Command Palette
Search for a command to run...
環境設定から大規模モデルの展開まで、vLLM実践チュートリアルの概要、主要な更新を追跡する中国語ドキュメント

大規模言語モデル (LLM) が徐々にエンジニアリングと大規模展開へと進むにつれて、その推論効率、リソース利用率、ハードウェア適応性がアプリケーションの実装に影響を与える中核的な問題になりつつあります。 2023年、カリフォルニア大学バークレー校の研究チームがvLLMをオープンソース化しました。vLLMは、KVキャッシュを効率的に管理するPagedAttentionメカニズムを導入し、モデルのスループットと応答速度を大幅に向上させ、オープンソースコミュニティで急速に人気を博しました。現在、vLLM は GitHub で 46,000 スターを超えており、大規模モデル推論フレームワークのスター プロジェクトとなっています。
2025年1月27日vLLMチームがv1アルファ版をリリースしました。コア アーキテクチャは、過去 2 年間の開発作業に基づいて体系的に再構築されました。この更新バージョン v1 の中核は、実行アーキテクチャの包括的な再構築です。分離された EngineCore は、モデル実行ロジックに重点を置き、マルチプロセスのディープ統合を採用し、ZeroMQ を通じて CPU タスクの並列化とマルチプロセスのディープ統合を実現し、API レイヤーを推論コアから明示的に分離するために導入され、システムの安定性が大幅に向上します。
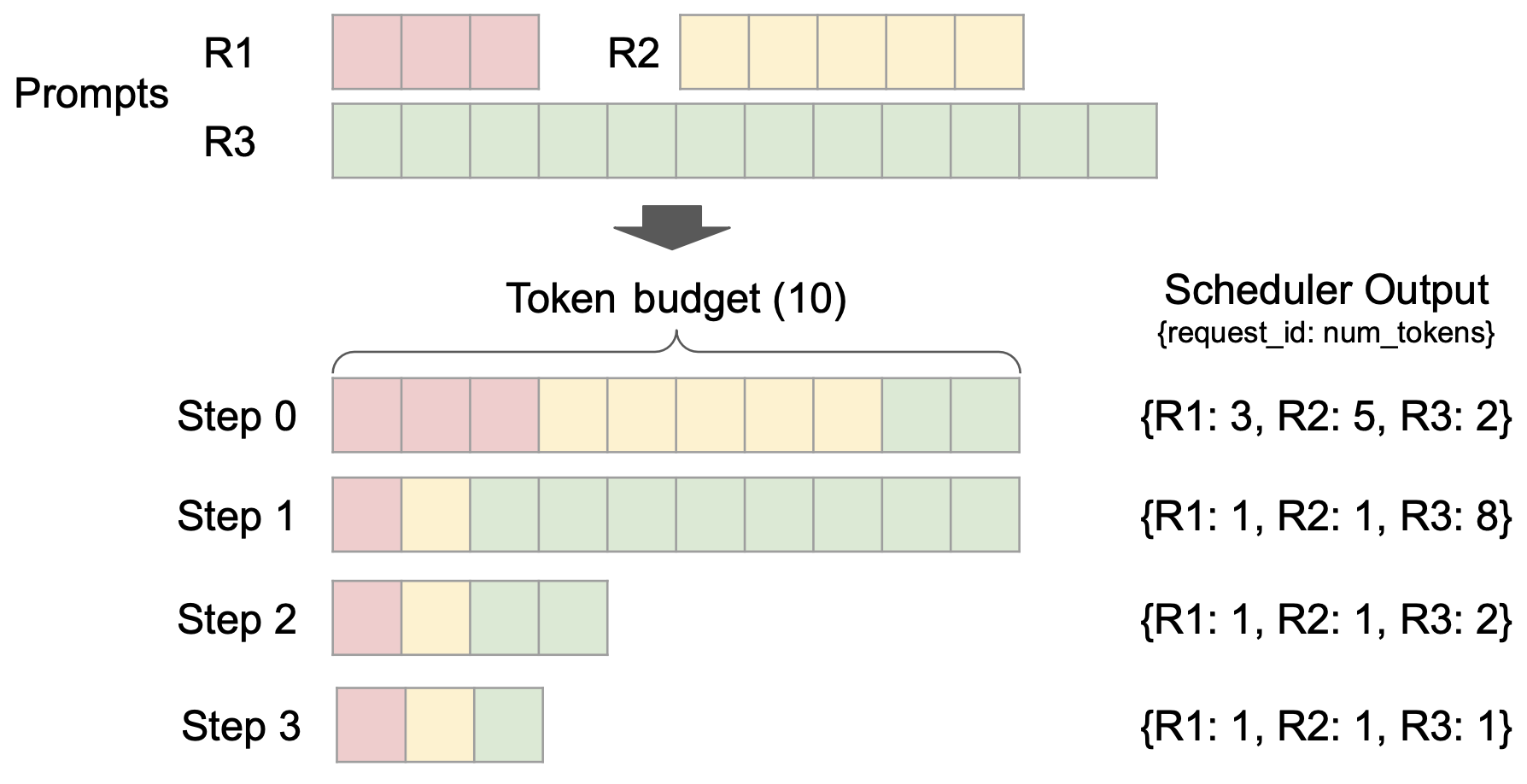
同時に、きめ細かなスケジュールの粒度、投機的デコードのサポート、チャンク化されたプリフィルなどの機能を備えた統合スケジューラが導入されました。高いスループットを維持しながら、レイテンシ制御機能を向上させます。
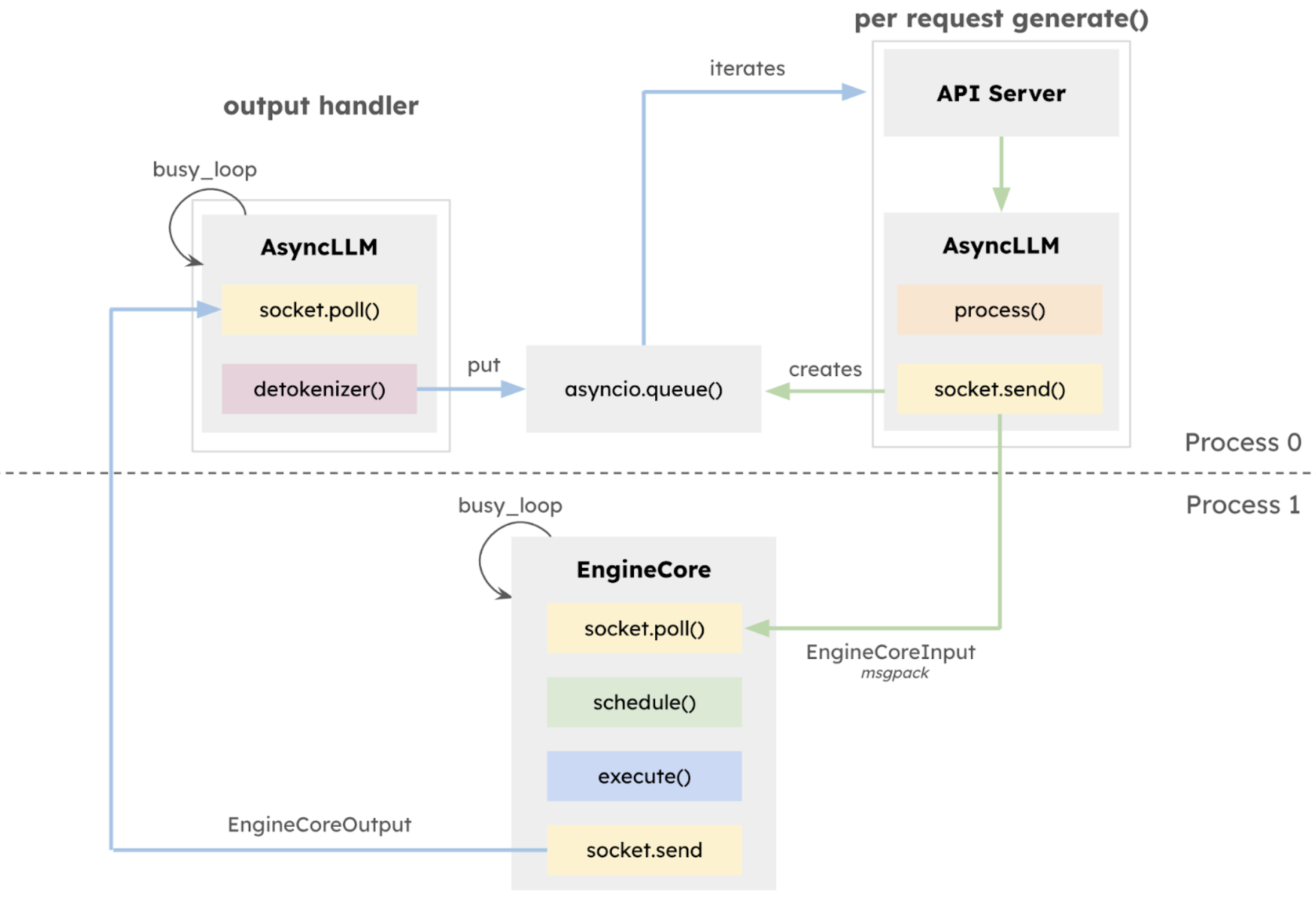
また、vLLM v1 は、画期的なステージフリー スケジューリング設計を採用しています。ユーザー入力とモデル出力トークンの処理が最適化され、スケジュール ロジックが簡素化されました。スケジューラは、チャンク化されたプリフィルとプレフィックス キャッシングをサポートするだけでなく、投機的なデコードも実行できるため、推論効率が効果的に向上します。
キャッシュ メカニズムの最適化ももう一つのハイライトです。 vLLM v1 は、ゼロオーバーヘッドのプレフィックス キャッシングを実装します。キャッシュヒット率が極めて低い長いテキスト推論シナリオでも、繰り返し計算を効果的に回避し、推論の一貫性と効率性を向上させることができます。
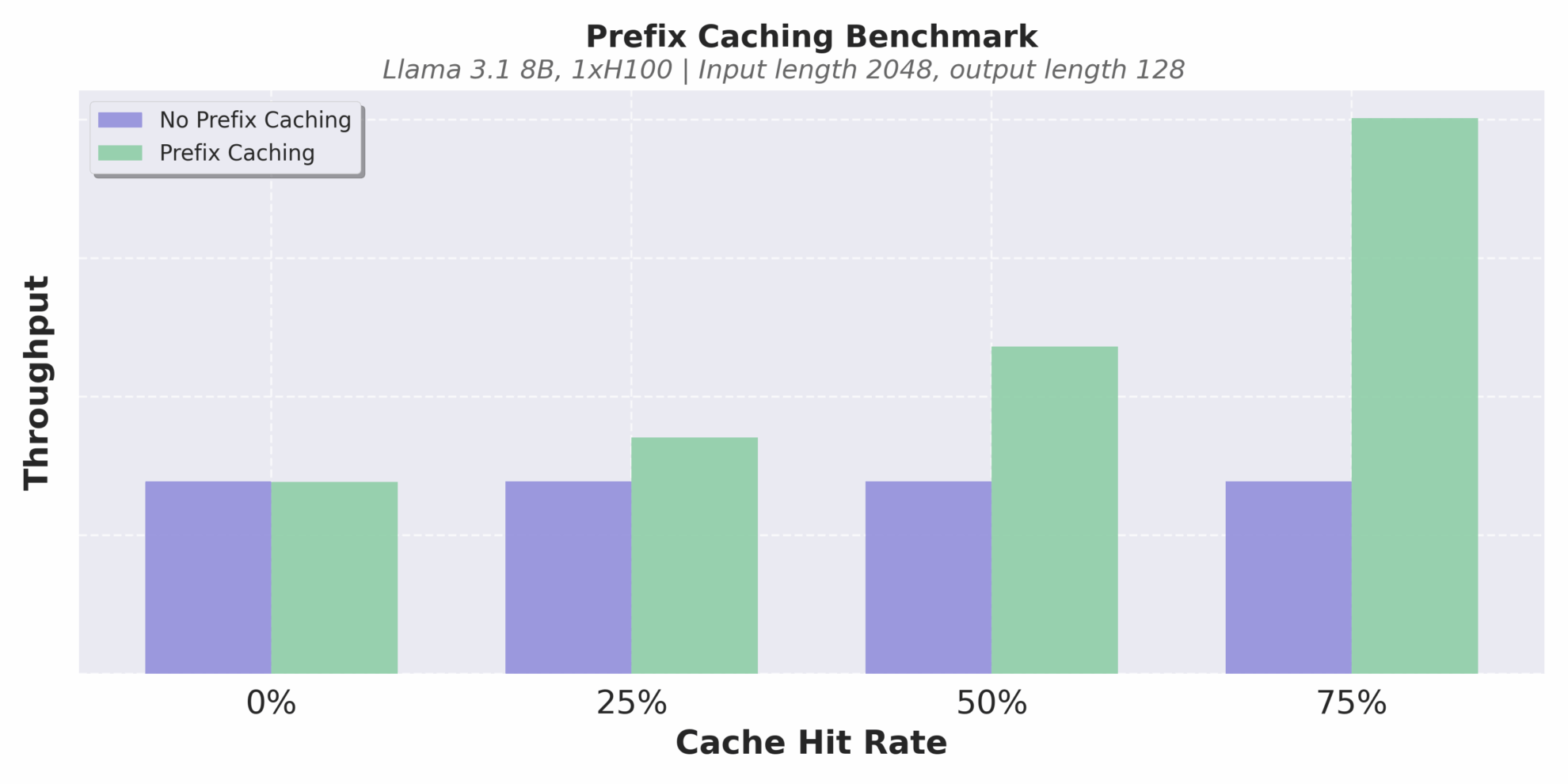
異なるキャッシュヒット率でのスループット
下の図からわかるように、vLLM v1 のスループットは v0 と比較して最大 1.7 倍に増加し、特に高 QPS の場合にパフォーマンスの向上がより顕著になります。 vLLM v1 はアルファ版であるため、まだ開発が活発に行われており、安定性と互換性の問題がある可能性がありますが、そのアーキテクチャの進化の方向性は、高性能、高保守性、高モジュール性を明確に示しており、後続のチームが新しい機能を迅速に開発するための強固な基盤を築いています。
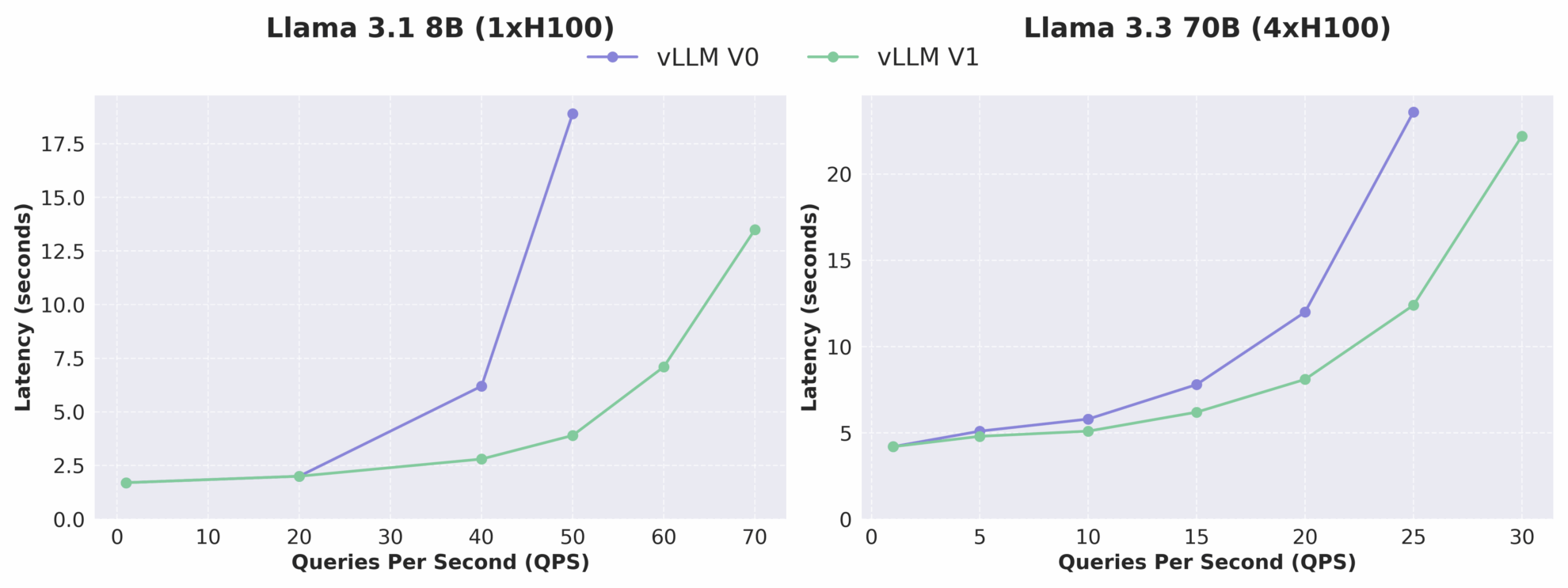
vLLM V0とV1のレイテンシとQPSの関係の比較
先月、vLLM チームは、モデルの互換性と推論の安定性の向上に重点を置いたマイナー バージョン アップデートも実行しました。この更新された vLLM v0.8.5 バージョンでは、Qwen3 および Qwen3MoE モデルの初日からのサポートが導入され、融合された FP8_W8A8 MoE カーネル構成が追加され、マルチモーダル シナリオの重大なバグが修正され、実稼働環境でのパフォーマンスの堅牢性がさらに強化されています。
vLLM をより効率的に使い始められるように、エディターは、基本的なインストールから推論の展開までのプロセス全体を網羅した、一連の実用的なチュートリアルとモデル ケースをまとめました。誰もがすぐに始められ、深い理解が得られるように支援します。興味のある方はぜひ体験しに来てください!
その他の vLLM 中国語ドキュメントとチュートリアルは以下から参照できます。
基本チュートリアル
1 . vLLM の使用を開始する: ステップバイステップ ガイド
* オンライン操作:https://go.hyper.ai/Jy22B
このチュートリアルでは、vLLM を設定して実行する方法を段階的に説明し、vLLM のインストール、モデル推論、vLLM サーバーの起動、リクエストの作成方法に関する完全な入門ガイドを提供します。
2 . vLLM を使って Qwen2.5 を推論する
* オンライン操作:https://go.hyper.ai/SwVEa
このチュートリアルでは、モデルの読み込み、データの準備、推論プロセスの最適化、結果の抽出と評価など、3B のパラメータを持つ大規模言語モデルで推論タスクを実行する方法を詳細に説明します。
3 . vLLM を使用した大規模モデルのロード , 少数ショット学習を実行する
* オンライン操作:https://go.hyper.ai/OmVjM
このチュートリアルでは、vLLM を使用して、少数ショット学習用の Qwen2.5-3B-Instruct-AWQ モデルを読み込みます。トレーニング データを取得して類似の質問を取得し、対話を構築する方法、モデルを使用してさまざまな出力を生成する方法、誤解を推測し、関連する方法を組み合わせて統合ランキングを作成する方法など、データの準備から結果の送信までの完全なプロセスを実現する方法について詳しく説明します。
4 . LangChainとvLLMを組み合わせる , チュートリアル
* オンライン操作:https://go.hyper.ai/Y1EbK
このチュートリアルでは、LangChain を vLLM で使用することに焦点を当て、基本設定から高度な機能アプリケーションまで幅広い内容を網羅し、スマート LLM アプリケーション開発の簡素化と高速化を目指します。
大規模モデルの展開
1 . vLLMを使用してQwen3-30B-A3Bをデプロイする
※発行機関:アリババ・クウェンチーム
* オンライン操作:https://go.hyper.ai/6Ttdh
Qwen3-235B-A22Bは、コード、数学、一般機能などのベンチマークテストにおいて、DeepSeek-R1、o1、o3-mini、Grok-3、Gemini-2.5-Proと同等の機能を示しました。注目すべきは、Qwen3-30B-A3B の有効化パラメータの数は QwQ-32B の 10% に過ぎないが、パフォーマンスはより優れているということである。 Qwen3-4B のような小型モデルでも、Qwen2.5-72B-Instruct のパフォーマンスに匹敵します。
2 . vLLMを使用してGLM-4-32Bを展開する
※発行機関:Zhipu AI、清華大学
* オンライン操作:https://go.hyper.ai/HJqqO
GLM-4-32B-0414 は、コード エンジニアリング、成果物生成、関数呼び出し、検索ベースの質問回答、レポート生成において優れた結果を達成しました。特に、コード生成や特定の質問応答タスクなどのいくつかのベンチマークでは、GLM-4-32B-Base-0414 は、GPT-4o や DeepSeek-V3-0324 (671B) などの大規模モデルに匹敵するパフォーマンスを実現します。
3 . vLLMを使用したデプロイメント , DeepCoder-14B-プレビュー
※発行機関:Agenticaチーム、Together AI
* オンライン操作:https://go.hyper.ai/sYwfO
このモデルは、DeepSeek-R1-Distilled-Qwen-14B に基づいており、分布強化学習 (RL) によって微調整されています。 140億のパラメータを持ち、LiveCodeBench v5テストで60.6%のPass@1精度を達成しました。これはOpenAIのo3-miniに匹敵します。
4 . vLLMを使用したデプロイメント , ジェマ-3-27B-IT
※発行機関:MetaGPTチーム
* オンライン操作:https://go.hyper.ai/0rZ7j
Gemma 3 は、テキストと画像の入力を処理し、テキスト出力を生成できる大規模なマルチモーダル モデルです。事前トレーニング済みバリアントと命令調整済みバリアントの両方が、質問への回答、要約、推論など、さまざまなテキスト生成および画像理解タスクに対してオープンな重みを提供します。比較的小型なので、リソースが限られた環境でも導入できます。このチュートリアルでは、モデル推論のデモンストレーションとして gemma-3-27b-it を使用します。
その他のアプリケーション
1 .オープンマナス + QwQ-32B , AIエージェントの実装
※発行機関:MetaGPTチーム
* オンライン操作:https://go.hyper.ai/RqNME
OpenManus は、2025 年 3 月に MetaGPT チームによって開始されたオープンソース プロジェクトです。Manus のコア機能を複製し、招待コードなしでローカルに展開できるインテリジェント エージェント ソリューションをユーザーに提供することを目的としています。 QwQ は Qwen シリーズの推論モデルです。従来の命令チューニング モデルと比較して、QwQ は思考および推論機能を備えており、下流のタスク、特に難しい問題において大幅なパフォーマンスの向上を実現できます。このチュートリアルでは、QwQ-32B モデルと gpt-4o に基づいた OpenManus の推論サービスを提供します。
2 .RolmOCR クロスシナリオ超高速OCR , 新しいオープンソース識別ベンチマーク
※発行機関:レダクトAI
* オンライン操作:https://go.hyper.ai/U3HRH
RolmOCR は、Qwen2.5-VL-7B ビジュアル言語モデルに基づいて開発されたオープンソースの OCR ツールです。メモリ使用量を抑えながら、画像や PDF からテキストをすばやく抽出できるため、olmOCR などの同様のツールよりも優れています。 RolmOCR は PDF メタデータに依存せず、プロセスを合理化し、手書きのメモや学術論文など、さまざまな種類のドキュメントをサポートします。
上記は編集者が作成したvLLM関連のチュートリアルです。ご興味がございましたら、ぜひご体験ください!
国内ユーザーがvLLMをよりよく理解し、適用できるようにするために、HyperAI コミュニティのボランティアが協力して、最初の vLLM 中国語ドキュメントを完成させました。このドキュメントは現在、hyper.ai で完全に公開されています。コンテンツには、モデルの原則、デプロイメントチュートリアル、バージョンの解釈が含まれ、中国の開発者に体系的な学習パスと実用的なリソースが提供されます。
その他の vLLM 中国語ドキュメントとチュートリアルは以下から参照できます。https://vllm.hyper.ai








