Command Palette
Search for a command to run...
上海交通大学のチームは、40以上の主流モデルとデータセットを網羅し、ワンストップのタンパク質工学設計プラットフォームVenusFactoryをリリースした。

人工知能コンピューティングとデータ駆動型手法の急速な発展により、タンパク質工学は AI 支援設計段階へと移行しています。研究者は、膨大な生物学的データから貴重な情報を正確に抽出し、新しいタンパク質の設計と最適化を加速し、生物医学、合成生物学などの分野で革新的な進歩を促進するために、包括的で高品質のタンパク質データセット、より強力で影響力のあるタンパク質人工知能モデル、より効率的で標準化された分析プラットフォームをこれまで以上に必要としています。
このような状況において、ますます多くのライフサイエンスの実践者が AI を理解し、AI 技術を使用してタンパク質工学の設計を支援したいと考えています。しかし、David Baker氏が再設計したオープンソースソリューションとMetaのESMシリーズの大規模モデルはどちらも、AIコンピューティングフレームワークの複雑なロジック、膨大なコード、強力なコンピュータプログラミング基盤の必要性など、使用上の困難が数多くあります。言い換えれば、生物学研究者や、経験の浅いコンピュータ実践者でさえ、使用にはまだかなり高いハードルに直面しています。この点で、ユーザーフレンドリーなローコード アプリケーションは、現代のオープン ソース ツールの使用において徐々に主流のトレンドになってきています。これらは研究者が複雑なモデル構成やコード実装から解放されるのに役立ち、コンピューター科学者や生物学者がより便利な方法でディープラーニングモデルを呼び出したりトレーニングしたりして、科学研究そのものに集中できるようにします。
タンパク質工学分野における人工知能の応用と発展を促進するため、中国の上海交通大学のHong Liang教授の研究グループは、タンパク質工学に特化したワンストップオープンプラットフォームであるVenusFactoryを開発しました。研究者は、面倒なデータ取得、モデルトレーニング、タスク評価、モデル展開などの機能を、インターフェースインタラクションまたはコマンドラインを通じて簡単に実装できます。このプラットフォームは、コードフリーでプロセスベースの設計を通じて、従来の複雑な AI エンジニアリング操作を、指先で操作できる軽量な操作に簡素化します。研究者は、複雑なコードを書かずに、ローカルでウェブサービスを開始し、40以上の最先端のタンパク質ディープラーニングモデルを簡単に呼び出すことができるため、個人データのプライバシーが保護され、インテリジェントな科学研究の敷居が大幅に下がり、ライフサイエンス分野におけるAIの徹底的な応用が加速されます。
コードとデータはオープンソースです: https://github.com/ai4protein/VenusFactory
現在、HyperAIウェブサイトのチュートリアルセクションに「VenusFactory タンパク質工学設計プラットフォーム」が公開されています。詳しい使用方法のチュートリアルはこの記事の最後に添付されています。興味のある読者は、以下のリンクからプラットフォームを体験できます。
VenusFactory: タンパク質AIアプリケーションの障壁を打ち破る統合プラットフォーム
タンパク質データは非常に分散しています。 VenusFactoryは生物学的データのソースに直接アクセスします AI タンパク質研究は大規模な生物学的データに大きく依存しており、注釈付きデータは複数の主流の公開データベースに分散されています。科学者は、複数のデータベースを切り替えたり、データを手動でダウンロードしたり、形式を変換するためのスクリプトを書いたりする必要があり、その結果、実用的ではない研究作業に時間とエネルギーが浪費されてしまいます。 VenusFactory は、RCSB PDB、UniProt、InterPro などの主要な公開データベースに直接接続します。マルチスレッドの高速ダウンロードにより、データ取得の効率が大幅に向上します。
- 生物学的情報を完全に統合し、タンパク質配列、三次元構造、機能注釈にワンストップでアクセスできます。
- 標準化された形式の出力により、データの互換性の問題が回避され、直接的な AI トレーニングが容易になります。
- マルチスレッド ダウンロード メカニズムにより、データ取得速度が大幅に向上し、科学者は研究そのものに集中できるようになります。
タンパク質AIタスクの評価システムは統一されていません。 VenusFactory は 5 つのコアタスクをカバーします。 現在、タンパク質 AI モデル評価システムには既成の権威あるベンチマーク データが不足しており、ほとんどの研究は依然として個々のタスクの最適化に重点を置いています。研究者が解決策を選択する場合、多くの場合、実験の比較に多くの追加時間を費やす必要があります。 VenusFactory は、5 つのコアタスクをカバーする 40 を超える最先端のタンパク質工学評価データセットを統合します。
- タンパク質機能予測: タンパク質の機能タグを予測して、新しい酵素や新しいターゲットの発見に役立ちます。
- タンパク質の細胞内局在予測:細胞内のタンパク質の局在を予測して病気の診断を支援します。
- タンパク質の溶解性評価:溶解度の事前判断により湿式実験の効率を向上します。
- タンパク質変異の影響の分析遺伝子変異の潜在的な影響を調査し、精密医療を進歩させます。
- その他の予測タスク:金属イオン結合、タンパク質選別シグナル予測、最適温度予測など。
これらのベンチマーク データセットと評価結果を利用することで、ユーザーはさまざまなモデルのパフォーマンスを簡単に比較し、ソリューションを選択して最適化できます。同時に、VenusFactory はすべてのデータセットをダウンロードする機能も提供しているため、ユーザーはワンクリックで対応するタンパク質の配列、構造、ラベルなどの情報を取得できます。
既存のタンパク質AI計算ツールは使用障壁が高く、コンピューティングの知識のない研究者が使用するのは困難である。 現在のタンパク質 AI モデルを使用するには、多くの場合、強力なプログラミング スキルとディープラーニングの知識が必要です。ほとんどの生物学者にとって、AI モデルのトレーニング、微調整、適用は、依然として敷居の高い作業です。 VenusFactoryは、Venusシリーズ(ProSST、Pro-Prime、PETAなど)、ESMシリーズ(ESM2、ESM1bなど)、Ankhシリーズ(Base、Large)、ProtTransシリーズ(ProtBert、ProtT5)など、包括的なAI大規模モデルソリューションを網羅する、世界最先端のタンパク質言語モデル(PLM)を40以上統合しています。
- 事前学習済みモデルのエコシステム: ゼロからトレーニングすることなくオープンソース PLM を直接呼び出すことで、コンピューティング リソースを節約します。
- 高性能な微調整: LoRA や SES-Adapter などの最先端の方法をサポートし、モデルを特定の生物学的タスクに適応させます。
- マルチタスクサポート: タンパク質の溶解度予測でも、変異体の特性予測でも、簡単に始めることができます。
- コマンドラインモード: コンピューター科学者に適しており、パラメータを柔軟に調整し、高度な最適化を実現できます。
- コード不要のウェブインターフェース: 生物学者に適しており、プログラミングの知識がなくても、簡単なクリックで AI タスクを実行できます。
これらの主要な課題に対処するために、VenusFactory はワンストップの AI 対応タンパク質エンジニアリング プラットフォームを構築し、データ取得、タスク評価からモデルの微調整までの完全なソリューションを提供することで、生物学者や計算科学者が研究を効率的に進めることができるようにしています。
科学的革新を促進するオープンソースとコミュニティ構築
科学研究の未来はオープンな共有にあります。 VenusFactory は Apache 2.0 ライセンスを使用します。すべてのコード、データセット、モデルの重みは完全にオープンソースです。ユーザーは自由にダウンロード、変更、最適化し、最新の結果を世界中の研究者と共有することができます。すべてのデータ、モデル、微調整コードは GitHub と Hugging Face でホストされており、世界中の科学者が簡単にアクセスして実験を再現し、VenusFactory に基づいて独自の AI 研究プロジェクトを構築できます。
読者が VenusFactory を体験できるように、HyperAI は「VenusFactory タンパク質エンジニアリング設計プラットフォーム」のワンクリック展開チュートリアルを開始しました。以下にその使用方法を詳しく説明します。
チュートリアルリンク: https://go.hyper.ai/ZqO3h
VenusFactory タンパク質工学設計プラットフォームチュートリアル
デモの実行
1. hyper.ai にログインし、チュートリアル ページで VenusFactory Protein Engineering Design Platform を選択し、このチュートリアルをオンラインで実行をクリックします。
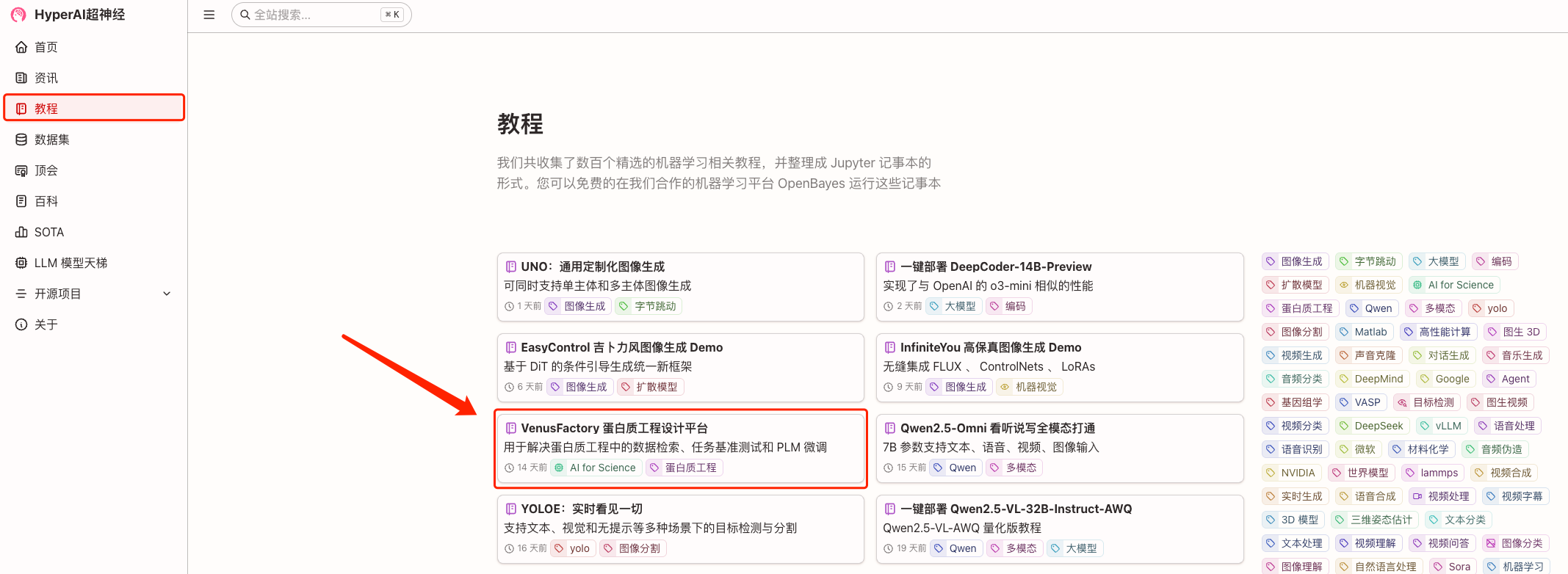
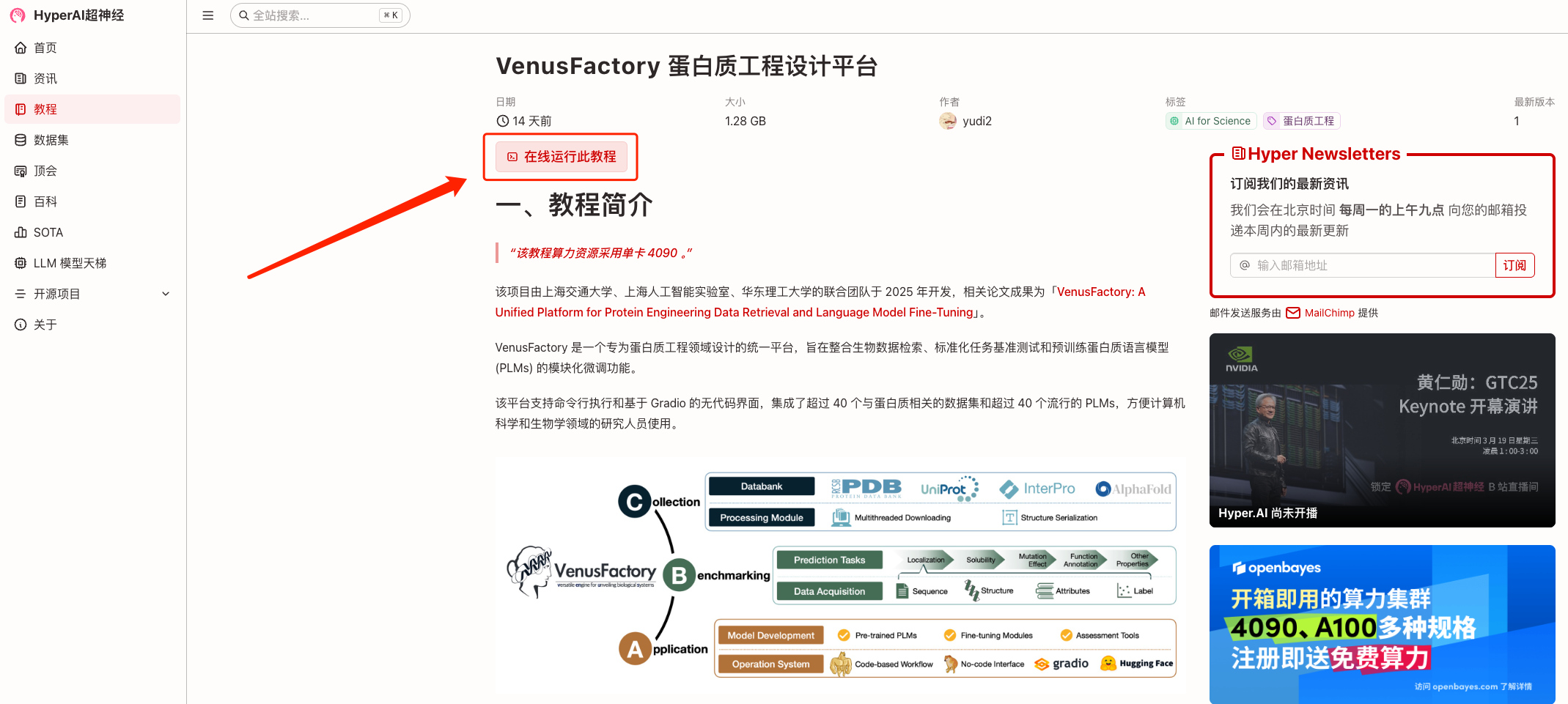
2. ページがジャンプしたら、右上隅の「クローン」をクリックしてチュートリアルを独自のコンテナにクローンします。
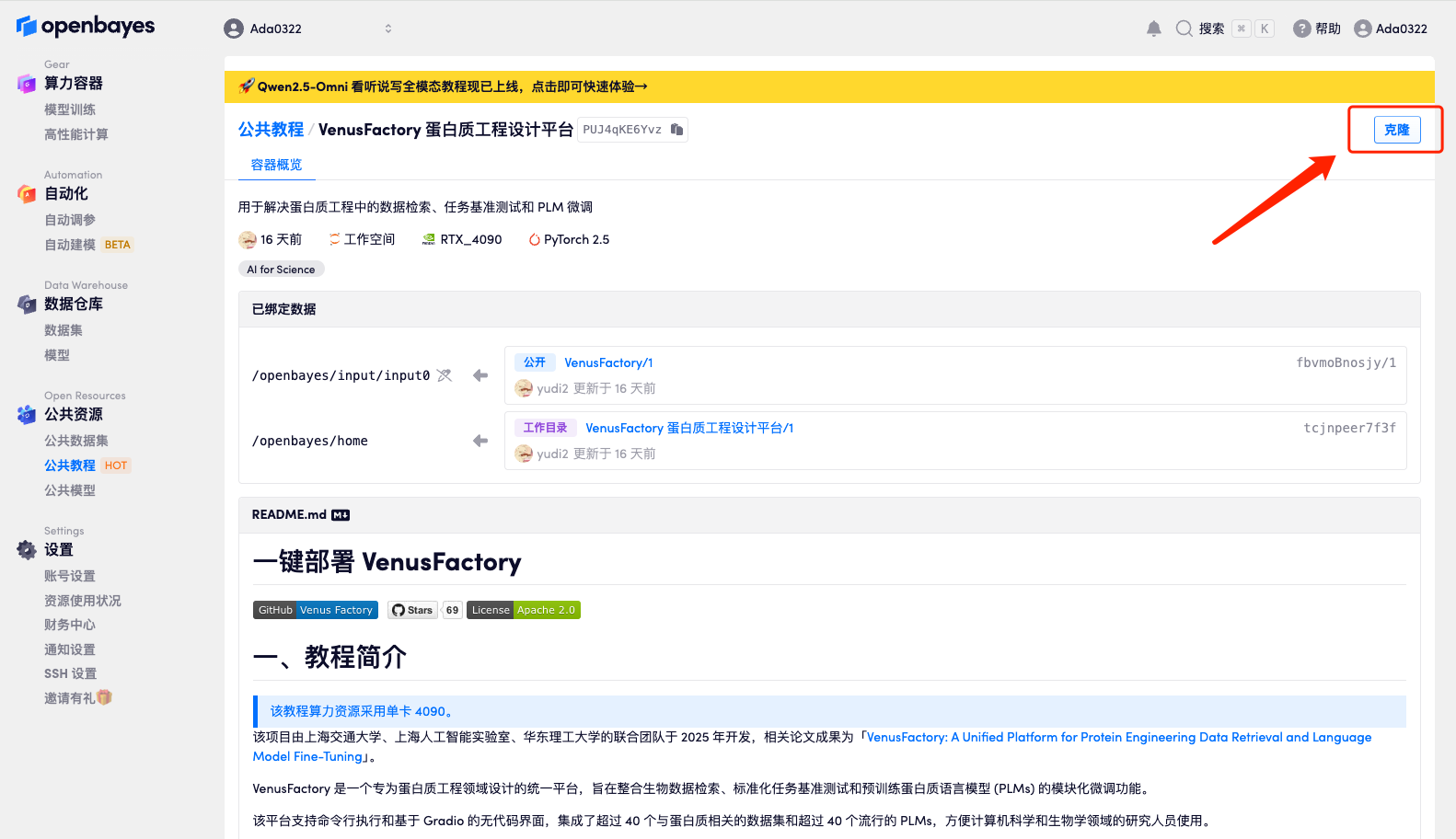
3. NVIDIA GeForce RTX 4090 と PyTorch イメージを選択し、「続行」をクリックします。 OpenBayes プラットフォームは 4 つの課金方法を提供します。ニーズに応じて、「従量課金制」または「日次/週次/月次」を選択できます。新規ユーザーは、以下の招待リンクを使用して登録すると、4 時間の RTX 4090 + 5 時間の CPU フリー時間を獲得できます。
HyperAI ハイパーニューラルの専用招待リンク (ブラウザに直接コピーして開きます):
https://openbayes.com/console/signup?r=Ada0322_NR0n
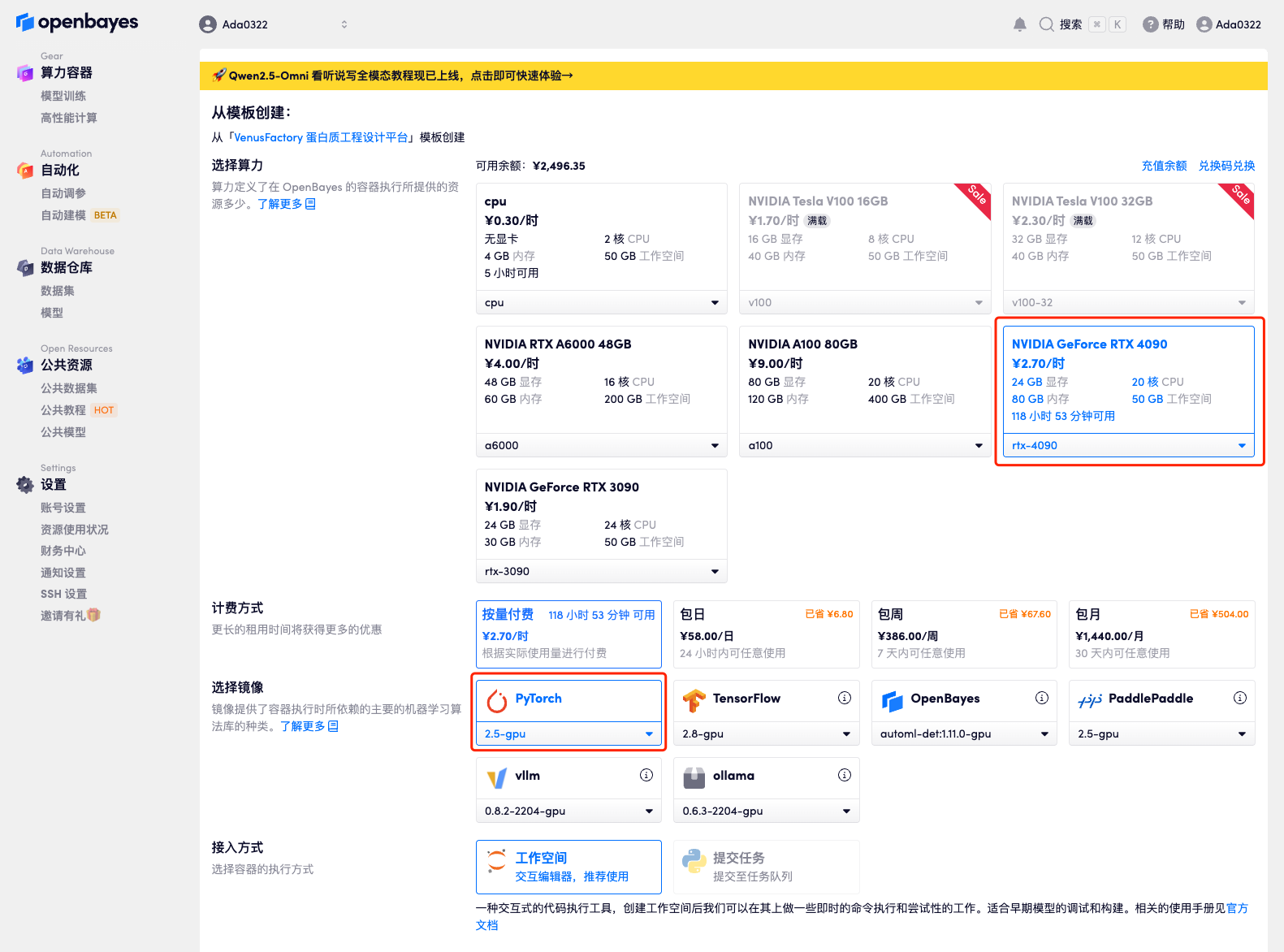
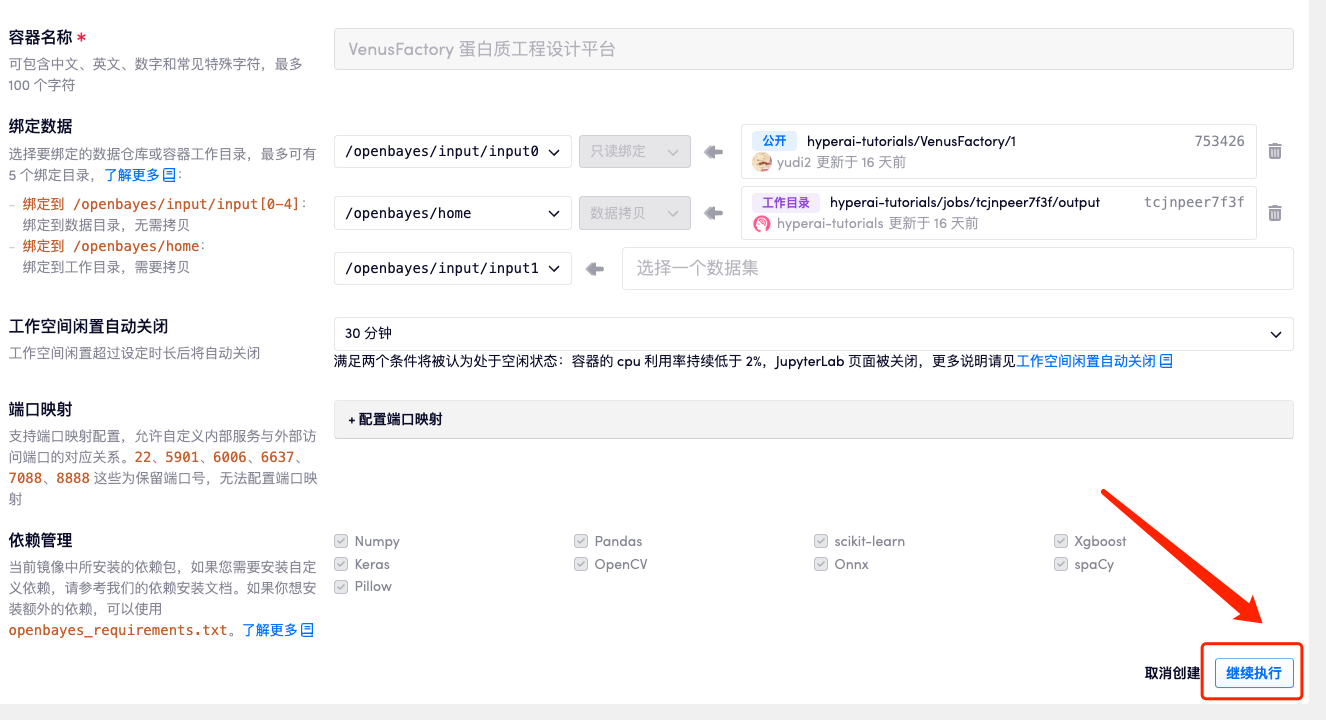
4. リソースが割り当てられるまで待ちます。最初のクローン作成プロセスには約 2 分かかります。ステータスが「実行中」に変わったら、「API アドレス」の横にあるジャンプ矢印をクリックしてデモ ページに移動します。モデルが大きいため、WebUI インターフェイスが表示されるまでに約 3 分かかります。そうでない場合は、「Bad Gateway」と表示されます。 APIアドレスアクセス機能を使用する前に、ユーザーは実名認証を完了する必要がありますのでご注意ください。
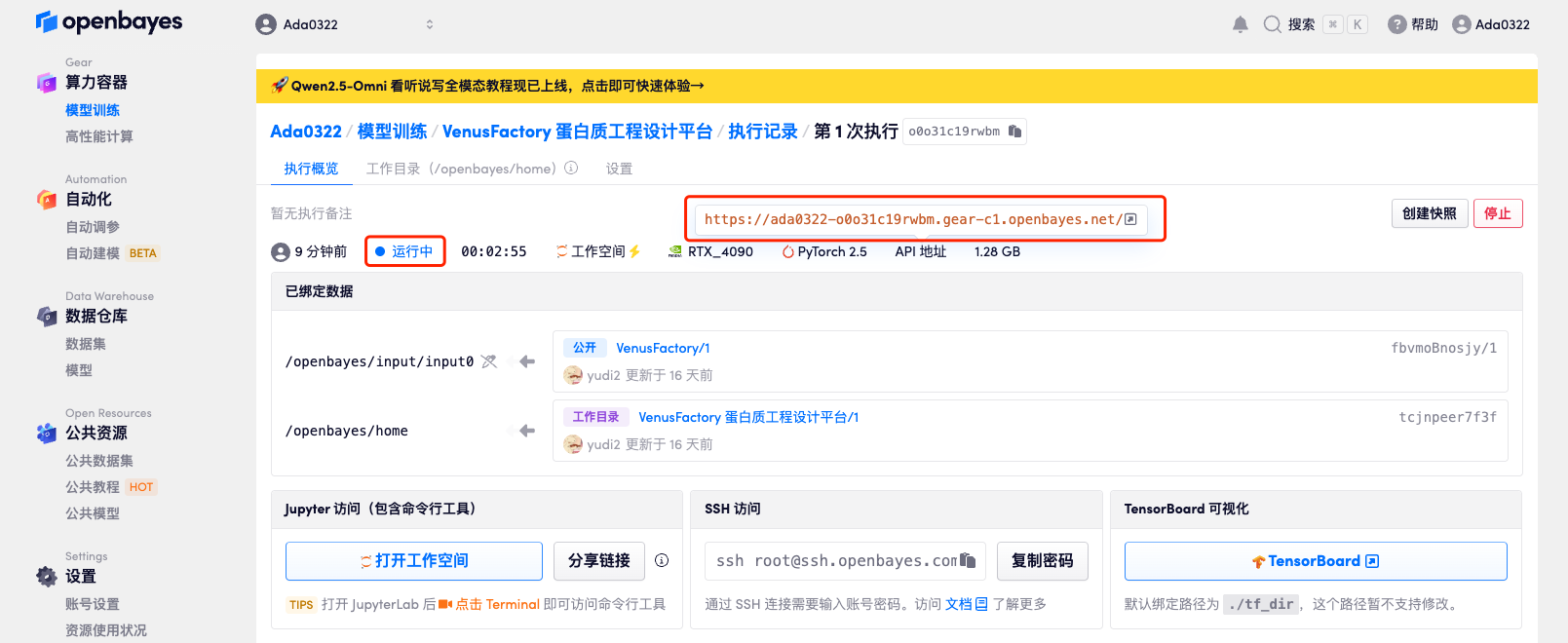
エフェクト表示
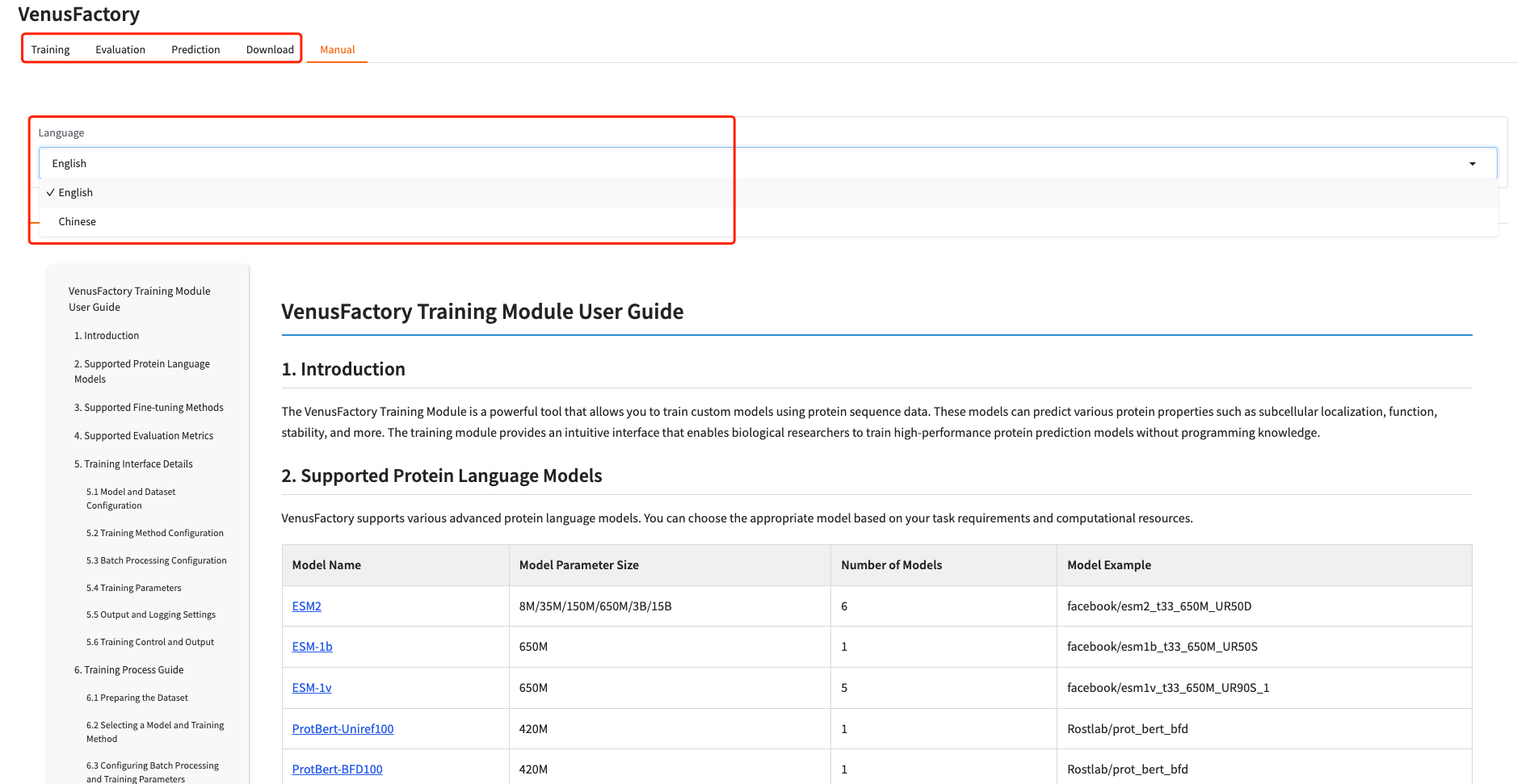
1. このチュートリアルには、トレーニング、評価、予測、ダウンロードの 4 つのモジュールが含まれています。 「マニュアル」をクリックして言語を選択すると、各モジュールの詳細な手順が表示されます。
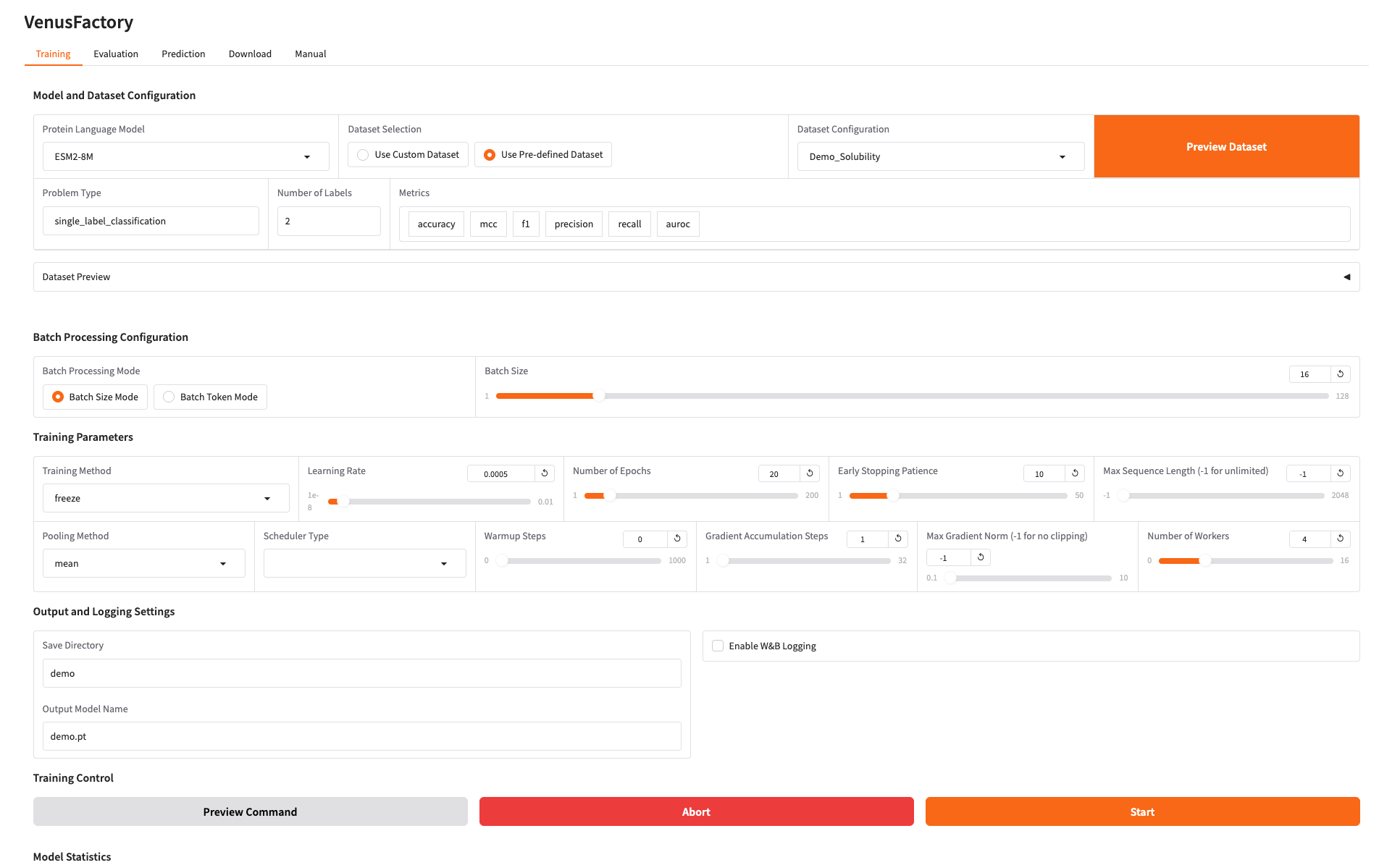
2. トレーニングモジュール
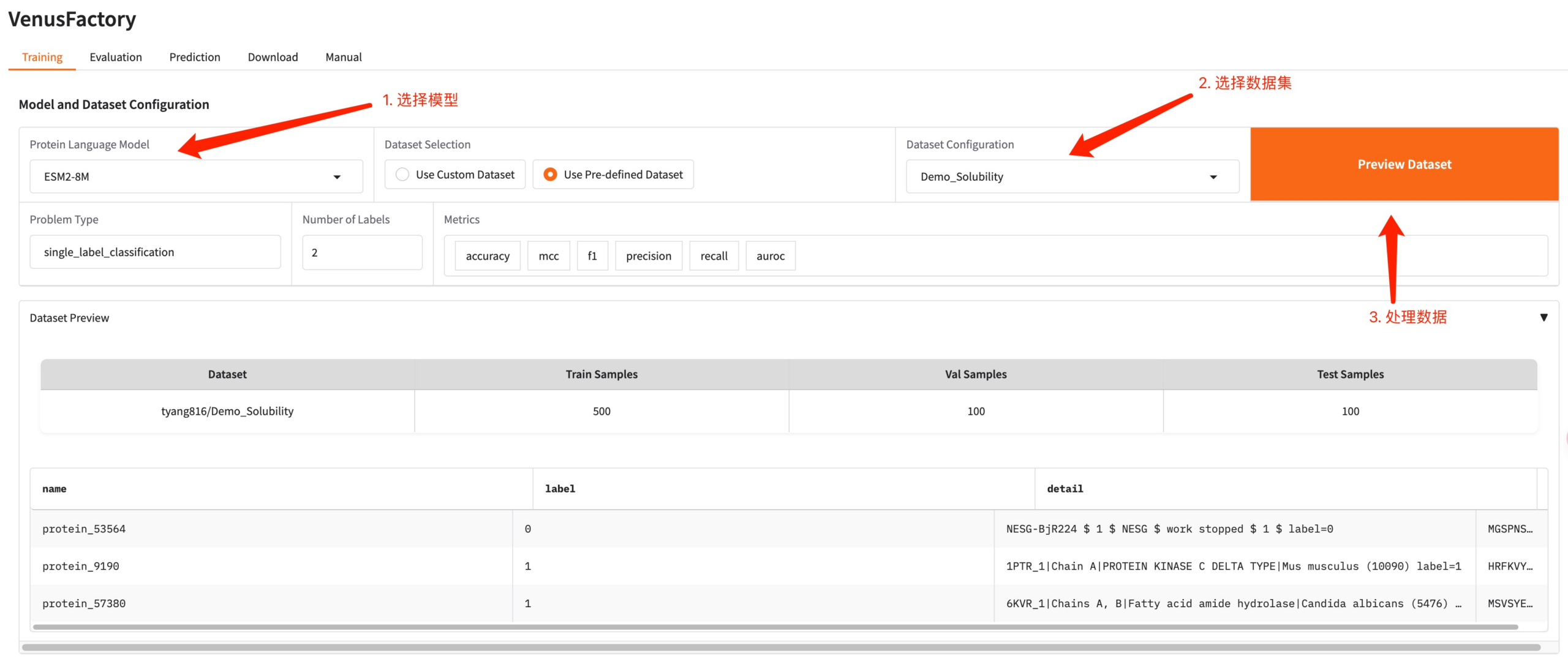
トレーニングモジュールをクリックし、タンパク質言語モデルでトレーニングするモデルを選択し、データセット構成でトレーニングデータを設定します。
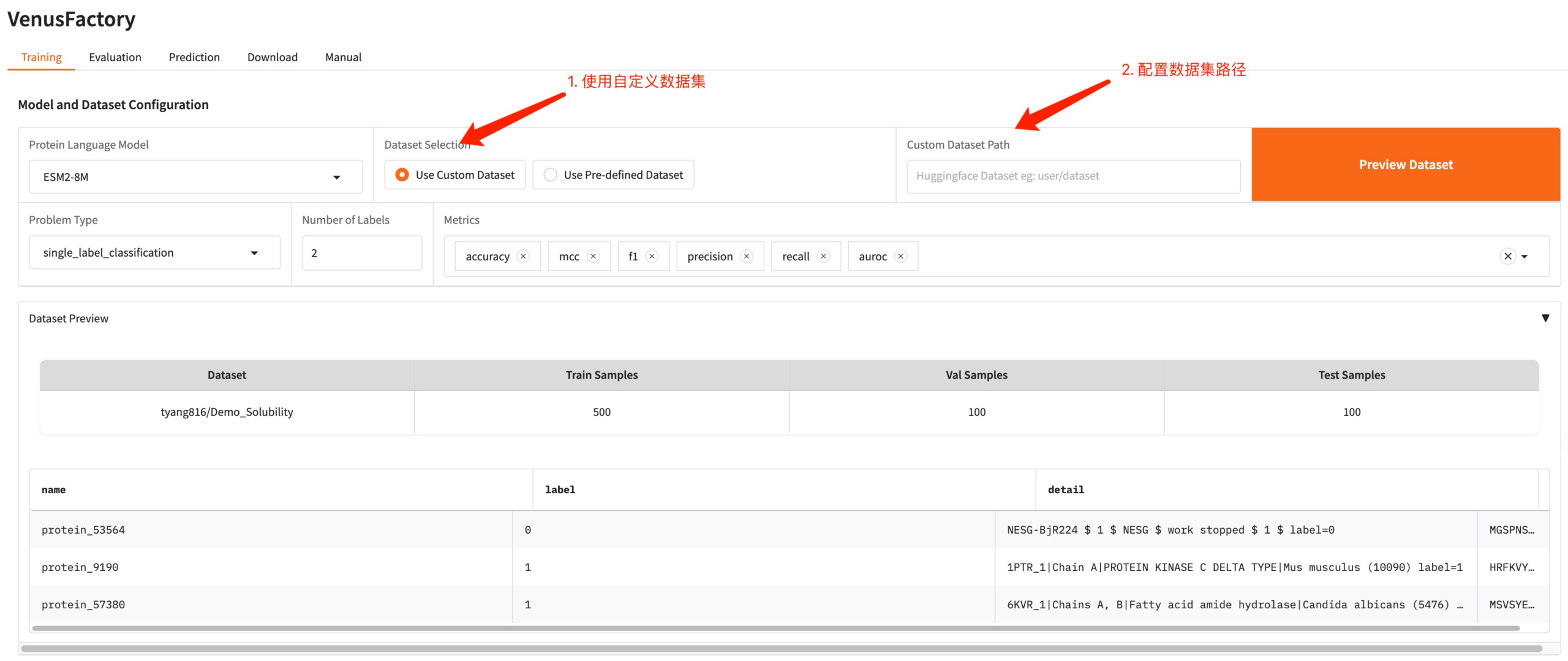
独自のデータセットを使用する必要がある場合は、「カスタム データセットの使用」構成を使用して、データセット パスを入力するだけです (詳細については、手動使用のドキュメントを参照してください)。
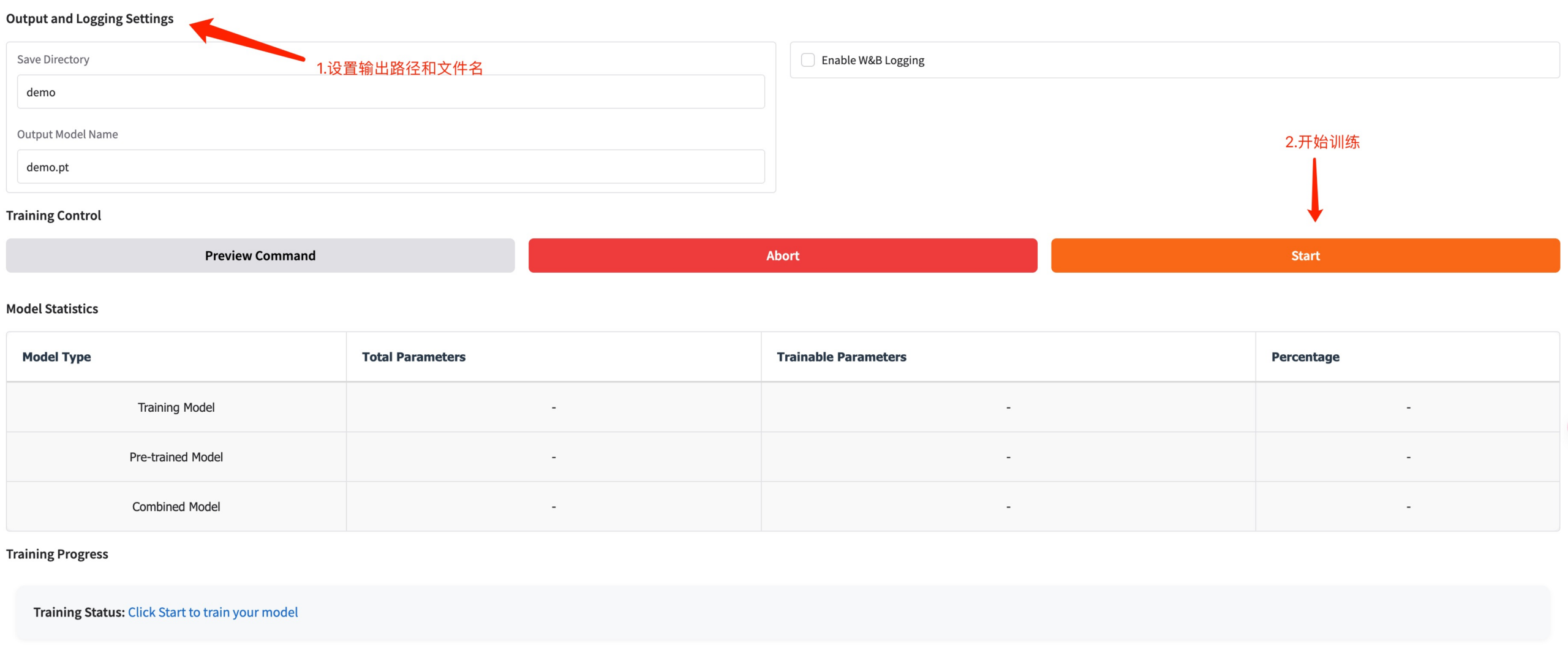
トレーニング モデルの保存パスを設定し、[開始] をクリックしてトレーニングを開始します。
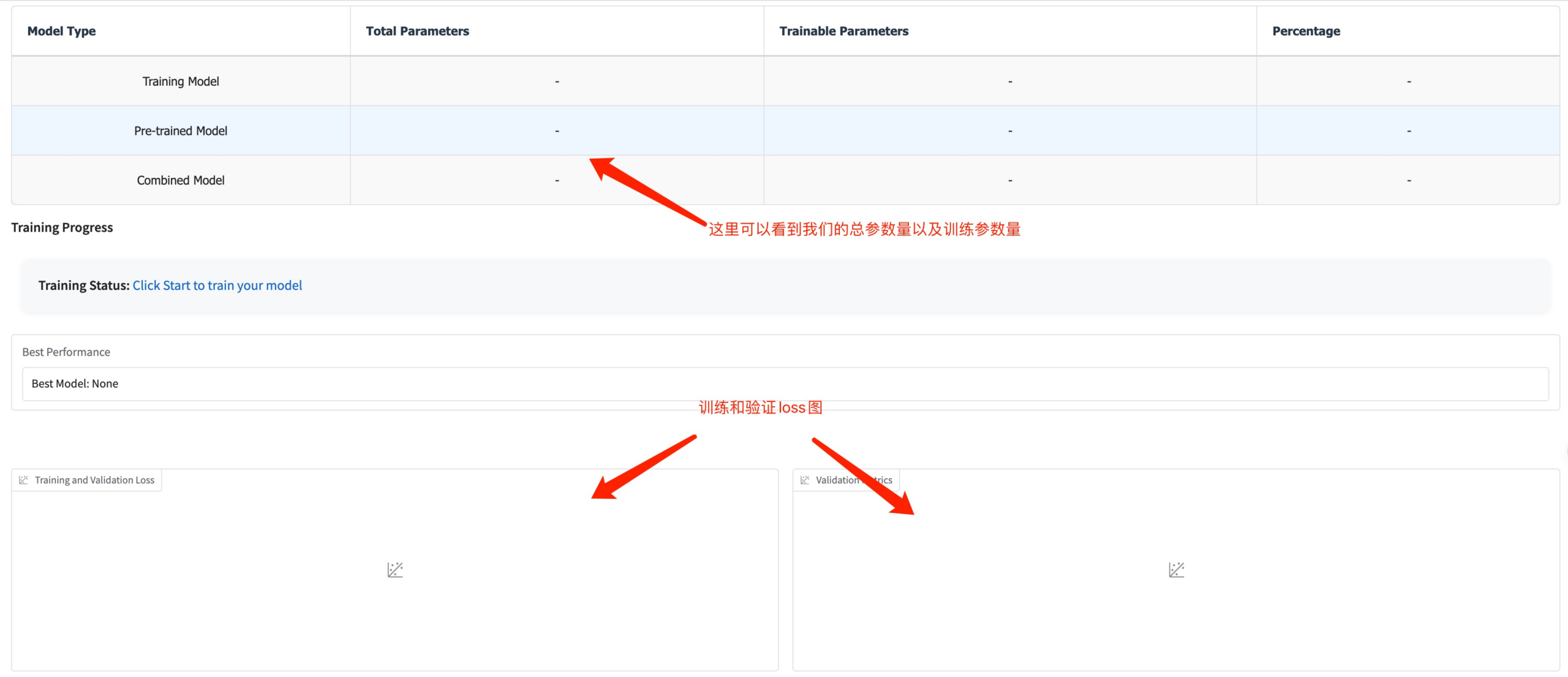
この時点で、トレーニングパラメータと損失曲線を見ることができます。
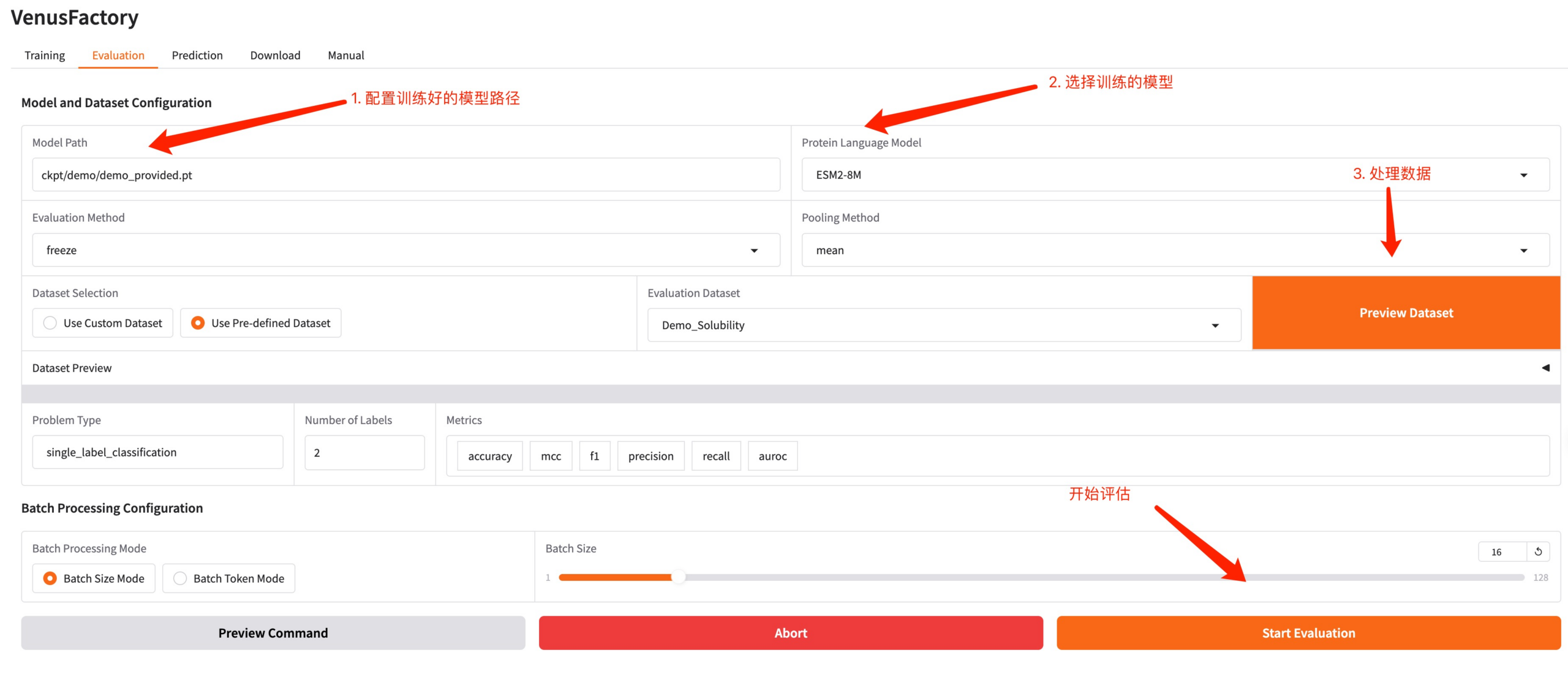
3. 評価モジュール
評価モジュールをクリックし、トレーニングによって生成されたモデルパスとトレーニング済みモデルを構成し、データを処理し、ハイパーパラメータを調整して評価を開始します。
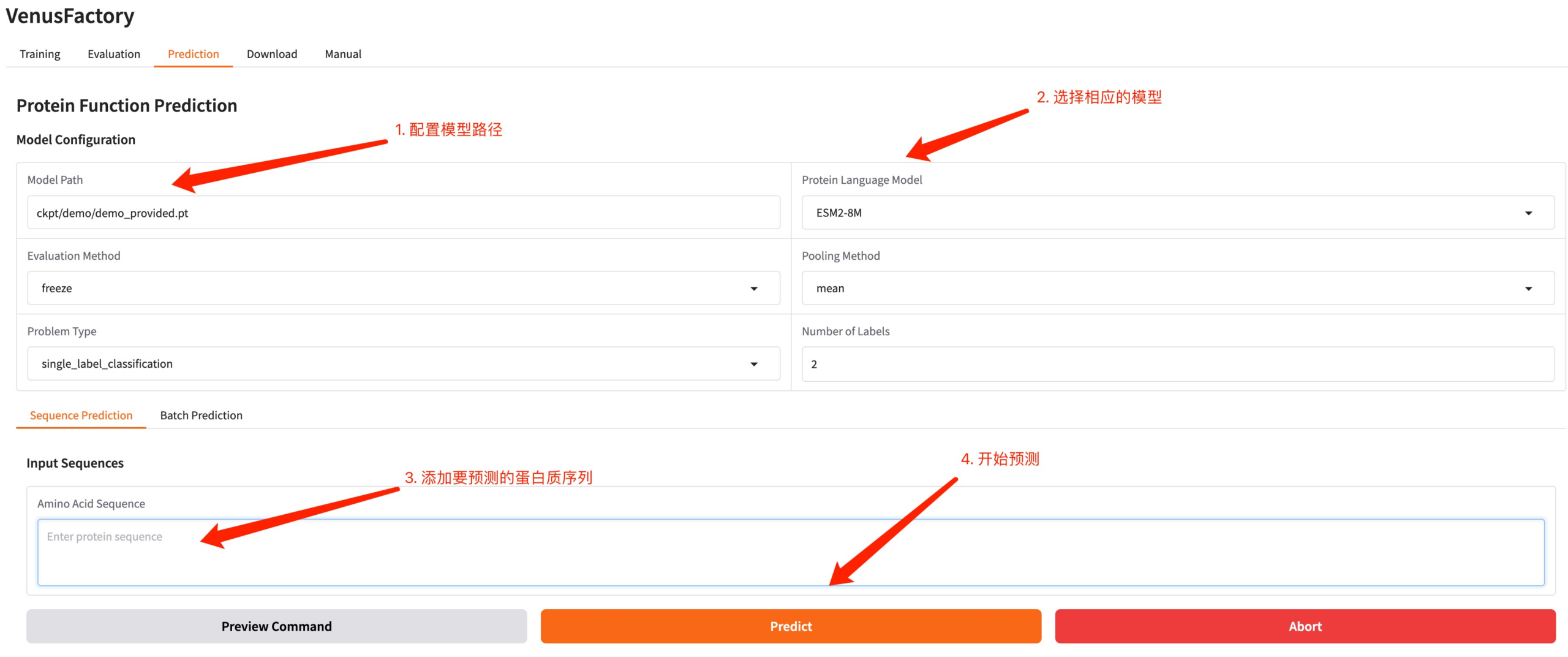
4. 予測モジュール
「予測」モジュールをクリックし、トレーニングによって生成されたモデル パスとトレーニング済みモデルを構成し、予測するタンパク質配列を入力して、「予測」をクリックして予測を行います。
タンパク質配列の例: MKTWFGHVLQ
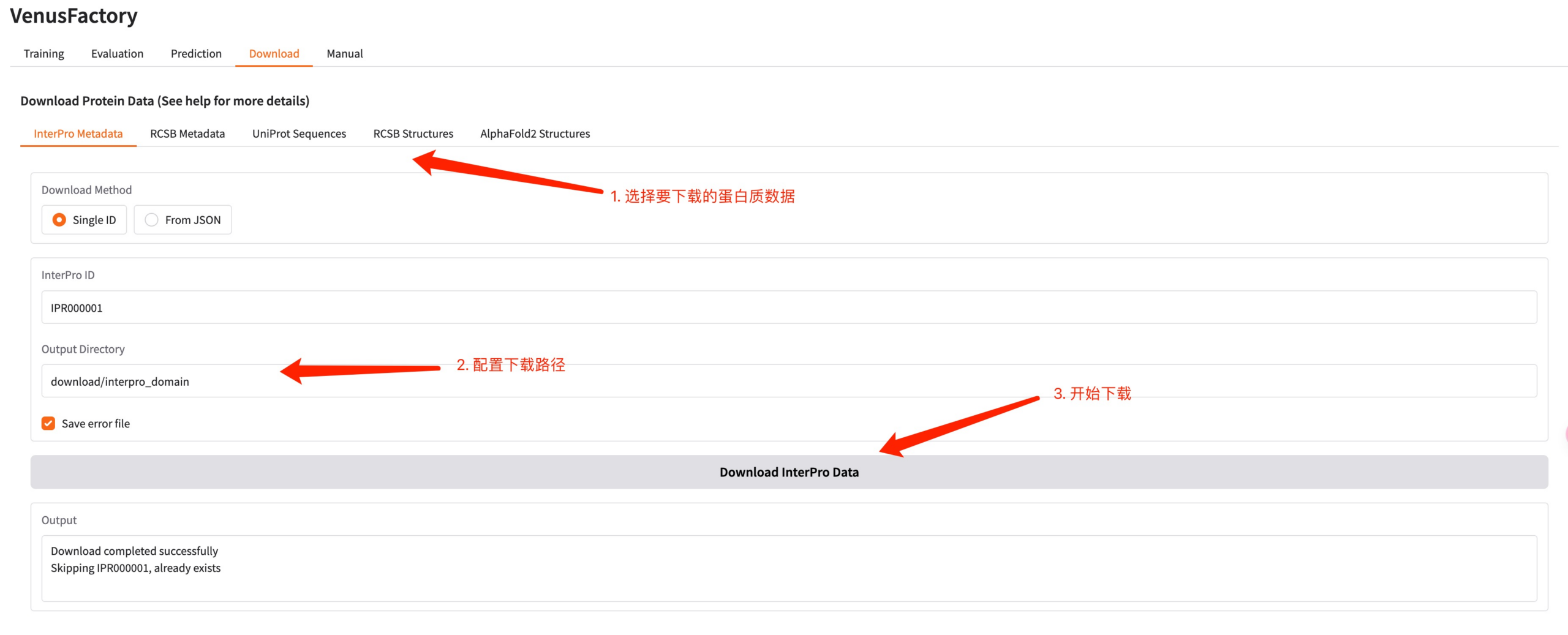
5. モジュールをダウンロードする
このインターフェースでタンパク質データをダウンロードするには、ダウンロード モジュールをクリックします。
上記は「VenusFactory タンパク質工学設計プラットフォーム」の使い方を詳しく説明したチュートリアルです。ぜひ皆様も体験してみてください!








