Command Palette
Search for a command to run...
安定した仮想カメラは 3D コンテンツ生成を再定義し、画像の新しい次元を実現します。 BatteryLifeはバッテリー寿命をより正確に予測するのに役立ちます

デジタルコンテンツ制作の熾烈な競争の中で、Stability AI は運命の岐路に立っています。かつて「安定拡散」で画像生成に革命を起こしたこの会社は、上層部のトラブルにより危機に陥った。最近、Stability AI は Stable Virtual Camera モデルをリリースしました。強力な一撃で膠着状態を打破できるだろうか。
安定した仮想カメラはマルチビュー拡散モデルであるは、従来の仮想カメラの制御機能と生成 AI の創造性を組み合わせたものです。この技術は、複雑なシーンの再構築や専門的なスキルを必要とせずに、通常の 2D 画像をリアルな奥行きと遠近感を持つ 3D ビデオに変換します。
従来の3Dビデオモデルと比較して、このモデルでは、大量の入力画像や複雑な前処理手順は必要ないため、3D コンテンツの生成がはるかにシンプルかつ実現可能になります。このテクノロジーは Novel View Synthesis (NVS) ベンチマークでも優れたパフォーマンスを発揮します。パフォーマンスは既存のモデルを上回ります。
現在、HyperAI Super Neuralはオンラインです 「安定したバーチャルカメラ画像が数秒で3D動画に変換されます」チュートリアル、ぜひ試してみてください〜
オンラインでの使用:https://go.hyper.ai/N2u9l
3月24日から3月28日まで、hyper.ai公式サイトが更新されます。
* 高品質の公開データセット: 10
* 高品質なチュートリアルのセレクション: 3
* コミュニティ記事の選択: 3 記事
* 人気のある百科事典のエントリ: 5
* 4月に締め切りを迎えるトップカンファレンス: 10
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
このデータセットには、17,966 人のキャラクターと 29,798 件の実際の会話が含まれています。キャラクターの概要や会話だけでなく、プロットの要約、キャラクターの経験、会話の背景などの豊富なコンテンツも提供されます。さらに、セリフ内容は言語、行動、思考の3つの次元をカバーし、キャラクターのパフォーマンスをより立体的にします。
直接使用します:https://go.hyper.ai/1WbXV

MV-MATH データセットには、複数選択問題、空欄補充問題、複数ステップ問題の 3 つのタイプに分かれた 2,009 個の高品質な数学問題が含まれています。データセットには複数の視覚シーンが含まれており、各質問には 2 ~ 8 枚の画像が用意されています。これらの画像はテキストと絡み合って複雑なマルチビジュアルシーンを形成します。これは現実世界の数学的問題に近いものであり、マルチビジュアル情報を処理するモデルの推論能力を効果的に評価できます。
直接使用します:https://go.hyper.ai/tRQsA
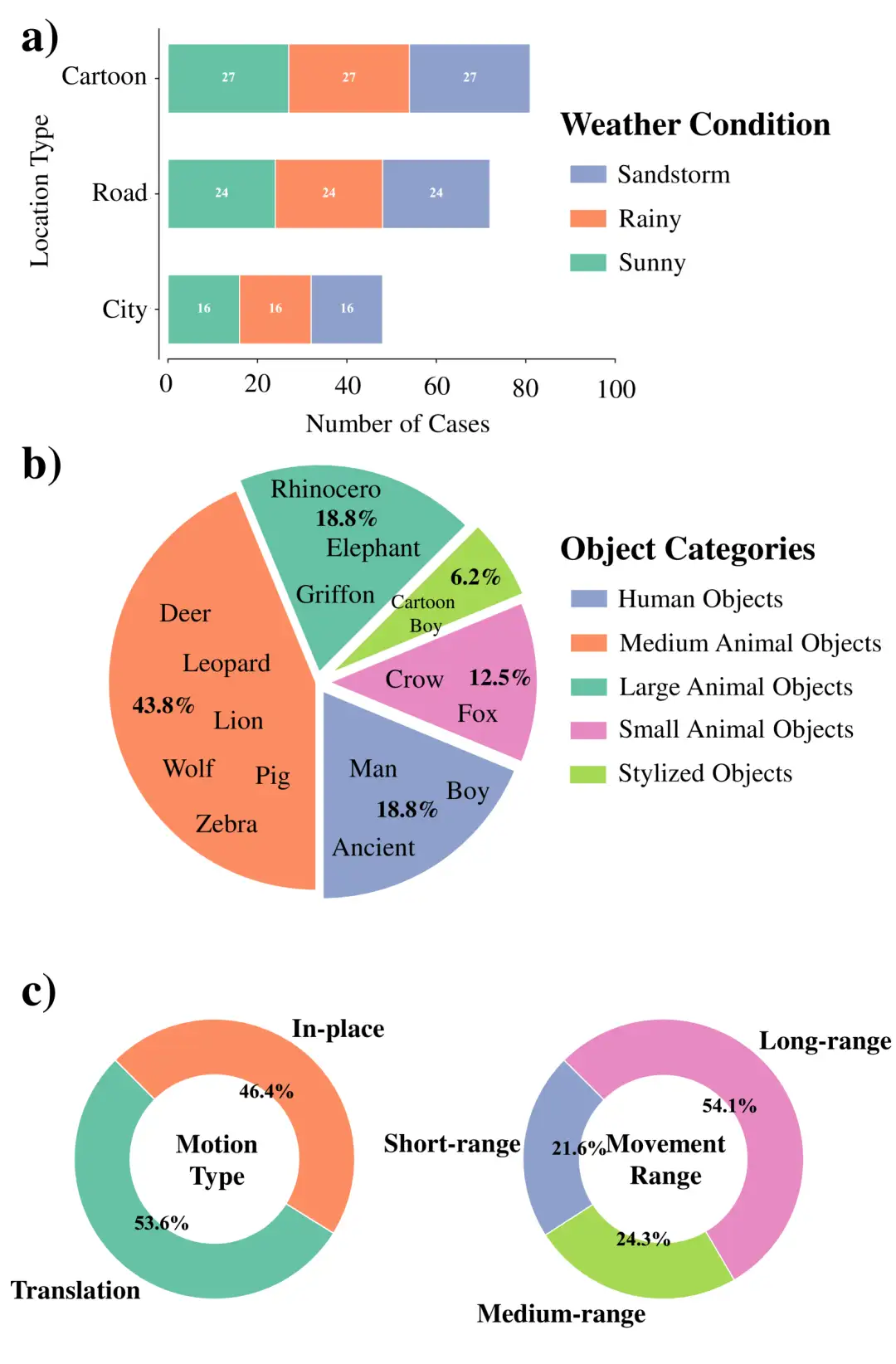
3. WideRange4D マルチビューシーンデータセット
このデータセットは、広範囲の空間モーションを持つ 4D シーン データを導入することで、複雑な動的シーンにおける既存の 4D 再構築データセットのギャップを埋めます。シーンの豊かさ、動きの複雑さ、環境の多様性に優れており、現実世界のシーン (市街地の道路、田舎道など) や仮想シーンを含み、短距離、中距離、長距離の動き、複雑な動きの軌跡をカバーし、晴れの日、雨の日、砂嵐などのさまざまな気象条件もシミュレートします。
直接使用します:https://go.hyper.ai/9KszI
4. TacQuad マルチモーダル マルチセンサー触覚データセット
TacQuad は、4 種類の視覚触覚センサー (GelSight Mini、DIGIT、DuraGel、Tac3D) から収集された、整列されたマルチモーダル マルチセンサー触覚データセットです。テキストと視覚画像を含むマルチセンサーアライメントデータを提供することで、視覚触覚センサーの標準化の低さに対するより包括的なソリューションを提供します。これにより、モデルは意味レベルの触覚属性とセンサーに依存しない機能を明示的に学習できるようになり、データ駆動型アプローチを通じて統一されたマルチセンサー表現空間を形成できるようになります。
直接使用します:https://go.hyper.ai/uL0Zd

このデータセットは、GTC25 カンファレンスで NVIDIA がリリースした物理 AI データセットです。これには、15 TB のデータ、ロボット トレーニング用の 320,000 を超える軌跡、SimReady コレクションを含む最大 1,000 の一般的なシーン記述 (OpenUSD) アセットが含まれており、さまざまな種類の道路や地理的環境、さまざまなインフラストラクチャ、さまざまな気象環境をカバーしています。
直接使用します:https://go.hyper.ai/LEHa5

Skyview は、合計 12,000 枚の画像、15 の異なるカテゴリを含む、航空風景分類用の厳選されたデータセットです。各カテゴリには、解像度 256×256 ピクセルの 800 枚の高品質画像が含まれています。このデータセットは、公開されている AID データセットと NWPU-Resisc45 データセットの画像を融合したものです。この編集は、コンピューター ビジョンの分野、特に航空景観分析における研究開発を促進することを目的としています。
直接使用します:https://go.hyper.ai/mne9z

このデータセットは、運転事故推論タスク用に特別に設計された最初のデータセットであり、高度なビデオ生成および強化技術を活用して MM-AU データセットを拡張します。このデータセットには、事故の理解と防止のためのより豊富で多様なトレーニング データを提供することを目的として、事前トレーニング済みの Open-Sora 1.2 モデルを微調整して生成された、新たに生成された 2,000 本の詳細な事故現場ビデオが含まれています。
直接使用します:https://go.hyper.ai/gy0mb
8. BatteryLife バッテリー寿命予測データセット
このデータセットはもともと、バッテリー寿命予測の研究をサポートするために作成されました。 16 種類の異なるデータセットを統合し、998 個のバッテリーから 90,000 個を超えるサンプルを提供し、すべてに寿命ラベルが付いています。 BatteryLife データセットは、これまでの最大のバッテリー寿命リソースである BatteryML の 2.4 倍の大きさです。
直接使用します:https://go.hyper.ai/0PzfZ
9. VenusMutHub タンパク質変異小規模サンプルデータセット
VenusMutHub は、実際の応用シナリオ向けのタンパク質変異の小規模サンプルデータセットとしては初となるものです。研究チームは、実際の応用シナリオ向けに 905 件の小規模サンプル実験変異データセットを慎重に編集し、527 個のタンパク質 (うち 981 個の TP3T タンパク質には 5 ~ 200 件の変異があります) をカバーし、安定性、活性、結合親和性、選択性など、さまざまな機能測定データをカバーしています。すべてのデータは、代替の蛍光読み取りではなく直接的な生化学測定を使用して取得され、評価の正確性が保証されています。
直接使用します:https://go.hyper.ai/8y20R
このデータセットには、動いている鳥やドローンを表す、Pexel ウェブサイトからの多様な画像コレクションが含まれています。画像はビデオ フレームからキャプチャされ、セグメント化、拡張、前処理されてさまざまな環境条件をシミュレートし、モデルのトレーニング プロセスを強化します。
直接使用します:https://go.hyper.ai/RdN4d
選択された公開チュートリアル
コンピューター ビジョンの分野では、画像のかすみ除去は、特に自動運転、リモート センシング画像分析、監視システムにおいて重要な前処理タスクです。かすみ除去により、画像の品質が効果的に向上し、対象物をより鮮明に見ることができます。
このプロジェクトでは、画像のかすみ除去に Retinex アルゴリズムを使用し、これを GPU アクセラレーションと組み合わせて計算効率を向上させます。チュートリアルに従って関連コードを入力し、画像のかすみ除去プロセスを完了します。
オンラインで実行:https://go.hyper.ai/wu1fE
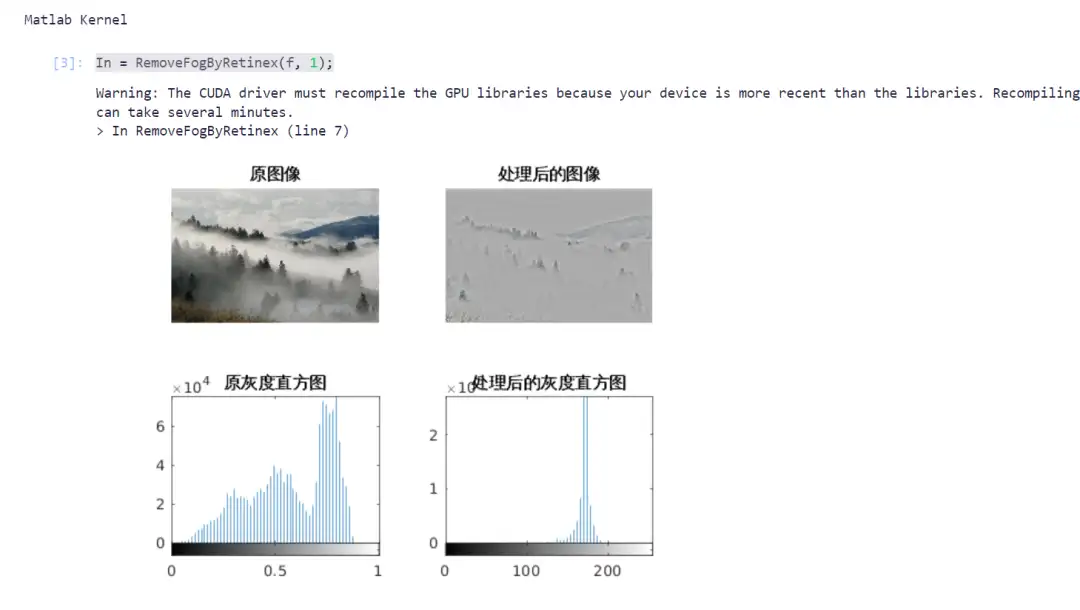
2. 安定したバーチャルカメラが画像を数秒で3D動画に変換します
Stable Virtual Camera (略して Seva) は、2025 年 3 月に Stability AI によってリリースされた汎用拡散モデルです。Seva は、任意の数の入力ビューとターゲット カメラを指定して、シーンの新しいビューを生成できます。その設計は、特定のタスク構成に依存せずに、視点の変化が大きいサンプルや時間的に滑らかなサンプルを生成する際の既存の方法の制限を克服します。
このモデルの注目すべき特徴は、追加の 3D 表現学習を必要とせずに非常に一貫性のあるサンプル生成を維持できるため、実際のアプリケーションでの遠近法合成プロセスが簡素化されることです。さらに、Seva は最長 30 秒の高品質ビデオを生成し、シームレスにループさせることができます。広範なベンチマーク テストにより、Seva はさまざまなデータセットと設定で既存の方法よりも優れていることが示されています。
このプロジェクトの関連モデルと依存関係がデプロイされました。コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります。
オンラインで実行:https://go.hyper.ai/N2u9l

3. オンラインチュートリアル | CSM が来ました。どいてください!より鮮明な音声生成、遅延、鈍い、機械的な音声の排除
Sesame チームが発表した音声生成モデル CSM (Conversational Speech Model) は、テキストと音声入力に基づいて流暢で自然、かつ感情的な音声を出力できます。従来の AI 音声生成モデルと比較すると、CSM は感情理解能力が強く、会話のリズムがより自然で、遅延がほぼゼロのリアルタイムインタラクションが可能で、ドローン感覚がありません。
オンラインで実行:https://go.hyper.ai/bxOoN
注目のコミュニティ記事
1. 若手皮膚科医に比べて、正確率がはるかに高い。北京大学国際病院などがニキビ病変の検出と分類を実現するディープラーニングアルゴリズムを開発した。
北京大学国際病院チームが開発したAcneDGNetディープラーニングアルゴリズムは、ニキビ病変を正確に識別し、その重症度を自動的に判断することができ、その診断精度は上級皮膚科医に匹敵します。オンライン診療とオフライン診療を強力にサポートし、ニキビのより効率的な管理をサポートします。この記事は、研究の詳細な解釈と共有です。
レポート全体を表示します。https://go.hyper.ai/qAjYK
ケンブリッジ大学の研究チームは、AlphaFold-Metainferenceと呼ばれる手法を提案しました。この手法は、AlphaFoldによって予測されたアライメント誤差マップと分子動力学シミュレーションの距離変化行列との相関関係を利用して、無秩序なタンパク質と無秩序な領域を含むタンパク質の構造コレクションを構築し、ディープラーニング手法に基づく無秩序なタンパク質構造の予測に新たなアイデアを提供し、AlphaFoldの適用範囲をさらに広げます。この記事は、研究の詳細な解釈と共有です。
レポート全体を表示します。https://go.hyper.ai/6Bbhc
3. 精度向上 5.2%、NVIDIAなどが3D画像の自動セグメンテーションとインタラクションを実現するマルチモーダル医療画像セグメンテーションモデルをリリース
研究によると、医療画像を長時間扱う専門家の視覚疲労により、12% もの境界エラーが発生する可能性があることがわかっています。この問題を解決するために、NVIDIA は最近他の研究チームと協力して、VISTA3D マルチモーダル医療画像セグメンテーション モデルを提案しました。このモデルは、3次元スーパーボクセル特徴抽出法の先駆者であり、統一されたアーキテクチャを通じて3次元自動セグメンテーションとインタラクティブセグメンテーションの協調的最適化を実現しました。 23 のデータ セットを含む包括的なベンチマーク テストでは、既存の最適なエキスパート モデルと比較して、セグメンテーション精度が 5.2% 向上しました。関連する結果は arXiv にプレプリントとして公開されています。この記事は、研究の詳細な解釈と共有です。
レポート全体を表示します。https://go.hyper.ai/D19LU
人気のある百科事典の項目を厳選
1.ダルイー
2. 相互ソーティング融合 RRF
3. パレートフロント パレートフロント
4. 大規模マルチタスク言語理解MMLU
5. 対照学習
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。

主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!








