Command Palette
Search for a command to run...
58,000以上の星!RAGFlowはQwen3 Embeddingを統合し、複雑な形式のデータを簡単に処理します。WebclickはWebページ理解の新たな次元を開きます。
Metaが2020年に提案したRAG(Retrieval-Augmented Generation:検索拡張生成)フレームワークは、LLM出力の精度と信頼性を効果的に向上させます。この技術は、当初の単純な検索+生成から、マルチラウンド推論、ツール利用、コンテキストメモリといったエージェント機能を備えた高度な形式へと進化しました。現在のRAGエンジンの多くは、文書解析が比較的単純で、市販の検索ミドルウェアに依存しているため、検索精度が低くなっています。
これを踏まえ、InfiniFlowは、深層文書理解に基づくオープンソースのRAGエンジンであるRAGFlowをオープンソース化しました。RAGFlowは上記の課題を解決するだけでなく、構築済みのRAGワークフローも提供します。ユーザーは、手順に従って手順を追うだけで、迅速にRAGシステムを構築できます。Qwen3 Embedding との統合後、ローカル ナレッジ ベース、インテリジェントな質問応答システム、エージェントをワンストップで構築できます。
現在、HyperAI公式サイトでは「RAGシステムの構築:Qwen3埋め込みに基づく実践」チュートリアルを公開していますので、ぜひお試しください。
RAGシステムの構築:Qwen3埋め込みに基づく実践
オンラインでの使用:https://go.hyper.ai/FFA7f
6月23日から6月27日まで、hyper.ai公式サイトが更新されます。
* 高品質の公開データセット: 10
*厳選された高品質なチュートリアル: 6
* 今週のおすすめ論文:5
* コミュニティ記事の解釈:3件
* 人気のある百科事典のエントリ: 5
* 7月に締め切りを迎えるトップカンファレンス:5
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
1. 世界動画データセット
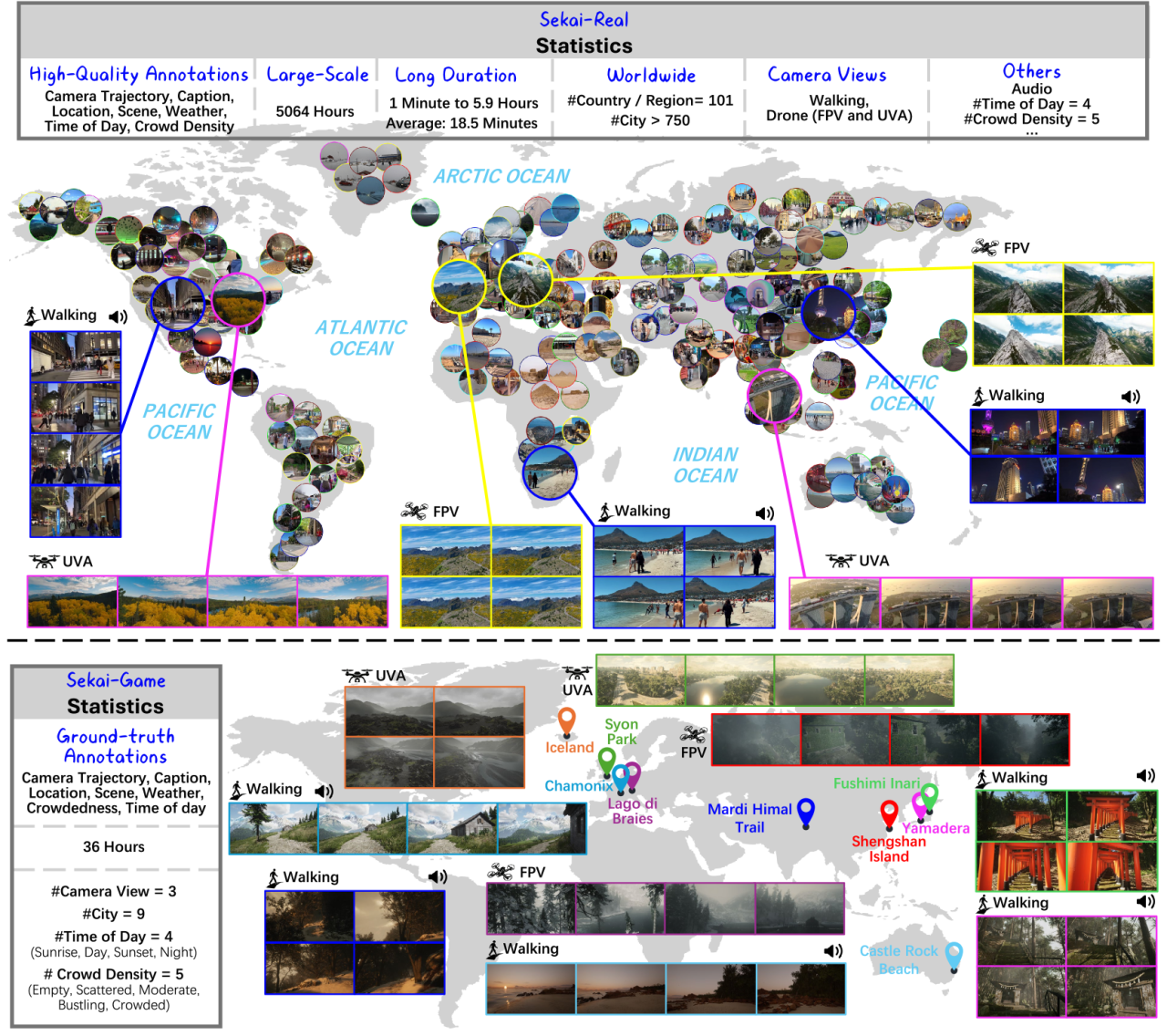
Sekaiは、動画生成や世界探索の分野における価値ある応用を刺激するために設計された、高品質な一人称視点のグローバル動画データセットです。このデータセットは、自己中心的な世界探索に焦点を当てており、「Sekai-Real」と「Sekai-Game」の2つの部分で構成されています。100以上の国と地域、750以上の都市から撮影された、5,000時間を超える徒歩またはドローン視点の動画が収録されています。
直接使用します:https://go.hyper.ai/YyBKB
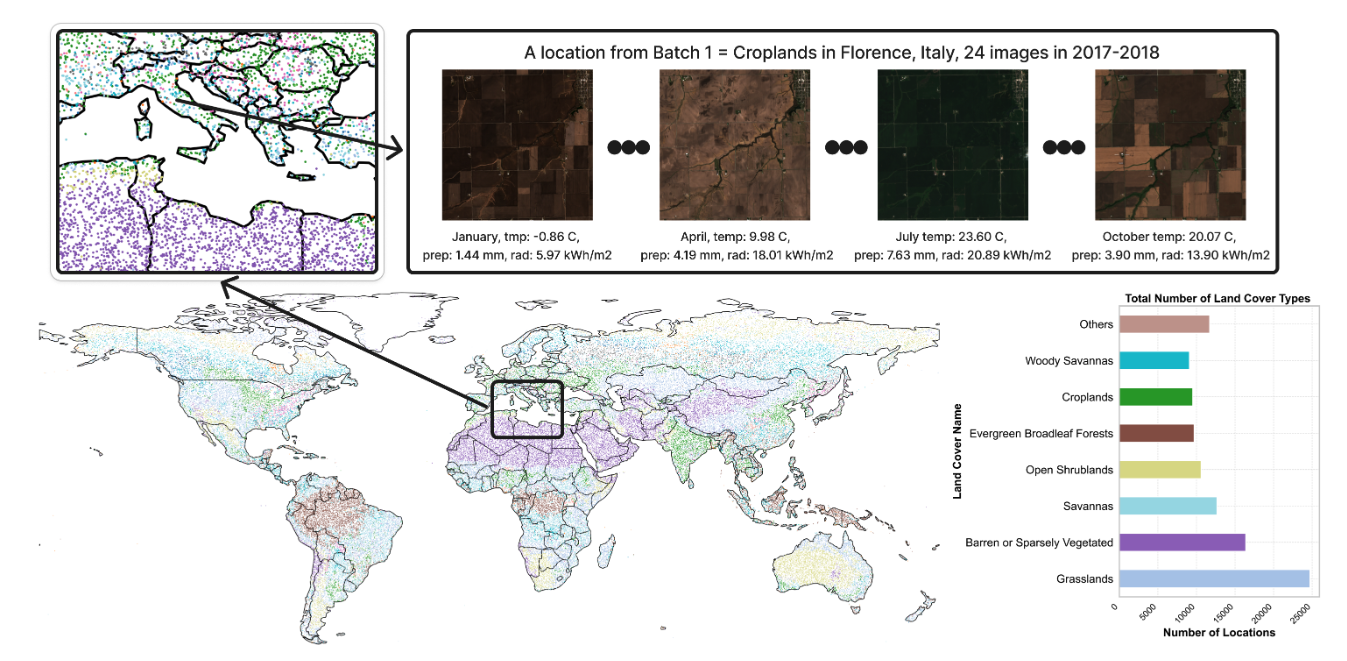
2. Ecomapper 衛星画像データセット
このデータセットには、RGB画像と特定のマルチスペクトルチャネルデータを含む290万枚以上の衛星画像が含まれています。これらの画像はコペルニクス・センチネル衛星ミッションから取得され、様々な土地被覆タイプと複数の時点をカバーしています。トレーニングセットには98,930の異なる地理的位置が含まれ、テストセットには5,494の位置が含まれています。各画像のタイムスタンプには、気温、日射量、降水量などの関連する気象メタデータが付与されています。
直接使用します:https://go.hyper.ai/1u8s6
3. NuScenes 自動運転データセット
NuScenes は、ボストンとシンガポールの 40,000 キーフレームに約 140 万枚のカメラ画像、390,000 枚の LIDAR スキャン画像、140 万枚のレーダー スキャン画像、140 万個のオブジェクト境界ボックスが含まれる自動運転用の公開データセットです。
直接使用します:https://go.hyper.ai/rgw1k
4. Tahoe-100M 単一細胞データセット
Tahoe-100Mは、世界最大の単一細胞データセットであり、介入理解機能を備えた大規模言語モデル(LLM)のための現実的で構造化された実験データ基盤を提供するために設計されています。このデータセットには1億個以上の細胞が含まれており、6万件以上の分子介入実験を網羅し、50種類のがんモデルに対する1,100種類以上の薬物治療への反応をマッピングしています。
直接使用します:https://go.hyper.ai/Hfzva
5. WebClick Webページ理解ベンチマークデータセット
WebClickは、マルチモーダルモデルとエージェントがWebインターフェースを理解し、ユーザーコマンドを解釈し、デジタル環境において正確なアクションを実行する能力を評価するための、高品質なWebページ理解ベンチマークデータセットです。このデータセットには、100以上のウェブサイトから1,639枚の英語Webページスクリーンショットが含まれており、正確にアノテーションされた自然言語コマンドとピクセルレベルのクリックターゲットが付与されています。
直接使用します:https://go.hyper.ai/ezz46
6. ディープリサーチベンチ ディープリサーチベンチ
DeepResearch Benchは、様々な分野における人間のディープリサーチニーズの真の分布を明らかにすることを目的とした、ディープリサーチエージェントのベンチマークデータセットです。このデータセットには、22の異なる分野の専門家によって綿密に作成された100個の博士課程レベルの研究課題が含まれています。
直接使用します:https://go.hyper.ai/yVHfH
7. SA-Text画像テキストデータセット
SA-Textは、テキスト認識画像復元タスク向けに設計された、高品質シーン画像の大規模ベンチマークデータセットです。このデータセットには、画像内のテキストの位置と形状を正確に記述するポリゴンレベルのテキスト注釈が付与された105,330枚の高解像度シーン画像が含まれており、モデルが画像内のテキストの位置と構造をより正確に理解することを可能にします。
直接使用します:https://go.hyper.ai/ICYIY
8. OCRBench テキスト認識ベンチマークデータセット
このデータセットには、テキスト認識、シーンのテキスト中心、ドキュメントの方向、キー情報、手書きの数式という 5 つの代表的なテキスト関連タスクから手動で選別され修正された 1,000 個の質問と回答のペアが含まれています。
直接使用します:https://go.hyper.ai/ZcKoD
9. Parse-PBMC単一細胞RNAシーケンシングデータセット
Parse-PBMC は、1 回の実験で 1,152 のサンプルから 1,000 万個の細胞を分析するオープンソースの単一細胞 RNA シーケンス データセットであり、主にさまざまな条件下でのヒト末梢血単核細胞の遺伝子発現特性を研究するために使用されます。
直接使用します:https://go.hyper.ai/CwOMc
10. VIRESET ビデオインスタンス編集データセット
VIRESETは、動画インスタンスの再描画や時間的セグメンテーションといったタスクにおいて、正確なアノテーション支援を提供することを目的としています。データセットには、SA-V拡張マスクアノテーションと86,000本の動画クリップの2つのコンテンツが含まれています。
直接使用します:https://go.hyper.ai/5hnGF
選択された公開チュートリアル
今週は、2種類の高品質な公開チュートリアルをまとめました。
*大規模モデル展開チュートリアル: 3
*ビデオ生成チュートリアル: 3
大規模モデルの展開チュートリアル
1. RAGシステムの構築:Qwen3埋め込みに基づく実践
RAGFlowは、深い文書理解に基づくオープンソースのRAG(Retrieval Augmented Generation)エンジンです。LLMと統合することで、様々な複雑な形式のデータから信頼性の高い参照情報を取得し、真の質問応答機能を提供できます。
オンラインで実行:https://go.hyper.ai/FFA7f
2. vLLM+Open WebUIを使用してQwenLong-L1-32Bをデプロイする
QwenLong-L1-32Bは、強化学習に基づく長文推論のための初の大規模モデルです。従来の大規模モデルが超長文コンテキスト(例えば12万トークン)を処理する際に直面するメモリ不足や論理的混乱の問題を解決することに重点を置いています。従来の大規模モデルのコンテキスト制約を打破し、金融や法律といった高精度なシナリオ向けに、低コストで高性能なソリューションを提供します。
オンラインで実行:https://go.hyper.ai/f73C2
3. vLLM+Open WebUI の展開 Magistral-Small-2506
Magistral-Small-2506は、Mistral Small 3.1 (2503)をベースに構築され、推論能力の向上、Magistral MediumによるSFTトラッキング、そして強化学習を搭載しています。24Bのパラメータを持つ小型で効率的な推論モデルであり、長鎖推論トラッキングによる解答生成が可能で、複雑な問題をより深く理解し、対処することで、解答の精度と合理性を向上させます。
オンラインで実行:https://go.hyper.ai/yLeoh
ビデオ生成チュートリアル
1. MAGI-1: 世界初の大規模自己回帰ビデオ生成モデル
Magi-1は、連続するフレームの固定長セグメントとして定義される一連のビデオブロックを自己回帰予測することでビデオを生成する、世界初の大規模自己回帰ビデオ生成モデルです。テキスト指示に基づく画像からビデオへの変換タスクにおいて優れたパフォーマンスを発揮し、高い時間的一貫性とスケーラビリティを提供します。
オンラインで実行:https://go.hyper.ai/NZ6cc
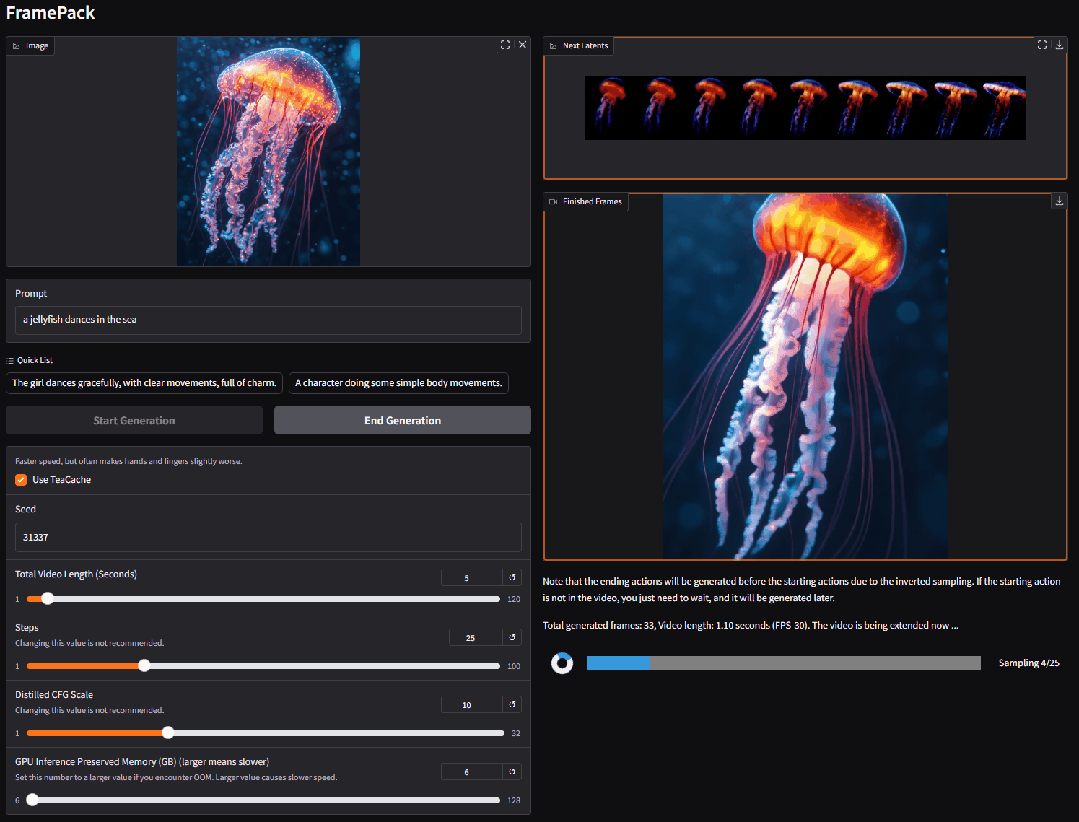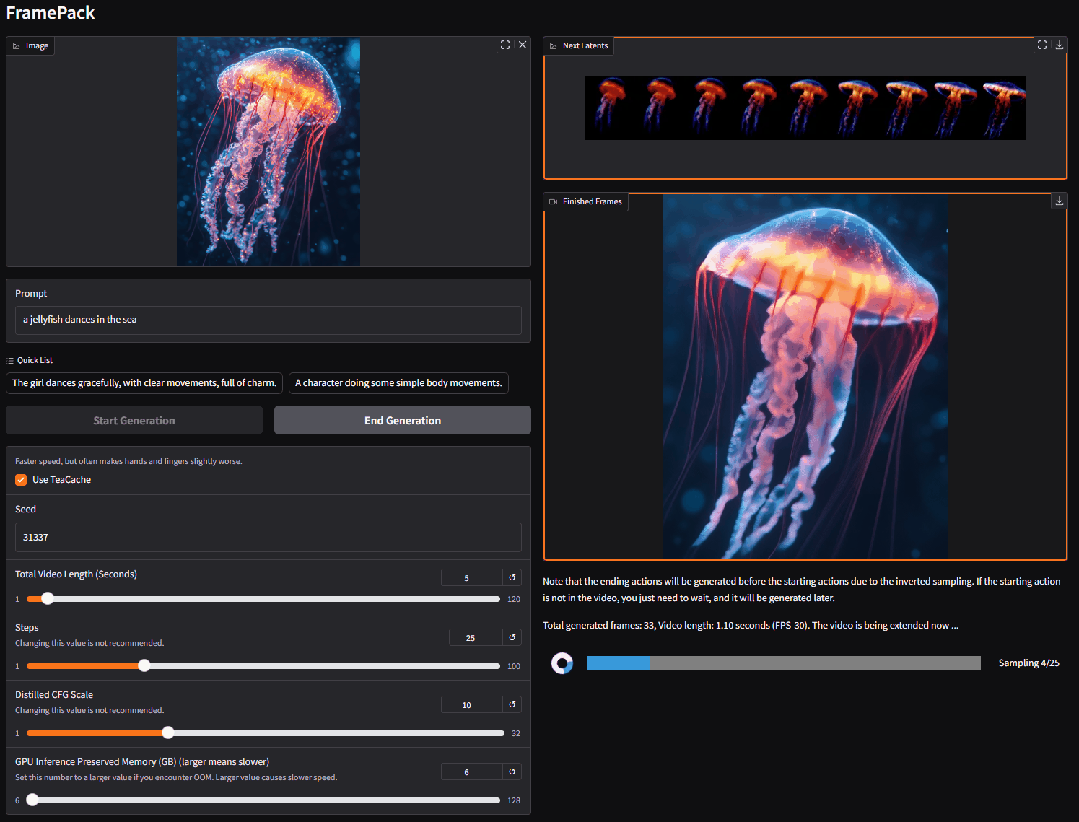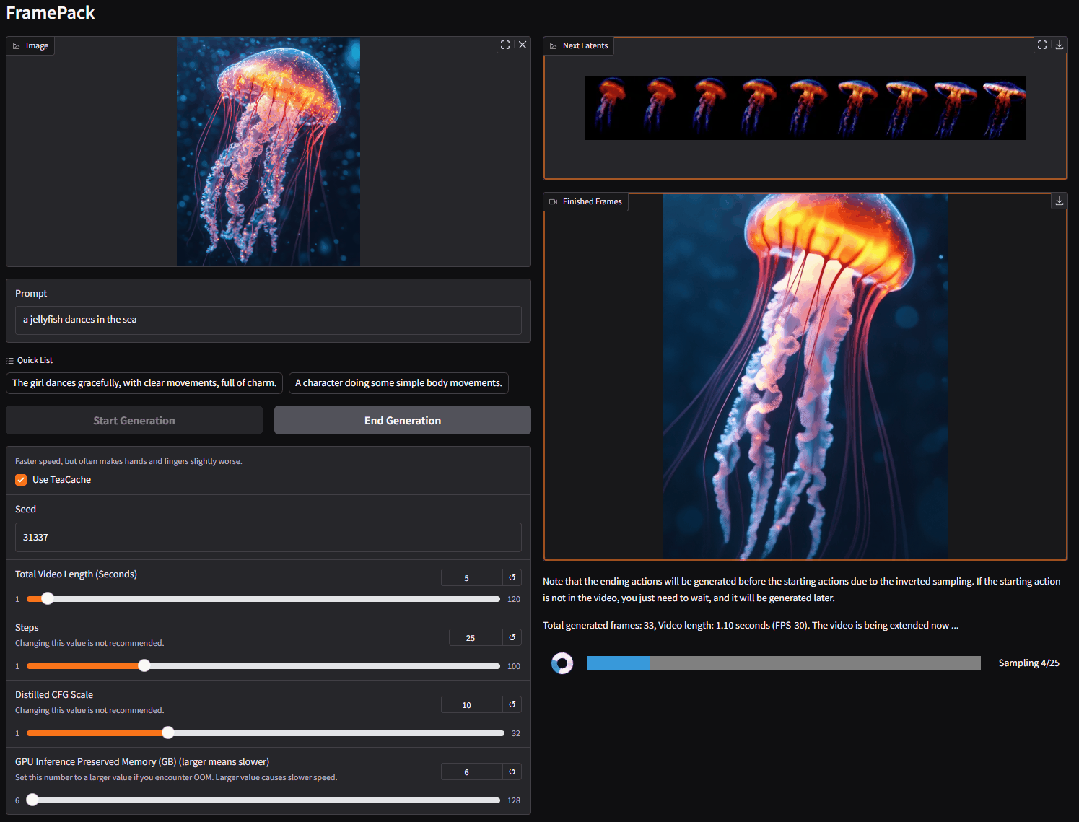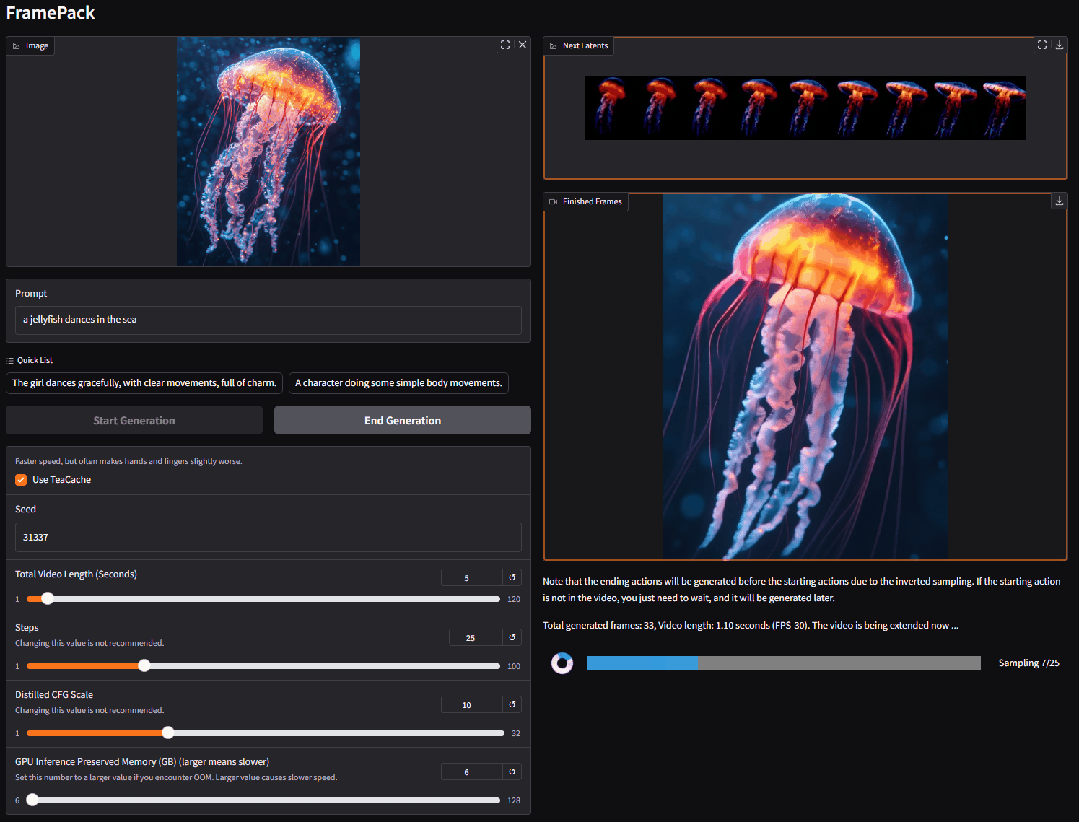
2. FramePackLoop: オープンソースのシームレスループビデオ生成ツール
FramePackLoopは、ビデオ制作ワークフローを簡素化するために設計された、フレームシーケンス処理およびループ生成の自動化ツールです。このツールは、モジュール型アーキテクチャを採用し、フレームシーケンスのパッキング、時間的アライメント、そしてシームレスなループ合成を実現します。具体的には、オプティカルフロー推定とアテンションベースの時間的モデリングを組み合わせることで、フレーム間の動きの一貫性を維持します。
オンラインで実行:https://go.hyper.ai/WIRoM
3. VIRES: スケッチとテキストのデュアルガイドによるビデオ再描画
VIRESは、スケッチとテキストガイダンスを組み合わせた動画インスタンスの再描画手法であり、動画の主題の再描画、置換、生成、削除といった複数の編集操作をサポートします。この手法は、テキスト生成動画モデルの事前知識を用いて、時間的な一貫性を確保します。実験結果では、VIRESは動画品質、時間的な一貫性、条件付きアライメント、ユーザー評価など、多くの側面で優れた性能を発揮することが示されています。
オンラインで実行:https://go.hyper.ai/GeZxZ

💡安定拡散チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] にメモし、グループに参加してさまざまな技術的な問題について話し合い、アプリケーションの効果を共有してください。

今週のおすすめ紙
1. ドラッグアンドドロップLLM:ゼロショットプロンプトウェイト
本論文では、ドラッグ&ドロップ方式の大規模言語モデル(DnD)を紹介します。これは、少数のラベルなしタスクプロンプトをLoRA重み更新に直接マッピングすることで、タスクごとの学習を不要にするプロンプトベースのパラメータ生成器です。軽量テキストエンコーダーが各プロンプトバッチを条件付き埋め込みに精製し、その後、カスケード型ハイパー畳み込みデコーダーによってLoRA行列の完全なセットに変換されます。
論文リンク:https://go.hyper.ai/hAO8y
2. 法線の光:ユニバーサル照度差ステレオ法のための統一的な特徴表現
本稿では、任意の照明条件下で高精度な表面法線を復元する問題を解決する、新たなユニバーサルフォトメトリックステレオ(UniPS)手法を提案する。実験結果では、LINO-UniPSが既存の最先端のユニバーサルフォトメトリックステレオ手法を公開ベンチマークで上回り、異なる材質特性や照明シナリオに対応できる強力な汎化能力を示すことが示された。
論文リンク:https://go.hyper.ai/oTFMo
3. 視覚誘導によるチャンキングこそが全て:マルチモーダル文書理解によるRAGの強化
本論文では、大規模マルチモーダルモデル(LMM)を活用し、意味的一貫性と構造的整合性を維持しながらPDF文書をバッチ処理する、新しいマルチモーダル文書チャンキング手法を提案する。この手法は、設定可能なページバッチ単位で文書を処理し、バッチ間で文脈情報を保持するため、複数ページにまたがる表、埋め込まれた視覚要素、手続き型コンテンツを正確に処理することができる。
論文リンク:https://go.hyper.ai/IZA15
4. OmniGen2: 高度なマルチモーダル生成への探求
本稿では、テキストから画像への生成、画像編集、コンテキスト生成など、複数の生成タスクに対する統合ソリューションを提供することを目的とした、汎用性の高いオープンソース生成モデルであるOmniGen2を紹介します。OmniGen v1とは異なり、OmniGen2はテキストと画像のモダリティに対して、非共有パラメータと個別の画像トークナイザーを用いて、独立した2つのデコードパスを設計しています。この設計により、OmniGen2はVAE入力を再適応させることなく既存のマルチモーダル理解モデルを基盤とすることができ、元のテキスト生成機能を維持できます。
論文リンク:https://go.hyper.ai/iCFzp
5. PAROAttention: 視覚生成モデルにおける効率的なスパースおよび量子化アテンションのためのパターンを考慮した並べ替え
本論文では、多様なアテンションパターンをハードウェアフレンドリーなブロックパターンに統合する、新しいパターン認識タグ並べ替え(PARO)手法を提案する。この統合により、スパース化と量子化の効果が大幅に簡素化され、強化される。この手法により、PARO Attentionはメトリクスの損失をほぼゼロに抑えながら動画・画像生成を実現し、密度とビット幅を大幅に削減しながらもフル精度ベースラインとほぼ同等の結果を達成し、エンドツーエンドのレイテンシを1.9~2.7倍高速化する。
ペーパーリンク:https://go.hyper.ai/sScNH
AIフロンティアに関するその他の論文:https://go.hyper.ai/iSYSZ
コミュニティ記事の解釈
1. DeepMindは、あらゆるモダリティと細胞の種類における突然変異の影響を1秒以内に予測するAlphaGenomeをリリースしました。
Google DeepMindは、数千もの分子特性をその調節活性に関連づけて予測できるAlphaGenomeモデルをリリースしました。また、変異体配列と非変異体配列の予測結果を比較することで、遺伝子変異や突然変異の影響を評価することもできます。AlphaGenomeの重要なブレークスルーの一つは、配列から直接スプライシングジャンクションを予測し、変異の影響予測に活用できることです。
レポート全体を表示します。https://go.hyper.ai/o8E1F
2. 心臓モデル全体からLLMベースの疾患ネットワーク分析まで、清華長庚病院のLi Dong氏はデータの観点から医療ビッグモデルの発展動向を分析した。
清華長庚病院医療データサイエンスセンター長の李東教授は、2025年北京知源会議において「スマートヘルスケア時代に医療データをどのように活用して革新的な研究を行うか」と題した特別講演を行い、スマートヘルスケア時代のビッグモデルがもたらすイノベーションを紹介した。
レポート全体を表示します。https://go.hyper.ai/rAabv
3. Evo 2に続いて、アーク研究所は70種類の異なる細胞株を含むトレーニングデータを備えた最初の仮想細胞モデルSTATEをリリースしました。
非営利研究機関であるアーク研究所は、カリフォルニア大学バークレー校、スタンフォード大学などの研究チームと共同で、幹細胞、がん細胞、免疫細胞が薬剤、サイトカイン、または遺伝子介入に対してどのように反応するかを予測できる仮想細胞モデル「STATE」を発表しました。実験結果によると、STATEは介入後のトランスクリプトーム変化の予測において、現在の主流手法を大幅に上回る性能を示しました。
レポート全体を表示します。https://go.hyper.ai/B3Rc6
人気のある百科事典の項目を厳選
1. DALL-E
2. 相互ソート融合RRF
3. パレートフロント
4. 大規模マルチタスク言語理解MMLU
5. 対照学習
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。
サミットの締め切りは7月
7月2日 7:59:59 2026年
7月11日 7:59:59 ポピュラリティ 2026
7月15日 7:59:59 ソーダ2026
7月18日 7:59:59 シグモッド 2026
7月19日 7:59:59 ICSE2026
主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!








