Command Palette
Search for a command to run...
四川大学華西病院のチームは、医師の診察をシミュレートし、病気の診断を支援するマルチエージェント対話フレームワークを開発した。

希少疾患の有病率は低く、関連する専門知識も不足しています。さらに、個々の症状は複雑かつ多様であるため、誤診や診断の遅れが頻繁に発生します。近年、GPT-4 などの大規模言語モデル (LLM) は、医療に関する質問への回答や一般的な病気の診断では優れたパフォーマンスを発揮していますが、希少疾患などの複雑な臨床タスクでは依然として課題に直面しています。医療分野におけるLLMの実用的応用能力を向上させるために、一部の研究者はマルチエージェントシステム(MAS)の応用を検討し始めています。
インテリジェント エージェントは、特定の目標を達成するために入力を受け取り、特定の操作を実行できるシステムです。たとえば、私たちが自分の健康状態について ChatGPT とコミュニケーションをとるとき、実際には 1 人のエージェントと会話していることになります。対照的に、マルチエージェントシステムは、マルチエージェントダイアログ (MAC) を通じて、より動的でインタラクティブな診断を実現します。このモデルは、臨床現場における多職種チーム (MDT) の議論メカニズムをシミュレートし、複数のエージェントが同じ症例について議論して分析し、合意に達した後に診断結果を出力できるようにします。
最近、四川大学華西病院、華西バイオメディカルビッグデータセンター、浙江大学医学部、北京郵電大学などのチームが参加しました。マルチエージェント対話 (MAC) フレームワークは、それぞれ GPT-3.5 と GPT-4 に基づいて開発されました。このフレームワークは、管理エージェント、スーパーバイザー エージェント、および複数の医師エージェントで構成されており、これらが共同で患者の状態の分析に参加します。 MAC の最適な構成は、GPT-4 をベース モデルとして使用し、4 つのドクター エージェントと 1 つのスーパーバイザー エージェントで構成することです。
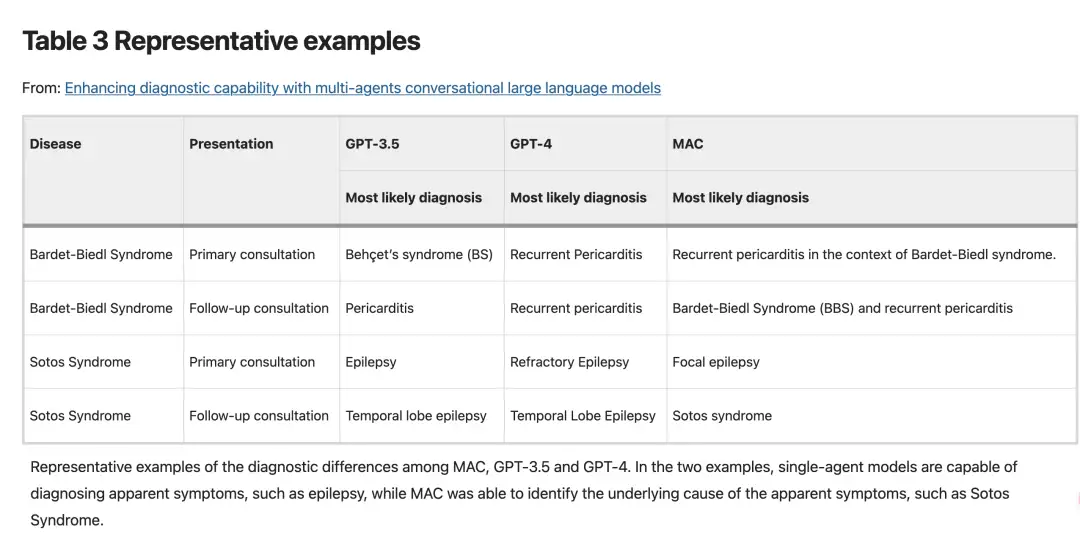
302 種類の希少疾患に対する臨床推論と医学知識生成における GPT-3.5、GPT-4、および MAC のパフォーマンス評価が利用可能です。MAC は、初期段階とフォローアップ段階の両方で単一エージェント モデルよりも優れたパフォーマンスを発揮しました。さらに、MAC の診断機能は、Chain of Thought (CoT) プロンプト、Self-Refine、Self-Consistency などの方法を超えています。より豊富な診断コンテンツを出力できます。たとえば、GPT-3.5 と GPT-4 は臨床症状に基づいて心膜炎とてんかんを識別できますが、MAC は共同対話のより詳細な分析を通じて、特定の症例の心膜炎がバルデット・ビードル症候群によって引き起こされたことを判断できます。
結論として、MAC は LLM の診断能力を大幅に向上させ、理論的知識と臨床実践の間のギャップを埋め、医師にとって重要な補助ツールになることが期待されます。「マルチエージェント会話型大規模言語モデルによる診断能力の強化」と題されたこの研究は、ネイチャー誌のnpj Digital Medicineに掲載された。

用紙のアドレス:
https://www.nature.com/articles/s41746-025-01550-0#Tab6
オープンソース プロジェクト「awesome-ai4s」は、200 を超える AI4S 論文の解釈をまとめ、膨大なデータ セットとツールを提供します。
https://github.com/hyperai/awesome-ai4s
データセット: 302 種類の希少疾患のスクリーニング
この研究では、Orphanet データベースから 302 の希少疾患を研究対象として選別しました。 Orphanet データベースは、欧州委員会が共同出資する包括的な希少疾患データベースであり、33 種類の 7,000 を超える疾患を網羅しています。
希少疾患症例 302 件のデータセットをダウンロード:
https://go.hyper.ai/EETet
研究チームは対象疾患を特定した後、2022年1月以降に発表された臨床症例報告をMedlineデータベースで検索しました。これらの症例報告から構造化データを抽出することで、患者の人口統計学的特徴、臨床症状、病歴、身体検査結果、各種補助検査結果(遺伝子検査、病理組織検査、放射線学的検査を含む)に関する詳細な情報を収集し、最終的な診断情報を記録しました。
臨床現場における大規模言語モデル(LLM)の応用価値を総合的に評価するために、研究チームは2段階の臨床相談シミュレーション実験を設計し、各ケースを初回相談とフォローアップ相談の環境でテストしました。
* 第一段階では、初回診察のシナリオ(初回訪問)をシミュレートします。主な目的は、初めて受診し、臨床情報が限られている患者における LLM のパフォーマンスを調査することです。 LLM の任務は、最も可能性の高い診断、いくつかの可能性のある診断、およびさらなる診断に到達することです。
* 第 2 段階では、フォローアップ相談シナリオ (再検査) をシミュレートします。完全な患者情報(各種検査結果を含む)を入手した後、LLMの診断能力を評価する。 LLM の任務は、最も可能性の高い 1 つの診断といくつかの可能性のある診断に到達することです。
この段階的な研究設計により、不完全な情報条件下での LLM の初期判断能力をテストできるだけでなく、臨床データを完全に習得した後の医学的推論と最終的な診断精度を体系的に評価できるため、臨床意思決定支援における LLM の実用的応用可能性を総合的に反映できます。

GPT-4をベースにした4人のドクターエージェントを備えたMACフレームワークが最も優れたパフォーマンスを発揮した。
研究チームは、Autogen が提供する構造を使用して、GPT-3.5-turbo と GPT-4 に基づく 2 つのマルチエージェント会話フレームワーク (MAC) を開発し、医師の診察をシミュレートしました。下の図に示すように、管理エージェントが患者情報を提供し、スーパーバイザーエージェントが共同会話を開始して監督し、3 人の医師エージェントが患者の状態について一緒に話し合います。エージェントが合意に達するか、事前に設定された最大対話ラウンド数(本研究では13ラウンドに設定)に達するまで対話は継続され、最終的な診断結果が出力されます。
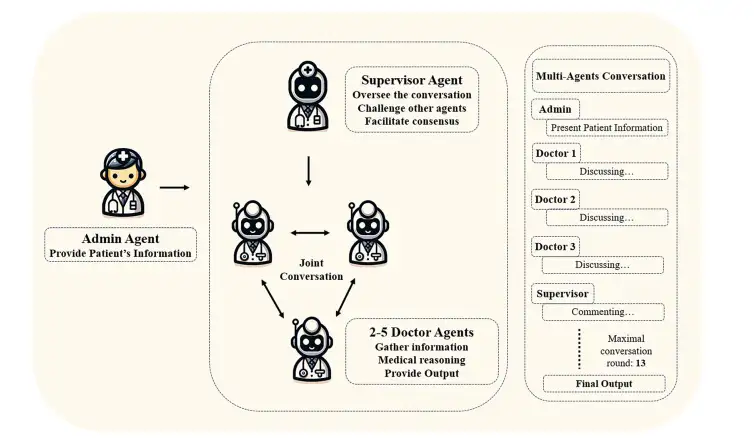
スーパーバイザーエージェントは、品質管理とプロセス最適化の役割を果たします。その責任には以下が含まれます。(1) ドクターエージェントによる勧告や決定を監督し評価すること。 (2)診断計画と提案された検査項目を検討し、見落とされる可能性のある重要な点を特定する。 (3)医師エージェント間の協議を調整し、診断計画の改善を促進すること。 (4)医師代理人による最終診断・検査計画の合意形成を推進する。 (5)合意に達した後、適時に対話プロセスを終了すること。
ドクターエージェントの責任には以下が含まれます:(1)専門的な医学的知識に基づいた診断推論および臨床アドバイスを提供すること。 (2)他のエージェントの意見を体系的に評価し、コメントし、科学的かつ合理的な議論と証拠を提示する。 (3)他のエージェントからのフィードバックを統合・最適化し、診断出力を継続的に改善する。
研究者らは、Medline データベースの実際の臨床症例報告を使用して、302 の希少疾患に対する GPT-3.5、GPT-4、および MAC の知識と診断能力を評価しました。さらに、さまざまな設定が MAC パフォーマンスに与える影響についても調査します。
たとえば、研究チームは、MAC フレームワークが GPT-4 と GPT-3.5 をベースモデルとして使用した場合のパフォーマンスの違いを比較しました。結果は、GPT-3.5 または GPT-4 をベースモデルとして使用する MAC が、それぞれの独立したバージョンよりも大幅に優れたパフォーマンスを発揮することを示しています。つまり、MAC の診断能力は単剤モデルに比べて大幅に向上します。さらに、MAC の基本モデルとして使用した場合、GPT-4 は GPT-3.5 よりも優れたパフォーマンスを発揮することが示されており、より強力な基本モデルを使用すると全体的なパフォーマンスが向上する可能性があることが示唆されています。
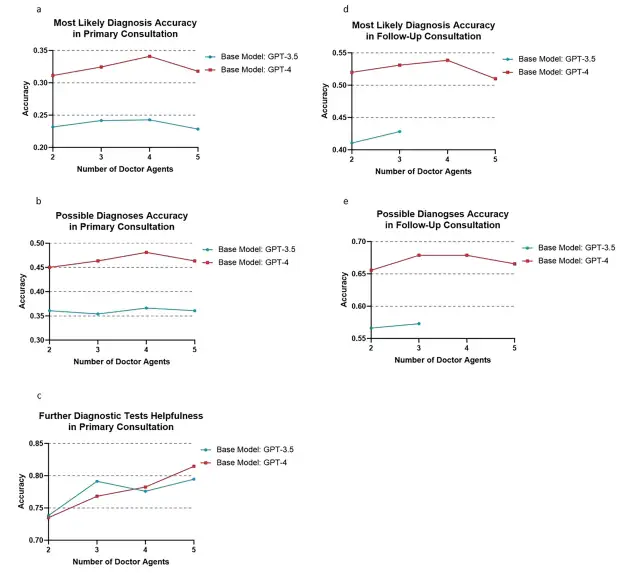
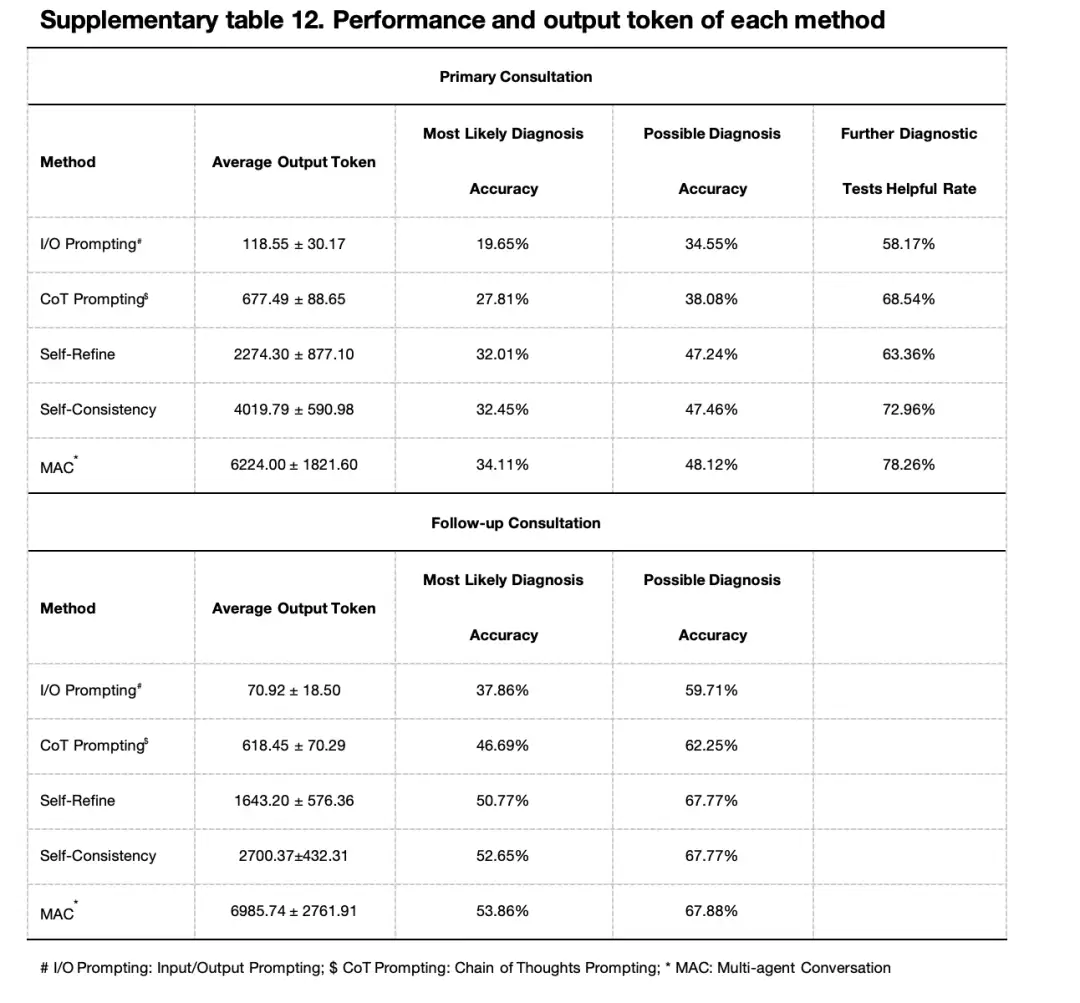
また、研究者らは、ドクターエージェントの数がマルチエージェントフレームワークのパフォーマンスに与える影響についても研究しました。GPT-4 モデルに基づく実験結果では、最も可能性の高い診断精度は 4 つのエージェントで 34.11% のピークに達し、5 つのエージェントでは 31.79% にわずかに低下することが示されました。可能性のある診断の精度でも同様のパターンが見られ、エージェント 2、3、4、5 の精度はそれぞれ 51.99%、53.31%、53.86%、50.99% でした。 GPT-3.5 モデルに基づく実験でも、4 つのドクターエージェントが最高のパフォーマンスを示しました。ただし、全体的には、3 つのエージェントのパフォーマンスは 4 つのエージェントのパフォーマンスとそれほど変わりません。
さらに、4人のドクターエージェントが参加する事前相談のシミュレーションでは、GPT-4 に基づく MAC フレームワークは、多くの主要指標で優れたパフォーマンスを達成しました。最も可能性の高い診断の精度は 34.11% (GPT-3.5 は 24.28%) に達し、可能性のある診断の精度は 48.12% (GPT-3.5 は 36.64%) に達し、さらなる診断テストの有用性は 78.26% (GPT-3.5 は 77.37%) に達しました。フォローアップ診察における診断パフォーマンスの点でも、4 人のドクターエージェントが参加した GPT-4 ベースの MAC フレームワークが最高のパフォーマンスを発揮しました。
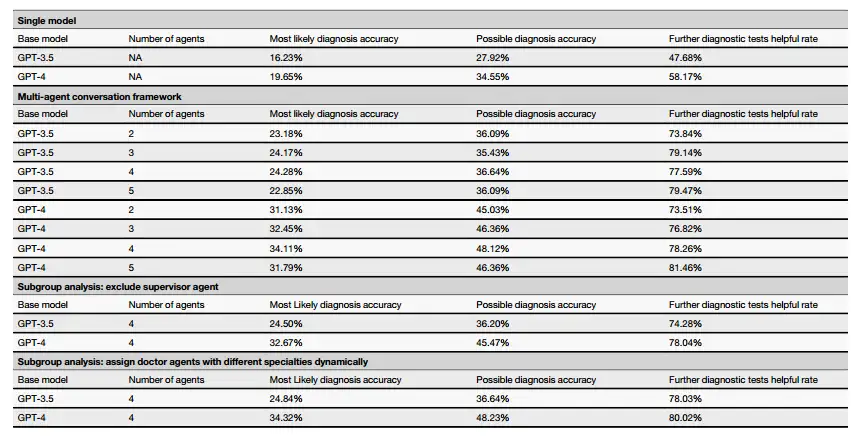
研究者らは、スーパーバイザー エージェントを削除した場合の MAC の全体的なパフォーマンスへの潜在的な影響も評価しました。結果は、スーパーバイザーエージェントが削除されると、4人のドクターエージェントでシミュレートされた最初の相談シナリオで、GPT-4 に基づく MAC フレームワークのデータは、最も可能性の高い診断精度、可能性のある診断精度、およびさらなる診断テストの有用性に関して、それぞれ 32.67%、45.47%、および 78.04% であり、いずれも削除していない場合よりも低くなっています。フォローアップ相談シナリオでは、スーパーバイザー エージェントを削除した MAC フレームワークでは、削除しなかった場合よりも、最も可能性の高い診断精度と可能性のある診断精度が低下しました。これは、スーパーバイザー エージェントがフレームワークの有効性を向上させることを示しています。
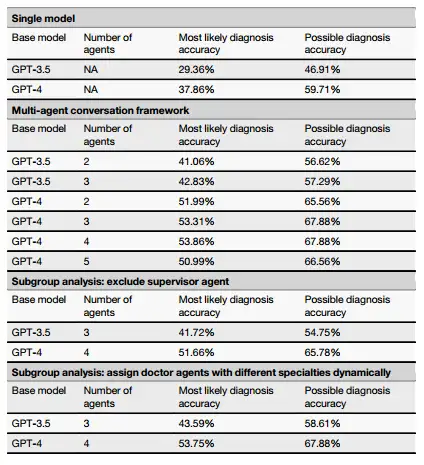
実験的結論:MACは病気の根本原因を直接特定でき、より強力な診断能力を持つ
研究チームは、疾患の定義、疫学、臨床的特徴、病因、診断方法、鑑別診断、出生前診断、遺伝カウンセリング、治療管理、予後など、希少疾患に関する知識の生成におけるGPT-3.5、GPT-4、MACフレームワークのパフォーマンスを評価しました。結果は、これらのモデルがすべての評価次元で優れたパフォーマンスを発揮し、下の図に示すように、各指標のスコアが 4 ポイントを超えていることを示しています。また、これらは、コンテンツの正確性(不適切/不正確なコンテンツ)、情報の完全性(省略)、安全性(起こり得る危害の可能性と大きさ)、客観性(偏り)において高いレベルを示しました。
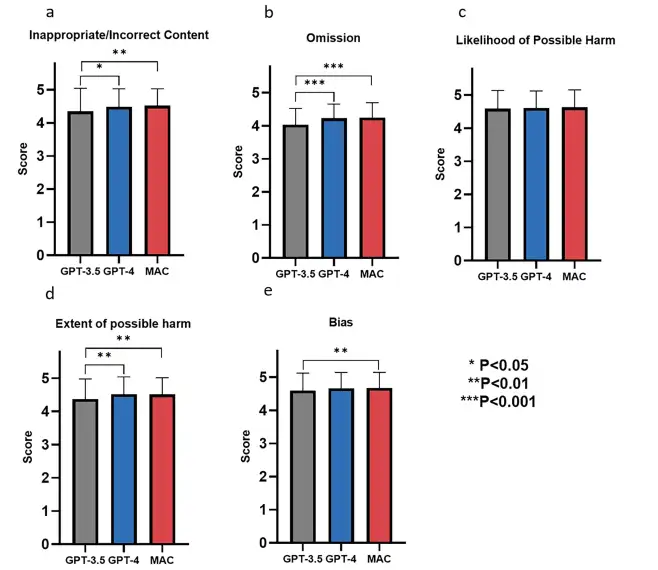
具体的なケースの病気の診断では、下の図に示すように、GPT-3.5 と GPT-4 は臨床症状から心膜炎やてんかんを特定するなど、明らかな症状に基づいて病気を診断できましたが、病気の根本的な原因を探るには不十分であることが研究者によって判明しました。対照的に、MAC フレームワークは共同対話を通じてより詳細な分析を提供し、特定の症例における心膜炎がバルデット・ビードル症候群によって引き起こされたことを判断できます。
研究者らは、MAC を入力/出力 (I/O) キュー、思考連鎖キュー (CoT)、自己最適化、自己一貫性法と比較しました。下の図に示すように、初回診察とフォローアップ診察の両方において、MAC は最も可能性の高い診断、可能性のある診断、およびさらなる診断検査の有効性の点で最も優れた成績を収めました。
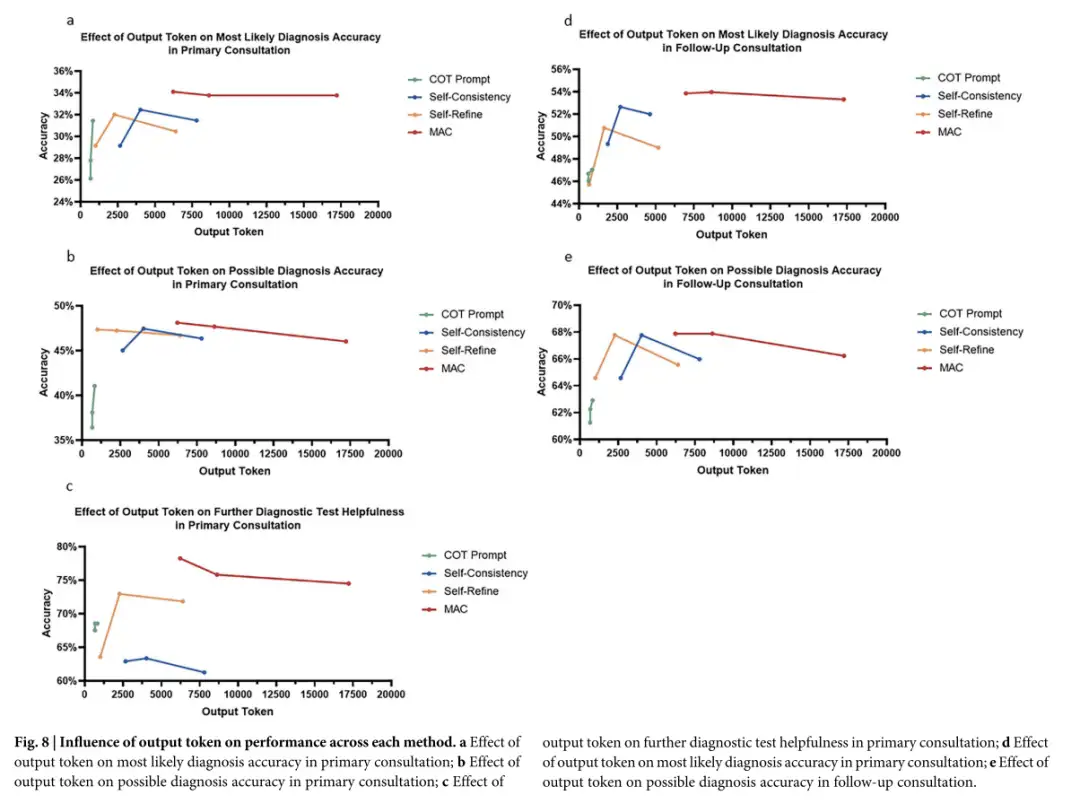
さらに、MAC はより多くのトークンを出力します。出力の増加は、さまざまな推論パスの探索に役立つだけでなく、以前の出力を振り返って修正することも可能になり、分析の深さが増し、無視されている病気の根本原因を特定する能力が向上します。しかし、研究によれば、LLM 呼び出しの数を増やしてより多くのトークンを生成すると MAC パフォーマンスが向上しますが、この改善の程度はタスクの種類と使用される改良方法によって制限されます。
要約すると、本研究では、疾患診断のためのマルチエージェント対話フレームワーク(MAC)の開発に成功しました。このフレームワークは、臨床相談のさまざまな段階で貴重な診断提案を提供し、さらなる診断を推奨することができ、あらゆる種類の希少疾患に適用できます。さらに、思考連鎖(CoT)、自己最適化、自己一貫性などの既存の方法と比較して、MAC は診断精度が高いだけでなく、より豊富で包括的な診断コンテンツも生成します。このフレームワークにより、大規模言語モデルの臨床診断機能が大幅に向上します。
マルチエージェントシステムは医療分野で大きな応用可能性を秘めている
近年、マルチエージェントシステムは医療上の意思決定と診断の分野で有望な進歩を示しています。いくつかの重要なフレームワークが登場し、大規模な言語モデルを活用して臨床タスクを実行するためのさまざまな戦略を採用しています。例えば、上海交通大学は、医療分野向けの学際的なコラボレーションフレームワークである MedAgents を提案しました。このフレームワークにより、LLM ベースのエージェントはロールプレイング環境で複数回の共同ディスカッションを実施できるようになり、ゼロサンプルの医療質問応答における LLM のパフォーマンスが大幅に向上します。この研究は「MedAgents: ゼロショット医療推論のための協力者としての大規模言語モデル」というタイトルでarXivに掲載されました。
用紙のアドレス:
https://arxiv.org/abs/2311.10537
MedAgentsや他の医療に関する質問と回答に焦点を当てたプラットフォームとは異なり、MAC フレームワークは診断タスクに重点を置いており、複数のエージェントが同じ臨床コンテキストで分析し、対話的に議論し、オープンエンドの診断提案を提供するように促します。インテリジェント エージェントのアーキテクチャ設計に関して言えば、MAC には複数のドクター エージェントとスーパーバイザー エージェントが含まれますが、他のフレームワークでは、質問と回答に別々のエージェントを作成するなど、異なる設定が採用されています。フレームワークは合意に達する方法も異なります。たとえば、MedAgent は、すべての専門家が合意に達するまで反復的な修正を通じて回答を継続的に改善しますが、MAC は、Doctor Agent が十分な合意に達したときに Supervisor Agent によって決定されます。
これらのマルチエージェントシステムは、構成や目的において独自の特徴を持っていますが、医療分野への応用に大きな可能性を秘めており、臨床環境における実際の役割を十分に探求し最適化するためには、今後もさらなる研究が必要です。
前述のマルチエージェント対話フレームワークの研究チームは、生成型人工知能と臨床医学の交差点における最先端の探究に重点を置いています。豊富な臨床データリソースと高度なコンピューティングハードウェア設備を備えており、その研究成果は国際的な高水準の学術雑誌に掲載されています。
チームは、人工知能技術の実用化と、臨床医学診断および治療モデルとエコシステムの真の変革に取り組んでいます。学術機関および企業の皆様に、プロジェクト協力を心からお願い申しあげます。この分野に興味のある優秀な大学院生の応募を歓迎します。同時に、チームに加わる熱意ある科学研究アシスタントを募集しています。ご興味のある方は [email protected] までご連絡ください。








