレベルの最適化では、AMD GPU固有の最適化プロセスに、LDS/共有メモリ関連の最適化とLLVM-IRレベルの一般的な最適化が含まれます(下図参照)。
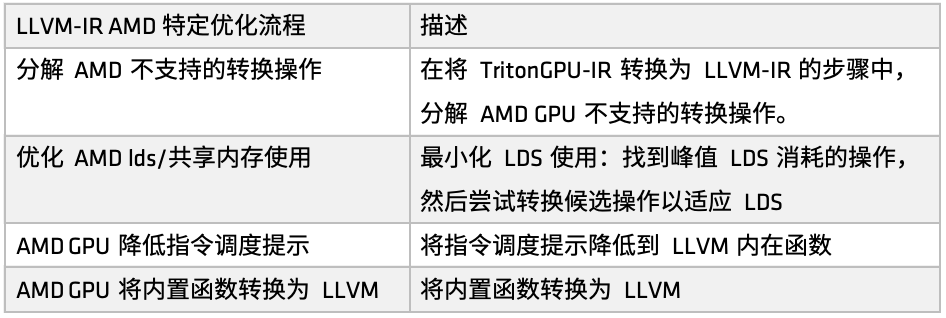
初め、AMDがサポートしていない一部の変換操作を分解します。例えば、Triton GPU IRをLLVM-IRに変換する際、現在サポートされていない変換パスに遭遇した場合、これらの操作をより基本的なサブ操作に分解し、変換プロセス全体がスムーズに完了できるようにします。
AMD GPU LLVM コンパイラを構成するときは、まず LLVM ターゲット ライブラリとコンテキストを初期化し、LLVM モジュールのコンパイル パラメータを設定し、次に AMD GPU HIP カーネルの呼び出し規約を設定し、amdgpu-flat-work-group-size、amdgpu-waves-per-eu、denormal-fp-math-f32 などのいくつかの LLVM-IR プロパティを構成し、最後に LLVM 最適化を実行して最適化レベルを OPTIMIZE_O3 に設定します。
プロパティ構成のリファレンスドキュメント:
https://llvm.org/docs/AMDGPUUsage.html
バックエンドマシンコード生成モジュール
バックエンドのマシンコード生成モジュールは、主に中間コードをハードウェア上で実行可能なバイナリファイルに変換する役割を担います。この段階は、AMDGCNアセンブリコードの生成と最終的なAMD hsaco ELFファイルのビルドという2つのステップに分かれています。
まず、make_amdgcnステージでtranslateLLVMIRToASM関数を呼び出してAMDアセンブリコードを生成します。このプロセスにより、中間コードからターゲットアーキテクチャの命令セットへのマッピングが完了し、後続のバイナリ生成の基盤が構築されます。その後、コンパイラはmake_hsacoステージでassemble_amdgcn関数とROCmリンクモジュールを使用してAMD hsaco ELF(実行可能およびリンク可能形式)バイナリファイルを生成します。このファイルはAMD GPUで直接実行できる最終的なバイナリであり、デバイス側の完全な命令とメタデータが含まれています。
これら 2 つのステップを通じて、コンパイラは高レベルの中間表現を低レベルの GPU 実行可能コードに効率的に変換し、プログラムが AMD Instinct シリーズなどの GPU 上でスムーズに実行され、基盤となるハードウェアのパフォーマンスを最大限に活用できるようにします。
AMD GPU開発者クラウド
AMD は、高性能 GPU クラウド プラットフォームである AMD Developer Cloud を、世界中の開発者とオープン ソース コミュニティに正式に公開しました。すべての開発者が世界クラスのコンピューティング リソースに自由にアクセスし、AMD Instinct MI シリーズ GPU リソースに便利にアクセスし、AI および高性能コンピューティング タスクをすぐに開始できるようにすることを目的としています。
AMD Developer Cloud では、開発者はニーズに応じてコンピューティング リソースを柔軟に選択できます。
* 小型: MIシリーズGPU 1個 (192 GB VRAM)
* 大規模: 8 つの MI シリーズ GPU (1536 GB VRAM)
このプラットフォームは設定のハードルを最小限に抑え、ユーザーは複雑なインストールなしでクラウドベースのJupyter Notebookをすぐに使い始めることができます。GitHubアカウントまたはメールアドレスさえあれば、簡単に設定を完了できます。さらに、AMD Developer Cloudは、主要なAIソフトウェアフレームワークが組み込まれた、事前構成済みのDockerコンテナを提供します。これにより、環境構築にかかる時間を最小限に抑えながら、高い柔軟性を維持し、開発者は特定のプロジェクトのニーズに合わせてコードをカスタマイズできます。
開発者の皆様は、AMD Developer Cloudを実際に体験し、コードを実行してアイデアを検証していただけます。このプラットフォームは、安定性、パワフルさ、柔軟性に優れたコンピューティングパワーを提供し、イノベーションと実装を加速します。
AMD 開発者クラウドリンク:
https://www.amd.com/en/developer/resources/cloud-access/amd-developer-cloud.html
PPT を入手:WeChatパブリックアカウント「HyperAI Super Neuro」をフォローし、キーワード「0705 AI Compiler」に返信すると、認定講師の講演PPTを入手できます。








