Command Palette
Search for a command to run...
チュートリアル付き: 医療VLMにおける新たなブレークスルー!HealthGPTは複雑なMRIモダリティの理解において99.7%の精度を達成し、単一のモデルで複数の生成タスクを処理できます。

現代の医療診断と研究は、医用画像の解釈と生成に大きく依存しています。X線画像における病変の特定からMRIからCT画像への画像変換まで、それぞれのプロセスにおいてAIシステムのマルチモーダル処理能力に厳しい要件が課せられます。しかしながら、医療用視覚言語モデル(LVLM)の現在の開発は、2つのボトルネックに直面しています。一つは、医療データの特殊性により、大規模で高品質の注釈付きデータが不足しています。公開されている医療画像データセットのサイズは、一般的なデータセットの1万分の1程度に過ぎず、統一されたモデルをゼロから構築するというニーズに応えることは困難です。一方で、理解することとタスクを生成することの間には矛盾があり、それを調和させることは難しい。——理解タスクでは抽象的な意味の一般化が求められ、生成タスクでは細部の正確な保持が求められます。従来のハイブリッドトレーニングでは、「あることに集中する一方で別のことを失う」という問題が発生するため、パフォーマンスの低下につながることがよくあります。
技術進化の観点から見ると、Med-FlamingoやLLaVA-Medといった初期の医療用LVLMは、主に視覚理解タスクに焦点を当て、画像とテキストのアライメントを通じて医療画像の意味解釈を実現していましたが、「可視化」生成能力が欠けていました。Unified-IO 2やShow-oといった汎用統合LVLMは、生成機能を備えているものの、医療データへの適応が不十分なため、専門タスクのパフォーマンスは低いものでした。2024年のノーベル化学賞は、AIによるタンパク質構造予測分野における画期的な成果に対して授与されました。これは、生命科学分野におけるAIの潜在能力を間接的に証明するものであり、理解と生成の両方の機能を備えた医療用LVLMの構築が、現在の医療AI応用のボトルネックを打破する鍵となっていることを学界に認識させました。
この点について、浙江大学と中国電子科技大学が共同でHealthGPTモデルを提案した。革新的な異種知識適応フレームワークを通じて、医療のマルチモーダル理解と生成を統合する初の大規模視覚言語モデルの構築に成功しました。医療AI開発に新たな道を切り開き、その成果はICML2025に選定されました。
用紙のアドレス:
医療データの制限とタスクの競合という 2 つの大きな課題に対応するため、研究チームは 3 層の段階的なソリューションを提案しました。
まず、異種低ランク適応 (H-LoRA) テクノロジを設計します。タスク ゲーティング分離メカニズムにより、理解と生成の知識は独立した「プラグイン」に保存され、従来の共同最適化の競合問題を回避します。
第二に、階層的視覚知覚(HVP)フレームワークを開発し、Vision Transformer の階層的特徴抽出機能を活用して、理解タスク用の抽象的な意味的特徴を提供し、生成タスク用の詳細な視覚的特徴を保持することで、「オンデマンド」の特徴調整を実現します。
最後に、3 段階学習戦略 (TLS) が構築されます。マルチモーダルアライメントから異種プラグインの融合、そして視覚指示の微調整まで、モデルは徐々に特殊なマルチモーダル処理能力を備えていきます。
データセット: VL-Health のマルチモーダル医療知識グラフ
HealthGPTトレーニングをサポートするために、研究チームは、医療のマルチモーダル理解と生成のための最初の包括的なデータセット VL-Health を構築しました。このデータセットには、765,000 件の理解タスク サンプルと 783,000 件の生成タスク サンプルが統合されており、11 種類の医療モダリティ (CT、MRI、X 線、OCT など) と複数の疾患シナリオ (肺疾患から脳腫瘍まで) をカバーしています。
データセットアドレス:
https://hyper.ai/cn/datasets/40990
理解タスクに関しては、VL-HealthはVQA-RAD(放射線学の質問)、SLAKE(セマンティックアノテーション知識強化)、PathVQA(病理学の質問回答)などの専門データセットを統合し、LLaVA-MedやPubMedVisionなどの大規模マルチモーダルデータを補完することで、モデルが基本的な画像認識から複雑な病理学的推論に至るまでの一連の機能をフルに学習できるようにします。生成タスクは主に、モダリティ変換、超解像、テキスト画像生成、画像再構成という4つの主要な方向に焦点を当てています。
* モーダル変換:SynthRAD2023のCT-MRIペアデータに基づいて、モデルのモダリティ間変換機能をトレーニングします。
* 超解像度:IXI データセットの高解像度脳 MRI を使用して、画像詳細再構成の精度を向上します。
* テキスト画像生成:MIMIC-CXR に基づく X 線画像とレポート。テキスト記述から画像への生成を実現します。
* 画像再構成:LLaVA-558k データセットを採用し、モデルの画像エンコード/デコード機能をトレーニングしました。
データ処理フェーズでは、チームはスライス抽出、画像登録、データ強化などの医療画像の標準化された前処理を実行しました。そして、すべてのサンプルを「コマンドレスポンス」形式に統一し、モデルのトレーニング後の指導を容易にします。
モデルアーキテクチャ:視覚認識から自己回帰生成までの完全なチェーン設計
HealthGPTは、「ビジュアルエンコーダー-LLMコア-H-LoRAプラグイン」の階層化アーキテクチャを採用し、マルチモーダル情報の効率的な処理を実現します。
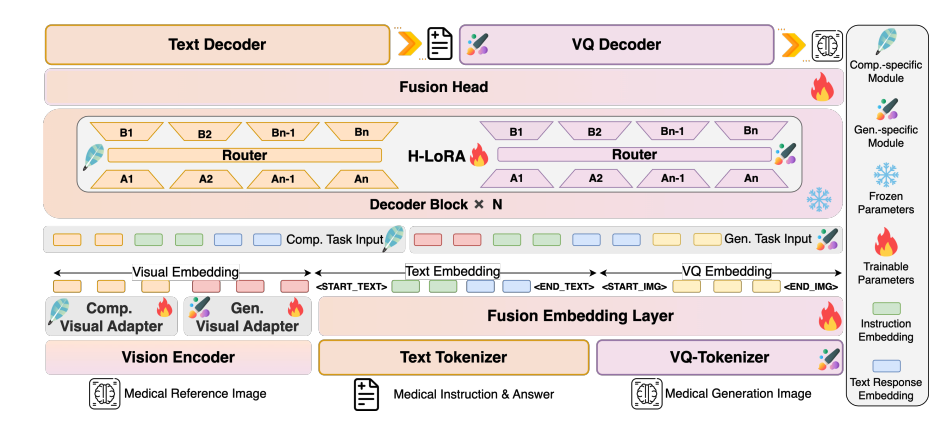
モデルアーキテクチャ図
視覚エンコーディング層: 階層的特徴抽出
CLIP-L/14は、浅い特徴(第2層)と深い特徴(最後から2番目の層)を抽出するためのビジュアルエンコーダとして使用されます。浅い特徴は、画像の詳細を保持するために2層MLPアダプタを介して具体的な粒度特徴に変換されます。深い特徴は、アダプタによって抽象的な粒度特徴に変換され、意味概念を捉えます。このデュアルトラック特徴抽出メカニズムは、後続の理解および生成タスクのための適応的な視覚表現を提供します。
LLMコア:一般知識ベース
Phi-3-miniとPhi-4をベースに、異なるパラメータを持つ2つのモデル、HealthGPT-M3(モデルパラメータボリュームは38億)とHealthGPT-L14(モデルパラメータボリュームは14億)を構築しました。LLMコアはテキスト理解と生成だけでなく、自己回帰メカニズムを通じて視覚トークンシーケンスを均一に処理します。理解タスクではテキスト応答を出力し、生成タスクではVQGANインデックスシーケンスを出力し、その後VQGANデコーダーを介して画像を再構成します。
H-LoRAプラグイン: ミッション固有のアダプター
H-LoRAプラグインをLLMの各Transformerブロック(理解と生成の2種類のサブモジュールを含む)に挿入します。各サブモジュールには複数のLoRAエキスパートが含まれており、タスクタイプと入力隠れ状態の動的ルーティングを通じて、知識の選択的な活性化が実現されます。このプラグインはLLMの固定重みと組み合わせることで、「一般知識 + タスク専門知識」のハイブリッド推論モードを形成します。
実験的結論: HealthGPTは医療視覚理解および生成タスクにおいて大幅に先行している
使命を理解する:専門能力でリードする
医療視覚理解タスクにおいて、HealthGPTは既存のモデルを大きく上回りました。HealthGPTを他の医療特化型および汎用型モデル(Med-Flamingo、LLA-VA-Med、HuatuoGPT-Vision、BLIP-2など)と比較した結果、以下のことが示されました。HealthGPT は医療の視覚理解タスクで優れたパフォーマンスを発揮し、他の医療特化型モデルや一般モデルを大幅に上回ります。
VQA-RADデータセットにおいて、HealthGPT-L14はLLaVA-Medと比較して29.1%向上し、77.7%の精度を達成しました。OmniMedVQAベンチマークテストでは、平均スコアが74.4%となり、CT、MRI、OCTを含む7つのサブタスクのうち6つで最高の結果を達成しました。特に、複雑なMRIモダリティの理解精度は99.7%と高く、難解な医用画像に対する深い理解力を示しました。
生成タスク:モダリティ変換と超解像におけるブレークスルー
生成タスク実験では、HealthGPTが医用画像の変換と強化において優れた性能を発揮することが示されました。CT-MRIモダリティ変換タスクにおいて、HealthGPT-M3のSSIM指数は79.38(Brain CT2MRI)に達し、従来のPix2Pix法よりも11.6%高く、骨盤などの複雑な領域における変換精度も優れています。超解像タスクでは、SSIMは78.19、PSNRは32.76に達し、特に脳構造の微細な再構成において、SRGAN、DASRなどの専用モデルを凌駕する詳細な復元性能を示しました。
注目に値するのは、HealthGPT は、単一のモデルで複数の生成タスクを処理できます。従来の方法では、サブタスクごとに独立したモデルをトレーニングする必要があり、統合フレームワークの効率性の利点が強調されます。
方法の検証:H-LoRAの価値と3段階戦略
除去実験により、コア技術の必要性が確認されました。H-LoRA を除去した後、理解タスクと生成タスクの平均パフォーマンスは 18.7% 減少しました。3 段階戦略の代わりにハイブリッド トレーニングを採用すると、タスクの競合により 23.4% のパフォーマンス低下が発生しました。
H-LoRAとMoELoRAの比較では、4人のエキスパートを用いた場合、H-LoRAの学習時間はMoELoRAのわずか67%であるのに対し、パフォーマンスは5.2%向上しており、計算効率とタスクパフォーマンスの両面で優位性があることを示しています。階層的視覚知覚の役割も検証されています。理解タスクで抽象的な特徴を使用すると収束速度が 40% 向上し、生成タスクで具体的な特徴を使用すると画像忠実度が 25% 向上します。
臨床応用の可能性:研究から実践への架け橋
人間による評価実験では、5 人の臨床医が 1,000 個の自由形式の質問に対する回答を盲検で評価しました。HealthGPT-L14の回答のうち「ベストアンサー」として選ばれた回答の割合は65.7%に達しました。LLaVA-Med(34.08%)とHuatuoGPT-Vision(21.94%)をはるかに上回ります。
現在のところ、ハイパーAI ハイパー.ai「HealthGPT: AI 医療アシスタント」チュートリアルがチュートリアル セクションで利用できるようになりました。医療画像をアップロードするだけで、プロの医師と同等の相談会話が始まります。ぜひご体験ください!
チュートリアルのリンク:
デモの実行
1. hyper.ai ホームページにアクセス後、「チュートリアル」ページを選択し、「HealthGPT: AI Medical Assistant」を選択して、「このチュートリアルをオンラインで実行」をクリックします。

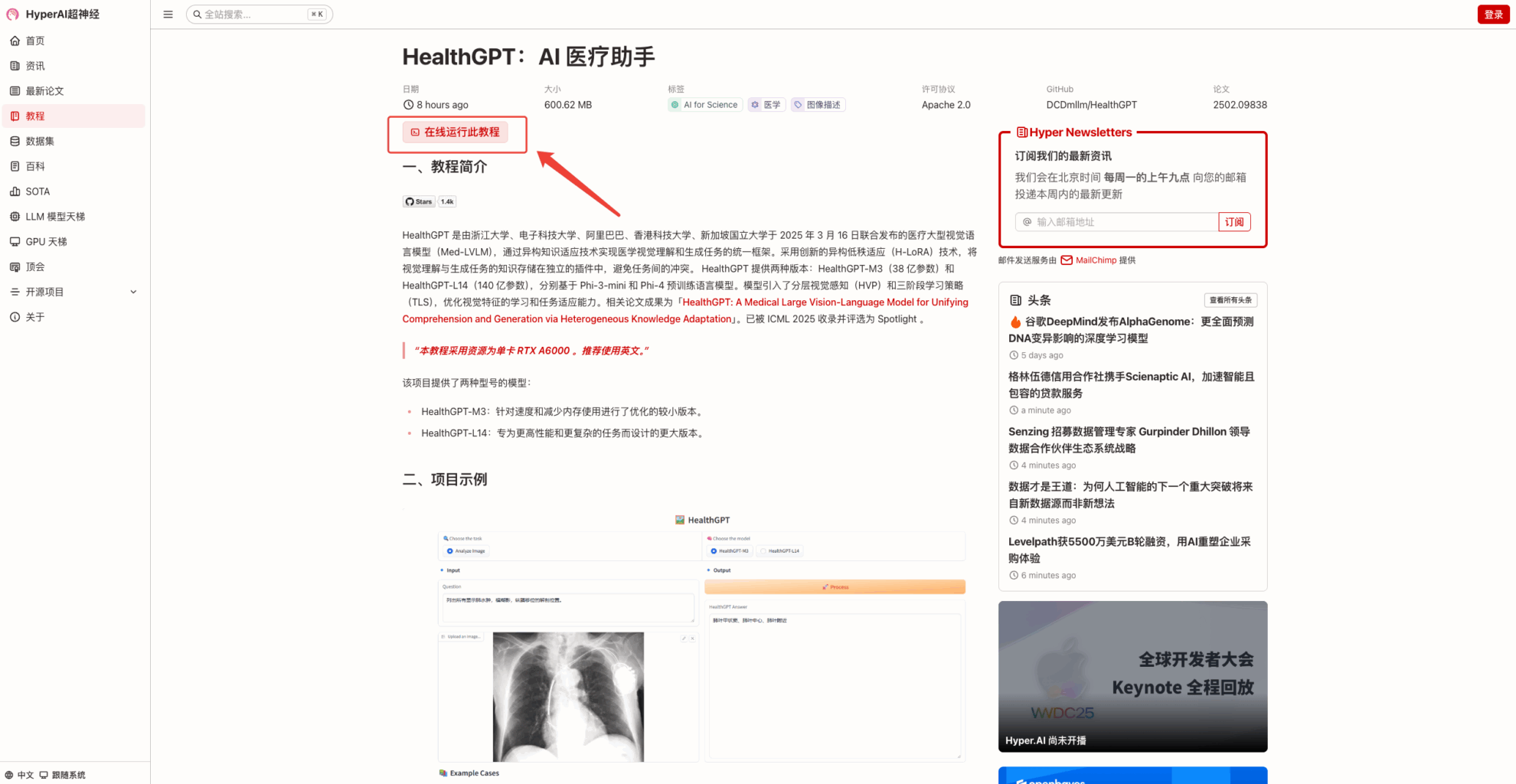
2. ページがジャンプしたら、右上隅の「クローン」をクリックしてチュートリアルを独自のコンテナにクローンします。
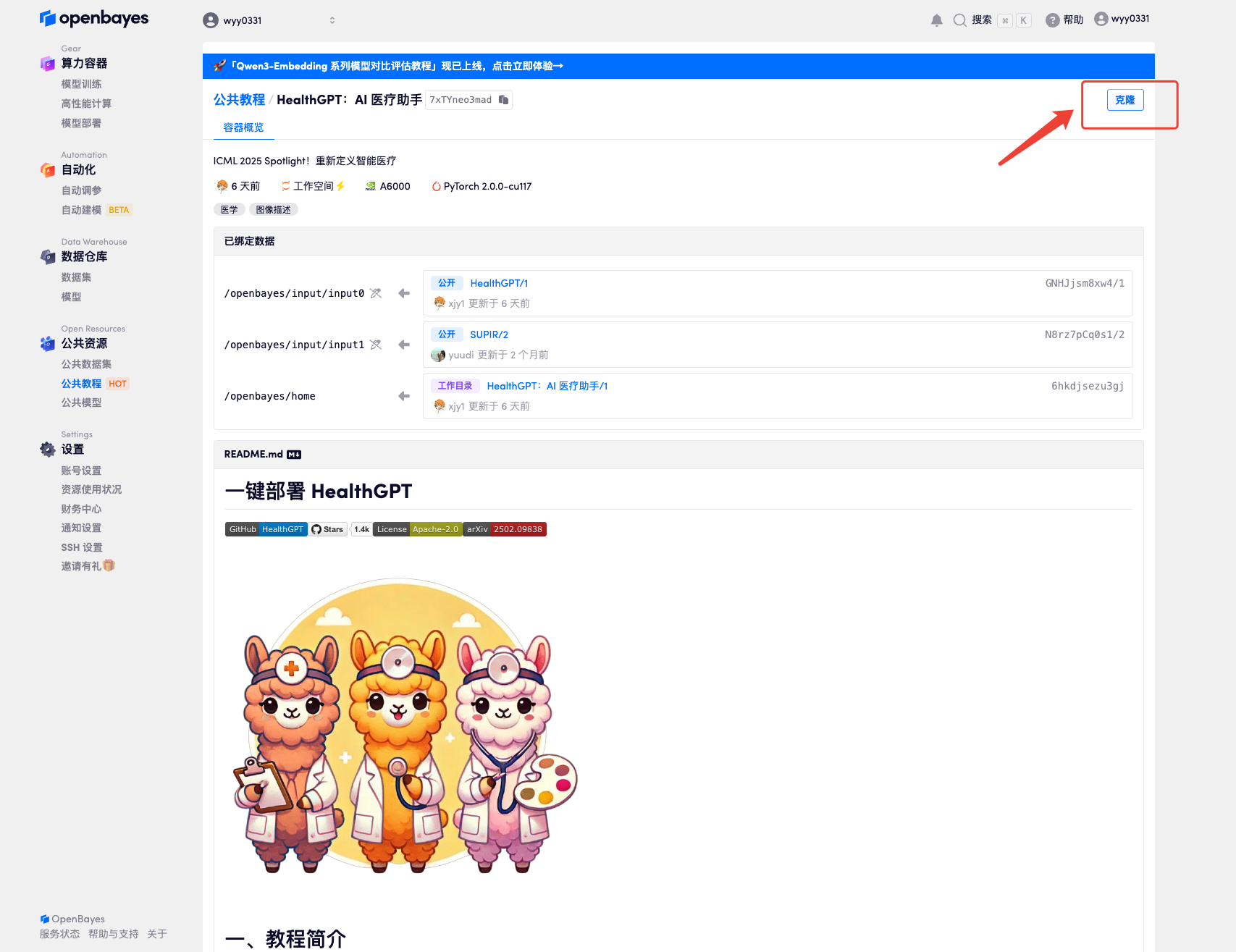
3. 「NVIDIA RTX A6000」と「PyTorch」のイメージを選択してください。OpenBayesプラットフォームでは4つの課金方法をご用意しています。ニーズに合わせて「従量課金制」または「日次/週次/月次」からお選びいただけます。「続行」をクリックしてください。新規ユーザーは、以下の招待リンクから登録すると、RTX 4090を4時間分とCPUを5時間無料でご利用いただけます。
HyperAI ハイパーニューラルの専用招待リンク (ブラウザに直接コピーして開きます):
https://openbayes.com/console/signup?r=Ada0322_NR0n
4. リソースが割り当てられるのを待ちます。最初のクローン作成プロセスには約 2 分かかります。ステータスが「実行中」に変わったら、「API アドレス」の横にあるジャンプ矢印をクリックしてデモ ページに移動します。モデルが大きいため、WebUI インターフェイスが表示されるまでに約 3 分かかります。そうでない場合は、「Bad Gateway」と表示されます。 APIアドレスアクセス機能を使用する前に、ユーザーは実名認証を完了する必要がありますのでご注意ください。
効果実証
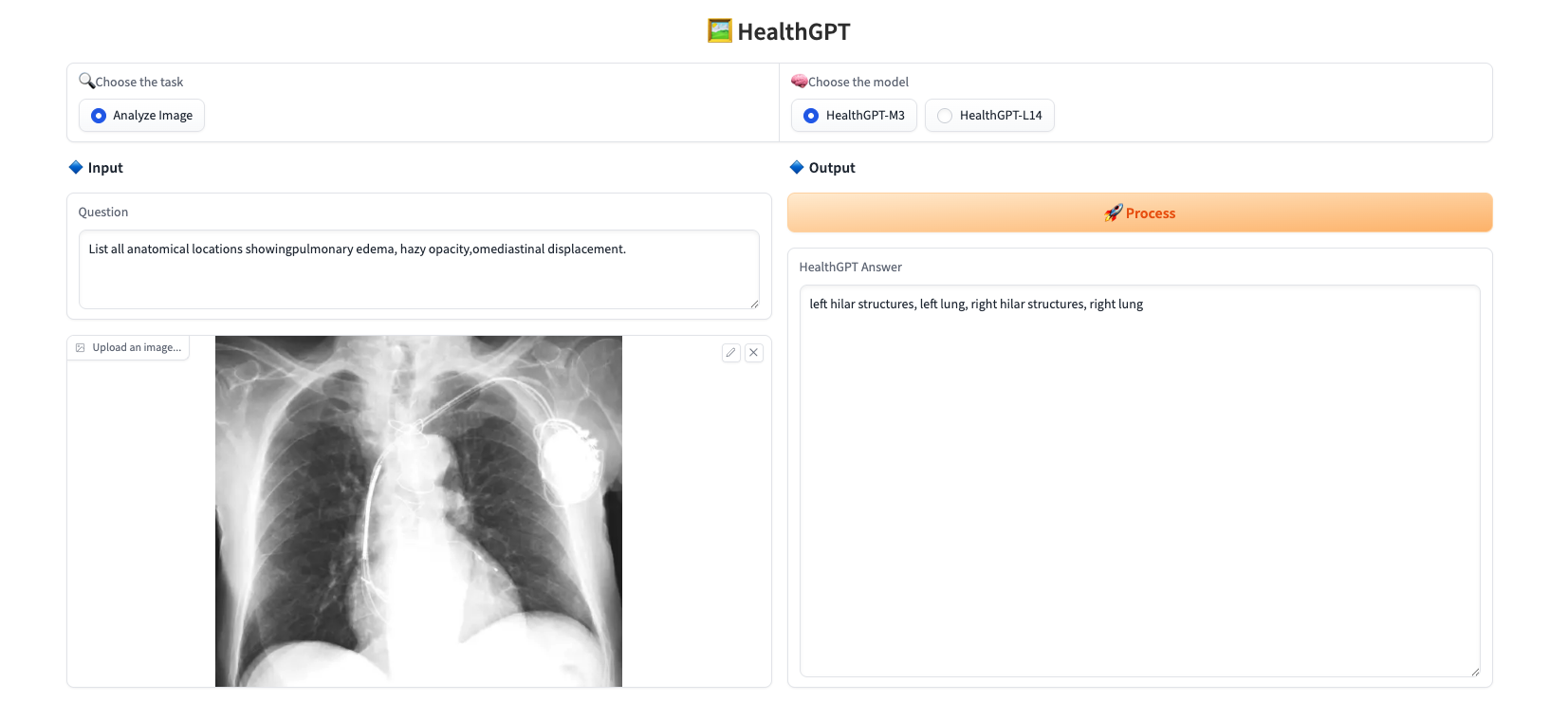
写真をアップロードし、「質問」に質問内容を入力し、「モデルを選択」でモデルを選択し、「処理」をクリックすると、リアルタイムで回答が表示されます。このプロジェクトでは、以下の2つのモデルを提供しています。
* HealthGPT-M3: 速度とメモリ使用量の削減を最適化した小型バージョンです。
* HealthGPT-L14: より高いパフォーマンスとより複雑なタスク向けに設計された大型バージョンです。
応答の例を以下に示します。
上記はHyperAIが推奨するチュートリアルです。ご興味のある方はぜひお試しください⬇️
チュートリアルのリンク:








