Command Palette
Search for a command to run...
SAMシリーズモデルをはるかに上回る性能を実現。チューリッヒ大学らは、汎用的な3D血管セグメンテーション基本モデルを開発し、CVPR2025に選定された。
人体を巨大な都市に例えるなら、血管はまさにその都市の「道路」です。動脈、静脈、毛細血管は、高速道路、市街地道路、田舎道に相当します。これらは連携して血液を通じて栄養素や酸素などを体の各部に運び、この「都市」の効率的かつ安定した運営を保っています。そして、これらの道路に問題が生じると、当然人々の身体は病気になります。
血管のセグメンテーションは、これらの「道路」に問題があるかどうかを確認するための重要な手段です。都市建設における交通画像から問題を発見するのと同様に、これは医療画像処理における重要なタスクです。血管セグメンテーションは、医用画像から血管の構造を正確に識別して抽出することができます。さまざまな血管疾患の分析、診断、治療に応用できます。たとえば、心血管疾患では、冠動脈のセグメンテーションにより、医師は血管の狭窄の程度を評価し、患者に適切な治療計画を立てることができます。
近年、コンピューターと医療用画像技術の助けにより、血管のセグメンテーションは大きく進歩しました。しかし、特に 3D 血管セグメンテーションにおいて、タスク固有のイメージングに直面すると、完全に接続された血管を正確かつ堅牢にセグメンテーションすることは依然として困難な問題です。一方では、血管自体の限界によるものです。血管の複雑かつ微細な幾何学的形状により、セグメンテーションの難しさが急激に増大します。一方、イメージング方法とプロトコルの制限、特定の信号対雑音比、血管パターン、イメージングアーティファクト、背景組織の変化によって引き起こされる重大なドメインギャップが存在します。
3D医用画像ではSAM(Segment Anything Model)やSAM-Med3D、VISTA3Dなど、基本モデルに基づいた医用画像セグメンテーション手法が数多く存在しますが、ただし、これらのモデルでは、血管のセグメンテーションのタスクにおいて依然として限界があります。そのため、3D 血管セグメンテーションは医療スタッフや研究者にとって依然として労働集約的な作業であり、正確な血管画像分析をさらに実現するには、広範囲にわたるボクセルレベルの手動注釈が必要です。
この問題を解決するために、チューリッヒ大学、チューリッヒ工科大学、ミュンヘン工科大学のチームが、3D 血管セグメンテーション専用に設計された基本モデル vesselFM を提案しました。このモデルは、大規模なデータセット (Dreal) と、ドメインランダム化 (Ddrand) およびフローマッチングベースの生成モデル (Dflow) によって生成された合成データでトレーニングされます。ゼロショット、シングルショット、および少数ショットのシナリオにおいて、既存の高度なモデルよりも優れたセグメンテーションおよび一般化機能を実現できます。
関連研究は「vesselFM: ユニバーサル 3D 血管セグメンテーションの基礎モデル」というタイトルで公開され、CVPR 2025 に選出されました。
研究のハイライト:
この研究では、ゼロショットと一般化機能を備えた3D血管セグメンテーションの汎用ベースモデルを提案しており、研究者や医療スタッフが「すぐに」使用できる。
* チームは、慎重に処理された実際の3D血管画像と一致するボクセルレベルの注釈を含む、最大の3D血管セグメンテーションデータセットをキュレートしました。
* この研究では、3D 血管セグメンテーションのためのきめ細かな近傍ランダム化戦略を提案し、3D 医用画像生成にフロー マッチングを導入しています。

用紙のアドレス:
https://go.hyper.ai/lVad9
データセット: 3つの異種データソース
研究者たちは、これをトレーニングするために 3 つの異種データ ソースを使用しました。1 つ目は、さまざまな実際のデータを含むデータセット Dreal (Diverse Real Data) です。 2つ目は2つの合成データソースです。これらは、ドメインランダムデータセット Ddrand (Domain Randomization) と、フローマッチングベースの生成モデル Dflow (Flow Matching-Based) から収集されたデータです。
で、Dreal は、現在までに 3D 血管セグメンテーション タスクで使用された最大の実際のデータセットです。さまざまな生物のさまざまな解剖学的領域をカバーする幅広い画像診断法17 の注釈ソースからの 128³ 形状の 115,000 を超える 3D パッチが含まれています。具体的には、MRA、CTA、X線、二光子顕微鏡法、vEMなどの広範な臨床画像診断技術を採用しており、生体サンプルは人間や実験用マウスの脳、腎臓、肝臓から採取され、研究用にさまざまな構造的・機能的特性を持つ血管パターンを提供しています。下の図の通りです。
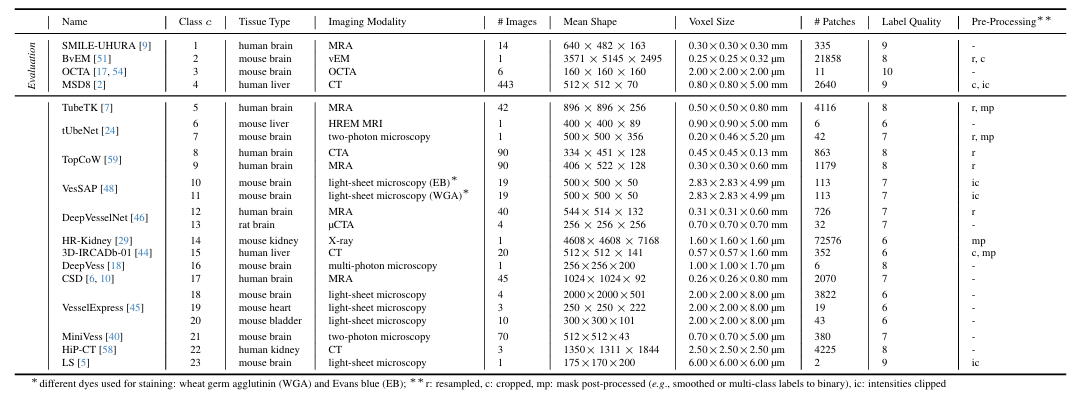
その後、研究者らはさまざまなタイプの組織、画像化方法、プロトコルを検討しました。Dreal はさらに 23 のデータ セットに分割されます。各データセットは前処理され、最終的に 128³ のターゲット シェイプを持つパッチが画像とそれに対応するラベルから抽出されます。
研究者らは、下の図に示すように、Ddrand を作成するためにドメインランダム化戦略を導入しました。この方法では、一連の空間変換と人工アーティファクトを実際の血管データに適用することで、多数の多様な合成画像マスク ペアを生成し、実際のデータに対するモデルの堅牢性を向上させます。具体的には、前景生成、背景生成、背景融合の 3 つのステップに分けられます。
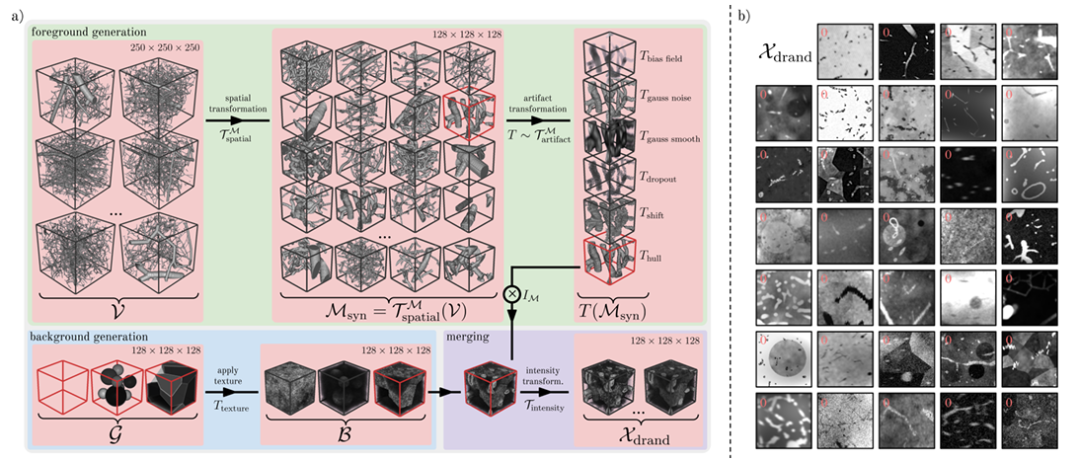
見込み客創出フェーズでは、研究者らは、Wittmann らが提供した 250³ の形状の血管パッチ v を 1,137 個使用しました。合成マスクのベースとして。これらの血管プラークは、高い忠実度で腐食鋳型のグラフィック表現から生成されます。
研究者が採用している主なアプローチは、ランダムクロッピング、反転、拡張とスケーリング、ランダム弾性変形、バイナリスムージングなどの空間変換を通じて、さまざまなリアルな血管パターンを生成することです。次に、研究者らは、バイアス フィールド、ガウス ノイズ、ガウス スムージング、ドロップアウト、オフセット、ぼかしなどのアーティファクト変換を選択して、実際の血管画像に存在するさまざまな前景アーティファクトをシミュレートしました。
背景生成フェーズでは、研究者たちは、さまざまなテクスチャを持つさまざまな背景形状を含む背景画像をモデル化しました。主なバリエーションは 3 つあります: 球 (重なり合わない球)、多面体 (ボロノイを使用して画像が複数の多面体領域に分割されます)、および背景のない幾何学画像です。
背景融合段階では、研究者たちは、ボクセルの加算と減算、または背景の強度値をマスクの強度値に置き換えることで、前景を背景に融合しました。画像領域を拡大するために、研究者らはランダムバイアスフィールドによって画像を継続的に強化し、ガウスノイズを追加し、k空間にランダムローカルピークを適用し、画像コントラストをランダムに調整し、すべての空間次元の個別または共有σ値に対してガウス平滑化を実行し、ライスノイズとギブスノイズを追加し、ランダムガウスシャープニングを実行し、強度ヒストグラムをランダムに変換して、最終的に合成画像Xdrand(上図bに示す)を取得しました。
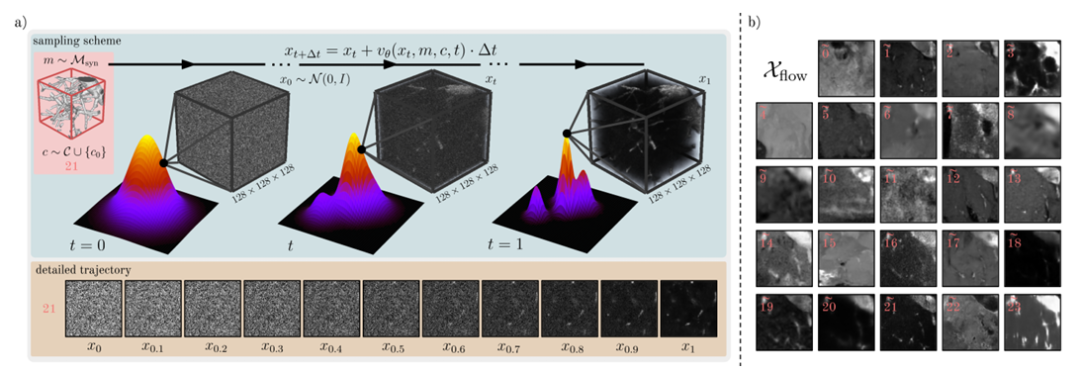
実データ Dreal の分布をさらに充実させるために、研究者はフローマッチングに基づく条件付き生成モデル F をさらにトレーニングおよびサンプリングして、3 番目のデータ ソース Dflow を生成しました。下の図の通りです。

モデルアーキテクチャ: 深層生成モデルとドメインランダム化戦略の導入
全体、vesselFM は、さまざまなモダリティや組織タイプで 3D 血管系を正確にセグメント化できる 3D 血管セグメンテーション専用に設計された汎用ベース モデルです。モデルの設計プロセスにおいて、研究者は 3 つの異種データ ソースを通じてモデルをトレーニングし、強力なセグメンテーションおよび一般化機能を実現しました。
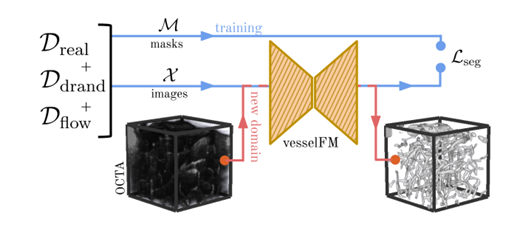
このプロセスにおいて、研究者らは次の 2 つの重要なステップを導入しました。それらはそれぞれ、深層生成モデルとドメインランダム化戦略です。上記のデータセット導入セクションでは、ドメインランダム化戦略について詳しく説明しています。このセクションでは、Dflow データセットの生成に使用されるディープ生成モデルに焦点を当てます。
ディープ生成モデルは、主に拡散モデルに基づいて合成医用画像を生成する重要な手段であり、大量の高忠実度合成データを生成するために使用されます。これらのデータに対してセグメンテーション タスクを実行するには、画像とマスクのペアの正確なマッチングが必要です。 Med-DDPM や SegGuidedDiff などの方法は、この課題に対応するために設計されています。チャネルごとにセグメンテーション マスクを連結してモデル入力に意味的調整を組み込み、一貫した解剖学的制約に準拠した画像とマスクのペアを生成します。前者は 3D 脳画像合成用にカスタマイズされており、後者は 2D 乳房 MRI および腹部 CT 生成用に設計されています。
この研究では、研究者たちは拡散モデルとは異なるアプローチを採用し、フローマッチングと呼ばれる生成モデリングアプローチを使用しました。既知の分布からターゲット分布へのデータの連続的な変換プロセスを学習することで新しいサンプルを生成し、拡散モデルと比較して自然画像で優れたパフォーマンスを発揮します。
具体的には、この研究では、生成モデル F は、θ パラメータ化されたネットワークを使用して学習した時間依存の速度場 v を表し、次に常微分方程式 (ODE) を通じてサンプル x₀~N(0,I) をデータ分布のサンプル x₁ にマッピングします。同時に、モデル F をトレーニングするために、研究者はフロー マッチングの目的を最適化し、予測速度とサンプリングの真値速度の間の時間スケールの損失を最小限に抑えました。
さらに、トレーニングモデルFはマスクとカテゴリ条件も採用しており、マスク調整は、マスク チャネルを入力画像 xₜ と連結することによって実現されます。研究者らは、クラス情報を組み込むために時間的埋め込みにクラス埋め込みを追加し、それを加算によって中間特徴レイヤーに注入しました。 Dflow を生成するために、研究者は最終的にオイラー積分によって x₁ を離散化し、下の図に示すように、多数の画像 Xflow をサンプリングしました。
実験結果:現在の最新モデルよりも優れた性能
船舶FMの有効性と信頼性を検証するために、研究者たちは比較評価を行った。また、ゼロサンプル、単一サンプル、少数サンプルのシナリオでのセグメンテーション機能を実証しました。
具体的には、検証フェーズでは、SMILE-UHURA、MSD8、OCTA、BvEM の 4 つの臨床データセットが使用されました。これらの評価データセットから形状 128³ の 3 つのパッチを抽出し、それらを使用して 1 つまたは 3 つのパッチすべてに対してシングルショットおよび少数ショットのセグメンテーション タスクを定義し、モデルを微調整します。残りのデータはテストと検証に使用されます。ゼロショット評価では、事前の微調整なしでモデルをテスト データに直接適用します。
同時に、3D 血管セグメンテーション用に特別に設計された 4 つの基本モデルが比較対象として使用されました。これらは、tUbeNet、VISTA3D、SAM-Med3D、および MedSAM-2 です。
研究者たちは、単一の NVIDIA RTX A6000 GPU を使用して、モデル F から 10,000 個の画像マスクをサンプリングし、3 日間で Dflow を生成しました。 Ddrand を管理するために、ドメインランダム化生成パイプラインから、それぞれが 128³ の形状を持つ 500,000 個の画像マスク ペアをサンプリングしました。使用される 3 つのデータ ソースの重みは、サイズに応じて大まかに設定され、それぞれ Ddrand (70%)、Dreal (20%)、Dflow (10%) となります。
具体的な結果は下の図に示されています。 vesselFM は、4 つのデータセットとタスクすべてにおいて優れた一般化と優れたパフォーマンスを示します。ゼロショットタスクでは、MSD8 データセットで、vesselFM の Dice スコアが VISTA3D のスコアより 5.86 ポイント高くなっています (VISTA3D は 11,454 個の CT データでトレーニングされており、それ自体が MSD8 のデータを含んでいます)。これにより、vesselFM の強力な誘導バイアスがさらに強調されます。
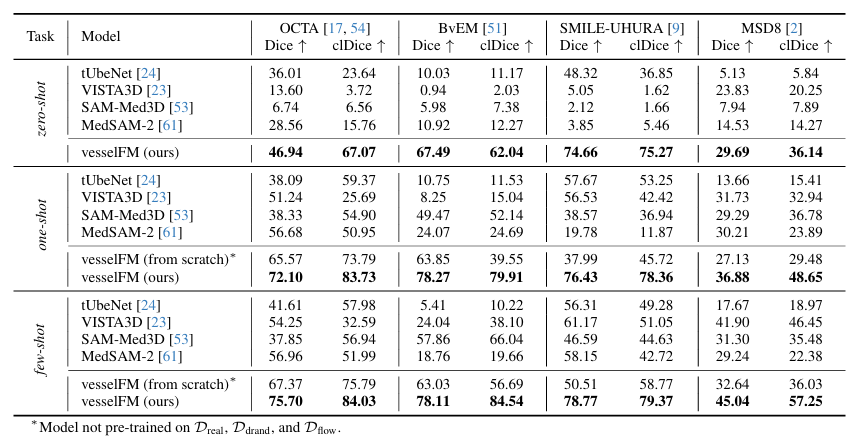
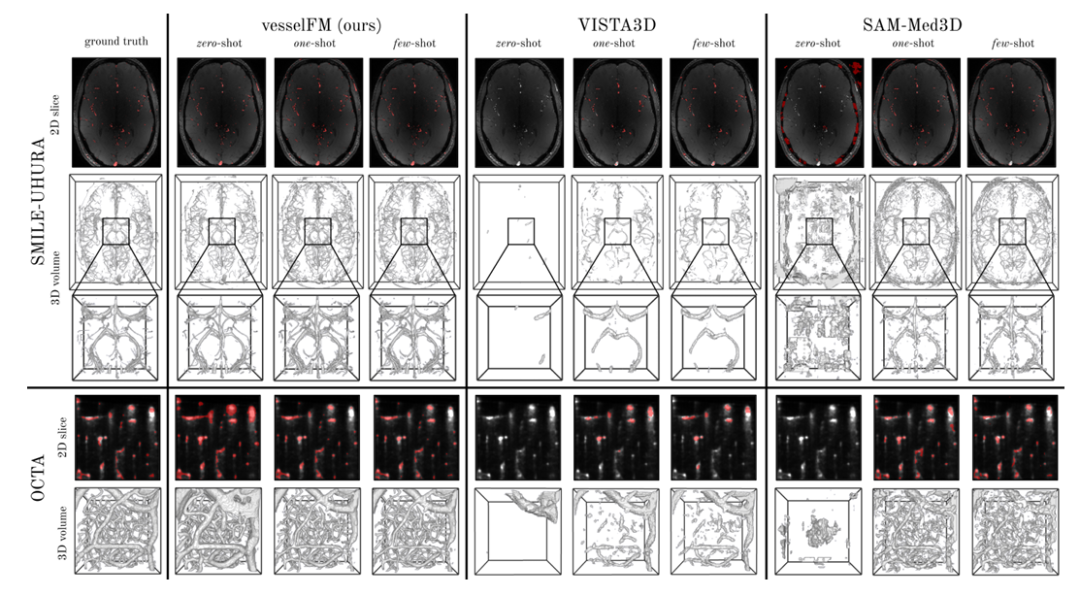
対照的に、一般的な 3D 血管セグメンテーション モデル tUbeNet は、より複雑な画像モダリティではパフォーマンスが十分ではなく、他の 2 つの一般的なセグメンテーション モデル SAM-Med3D と MedSAM-2 はゼロ ショット設定で血管をセグメンテーションできません。 SMILE-UHURA データセットでは、ゼロショット シナリオでの vesselFM の Dice スコアと clDice スコアが、少数ショット シナリオでのベースライン モデルのスコアを上回っていることは注目に値します。定性的な結果は、注釈者固有のバイアスの影響を受けずに、ゼロショットのコンテキストで vesselFM が優れた一般化能力を持つことを示しています。以下に示すように。
ディープラーニングが血管セグメンテーション研究に新たな道を開く
要約すると、vesselFMに関連する研究は、間違いなく3D血管セグメンテーション研究の進歩を促進し、血管疾患の治療と研究に新たな道を提供し、新しい高度なツールの誕生と応用を促進し、最終的に患者に利益をもたらすという目標を達成することが期待されます。
幸いなことに、この取り組みは、vesselFM だけが行っているわけではありません。ディープラーニング技術の発展と医療データの増加に伴い、人工知能による医療画像の処理は現代の医療改革の重要な方向性となっています。人類が直面している血管疾患の課題を自らの研究を通じて解決したいと願う研究所や研究機関がますますこの分野に注目し始めています。
たとえば、中国科学院のチームは、「VesselSAM: LoRA と Atrous Attention による大動脈血管セグメンテーションのための SAM の活用」というタイトルの研究を発表しました。この研究では、SAM の強化版である VesselSAM が提案されました。大動脈血管のセグメンテーション用に特別に設計されています。このモデルは、ホールアテンションモジュールと低ランク適応 (LoRA) を統合します。SAM の主な制限が解決され、医用画像内の複雑な階層的特徴をキャプチャする機能が強化されました。
用紙のアドレス:https://arxiv.org/abs/2502.18185
中国の上海交通大学のチームは、上海第一人民病院、ベルファストのクイーンズ大学、ルイジアナ州立大学のチームと共同で、「敵対的学習による自己教師付き血管セグメンテーション」と題する研究を発表しました。この研究では、敵対的学習を通じて 2 つのジェネレーターをトレーニングすることを提案しています。1 つは注意誘導ジェネレーター、もう 1 つはセグメンテーション ジェネレーターです。偽の血管を合成し、冠動脈造影画像から血管をセグメント化して、血管の特徴表現を学習させます。この論文はCVPR 2021にも選出されました。
ポルトガルのリスボン大学のチームとポルトガルのカトリック大学のチームも血管の分割に関する研究を発表しました。彼らは、ディープラーニングに基づいて開発された 3D 網膜血管ネットワークの自動セグメンテーションおよび定量化ソフトウェアである 3DVascNet を提案しました。このソフトウェアは、血管の正確なセグメンテーションを実現するだけでなく、血管密度、枝の長さ、血管の半径、分岐点の密度などの血管の形態測定パラメータを定量化することもできます。さらに重要なのは、このソフトウェアは無料だということです。同時に、その強力な一般化能力により、医療スタッフが3次元の血管ネットワークを研究する能力がさらに向上します。関連研究は「3DVascNet: マウス血管ネットワークを3Dでセグメンテーションおよび定量化する自動ソフトウェア」というタイトルで公開されました。
用紙のアドレス:https://www.ahajournals.org/doi/10.1161/ATVBAHA.124.320672
要約すると、医療画像処理における重要かつ困難なタスクとして、血管セグメンテーションには解決すべき問題がまだ多く残っていますが、研究者の度重なる試みにより、これらの問題は間違いなく解消されつつあることがわかりました。さらに説得力があるのは、近い将来、人工知能の応用が深まるにつれて、血管疾患が徐々に克服される可能性があるということです。








