Command Palette
Search for a command to run...
OmniGen2マルチモーダル推論×自己修正デュアルエンジン、画像生成の新たなパラダイムをリード。95万種類の分類ラベル!TreeOfLife-200Mが種認識の新たな次元を切り開く

近年、生成AI技術は画像分野において大きな進歩を遂げています。Stable DiffusionシリーズやDALL-E3といったモデルは、拡散モデルを用いて高品質なテキスト画像生成を実現しています。しかし、これらのモデルは、一般的な画像生成モデルに必要な包括的な知覚理解と生成能力を欠いています。OmniGenは、拡散モデルアーキテクチャに基づき、様々な生成タスクに統合的なソリューションを提供するために誕生しました。マルチタスク処理能力を備え、追加のプラグインなしで高品質な画像を生成できます。しかし、このモデルには、マルチモーダル分離とデータの多様性という点で依然として限界があることは否定できません。
これらの困難を克服し、システムの柔軟性と表現力をさらに向上させるために、OmniGen2 は大きな進歩を遂げました。テキストおよび画像モダリティ用の 2 つの独立したデコード パスがあります。OmniGen2は非共有パラメータと独立した画像タグ付け機能を採用しています。この設計により、変分オートエンコーダの入力を再調整することなく、既存のマルチモーダル理解モデルを基盤として構築できるため、元のテキスト生成機能を維持できます。
現在、HyperAI公式サイトでは「OmniGen2:高度なマルチモーダル生成の探求」チュートリアルが公開されていますので、ぜひお試しください。
OmniGen2: 高度なマルチモーダル生成の探求
オンラインでの使用:https://go.hyper.ai/fKbUP
6月30日から7月4日まで、hyper.ai公式サイトが更新されます。
* 高品質の公開データセット: 10
* 質の高いチュートリアルの選択: 7
* 今週のおすすめ論文:5
* コミュニティ記事の解釈:5件
* 人気のある百科事典のエントリ: 5
* 7月に締め切りを迎えるトップカンファレンス:4
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
1. ShareGPT-4o-Image 画像生成データセット
ShareGPT-4o-Imageは、GPT-4oレベルの画像生成機能をオープンソースのマルチモーダルモデルに移行することを目的とした、大規模で高品質な画像生成データセットです。このデータセットに含まれるすべての画像はGPT-4oの画像生成機能によって生成されており、データにはGPT-4oからの画像生成サンプルが合計92,256個含まれています。
直接使用します:https://go.hyper.ai/5G48Y

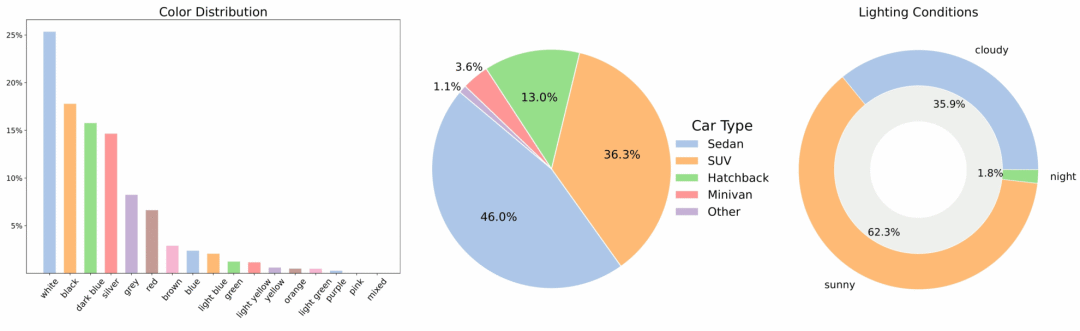
2. MAD-Cars マルチビューカービデオデータセット
MAD-Carsは、公開されている大規模なマルチビュー車両動画データセットであり、既存の公開マルチビュー車両データセットの範囲を大幅に拡大します。このデータセットには約7万台の車両動画インスタンスが含まれており、インスタンスあたり平均85フレームです。ほとんどの車両インスタンスの解像度は1920×1080で、約150ブランドの車両をカバーし、複数のモデル、カラー、3種類の照明条件が含まれています。
直接使用します:https://go.hyper.ai/xuB9I
3. 植物と作物の作物画像データセット
Plants and Cropsデータセットは、農業AI分野向けの包括的な作物画像データセットです。10万枚の標準化された画像が含まれており、世界中で広く栽培されている139種類の作物を網羅しています。このデータセットは、苗から開花、結実までの作物の複数の成長段階を網羅し、画像コンテンツは葉、茎、果実などの複数の構造部分を網羅し、豊富な表現情報を備えています。すべての画像は224×224ピクセルに統一されており、サイズの違いがモデルの学習に与える影響を軽減しています。
直接使用します:https://go.hyper.ai/PLVJp

4. マルチモーダル教科書-650万 マルチモーダル教科書データセット
Multimodal-Textbook-6.5Mは、マルチモーダル事前学習を強化し、インターレースされた画像とテキスト入力を処理するモデルの能力を拡張することを目的としています。このデータセットには、教育ビデオから抽出された650万枚の画像と8億枚のテキストデータが含まれています。すべての画像とテキストは、数学、物理、化学など6つの基礎科目を網羅したオンライン教育ビデオから抽出されています。
直接使用します:https://go.hyper.ai/q8Iin
5. IndicVault インド人質問回答ペアデータセット
Indic Vaultは、チャットボットや音声アシスタントのチューニングに適した、インドの日常言語による質疑応答データセットです。このデータセットには、2025年のインド全土で使用されている現代の日常言語で書かれた質疑応答のペアが含まれており、日常会話で実際に使用されている口語表現を20の主要カテゴリにわたって捉えています。
直接使用します:https://go.hyper.ai/JhEUR
6. DREAM-1K ビデオ記述ベンチマークデータセット
このデータセットには、5つの異なるカテゴリに分類された、複雑度が異なる1,000本のアノテーション付きビデオクリップが含まれており、各クリップには、単一のフレームからは正確に識別できない動的イベントが少なくとも1つ含まれています。各ビデオには、すべてのイベント、アクション、モーションを網羅したきめ細かい手動アノテーションが付与されています。
直接使用します:https://go.hyper.ai/AgOm0
7. 脳MRI脳腫瘍検出分析データセット
脳MRIには、様々な患者の高品質なマルチシーケンス脳MRIスキャン画像が含まれています。これらのスキャンには、T1強調画像、T2強調画像、FLAIR画像、拡散強調画像の画像シーケンスが含まれています。このデータセットは複数の種類の脳腫瘍を網羅し、健常対照群と比較されているため、高度な機械学習モデルや臨床研究アプリケーションの開発と検証に適しています。
直接使用します:https://go.hyper.ai/oZWNu
8. AceReason-1.1-SFT 数学コード推論データセット
このデータセットは、数学およびコード推論モデルAceReason-Nemotron-1.1-7BのSFT学習データとして使用されます。データセット内のすべての回答はDeepSeek-R1によって生成されます。AceReason-1.1-SFTデータセットには、2,668,741件の数学サンプルと1,301,591件のコードサンプルが含まれており、複数のデータソースからのデータが含まれています。データセットはクリーンアップされており、数学およびコードベンチマークのテストサンプルと9グラムの重複があるサンプルはフィルタリングされています。
直接使用します:https://go.hyper.ai/WGl1k
9. TreeOfLife-200M 生物視覚データセット
TreeOfLife-200Mは、生物系コンピュータービジョンモデル向けの機械学習対応データセットとして、最大規模かつ最も多様性に富んだ公開データセットです。このデータセットには約2億1,400万枚の画像が含まれており、95万2,000種のカテゴリーをカバーしています。また、4つの主要な生物多様性データプロバイダーからの画像とメタデータが統合されています。
直接使用します:https://go.hyper.ai/UKC0H
10. VL-Health 医療推論生成データセット
VL-Healthは、医療におけるマルチモーダル理解と生成のための初の包括的なデータセットです。このデータセットには、765,000件の理解タスクサンプルと783,000件の生成タスクサンプルが統合されており、11種類の医療モダリティと複数の疾患シナリオをカバーしています。
直接使用します:https://go.hyper.ai/GvKlu
選択された公開チュートリアル
今週は、3種類の高品質な公開チュートリアルをまとめました。
*画像生成と編集のチュートリアル: 3
*3D生成チュートリアル:2
* オーディオ生成チュートリアル: 2
画像生成と編集のチュートリアル
1. OmniGen2: 高度なマルチモーダル生成の探求
OmniGen2は、テキストから画像への生成、画像編集、コンテキスト生成など、複数の生成タスクに対応する統合ソリューションを提供することを目指しています。非共有パラメータと個別の画像トークナイザーの設計により、OmniGen2はVAE入力を再調整することなく、既存のマルチモーダル理解モデルを基盤として構築することができ、従来のテキスト生成機能を維持しています。
オンラインで実行:https://go.hyper.ai/fKbUP

2. FLUX.1-Kontext-dev: テキスト駆動型のワンクリック画像編集
FLUX.1 Kontext の画像編集は、広義の画像編集であり、ローカル画像編集 (画像内の特定の要素を他の部分に影響を与えずにターゲットを絞って変更する) をサポートするだけでなく、文字の一貫性 (参照文字やオブジェクトなど、画像内の固有の要素を保持して、複数のシーンや環境で一貫性を保つ) も実現します。
オンラインで実行:https://go.hyper.ai/PqRGn

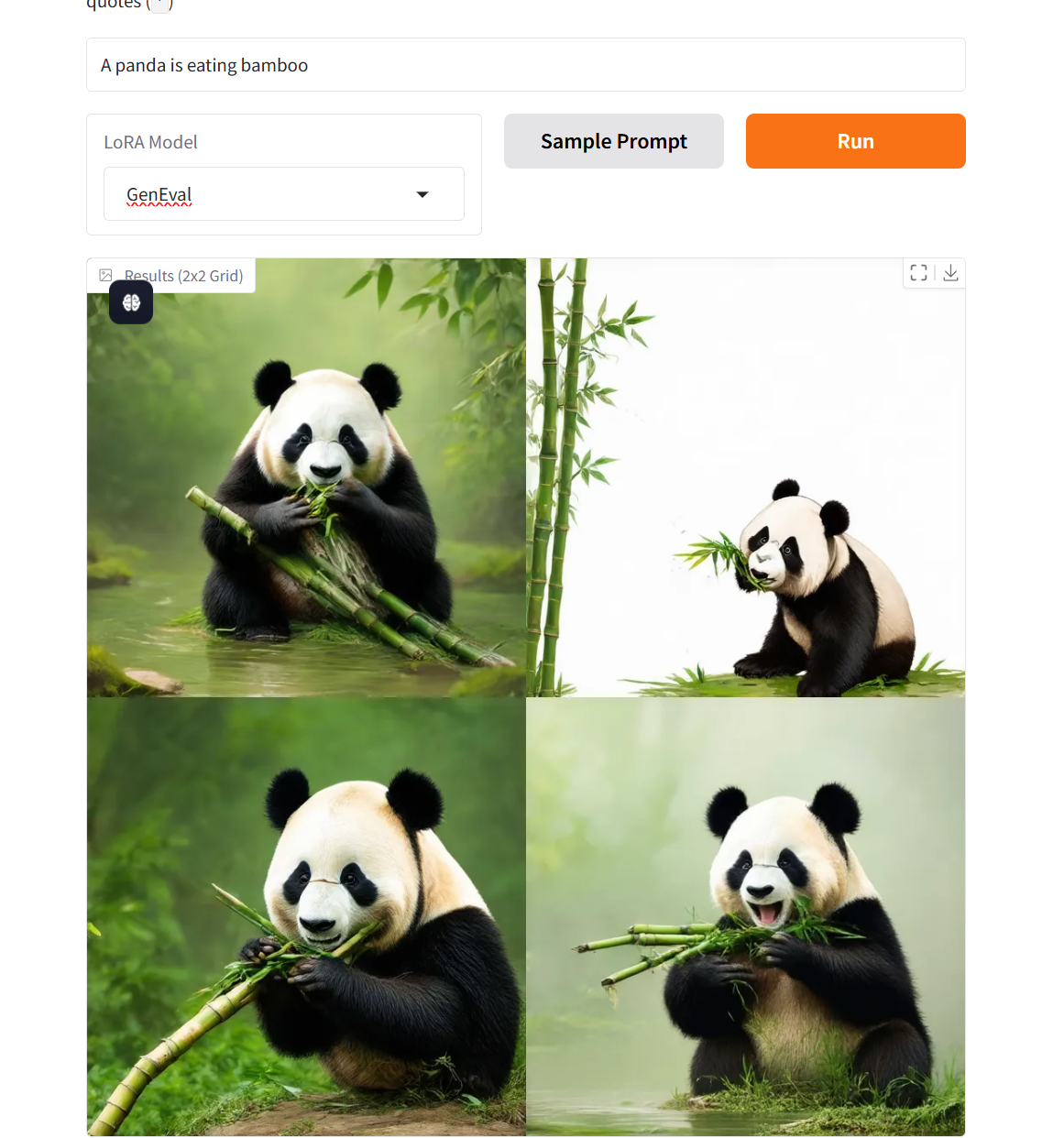
3. Flow-GRPOフローマッチングテキストグラフモデルデモ
このモデルは、オンライン強化学習フレームワークとフローマッチング理論の統合の先駆者であり、GenEval 2025ベンチマークテストで画期的な進歩を遂げました。SD 3.5 Mediumモデルの総合生成精度はベンチマーク値の63%から95%に急上昇し、生成品質評価指標は初めてGPT-4oを上回りました。
オンラインで実行:https://go.hyper.ai/v7xkq
3D生成チュートリアル
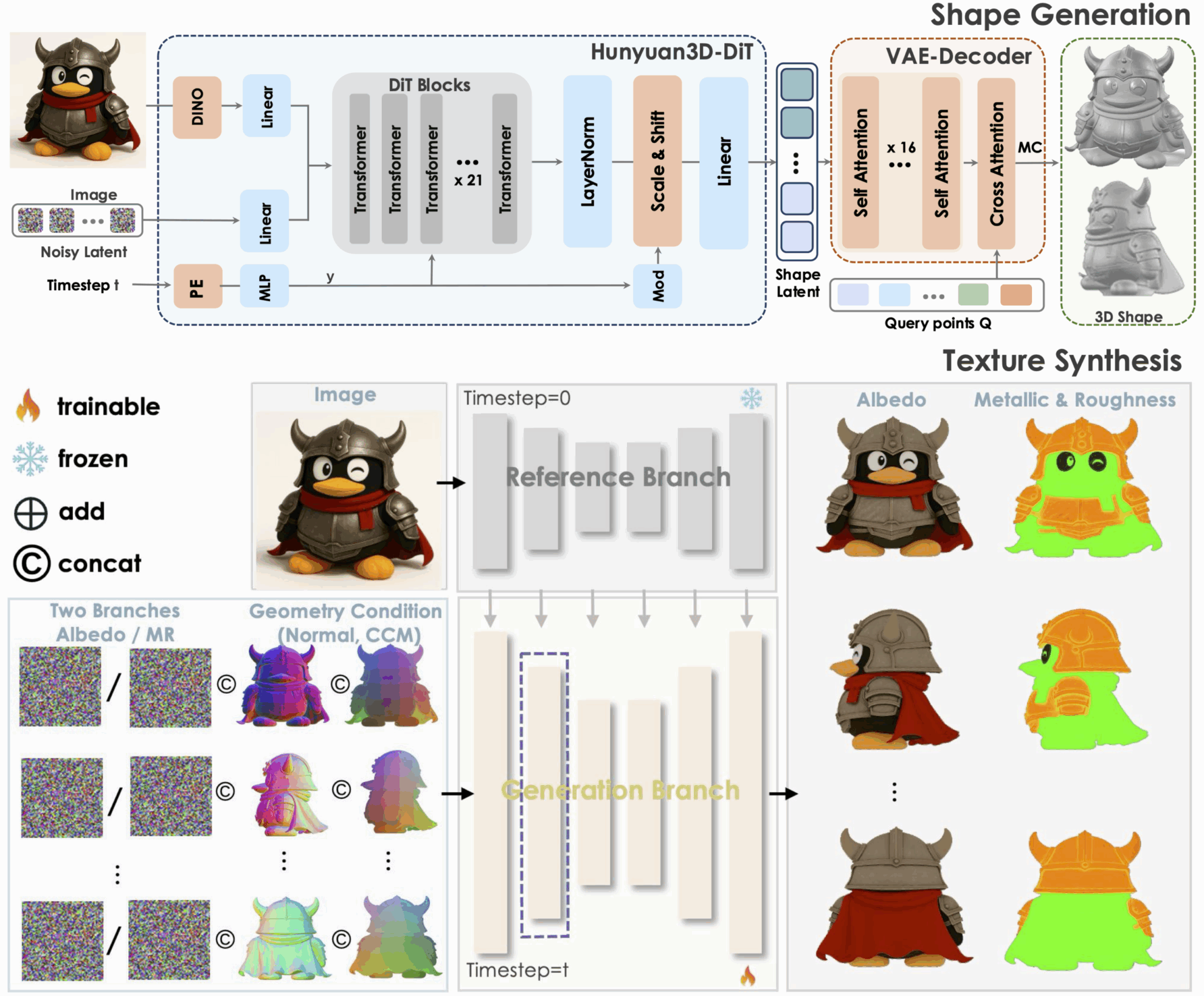
1. Hunyuan3D-2.1: 物理レンダリングテクスチャをサポートする3D生成モデル
Tencent Hunyuan3D-2.1は、産業グレードのオープンソース3D生成モデルとスケーラブルな3Dアセット作成システムです。完全にオープンソース化されたフレームワークと物理ベースレンダリングテクスチャ合成という2つの重要なイノベーションを通じて、最先端の3D生成技術の開発を促進します。同時に、データ処理、学習、推論コードなどを完全にオープン化することで、学術研究に再現可能なベースラインを提供し、産業実装における繰り返し開発コストを削減します。
オンラインで実行:https://go.hyper.ai/0H91Z
2. Direct3D-S2: 高解像度3Dレンダリングのためのフレームワーク
Direct3D-S2は、スパースボリューム表現と革新的な空間スパースアテンションメカニズムに基づき、拡散変換の計算効率を大幅に向上させ、学習コストを大幅に削減する高解像度3D生成フレームワークです。このフレームワークは、生成品質と効率の両面で既存の手法を凌駕し、高解像度3Dコンテンツ作成を強力にサポートします。
オンラインで実行:https://go.hyper.ai/67LQM

オーディオ生成チュートリアル
1. PlayDiffusion: オープンソースのオーディオローカル編集モデル
PlayDiffusionは、音声を個別のトークンシーケンスにエンコードし、修正が必要な部分をマスクします。そして、拡散モデルを用いて、更新されたテキストに基づいてマスクされた領域のノイズを除去することで、高品質な音声編集を実現します。文脈をシームレスに保持し、音声の一貫性と自然さを確保し、効率的なテキスト音声合成をサポートすることで、高い時間的一貫性とスケーラビリティを実現します。
オンラインで実行:https://go.hyper.ai/WTlI4
2. OuteTTS: 音声生成エンジン
OuteTTSはオープンソースのテキスト音声合成プロジェクトです。その革新性は、純粋な言語モデリング手法を用いることで、従来のTTSシステムにおける複雑なアダプタや外部モジュールに頼ることなく、高品質な音声を生成することにあります。主な機能には、テキスト音声合成と音声クローニングが含まれます。
オンラインで実行:https://go.hyper.ai/eQVHL
💡安定拡散チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] にメモし、グループに参加してさまざまな技術的な問題について話し合い、アプリケーションの効果を共有してください。

今週のおすすめ紙
1. GLM-4.1V思考:スケーラブルな強化学習による多用途マルチモーダル推論に向けて
本稿では、汎用的なマルチモーダル理解と推論を高度化するために設計された視覚言語モデル(VLM)であるGLM-4.1V-Thinkingを紹介します。強化学習とカリキュラムサンプリングを組み合わせることでモデルの潜在能力を最大限に引き出し、STEM問題解決、ビデオ理解、コンテンツ認識、プログラミング、共参照解決、GUIベースエージェント、長文文書理解など、多様なタスクにおいて包括的な機能を実現する手法を提案します。GLM-4.1V-9B-Thinkingは、同規模のオープンソースモデルの中で最先端の性能を達成し、長文文書理解やSTEM推論といった難解なタスクにおいては、GPT-4oなどのクローズドソースモデルと同等以上の性能を示します。
論文リンク:https://go.hyper.ai/5UuYG
2. Ovis-U1 技術レポート
本論文では、30億のパラメータを持つ統合モデルであるOvis-U1を紹介します。このモデルは、マルチモーダル理解、テキストから画像への生成、そして画像編集を統合しています。Ovisファミリーの基盤を基盤とするOvis-U1は、拡散視覚デコーダーと双方向タグ付けリファイナーを組み合わせることで、画像生成タスクにおいてGPT-4oなどの主要モデルに匹敵する性能を実現しています。Ovis-U1は、OpenCompassマルチモーダル学術ベンチマークで69.6というスコアを獲得し、Ristretto-3BやSAIL-VL-1.5-2Bといった近年の最先端モデルを凌駕しています。
論文リンク:https://go.hyper.ai/7Q8JV
3. BlenderFusion: 3Dを基盤としたビジュアル編集とジェネレーティブ合成
本論文では、オブジェクト、カメラ、背景を再結合することで新しいシーンを合成する生成的ビジュアル合成フレームワーク、BlenderFusionを提案します。このフレームワークは、レイヤー-編集-合成というパイプラインを採用しています。視覚入力はセグメント化され、編集可能な3Dエンティティに変換されます。その後、Blenderの3Dベースのコントロールを用いて編集され、生成的コンポジターを用いて一貫性のあるシーンに合成されます。実験結果では、BlenderFusionは複雑な合成シーン編集タスクにおいて、従来の手法を大幅に上回る性能を示すことが示されています。
論文リンク:https://go.hyper.ai/YoirX
4. SciArena: 科学文献タスクにおける基礎モデルのためのオープン評価プラットフォーム
本稿では、科学文献タスクにおけるベースモデルを評価するためのオープンで協調的なプラットフォームであるSciArenaを紹介します。従来の科学文献理解・統合ベンチマークとは異なり、SciArenaは研究コミュニティと直接連携し、Chatbot Arenaと同様の評価手法を採用しています。この評価手法では、コミュニティ投票を通じてモデルが比較されます。現在、このプラットフォームは23のオープンソースおよび独自仕様のベースモデルをサポートしており、複数の科学分野の信頼できる研究者から13,000件以上の投票を集めています。
論文リンク:https://go.hyper.ai/oPbpP
5. SPIRAL: ゼロサムゲームにおけるセルフプレイは、マルチエージェント・マルチターン強化学習を介して推論を奨励する
本論文では、モデルが複数ラウンドのゼロサムゲームを継続的に改善する自分自身と対戦することで学習するセルフプレイフレームワークであるSPIRALを紹介します。これにより、人間の監督は不要になります。大規模なセルフプレイ学習を可能にするため、研究者らは完全オンライン、複数ラウンド、マルチエージェント強化学習システムを実装し、マルチエージェント学習の安定化を図るため、役割条件付き優位性推定を提案しました。SPIRALを用いたゼロサムゲームのセルフプレイ学習は、広く応用可能な推論能力を生み出すことができます。
論文リンク:https://go.hyper.ai/n7J4m
AIフロンティアに関するその他の論文:https://go.hyper.ai/iSYSZ
コミュニティ記事の解釈
1. メタマテリアル設計がブレイクスルー!メタAIらが提案したUNIMATEは、トポロジー生成や性能予測といったタスクの統合モデリングを初めて実現した。
バージニア工科大学とMeta AIの研究チームは、革新的なモデルアーキテクチャを通じて、現在のAIによるメタマテリアル設計における主要なボトルネックを解決する統合モデル「UNIMATE」を提案しました。また、メタマテリアル設計の3つのコア要素、すなわち3次元トポロジカル構造、密度条件、および機械的特性の統合モデリングと協調処理を初めて実現しました。
レポート全体を表示します。https://go.hyper.ai/1x8iJ
2. チュートリアル付き: 医療VLMにおける新たなブレークスルー!HealthGPTは、複雑なMRIモダリティの理解において99.7%の精度を誇り、単一のモデルで複数の生成タスクを処理できます。
浙江大学は、中国電子科技大学をはじめとする研究チームと共同でHealthGPTモデルを提案しました。革新的な異種知識適応フレームワークを基盤として、医療におけるマルチモーダル理解と生成を統合する初の大規模視覚言語モデルの構築に成功し、医療AI開発の新たな道を切り開きました。関連成果はICML 2025に選出されています。
レポート全体を表示します。https://go.hyper.ai/F7W6a
3. タンパク質構造予測/機能アノテーション/相互作用同定/オンデマンド設計、中国海洋大学の張樹剛チームがタンパク質インテリジェントコンピューティングの中核タスクに直接取り組む
中国海洋大学コンピュータサイエンス学院の張樹剛准教授は、「タンパク質知能計算システムの構築と応用」と題した講演で、知能計算技術がもたらした革新的なブレークスルーについて体系的に解説しました。特に、タンパク質研究における従来の課題に焦点を当て、機能アノテーション、相互作用同定、設計最適化といった分野における研究成果に焦点を当てました。本稿は、張樹剛准教授の講演の記録です。
レポート全体を表示します。https://go.hyper.ai/rTgSi
4. ICML 2025 | ミュンヘン工科大学などがSD3に基づく衛星画像生成手法を開発し、現在最大のリモートセンシングデータセットを構築した。
ドイツのミュンヘン工科大学とスイスのチューリッヒ大学の研究チームは、地理的な気候条件を考慮した安定拡散モデル3(SD3)を用いて衛星画像を生成する新たな手法を提案し、これまでで最大かつ最も包括的なリモートセンシングデータセット「EcoMapper」を作成しました。このデータセットは、Sentinel-2から世界104,424地点から290万点以上のRGB衛星画像データを収集し、15種類の土地被覆タイプとそれに対応する気候記録を網羅しています。これは、微調整されたSD3モデルを用いた2つの衛星画像生成手法の基礎となります。
レポート全体を表示します。https://go.hyper.ai/1zpeD
5. CASPは廃止されるかもしれない!NIHの資金停止により、タンパク質構造予測コンペティションの将来は不透明
サイエンス誌は、米国立衛生研究所(NIH)からのCASPへの資金が枯渇したとする独占報道を発表し、プロジェクト資金の管理を担うカリフォルニア大学デービス校(UCデービス)が緊急支援を行っていたものの、これも8月8日に枯渇し、CASPは停止の危機に直面している。
レポート全体を表示します。https://go.hyper.ai/3kTMU
人気のある百科事典の項目を厳選
1. カン
2. シグモイド関数
3. 人間と機械のループHITL
4. RAG を生成するための検索機能の強化
5. 強化の微調整
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。
サミットの締め切りは7月
7月11日 7:59:59 ポピュラリティ 2026
7月15日 7:59:59 ソーダ2026
7月18日 7:59:59 シグモッド 2026
7月19日 7:59:59 ICSE2026
主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!








