Command Palette
Search for a command to run...
オンラインチュートリアル:シングルカードA6000はGemma 3を簡単に展開し、黄仁訓のスピーチの実際のショットを正確に識別します

3月12日の夕方、Google は、単一の GPU または TPU で実行できる最も強力なモデルと言われている「シングルカード デビル」である Gemma 3 をリリースしました。実際の結果も公式ブログの記述を裏付けており、27B バージョンは 671B のフル機能 DeepSeek V3 や o3-mini、Llama-405B を上回り、DeepSeek R1 に次ぐ性能となったが、計算能力の要件は他のモデルよりもはるかに低かった。次の図に示すように:
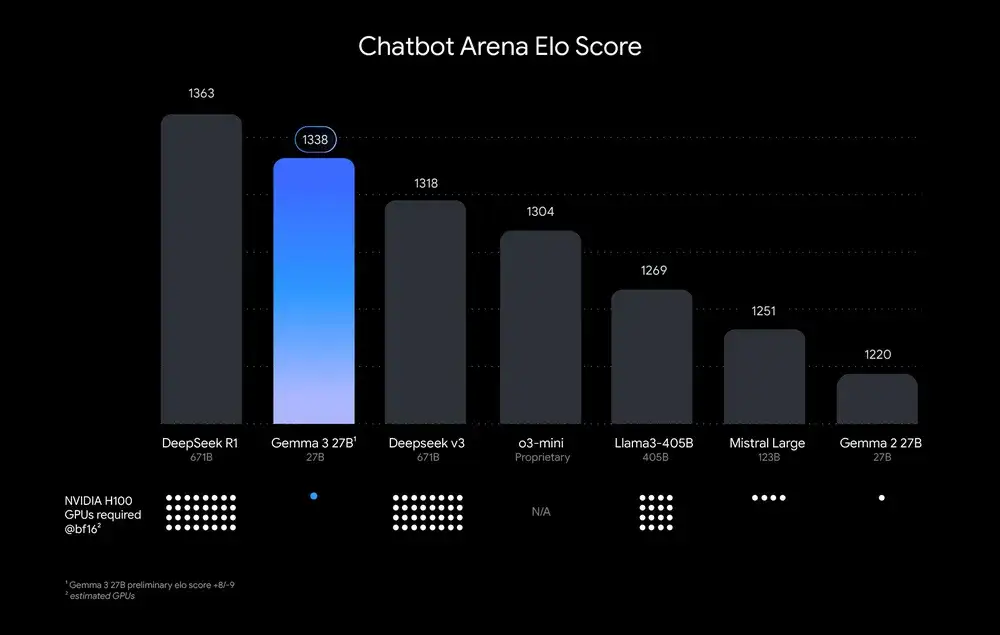
*モデルはChatbot Arena Eloスコアによってランク付けされています。ドットは推定コンピューティングパワー要件を表します。
その後、Google も寛大にも Gemma 3 の技術レポートの公開禁止を解除しました。 Gemma 3 は蒸留、強化学習、モデルマージなどの手法を組み合わせており、事前トレーニング済みバージョンと命令微調整バージョンの両方のパフォーマンスが Gemma 2 よりも優れていることが紹介されています。同時に、視覚理解機能とより広範な言語理解機能が導入され、140以上の言語と128kの長いコンテキストの理解をサポートします。
応用シナリオでは、マルチモーダル大規模モデル Gemma 3 はテキストと画像の入力を処理し、テキスト出力を生成することができ、質問への回答、要約、推論など、さまざまなテキスト生成および画像理解タスクに適しています。今回オープンソース化された 1B、4B、12B、27B の 4 つのパラメータ バージョンには、事前トレーニング済みのモデルと一般的な命令の微調整バージョンの両方が含まれており、携帯電話、ラップトップ、ワークステーションなどのデバイスで直接迅速に実行できます。
この「単一GPU上で最強のマルチモーダルモデル」を皆様にもっと体験していただくために、HyperAI の公式サイトのチュートリアル セクションでは、270 億のパラメータを持つ命令最適化バージョン「vLLM を使用して Gemma-3-27B-IT をデプロイする」が公開されました。
チュートリアルのリンク:
さらに、皆様にサプライズボーナスをご用意しました - 4時間 シングルカードRTX A6000 無料利用期間(リソース有効期間は1ヶ月)、新規ユーザーは招待コードを利用 ジェマ3登録して入手してください。空きは 10 名のみで、先着順です。
デモの実行
1. hyper.ai にログインし、チュートリアル ページで、「vLLM を使用して Gemma-3-27B-IT をデプロイする」を選択し、「このチュートリアルをオンラインで実行」をクリックします。
2. ページがジャンプしたら、右上隅の「クローン」をクリックしてチュートリアルを独自のコンテナにクローンします。
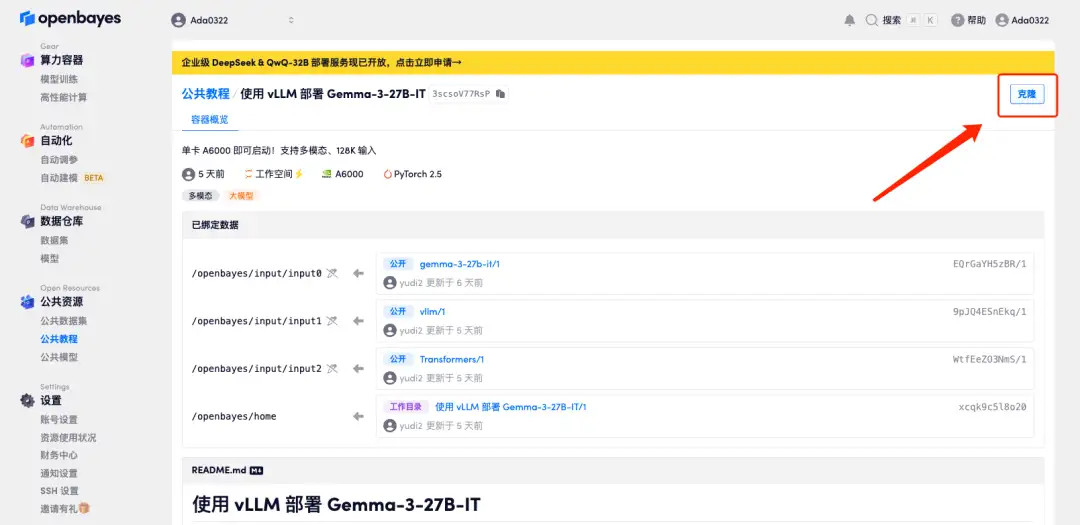
3. NVIDIA A6000 と PyTorch イメージを選択し、「続行」をクリックします。最新バージョンの vLLM がコンテナにプリロードされています。
OpenBayes プラットフォームは新しい課金方法を開始しました。ニーズに応じて、「従量課金」または「日次/週次/月次パッケージ」を選択できます。新規ユーザーは、以下の招待リンクを使用して登録すると、4 時間の RTX 4090 + 5 時間の CPU フリータイムを獲得できます。
HyperAI ハイパーニューラルの専用招待リンク (ブラウザに直接コピーして開きます):
https://openbayes.com/console/signup?r=Ada0322_NR0n
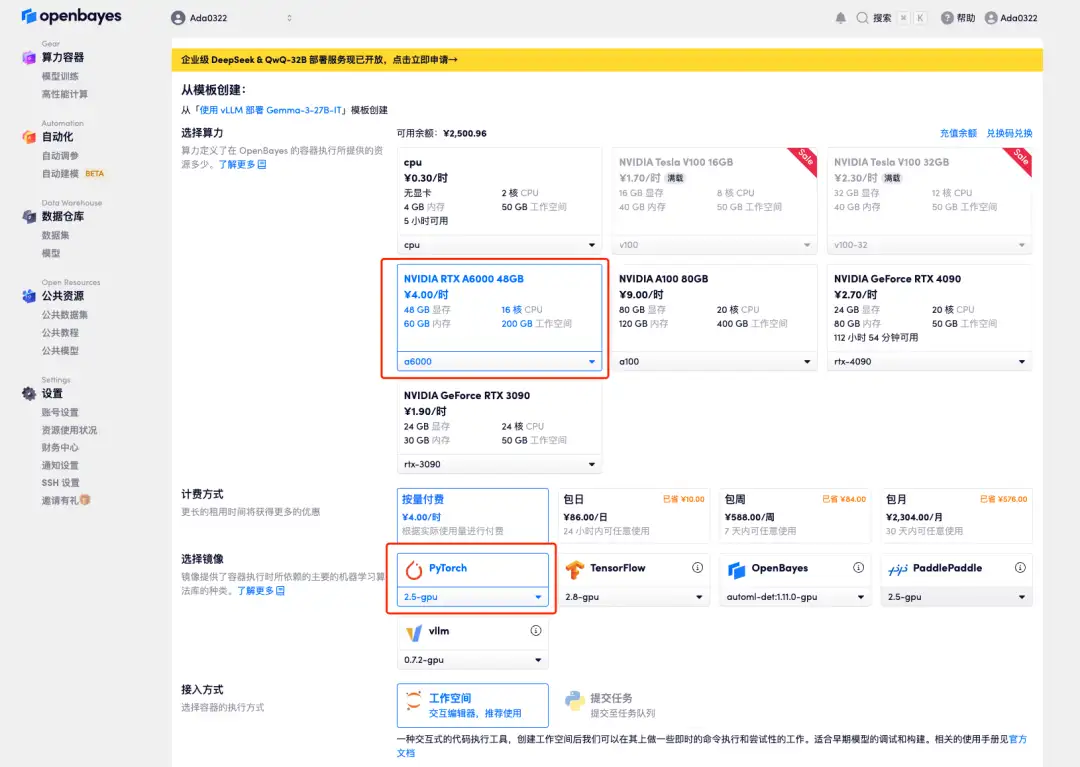
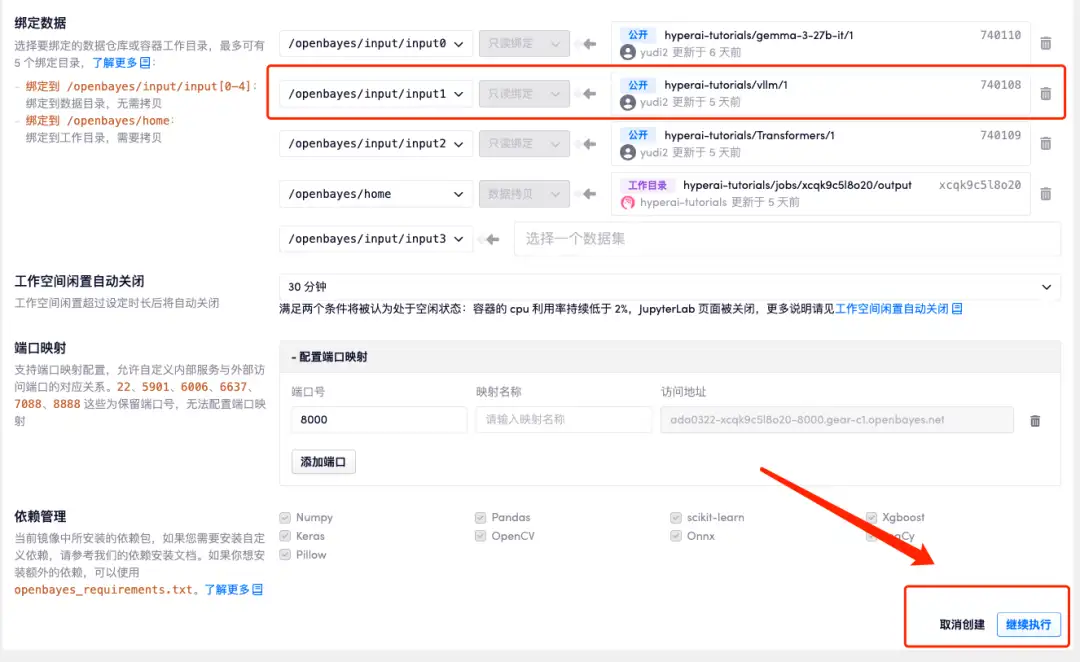
4. リソースが割り当てられるのを待ちます。最初のクローン作成プロセスには約 2 分かかります。ステータスが「実行中」に変わったら、「API アドレス」の横にあるジャンプ矢印をクリックしてデモ ページに移動します。モデルが大きいため、WebUI インターフェイスが表示されるまでに約 3 分かかります。そうでない場合は、「Bad Gateway」と表示されます。 APIアドレスアクセス機能を使用する前に、ユーザーは実名認証を完了する必要がありますのでご注意ください。
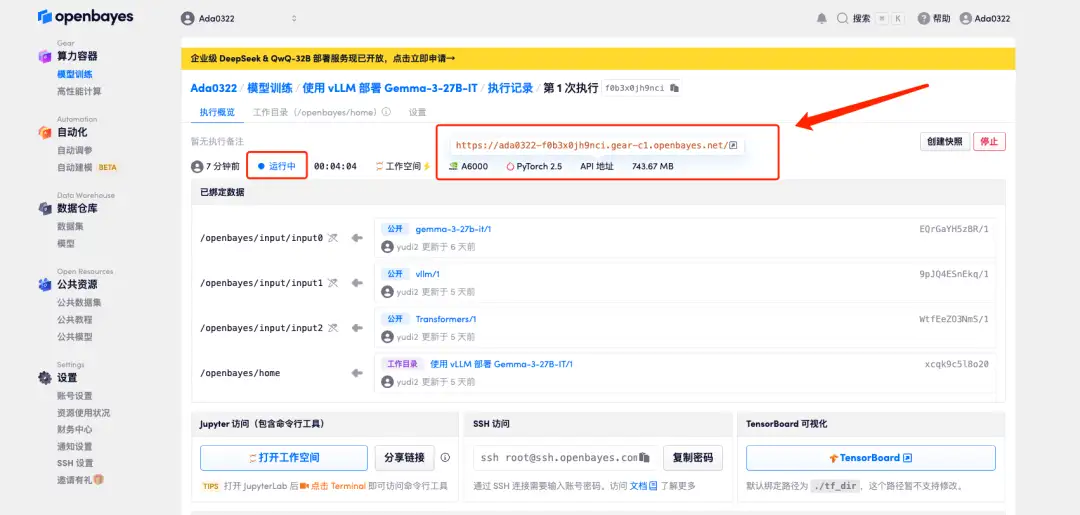
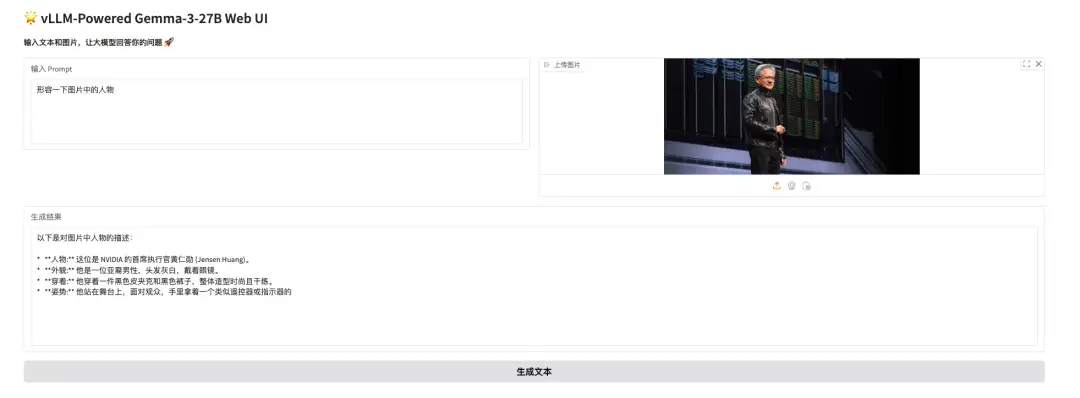
エフェクト表示
昨日(3月19日)早朝、「革剣士」黄仁訓がNVIDIA GTC 2025で基調講演を行いました。私は彼を使ってGemma 3の画像理解力をテストしました。一目で黄仁訓を認識しただけでなく、次の図に示すように、彼がリモコンを持ってステージに立っていることも認識しました。