Command Palette
Search for a command to run...
酵素反応速度パラメータ予測、ボトルネック特定…中国科学院深圳先端技術研究所の羅暁州氏は、酵素分野におけるAIの革新的な応用について講演した。

タンパク質は生命の礎として、生命活動において重要な役割を果たします。その構造と機能の研究は、革新的な医薬品の開発、合成生物学、酵素生産などの分野にとって非常に重要です。しかし、従来のタンパク質設計には多くの課題があります。タンパク質の構造は複雑で、配列空間は広大です。専門家の経験とハイスループットスクリーニングに依存する設計方法は、時間と労力がかかるだけでなく、成功率を保証することも困難です。
今日、AI for Science は、世界的な人工知能開発における新たなフロンティアとなり、科学研究のパラダイムを大きく変え、タンパク質設計の分野に多大な変化をもたらしています。特に、AlphaFold などの革新的な成果が登場して以来、関連する研究は徐々に世間の注目を集めるようになり、より多くの注目を集めるようになりました。同時に、国内外の優秀なチームを育成し、技術や応用などさまざまな面から困難に取り組んでもらうよう推進してきました。
中国科学院深圳先進技術研究所の研究員である羅暁州教授もその一人だ。彼は以前は合成生物学に重点を置いていました。 2019年に中国に帰国後、AIタンパク質の研究に専念し始めた。最近、中国の上海交通大学が主催した「未来はここにある」AIタンパク質設計サミットで、羅暁州教授は「人工知能主導の酵素工学」というテーマについて自身の見解を共有しました。酵素設計におけるマルチモーダル学習と生成AIの潜在的な応用を探る。酵素工学分野における AI の革新的な応用と実践について、UniKP フレームワークや ProEnsemble マシンなどの複数の観点から説明します。

HyperAIは、本来の意図を損なうことなく、詳細な共有を整理して要約しました。以下はスピーチのハイライトの書き起こしです。
自動化プラットフォーム構築、AIがタンパク質の問題を解決
天然物は、幅広い資源、豊富な構造、多様な作用といった特徴を持つ、医薬原料の宝庫です。しかし、天然資源から天然物を抽出する従来の方法は非効率であり、純粋な化学合成では収量が低いだけでなく、大量の有毒で危険な試薬の使用も必要になります。たとえば、アルテミシニンはもともとヨモギから抽出されましたが、化学合成中に多くの問題に直面しました。その後、複数の遺伝子を調節することでサッカロミセス・セレビシエでアルテミシニンの発現が達成されました。この画期的な発見により、生合成の可能性に気づき、生物学分野の研究に力を入れ始めました。さらに、酵素修飾の分野では、データ不足により研究の進歩が著しく制限されることになります。この問題はデータの重要性を認識させてくれるので、私はその後の AI 研究の基盤を築くために自動化とデータ プラットフォームの構築に取り組んでいます。
生命の基本分子である核酸、小分子脂質、炭水化物、代謝物、イオン、水などの物質はすべてタンパク質から生成されます。この特徴を踏まえ、2019年に中国に帰国後、私はタンパク質分野に研究の焦点を当て、3つの科学的な疑問を提起しました。第一に、タンパク質の配列から直接その活性と機能を予測することは可能でしょうか? 2 つ目は、人々が必要とするタンパク質をオンデマンドで生成または進化させることができるかどうかです。 3 つ目は、普遍的で標準化された戦略に基づいて酵素や菌株を最適化することが可能かどうかです。
UniKPフレームワークは酵素特性をより正確に予測します
教科書にはこう記されている。「タンパク質の一次配列は三次構造と機能を決定し、一次配列には機能情報が含まれていなければならない。」したがって、シーケンスをどのように抽出するかが非常に重要です。 AlphaFold に触発されて、私たちのチームは配列からタンパク質の機能を予測する方法を模索し始めました。私たちの研究では、Transformer アーキテクチャを導入して、従来の表現方法と機械学習機能を統合し、統合モデルを構築しました。融合機能と統合モデルに基づくペプチドおよびタンパク質機能予測フレームワークは、8 つの関連予測タスクで SOTA パフォーマンスを達成し、ペプチドおよびタンパク質機能を正確に予測しました。抗菌ペプチドなどの抗感染活性物質のスクリーニングプロセスを加速し、実験コストを削減します。
その後、研究チームは UniKP フレームワークを使用して、Transformer 埋め込み酵素パラメータ予測ツールに基づいて酵素の特性を予測しようとしました。 ProtT5 と従来の SMILE Transformer モデルを使用してシーケンスをベクトル化し、それを単純な機械学習モデルと組み合わせて SOTA 結果を実現します。
研究チームは、UniKP のパフォーマンスと価値を検証するために 4 つの代表的なデータセットを選択しました。
まずDLkcatデータセットです。研究者らは、851 種の生物由来の 7,822 個の固有のタンパク質配列と 2,672 個の固有の基質を含む 16,838 個のサンプルをスクリーニングしました。データセットは、9:1 の比率に従ってトレーニング セットとテスト セットに分割されます。
これに pH と温度のデータセットが続きます。pH データセットには、261 の固有の酵素配列と 331 の固有の基質からなる 636 のサンプルが含まれており、温度データセットには、243 の固有の酵素配列と 302 の固有の基質からなる 572 のサンプルが含まれています。データセットは、8:2 の比率に従ってトレーニング セットとテスト セットに分割されます。
3番目はミカエリス定数(Km)データセットです。これは、酵素配列、基質分子指紋、および対応する Km 値を含む 11,722 個のサンプルで構成されています。データセットは 8:2 の比率でトレーニング セットとテスト セットに分割されます。
4番目はkcat/Kmデータセットです。酵素配列、基質構造、および対応する kcat/Km 値で構成される 910 個のサンプルが含まれています。
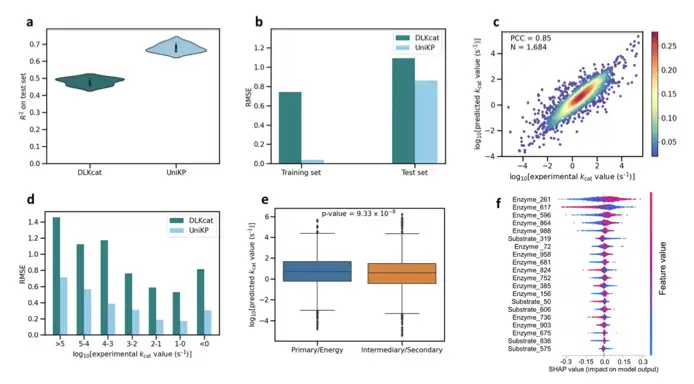
UniKP は、kcat 予測において既存のモデルよりも大幅に優れており、初めて kcat/Km 予測を達成したことが検証されました。kcat を例にとると、公開されている最大のデータセットでは、決定係数は現在の SOTA 結果よりも 20 パーセントポイント高くなります。同時に、異なるデータセットの分割、異なる間隔の分割、異なる酵素カテゴリの分割など、複数のタスクでも大幅に優れたパフォーマンスを発揮します。
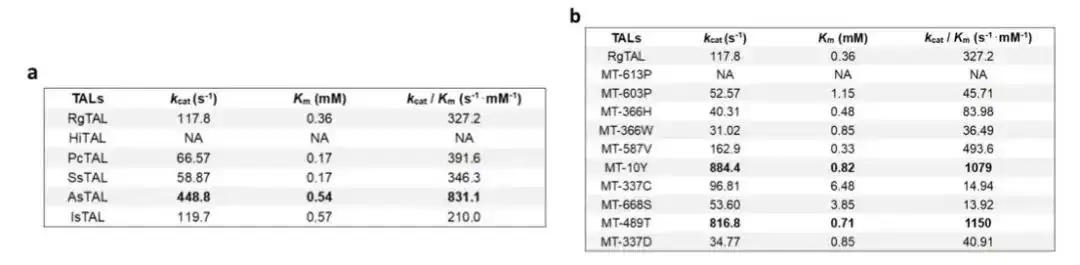
このアーキテクチャを使用して、1,000 個の Blast シーケンスからこれまでで最も高い酵素活性を示す野生型 TAL 酵素を見つけ、単一部位の変異を予測することで酵素活性の高い変異体を取得し、酵素エンジニアリング プロセスを大幅に加速しました。
さらに、タンパク質の熱安定性をターゲットとして、配列ベースの好熱性タンパク質予測モデル Thermal Finer を提案しました。このモデルは、3 つの分類データセットで SOTA パフォーマンスを達成し、タンパク質配列に基づいて対応する最適な触媒温度 (回帰) の予測を初めて実現しました。つまり、タンパク質配列から最適温度を直接予測することに初めて成功し、酵素マイニングと進化を強力にサポートすることになります。
必要に応じてタンパク質を生成または進化させるための ProGPT-2 の微調整
現在、タンパク質生産、特に酵素生産のモデルには主に 2 つの種類があります。
* 生成的敵対的ニューラルネットワーク(GAN):ProteinGAN
* 事前学習済みの生成大規模言語モデル(LLM):ProtGPT2、ProGen
しかし、これらのタンパク質生成ツールはいずれも類似した配列を生成するという問題があり、新しい機能や活性を備えた酵素を生成するというニーズを満たすことができません。理論的な分析にもいくつか不合理な側面があります。まず、画像のピクセル値は連続的であるため、勾配最適化に適しています。 2 番目に、テキスト (アミノ酸配列) は不連続であり、勾配最適化は埋め込みの更新には意味がなく、非常に非効率的です。
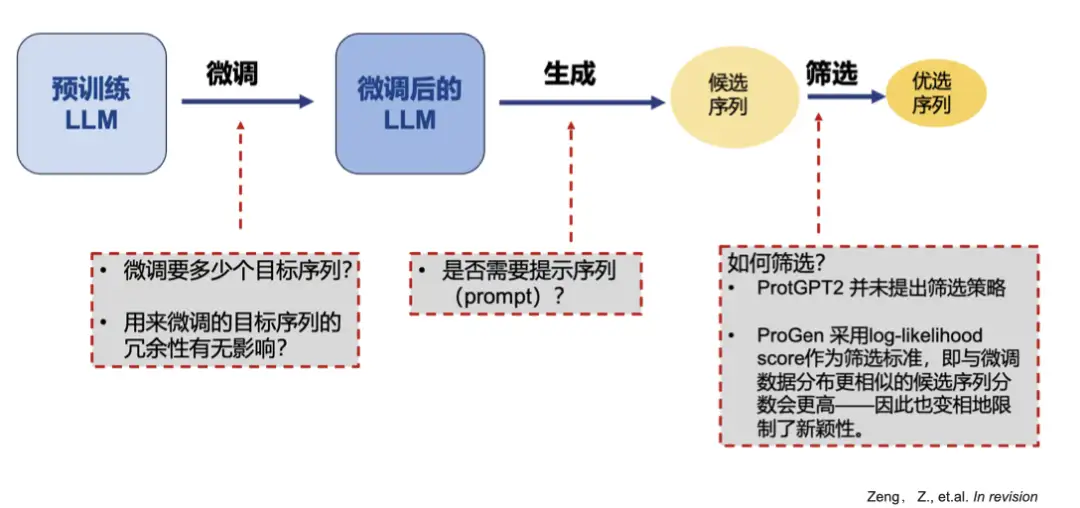
このような問題に対して、私たちは既存のモデルの欠点を深く分析し、新しい最適化フレームワークを提案します。
私たちのチームは ProGPT-2 を微調整し、生成されたシーケンスをフィルタリングして優先順位を付ける識別器として CNN ニューラル ネットワークを使用しました。実験により、配列の微調整には 2000 個かそれ以下しか必要ではなく、ヒントワードなしで生成された配列は天然の酵素に近くなります。同時に、冗長データを削減することで、生成されるシーケンスの新規性を向上させることができます。
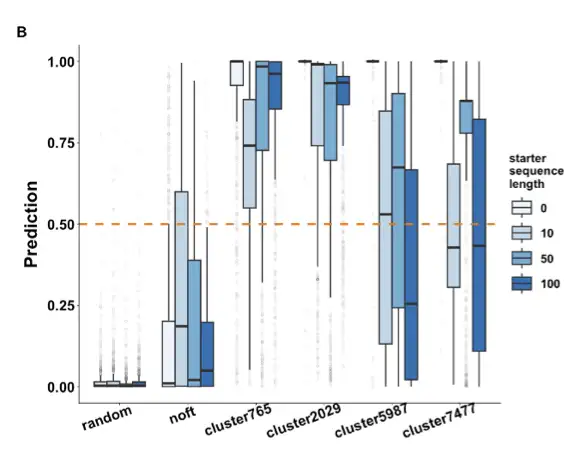
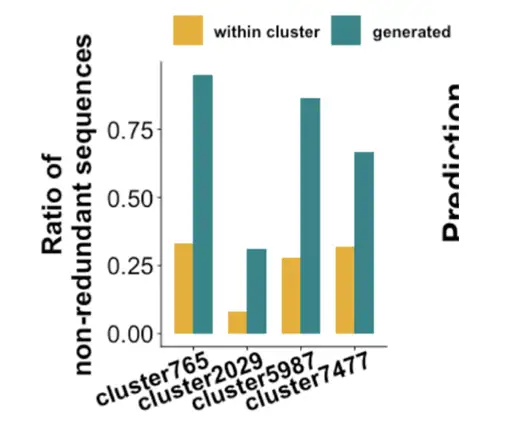
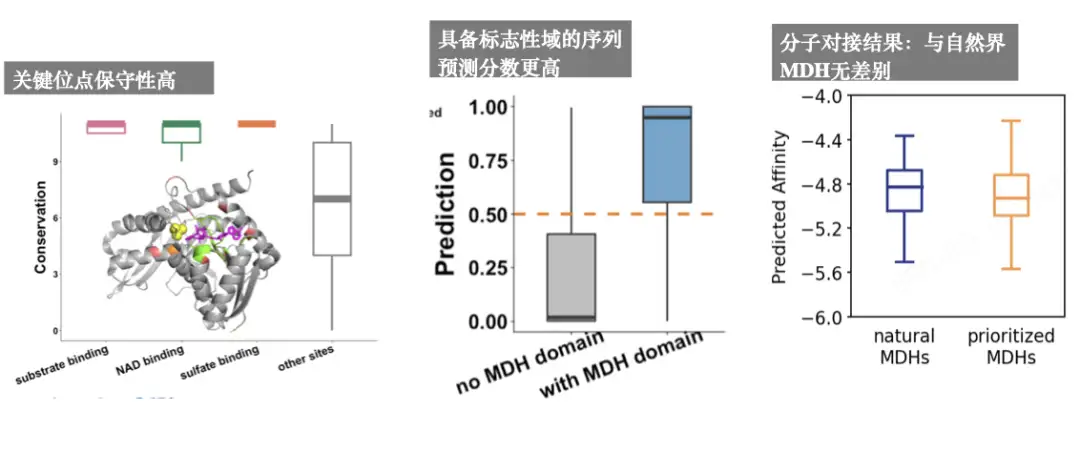
私たちが求めているのは、新しい構造と機能を備えた新しい酵素なので、冗長な配列は必要ありません。予測抗菌ペプチドを通じて、モデルが基本的にうまく機能していることがわかり、その後 MDH 分析を実行して次のことがわかりました。主要な遺跡は高度に保存されています。署名ドメインを持つものの予測スコアは高くなります。分子ドッキングの結果は、基本的に自然界のMDHの結果と同じです。以下に示すように:
次に、モデルに従って生成された異なる酵素が機能するかどうかを検証しました。 ProteinGAN の元のデータに基づくと、類似度が 80% の酵素は、優先順位付けされた MDH モデルを適用した後、類似度が 40% 未満に達する可能性があります。自然界からランダムに選んだ10種類の酵素と比較すると、不溶性、無発現、可溶性という点では基本的に同じですが、それでも非常に優れた酵素活性を持っています。言い換えると、このモデルを使用して当チームが生成した酵素は天然酵素との類似性が低く、そのほとんどが酵素活性を持っています。
ProEnsemble 代謝のボトルネックを特定し、酵素生産を最適化します
生合成プロセスでは、代謝経路における複数の酵素の低い触媒効率や酵素間のエピスタシス効果などの一連の代謝ボトルネックにより、最適化プロセスが複雑で不確実なものになります。経路酵素の過剰発現は細胞の成長や産物の発現に影響を与えることが多く、一部の酵素は悪影響を及ぼす可能性があります。この目的のために、酵素や菌株を最適化するための普遍的で標準化された戦略があるかどうかを尋ねました。
まずは過剰発現が本当に悪いのかどうかを検証してみましょう。研究チームは特定の酵素の発現レベルを人為的に低下させて人工的な代謝ボトルネックを作り出し、制御可能な進化空間を獲得した。
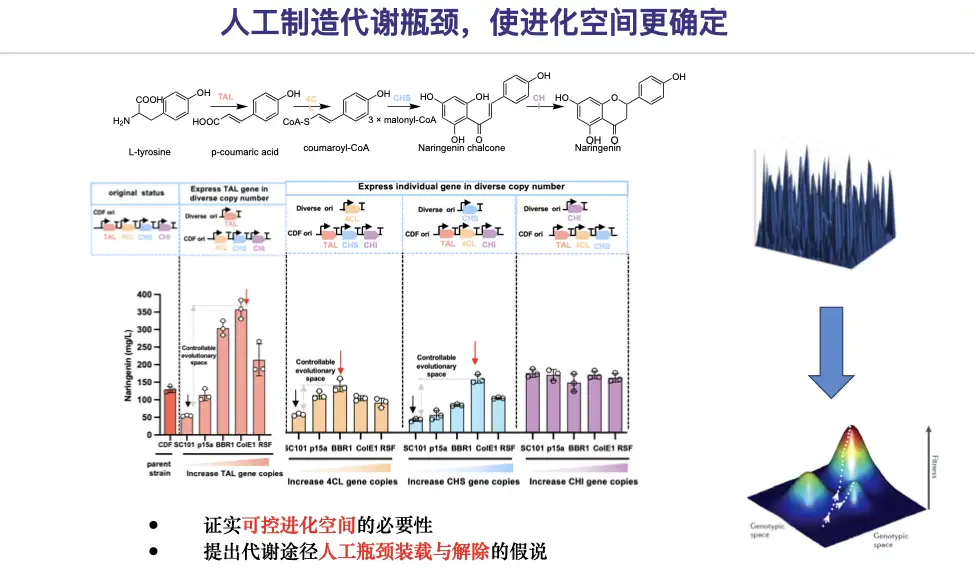
したがって、ナリンゲニンを例にとり、経路のボトルネックの設計と排除戦略の解決策を提案します。
* 第一段階では、自動化大規模施設プラットフォーム技術を用いて、ナリンゲニンの合成に関わる遺伝子を低レベル(低コピー数バックグラウンド)で発現させ、ナリンゲニンの合成における人工的な代謝ボトルネックを構築します。
* 第 2 段階では、候補変異体 4CL-11C1 および CHS-9H9 のナリンゲニン生成が元の変異体と同等であることがスクリーニングされ、ナリンゲニン経路のボトルネックが解消されました。
* 第 3 段階では、AI によるプロモーター エンジニアリングを通じて、単一遺伝子の変異体が元の経路に戻され、代謝フラックスのバランスが取られます。
研究結果は次のことを示しています人工的なボトルネックの作成と除去戦略により、明確な軌道の範囲内で代謝経路を効率的に進化させることができます。また、エピスタシス効果が経路進化の境界を制限する可能性があることも確認されました。
これを基に、指示、クローニング、細菌スクリーニングテストを含む自動化プロセスを設計しました。結果は、成長、ふるい分け、および製品の抽出に関して、手動操作と有意な差がないことを示唆しました。しかし、自動化支援による代謝経路進化法複数酵素の並行進化にかかる時間が大幅に短縮され、1回の並行進化を2週間以内に完了できます。
研究チームは、膨大なデータ蓄積を基に、代謝増加を最適化する機械学習統合モデル「ProEnsemble」を開発しました。実験の結果、機械学習に基づく統合モデルは代謝経路のバランスを取り、最適化されていないモデルと比較してナリンゲニンの生産量を5.16倍に増加させ、96ウェルプレートでは1.21 g/L、発酵槽では3.65 g/Lに達し、報告された最高レベルに達したことが示されました。主要な合成遺伝子を過剰発現させるだけで、さまざまな改変複合シャーシの生成が、文献で報告されているレベルよりも高くなりました(代謝工学戦略の助けを借りて)。
ProEnsembleの学習戦略は、代謝ボトルネックの識別と最適化の閉ループシステムを構築し、業界の現在のレベルよりも数倍高い、高収率のナリンゲニン大腸菌シャーシの開発に成功し、複雑な代謝ネットワークのバランスのための普遍的なソリューションを提供します。
産学連携を促進する大規模自動化プラットフォームの構築
最後に、これらの成果の産業への導入についてご紹介したいと思います。私たちは、中国の深センに、設計学習、合成テスト、ユーザーテストなどの複数のプラットフォームをカバーする大規模な自動化プラットフォームを含む、大規模な完全自動化プラットフォームである合成生物学研究のための主要科学技術施設を構築しました。このプラットフォームは強力な機能を備えており、クラウド上で機械学習のための標準化されたデータ処理と実験設計を実行できます。ロボットは実験操作の完了を支援することができます。スペクトルの準備と検出速度が速く、1つのサンプルをわずか10秒で生成できるため、ハイスループット検出を実現します。
さらに、このプラットフォームは自動化されたソフトウェア設計も提供しており、ユーザーはコンポーネント ライブラリから必要なコンポーネントを直接選択し、実験手順を生成できます。現在、私たちは多くの産業界や学術界と協力しています。当社は、ストレプトマイセス自動化の全プロセスを実現する業界初のプラットフォームです。皆様のご協力をお待ちしております。
羅暁州教授について
羅暁州教授は、中国科学院深圳先進技術研究所の研究者、博士課程指導教員、合成生物学研究所の副所長です。彼は、国家重点人材プロジェクト・青年プロジェクトの選抜専門家であり、国家バイオ製造産業イノベーションセンターの CTO、中国の深圳市合成生物学重点科学技術施設の副主任プロセスエンジニアです。
彼は博士号を取得した。 2016年にスクリプス研究所で化学の博士号を取得(指導教員:ピーター・G・シュルツ会員)、その後カリフォルニア大学バークレー校で博士研究員として研究を修了(共同指導教員:ジェイ・D・キースリング会員)。 2019年、中国科学院深圳先進技術研究所に入所。彼は国家青年人材計画、広東省優秀青年学者、深セン市優秀青年学者に選ばれました。
彼の研究は、酵素の指向性進化、タンパク質工学、ハイスループットスクリーニング、天然および非天然化合物の全生合成など、合成生物学の分野における生体内の生化学的プロセスに焦点を当てています。責任著者として、Nature Metabolism、Advanced Science、Nature Synthesis、Nature Communications、Angew に 20 本の論文を発表しています。化学。内線Ed.等、計50本以上のSCI論文、30件以上の特許出願、6件の認可。








