Command Palette
Search for a command to run...
タンパク質構造予測/機能注釈/相互作用認識/オンデマンド設計、中国海洋大学の張樹剛チームがタンパク質インテリジェントコンピューティングの中核タスクに直接取り組む
タンパク質は生命活動の主たる担い手として、人体の生理機能において重要な役割を果たしています。しかし、従来の研究では、構造解析の高コスト、機能アノテーションの深刻な遅れ、新規タンパク質設計の低効率などの課題に直面しています。近年、生命科学におけるタンパク質の複雑な特性解析の需要はますます緊迫したものとなっています。ビッグデータ、ディープラーニング、マルチモーダルコンピューティングなどの技術の画期的な発展は、タンパク質インテリジェントコンピューティングシステムの構築に新たな発展の機会をもたらしました。タンパク質インテリジェントコンピューティングシステムの構築により、タンパク質は大規模な機能アノテーション、相互作用予測、三次元構造モデリングの分野で目覚ましい成果を上げ、創薬や生命システムシミュレーションに新たな技術的道筋をもたらしました。
2025年北京知源会議において、中国海洋大学コンピュータサイエンス学院の張樹剛准教授が「AI+科学・工学・医学」フォーラムで「タンパク質インテリジェントコンピューティングシステムの構築と応用」について講演しました。本論文では、タンパク質インテリジェントコンピューティングシステムの中核価値から始めて、タンパク質構造予測、機能注釈、相互作用認識、新設計という 4 つの中核タスクの技術的進歩を体系的に説明します。チームの関連する研究結果が強調されました。

HyperAIは、張樹剛准教授の詳細な講演内容を、本来の趣旨を損なうことなく編集・要約しました。以下は講演の書き起こしです。
タンパク質インテリジェントコンピューティングシステムの概要:AI主導のライフサイエンス革命
生命科学研究において、タンパク質の重要性は明白です。タンパク質は生化学反応を触媒する酵素であるだけでなく、シグナル伝達を司るメッセンジャーであり、体の構造基盤を構成し、外敵に抵抗する免疫システムの「武器」でもあります。しかし、従来の研究手法は、タンパク質の複雑な特性を前にすると無力に思えます。構造解析の高コスト、機能アノテーションの深刻な遅れ、タンパク質設計の成功率の低さといった問題が、重要な課題となっています。
AI技術の導入により、この状況は完全に逆転しました。2024年には、AIによるタンパク質構造予測と設計における画期的な成果に対してノーベル化学賞が授与されました。これは、タンパク質研究におけるAIの重要な地位を改めて明確に示したことは間違いありません。タンパク質インテリジェントコンピューティングは、データ駆動型アルゴリズム モデルを構築することで、複雑なタンパク質特性の効率的なシミュレーションと予測を実現します。また、上記の課題に対処するための新しいアイデアと研究パラダイムを提供し、生命科学研究の新しい時代を切り開きます。
タンパク質知能コンピューティングの中核タスクにおけるブレークスルー
タンパク質インテリジェントコンピューティングの中心的な課題は、次の 4 つのカテゴリです。
タンパク質の構造をゼロから予測することは可能でしょうか?
レビンタールのパラドックスから AlphaFold の破壊まで
タンパク質の折り畳みを例にとると、100 個の残基を持つタンパク質には最大 10 個の立体配座が考えられます。200 ランダム探索の場合、必要な時間は宇宙の年齢(138億年)よりもはるかに長くなり、これは有名なレビンタールのパラドックスです。しかし、実際のタンパク質の折り畳みは数ミリ秒から数分で完了するため、特定の折り畳み経路が存在することが示唆されます。
2018年、第一世代のAlphaFoldモデルは、残差畳み込みモジュールを使用してアミノ酸ペアの距離とねじれ角を予測し、ディープラーニング手法を使用して問題の解決を試みました。CASP13 では、25 個のタンパク質構造を正確に予測し、他の競合製品を大きくリードしました。2位は3つだけ正しく予測しました。
2021年、第2世代モデルは質的な飛躍を遂げました。AlphaFold2はHMMERとHH-suiteを用いて、多重配列アライメントとテンプレート検索を実行しました。48 個の Evoformer モジュールと 8 個の Structure モジュールにより、原子精度のタンパク質構造予測を実現します。約2億1,400万件のタンパク質モノマー予測を含むデータベースが公開されました。予測構造と電子顕微鏡解析結果との平均誤差は1原子幅を超えず、「高精度」の基準に達しています。
2024年には、第3世代モデルが生体内タンパク質相互作用構造の完全な予測をさらに実現します。AlphaFold3は質的な飛躍を遂げました。タンパク質構造を予測するだけでなく、また、タンパク質、核酸、小分子、イオン、その他すべての生命分子から構成される複合体の構造を予測することもできます。PDB データベース内のほぼすべての分子タイプをカバーしており、細胞の機能や病気の治療を理解するための強力なツールを提供します。
タンパク質の機能を自動的に注釈付けできるか:マルチソースデータ融合におけるブレークスルー
AlphaFold3がタンパク質予測分野において先見的な進歩を遂げたことを受け、当チームは研究の焦点をタンパク質機能アノテーションと相互作用解析の分野に移すことを決定しました。現在、世界中の2億5000万のタンパク質配列のうち、正確な機能アノテーションを完了したTP3Tはわずか0.51個です。生物学専門家による手作業による解析に頼る従来のモデルでは、膨大なデータという課題に対応できませんでした。そのため、ディープラーニングを用いた大規模バッチアノテーションの実現は、重要なブレークスルーとなりました。
この分野での私たちの探求は2022年に始まりました。ディープラーニングが依存する電子顕微鏡構造データが不足しており、コストが高いという業界の悩みを解消するために、私たちは、モデルのトレーニングに AlphaFold2 によって予測された仮想構造データを使用するという革新的な提案をします。この戦略は「データ拡張」に似ており、従来の電子顕微鏡で提供できる500万サンプルから、理論上は数億サンプルという大規模な予測データプールへと、学習データの規模を大幅に拡大しました。実験検証では、予測データに基づいて学習したモデルはネイティブバージョンよりも優れた性能を発揮するだけでなく、従来の手法では特定できなかった新しいタンパク質機能を発見できることが示されています。
論文のタイトル:AlphaFold予測タンパク質構造を活用したタンパク質機能予測性能の向上
用紙のアドレス:
https://pubs.acs.org/doi/10.1021/acs.jcim.2c00885
技術革新に関しては、不十分なタンパク質構造情報マイニングの問題を解決するために、私たちのチームは自己教師付きグラフ注意に基づくタンパク質機能予測法を提案しました。タンパク質分子内の残基の相関情報をコード化し、補助的なタスクとして残基間の距離情報を最大限に活用することで、タンパク質機能予測のパフォーマンスを向上させることができます。
論文のタイトル:SuperEdgeGO: 強化されたタンパク質機能予測のためのエッジ教師付きグラフ表現学習(近日公開予定)
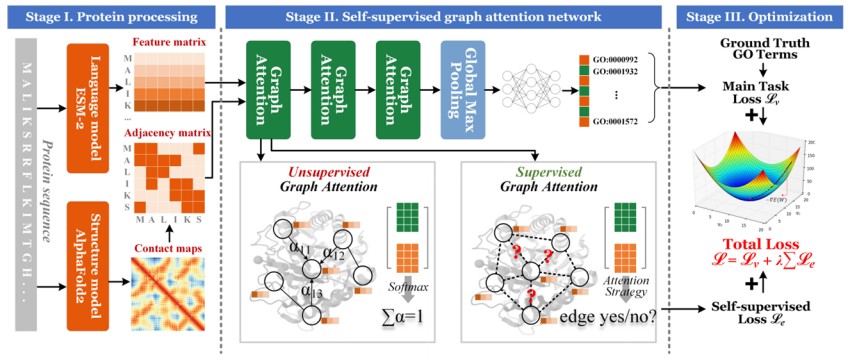
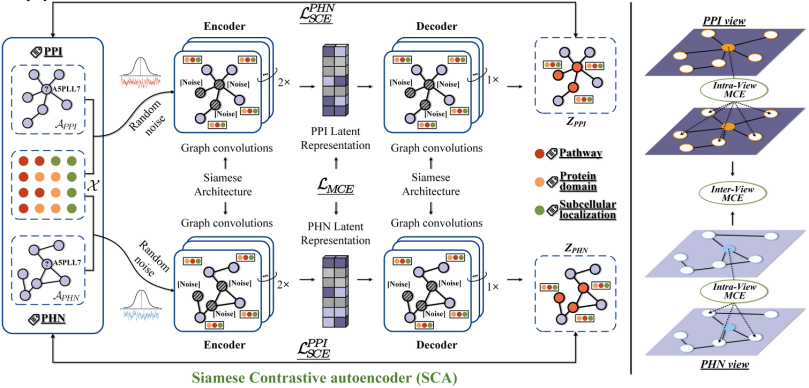
融合が困難で空間的に一貫性のない異種のタンパク質特性の問題に対処するために、タンパク質デュアルビュー構築戦略と特性アライメント法が提案されました。6つのクロススケールモード(配列、3次元構造、機能ドメインなどの次元をカバー)を持つ生物学的タンパク質の複雑な特性に基づいて、チームはさらにマルチモーダル融合戦略を提案した。——コンピューティング分野における対照学習と多視点分析手法を統合し、階層的特徴融合モデルを構築しました。このソリューションは、7つのデータセットにおいて20の主流ベースライン手法と比較され、いずれもSOTA結果を達成しました。これにより、モダリティの直接的なスプライシングによって引き起こされる性能低下という技術的課題を解決しました。
論文のタイトル:複数の生物学的モダリティを融合してタンパク質機能を注釈する
用紙のアドレス:https://www.nature.com/articles/s42003-024-07411-y
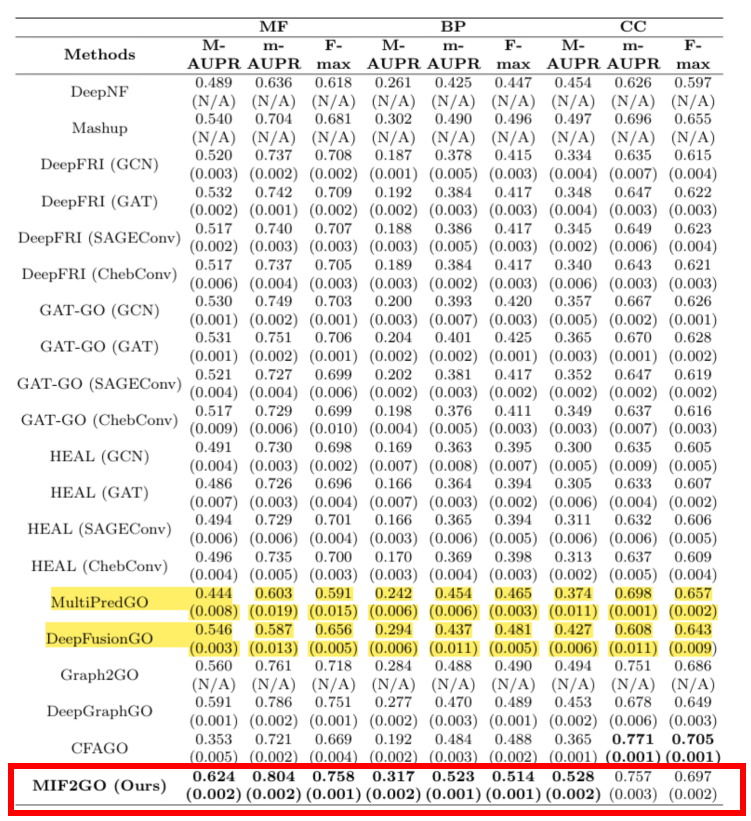
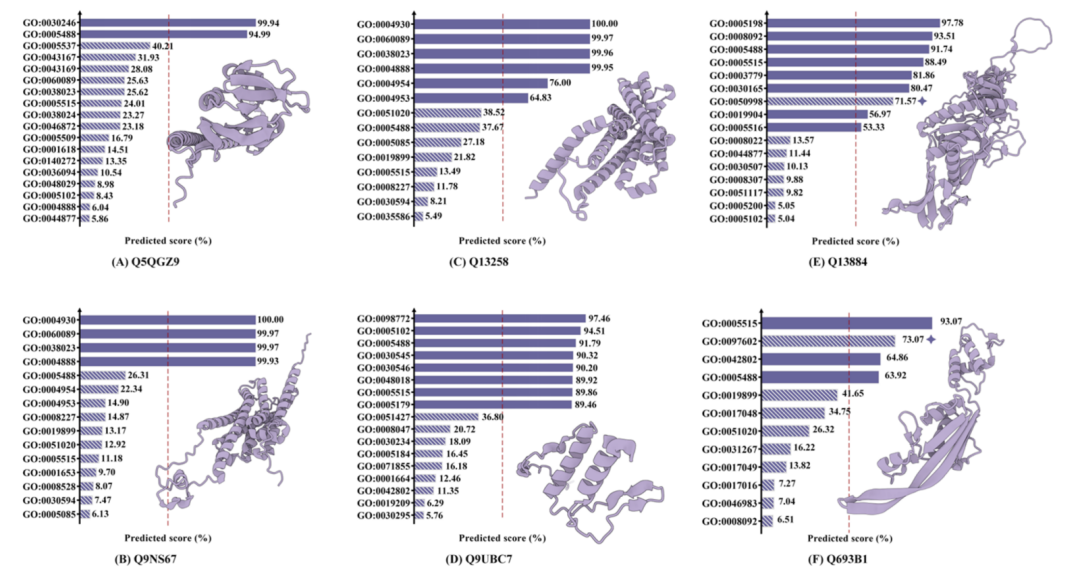
さらに、機能予測の解釈可能性の研究では、このモデルは、数千の GoTerms アノテーションから 10 を超えるタンパク質機能を正確に識別する優れた能力も示しました。さらに、研究チームは文献調査を通じて、モデルが誤差を予測しながらも高い信頼度を示した事例が、実際にはいくつかの研究で記録されていることを発見しました。これは、データセットのバージョンの遅れにより、これらの事例が誤って判断された可能性があることを示唆しています。この発見は、新しいタンパク質機能の探索におけるAIモデルの可能性を浮き彫りにしています。
タンパク質相互作用を正確に特定できるか?独自開発のモデルで効率的な予測が可能に
医薬品開発分野において、ヒト標的タンパク質の正確なドッキングは薬効の鍵であり、AI技術はこのプロセスにおいて重要な価値を示しています。AlphaFold3はタンパク質構造予測の分野で優れた成果を上げていますが、実用化には明らかな限界があります。無料版では1日20回のアクセスしかサポートされず、カバーされる分子の種類も15~20種類程度にとどまっており、商用利用権の申請も非常に困難です。そのため、チームは独自のモデルを開発するに至りました。
この問題に基づいて、チームは次のタスクに重点を置きました。
まず、既存のタンパク質相互作用予測法では相乗効果が乏しいという問題に取り組みました。タンパク質表現の協調的一貫性を高めるためにエンコーダにツイン学習モデルが導入され、タンパク質相互作用協調メカニズムとタスク協調メカニズムを備えた協調学習フレームワークが提案されています。研究チームは、インタラクティブ・アテンションとマルチタスク学習法を使用して、タンパク質-核酸、タンパク質-タンパク質、タンパク質-小分子のインタラクティブな予測を実現しました。
チームはまた、NLP 分野で Transformer とグラフ ニューラル ネットワークを統合し、リモート インタラクティブ モデリングを実現するための Convformer や Graphormer などのモジュールを開発しました。クロスアテンションメカニズムは、マルチモーダル情報の融合を強化するために用いられています。このモデルは実際のシナリオにおいて高い汎化能力を示しており、膵臓がんのシグナル伝達経路の予測を例に挙げると、その精度は95%を超え、相互作用予測誤差はわずか9組でした。
論文のタイトル:SSPPI: 配列と構造の観点からのクロスモダリティ強化タンパク質間相互作用予測(近日公開予定)
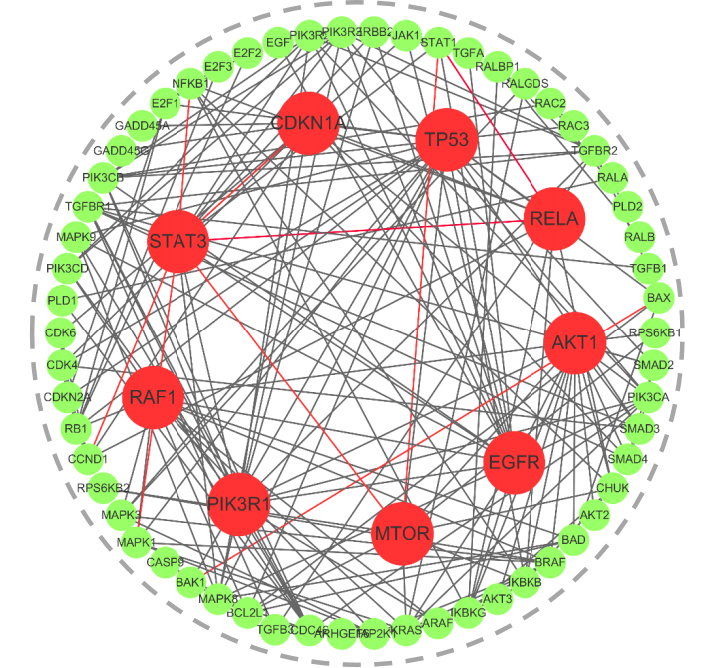
黒線:正しい予測、赤線:誤った予測
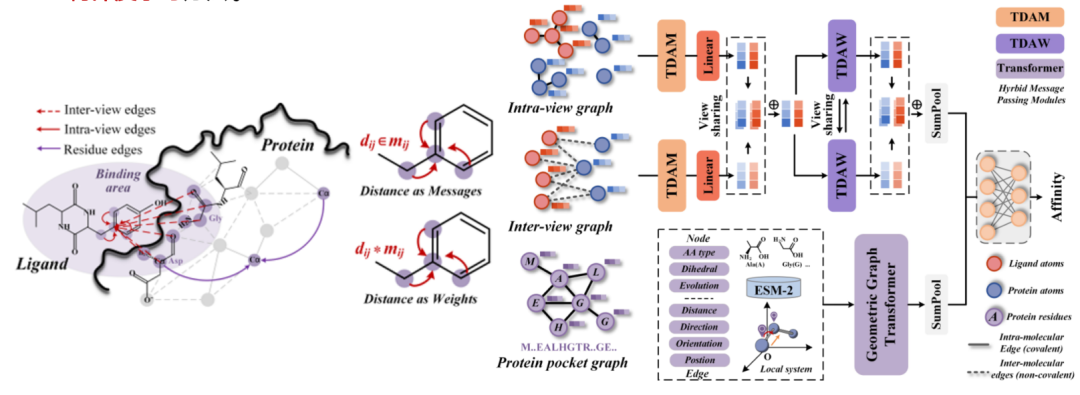
最近の研究では、ネットワークレベルでのタンパク質のクロススケール次元削減に加え、タンパク質の特徴量のマイニングにも取り組んでいます。従来のグラフモデルでは、3次元構造情報を2次元に削減する際に情報損失が発生するため、最新の幾何学的深層学習を導入しました。ハイブリッド メッセージ パッシング戦略に基づく幾何学的ディープラーニング手法を提案し、完全な 3 次元情報統合パラダイムを構築します。このパラダイムは、空間サイトモデリングで 3 次元情報を破棄することの不合理性を解決し、タンパク質 3 次元モデリングの分野に新しい研究アイデアを提供することを目的としています。
論文のタイトル:ハイブリッドメッセージパッシング戦略を用いたタンパク質-リガンド親和性予測のための幾何学的深層学習(近日出版予定)
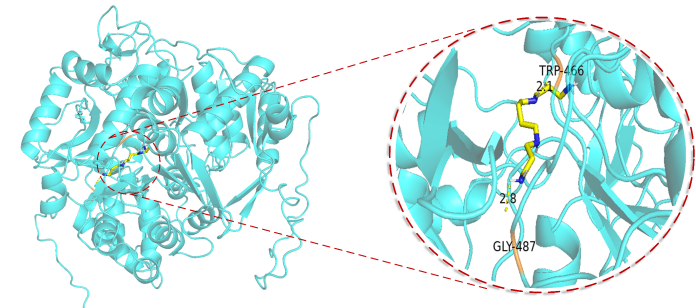
また、また、ACSS2タンパク質に対して実際の試験を実施し、数万の化合物の中からいくつかの候補化合物を選別しました。モデル予測の結果、スクリーニングされた化合物の親和性はnMレベルに達する可能性があり、優れた薬物ポテンシャルを示していることが示されました。私たちのチームは青島大学医学部のチームと協力して検証を行い、最近実施したウェット実験でもドッキング結果が予備的に確認されました。
新しいタンパク質はオンデマンドで設計できるか:逆問題から革新的な応用まで
タンパク質設計はタンパク質研究の究極の目標の一つであり、ワクチン開発、がん治療、バイオマテリアル開発において極めて重要です。しかし、タンパク質フォールディングの逆問題として、タンパク質配列設計は探索空間の爆発や従来の力場シミュレーションにおける誤差といった課題にも直面しています。
インテリジェントなタンパク質設計と最適化という核心的な課題に向き合い、昨年ノーベル賞を受賞したベイカー氏のチームの最新研究を例に挙げましょう。ヘビ毒には特効薬がありません。コンピューターをベースに新しいタイプのタンパク質を設計することは可能でしょうか?この問題を踏まえ、ベイカー氏のチームは既存のProteinMPNNとRFDiffusionを組み合わせ、新しいタンパク質を設計しました。さらに、チームはヘビ毒に特異的に結合するタンパク質の設計も行い、致死性のヘビ毒を中和する新たな解決策を提供しました。この論文は2025年初頭にNature誌に掲載されました。これらの研究成果は、タンパク質設計分野におけるAIの大きな可能性を示し、「創造主」のような目標である「新しいタンパク質を設計する」という目標に向けて着実な一歩を踏み出しました。
複雑な生命システムのクロススケールコンピューティング:ナノスケールからマクロスケールまでのフルチェーンシミュレーション
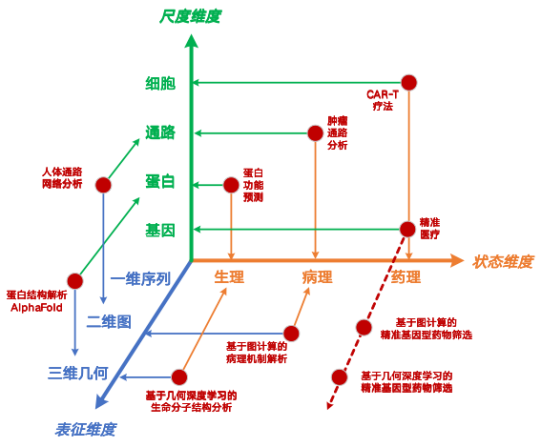
生命システムは複雑なマルチスケールシステムであり、ナノスケールの遺伝子レベルからマクロスケールの細胞レベルまで、各スケールが相互作用し、影響を与えています。英国マンチェスター大学の張恒貴教授の研究グループを訪問した際に、デジタル心臓に関する研究を行いました。中国に帰国後、デジタル細胞に関する研究をさらに進めました。デジタル心臓のような「数値駆動」パラダイムとは異なり、研究チームは、「データ駆動型」構築アプローチに基づく微視的生命活動のマルチスケールモデリング手法を提案し、「表現-状態-スケール」の3次元微視的計算手法システムを構築した。36の研究ポイントをカバーしており、現在、約3分の1の手法に関して論文や特許が蓄積されています。
さらに、魏志強教授の指導のもと、私たちは、ミクロな生命システムを4つのスケールレベルで新たに定義しました。ナノスケールの遺伝子レベル、ミクロレベルのタンパク質レベル、メソスケールのシグナル経路レベル、マクロレベルの細胞レベルを含め、完全な連鎖生命システムシミュレーションを実現し、原子から心臓までの本格的な結合を実現することを目指しています。
張樹剛准教授について
張樹剛氏は、中国海洋大学コンピュータサイエンス学院の准教授、修士課程の指導教員であり、中国情報科学センター(CCF)のシニアメンバー、CCFバイオインフォマティクス委員会の通信メンバー、中国中央研究院(CAAI)スマートヘルスケア委員会のメンバー、山東省バイオインフォマティクス学会の理事、中国国家自然科学基金、中央大学基礎科学研究事業費プロジェクトなどのディレクターを務めています。彼は2020年度山東省博士研究員イノベーション人材支援プログラムに選ばれました。
主な研究分野は計算生物学とバイオインフォマティクスで、超高精度デジタル心臓構築、タンパク質機能予測・設計などを行っています。近年では、IEEE JBHI、JCIM、npj Systems Biology and Applicationsなど、国際的に権威のあるジャーナルや会議に30以上の論文を発表し、Google Scholarでは1,600件以上の引用があります。








