Command Palette
Search for a command to run...
5.2%で精度が向上、NVIDIAらが3D画像の自動セグメンテーションとインタラクションを実現するマルチモーダル医療画像セグメンテーションモデルをリリース
1971 年に最初の臨床用 CT スキャナーが誕生して以来、医療用画像処理は 2 次元スライスから 3 次元ステレオへと革命的な進歩を遂げてきました。最新の 256 列スパイラル CT は、0.16 mm の層厚の全身スキャン データを 0.28 秒で収集でき、7T 超高磁場磁気共鳴画像法では、海馬の神経線維の微細な方向まで捉えることができます。しかし、数千万のボクセルを含むこれらの 3 次元マトリックスが医師に提示された場合、臓器、病変、血管網を正確にセグメント化する作業は、依然として手動で層ごとにアウトラインを作成することに大きく依存しています。研究によると、典型的な腹部 CT 画像セットの肝臓セグメンテーションには 45 ~ 90 分かかりますが、多臓器連携を含む放射線治療計画の注釈には 8 時間以上かかる場合があります。専門家の視覚疲労による境界エラー率は 12% に達することがあります。
このジレンマにより、医療画像解析の分野で最も活発なイノベーションの道が生まれました。初期のグレースケールしきい値ベースの領域拡張アルゴリズムから、ディープラーニングを統合した U-Net の 3 次元バリアント V-Net、ビジュアル Transformer を導入した TransUNet ハイブリッド アーキテクチャに至るまで、アルゴリズム エンジニアはピクセル迷路内でインテリジェントなナビゲーション システムを構築しようと絶えず取り組んできました。 2024 MICCAI カンファレンスの最新のブレークスルーでは、一部のモデルが前立腺セグメンテーションタスクにおいて経験豊富な放射線科医に匹敵するグループ間の一貫性を達成したことが示されましたが、まれな解剖学的変異のケースではパフォーマンスが依然として大きく変動しています。これは、より深い技術的哲学的命題を明らかにします。AI が人体を理解しようとするとき、どの程度の事前知識が必要であり、人間の認知を超えた解剖学的洞察をどの程度生成できるのでしょうか。
最近、NVIDIA、アーカンソー大学医学部、国立衛生研究所、オックスフォード大学からなる学際的なチームが、画期的な研究成果である VISTA3D マルチモーダル医療画像セグメンテーション モデルを発表しました。このモデルは、3D スーパーボクセル特徴抽出法の先駆者となりました。統一されたアーキテクチャを通じて、3D 自動セグメンテーション (127 の解剖学的構造をカバー) とインタラクティブ セグメンテーションの協調的な最適化を実現します。 14 のデータセットを含む包括的なベンチマーク テストでは、最先端の 3D ヒント付き自動セグメンテーションとインタラクティブ編集を実現し、ゼロ サンプル パフォーマンスを 50% 向上しました。
関連する研究結果は「VISTA3D: 3D 医療画像のための統合シーメンテーション基盤モデル」と題され、arXiv でプレプリントとして公開されています。

用紙のアドレス:
https://doi.org/10.48550/arxiv.2406.05285
3D医療画像技術におけるパラダイムシフトと課題
医療画像解析のデジタル化の波の中で、3D自動セグメンテーション技術は「専門医」から「総合診療医」へとパラダイムシフトを遂げています。従来の方法では、専用のネットワーク アーキテクチャとカスタマイズされたトレーニング戦略を構築して、解剖学的構造や病理の種類ごとに独立したエキスパート モデルを作成します。このモデルは特定のタスクでは優れたパフォーマンスを発揮しますが、放射線科医に単一臓器の診断トレーニングを繰り返し受けるよう要求するようなものです。127 個の解剖学的構造を含む全身 CT スキャンを扱う場合、システムは数十のモデルを並行して実行する必要があり、コンピューティング リソースの消費と結果の統合の複雑さは飛躍的に増大します。
さらに重要なことに、臨床現場で医師を本当に悩ませるのは、標準的な解剖学的アトラスを破る稀な症例であることが多い。実験用マウスの肝臓で新たに発見されたナノスケールの石灰化病巣や、移植患者の解剖学的変異により形成された通常とは異なる血管の形状などである。これらのシナリオは、既存のシステムの根本的な欠陥を明らかにしています。事前設定されたカテゴリとクローズドトレーニングに過度に依存すると、モデルがゼロサンプルを学習してオープンドメインに適応することが難しくなります。
このジレンマを打開する糸口は、自然画像処理の分野から生まれました。大規模な言語モデルがタスク全体にわたって驚くべき一般化能力を発揮すると、医療画像処理コミュニティは「会話型」インテリジェント システムの構築を模索し始めました。 Meta が提案する SAM (Segment Anything Model) は、2 次元画像で「クリックしてセグメント化」という革新的なインタラクションを実現し、そのゼロサンプル パフォーマンスは一部のプロフェッショナル モデルを上回ります。しかし、このパラダイムを 3 次元医療の分野に移行すると、単純な次元拡張では根本的な課題に遭遇します。連続断層撮影スキャンにおける人間の臓器の位相的な複雑さは、ビデオ内の移動車両の複雑さとは比べものにならないほどです。
肝臓のセグメンテーションを例にとると、門脈の分岐、腫瘍の浸潤、手術用クリップの金属アーチファクトが隣接するスライス間に同時に存在する可能性があるため、モデルには単純な時系列追跡ではなく、真の 3 次元空間推論機能が必要です。これまで、研究者たちは SAM アーキテクチャを 3 次元化しようと試み、SAM2 および SAM3D システムを形成してきました。血管追跡などのタスクでは進歩が見られましたが、ただし、ダイス係数はプロモデルよりも 9 ~ 15 パーセントポイント低くなっています。特に複数の臓器の重複領域を扱う場合、エラー率は劇的に増加します。
より深刻な矛盾は、医療データの独特の知識依存的性質にあります。自然な画像セグメンテーションがピクセルレベルの統計的特徴に依存できる場合、医療画像解析には、解剖学的な事前知識を統合する必要があります。たとえば、膵臓のセグメンテーションでは、グレースケールの特徴を識別するだけでなく、十二指腸への解剖学的な近接性を理解することも必要です。これにより、コンテキストベースの学習という新しいパラダイムが生まれました。つまり、サンプル画像やテキストの説明を入力することで、モデルが新しいカテゴリに適応するように誘導するのです。
しかし、テスト中に既存のシステムによって明らかになった問題は非常に皮肉なものでした。臨床医に高品質のサンプル注釈を提供することを要求すること自体が、自動セグメンテーションの本来の意図に反するのです。テキスト誘導による意味的整合バイアスにより、門脈胆管癌が正常な血管構造と誤認される可能性があります。この技術的道筋のパラドックスは、医療 AI 開発における基本的な命題を反映しています。オープンドメイン適応と臨床安全性の間の動的なバランスを確立する方法は、単にアルゴリズムのパフォーマンスを追求するよりも実用的かもしれません。
VISTA3D: 3D 医療画像のための統合セグメンテーション ベース モデル
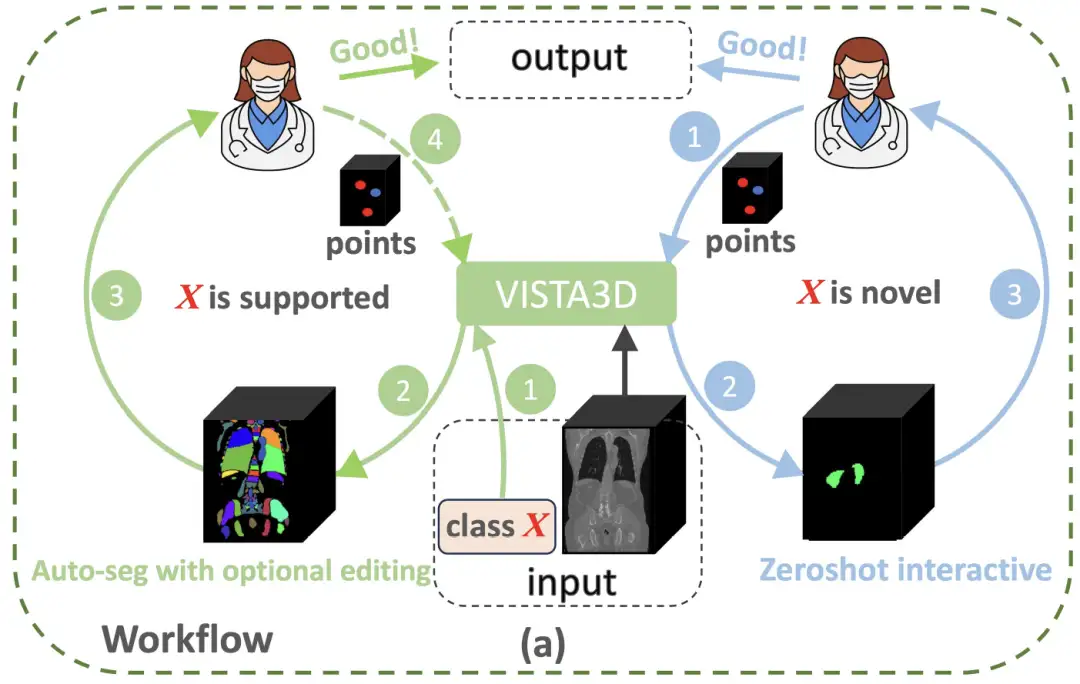
3D医療画像解析のパラダイム限界を打ち破るために、NVIDIA の研究チームは、2 次元の事前トレーニングの利点と 3 次元の解剖学的特性を組み合わせた革新的なアーキテクチャ、VISTA3D モデルを構築しました。下の図に示すように、セグメンテーション タスク X がサポートされている 127 のカテゴリ (左側の緑色の円) に属している場合、VISTA3D は高精度の自動セグメンテーション (Auto-seg) を実行します。医師は必要に応じて VISTA3D を使用して結果を確認し、効率的に編集できます。 X が新しいクラス (右側の青い円) の場合、VISTA3D は 3D インタラクティブ ゼロ ショット セグメンテーションを実行します。
具体的には、VISTA3D モデル アーキテクチャはモジュール設計コンセプトを採用し、医療画像処理分野で広く検証されている SegResNet に基づく 3D セグメンテーション コアを構築します。この U 字型のネットワーク アーキテクチャは、BraTS 2023 などの国際的に権威のあるセグメンテーション チャレンジで優れたパフォーマンスを発揮しています。下の図に示すように、ユーザーがサポートされている 127 のカテゴリに属するクラス プロンプトを提供すると、上部の自動分岐によって自動分割機能がすぐにアクティブになります。ユーザーが 3D ポイント プロンプトを提供すると、下部のインタラクティブ ブランチによってインタラクティブ セグメンテーション機能がアクティブになります。両方のブランチがアクティブになっている場合、アルゴリズムベースのマージ モジュールは対話型の結果を使用して自動結果を編集します。
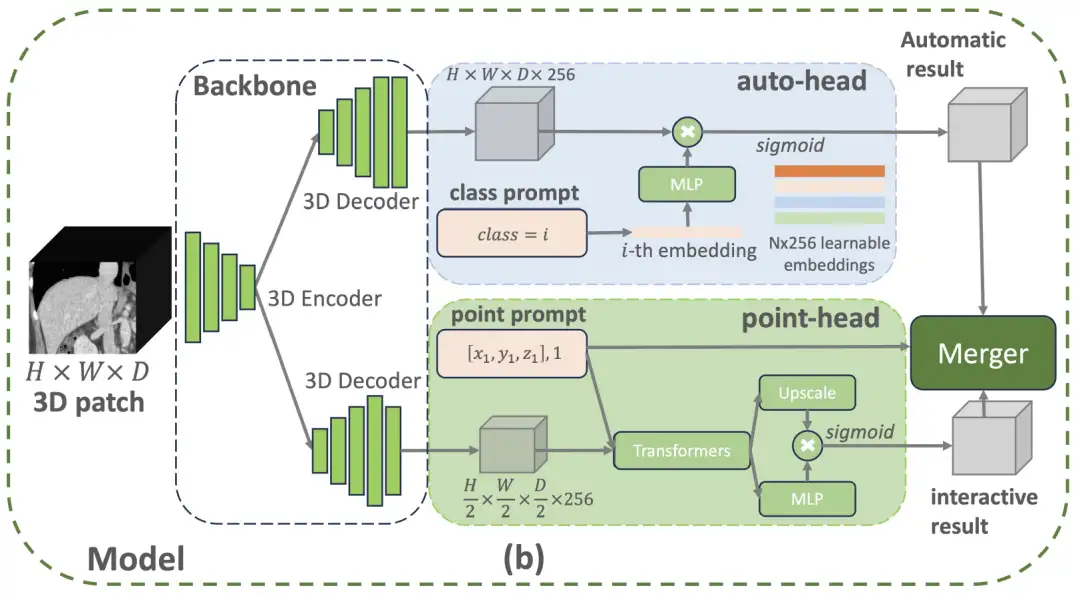
そのうち、自動分岐はインテリジェントコーディング技術を使用して 127 個の人体構造を管理します。特定の部品を見つける必要がある場合、システムはスキャンされた画像内の特徴情報を正確に照合し、インテリジェントな変換を通じてセグメンテーション結果を生成します。この設計により、従来の方法と比較して 60% のメモリ リソースが節約され、不完全な注釈によって生じる学習バイアスも回避できます。手動修正モジュールは、3 次元クリック位置決め技術を使用します。まず画像の詳細を復元し、次に処理速度を最適化します。医師がクリックした場所は空間座標に変換され、スキャン機能とインテリジェントに関連付けられます。膵臓や腫瘍など、紛らわしい構造に遭遇した場合、システムは自動的に識別マークを追加します。
2 つのモジュールはインテリジェントな連携により正確な調整を実現します。修正操作は、全体的なセグメンテーション結果を損なわずに特定の部分を修正するために精密メスを使用するのと同じように、クリック位置に接続されたローカル領域にのみ影響します。この3次元最適化ソリューションは、医師の矯正効率を40%向上させます。モデルのトレーニング段階では、研究チームは 11,454 個の CT スキャン データ セットも統合し、半教師あり学習フレームワークの下で疑似ラベル生成メカニズムを採用し、それを 4 段階の漸進的トレーニング戦略と組み合わせました。彼らはまず、混合データセット(疑似ラベルとスーパーボクセル注釈を含む)で事前トレーニングを行い、次に自動セグメンテーションとインタラクティブな修正タスクをそれぞれ微調整し、最後に共同トレーニングを通じて機能統合を達成しました。最終的に、VISTA3D モデルは、コアイノベーションを通じて複数の技術的飛躍を実現します。
まず、このモデルは 127 種類の解剖学的構造と病理学的特徴を網羅する 14 の国際公開データセットで体系的に検証されました。3D自動セグメンテーション精度(ダイス係数0.91±0.05)は、従来のベースラインモデルよりも8.3%高くなります。また、クリックベースのインタラクティブな修正もサポートしており、手動修正にかかる時間を従来の方法の 1/3 に短縮します。第二に、初の 3D スーパーボクセル特徴転送技術は、2D 事前トレーニング済みバックボーン ネットワークの空間特徴を切り離すことで、膵臓セグメンテーションなどのゼロショット タスクで 50% mIoU の改善を実現します。ラベル付け効率は教師あり学習の 2.7 倍です。さらに、研究チームは、機関間のマルチモーダルデータセットも構築しました。97.2% の注釈精度を維持しながら、データ注釈コストは完全な手動注釈の 15% に圧縮されます。
中国における3D医用画像とAIの統合に関する研究の進展
近年、医療分野におけるAI技術の幅広い応用に伴い、3次元医療画像技術と人工知能の組み合わせは徐々に研究のホットスポットとなり、中国で大きな進歩を遂げ、医療診断と治療に新たな機会をもたらしています。
2023年には、医療画像診断におけるAIの応用は、主に補助診断に重点が置かれるでしょう。 AI は、画像と患者情報の大規模なデータセットを迅速にスクリーニングし、診断効率を向上させることができます。例えば、AI を統合した画像診断システムでは、肉眼では判別が難しい微細な異常も検出できるため、診断の精度が向上します。さらに、AI は患者の電子医療記録から過去の画像スキャンを取得し、最新のスキャンと比較することで、医師により包括的な診断情報を提供します。例えば、上海交通大学は、3D 医療画像セグメンテーション用の新しい実用的なモデル PnPNet を提案しました。クラス間の境界混乱の問題は、交差する境界領域と隣接領域間の相互作用ダイナミクスをモデル化することによって解決されます。パフォーマンスは SOTA であり、MedNeXt、Swin UNETR、nnUNet などのネットワークよりも優れています。
* 紙のアドレス:
https://arxiv.org/abs/2312.08323
2024年には、3D医療画像技術とAIの統合がさらに進み、研究の方向性もより多様化します。一方、医療画像の3次元再構成におけるAI技術の応用は徐々に成熟しており、3次元画像のセグメンテーションと再構成を自動的に実行できるようになり、画像再構成の精度と効率が向上しています。一方、AIの画像解析能力もさらに向上し、医師による病気の診断や治療計画の立案を支援できるようになりました。さらに、AI 技術は、ノイズ除去、強調、レンダリングなどの画像後処理にも使用され、画像の読みやすさと美しさを向上させます。例えば、四川大学華西病院は、中国人口の肺がんスクリーニングコホートと肺結節臨床コホートに基づいて、データ駆動型の中国肺結節報告およびデータシステム (C-Lung-RADS) を革新的に開発しました。肺結節の悪性腫瘍リスクの正確な等級分けと個別管理が実現しました。
* 紙のアドレス:
https://www.nature.com/articles/s41591-024-03211-3
2025 年までに、3D 医療画像における AI 技術の応用はより広範囲かつ詳細になるでしょう。例えば、北京大学の研究チームは最近、国際的に「腎臓イメージンググループプロジェクト」を立ち上げた。マルチモーダルイメージング技術と人工知能アルゴリズムを通じて腎臓全体のデジタルマップの構築を主導する予定です。この「デジタル腎臓」は、腎臓病のメカニズムをより明確に可視化し、腎臓病の正確な診断、新薬の開発、精密な治療に新たな方向性を提供します。
同時に、中国地質大学と百度のチームが共同で、コントラスト主導の医療画像セグメンテーションのための「ConDSeg」と呼ばれる汎用フレームワークを提案した。このフレームワークは、一貫性強化トレーニング戦略、セマンティック情報分離モジュール、コントラスト駆動型特徴集約モジュール、およびサイズ認識デコーダーを革新的に導入し、医療画像セグメンテーション モデルの精度をさらに向上させます。
* 紙のアドレス:
https://arxiv.org/abs/2412.08345
それだけでなく、昆明科技大学と中国海洋大学は、双方向段階的特徴アライメント(BSFA)非アライメント医療画像融合法を提案しました。従来の方法と比較して、この研究では、統一された処理フレームワーク内で単一段階のアプローチを通じて、位置合わせされていないマルチモーダル医療画像を同時に位置合わせおよび融合します。これにより、二重タスクの調整が達成されるだけでなく、複数の独立した特徴エンコーダーの導入によって生じるモデルの複雑さの問題も効果的に軽減されます。
* 紙の住所:
https://doi.org/10.48550/arXiv.2412.08050
しかし、3D 医療画像技術と AI を組み合わせる研究にもいくつかの課題があります。データのプライバシー、アルゴリズムの透明性、モデルの一般化能力、規制監督などの問題は、依然として対処が必要な重要な問題です。将来的には、技術の継続的な進歩と規制の改善により、これらの問題は徐々に解決され、医療画像分野における AI 技術のより広範な応用が促進される可能性があります。








