Command Palette
Search for a command to run...
株価は下落を止められず、黄仁訓はブラックウェル・ウルトラとベラ・ルービンの発売時期を明らかにし、推論能力が焦点となった

近年、NVIDIA は、クラウド コンピューティングから暗号通貨、メタバースから人工知能まで、世界のテクノロジー分野のほぼすべての主要なトレンドに関与しています。特に人工知能の新波において、NVIDIA は深い技術的蓄積により、約 95% のデータセンター GPU 市場シェアをしっかりとコントロールし、AI チップの分野で絶対的なリーダーとなっています。
しかし、今年初め、ディープシーク 推論モデルの出現は、これまでデータと計算能力の蓄積に頼ってきた「奇跡を達成するための多大な努力」モデルが徐々に効果を失っているという明確なシグナルを世間に送った。これにより、AIの計算能力の見通しに対する市場の期待が揺らぎ、Nvidiaを含む多くのテクノロジー大手の株価が急落した。 Nvidiaの株価はその後回復したものの、業界における同社の優位性はかつてほど揺るぎないものではなくなった。同社の強さを証明するために、NvidiaはGPUを全面的にアップグレードし、更新する必要があるだろう。
3月19日北京時間午前1時に開催されたGTC 2025カンファレンスで、黄仁訓氏はNvidiaチップに関する最新ニュースを発表した。AIチップアーキテクチャBlackwellのアップグレード版であるBlackwell Ultraは、今年下半期に発売される予定です。NVIDIA GB300 NVL72とNVIDIA HGX™ B300 NVL16は、モデル推論機能を全面的に強化します。NVIDIAの次世代GPUアーキテクチャVera Rubinは来年発売される予定です。
NVIDIA Blackwell Ultra が AI 推論を加速
昨年のGTCカンファレンスで、黄仁勲氏は次世代AIチップアーキテクチャBlackwellを発表しました。 ホッパー NVIDIA GeForce GPUの後継であるBlackwellアーキテクチャは、2,080億個のトランジスタを備え、生成AIタスク、大規模なトレーニング、推論ワークロードの高速化に重点を置いています。黄仁勲氏はスピーチの中で、これがこれまでで最も強力なAIチップシリーズであると誇らしげに宣言しました。

今日の生放送で、黄仁訓は再びブラックウェルについて言及した。同氏は「Blackwellの利点は、より高速で、より大きく、より多くのトランジスタを搭載し、より強力なコンピューティングパワーを備えていることです」と述べた。さらに、採用されているNVL 72アーキテクチャ+ FP4コンピューティング精度モデルもBlackwellのパフォーマンスをさらに向上させ、より少ないエネルギー消費で同じコンピューティングタスクを完了できることを意味します。
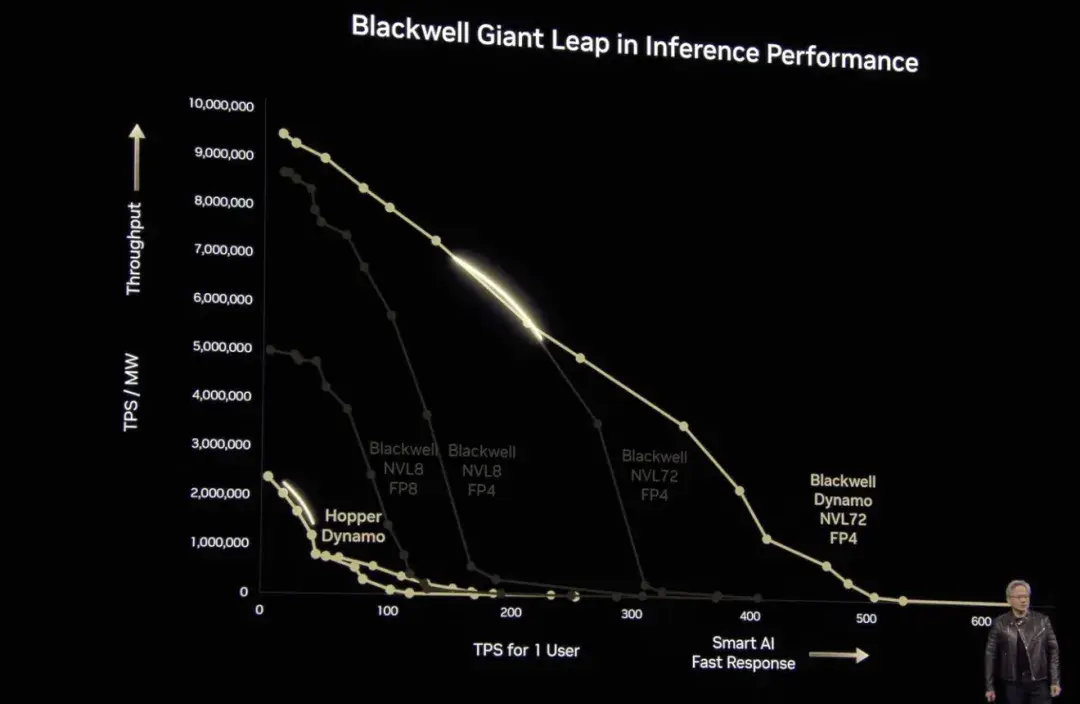
注目すべきは、DeepSeekの登場以降、人工知能市場の焦点が徐々に「トレーニング」から「推論」へと移行してきたことだ。今回のカンファレンスで、黄仁訓氏は推論モデルケースを具体的に引用し、ブラックウェルの計算性能がホッパーの40倍も優れていることを証明した。 「前にも言いましたが、ブラックウェルが大量出荷を始めたら、ホッパーを世に出すことすらできなくなるでしょう。」もちろん、黄仁訓氏は、ブラックウェルは生産に全面的に投資しており、NVIDIA ブラックウェル AI 工場は今年下半期に再度アップグレードされる予定であると述べました。Blackwell Ultra にシームレスに移行します。

Blackwell Ultraには、NVIDIA GB300 NVL72ラックスケールソリューションが含まれ、 NVIDIA HGX B300 NVL16 システム。
まず、NVIDIA GB300 NVL72は、72個のNVIDIA Blackwell Ultra GPUと36個のArmベースのNVIDIAを搭載した、完全に液体冷却されたラックマウント設計を採用しています。 グレース™ CPU テスト時のスケールアウト推論に最適化された単一のプラットフォームに統合します。 GB300 NVL72 は、前世代の NVIDIA GB200 NVL72 の 1.5 倍の AI パフォーマンスを実現し、複数のソリューションを探索し、複雑なタスクを複数のステップに分解して、より高品質の応答を生成することが可能になります。
第二に、NVIDIA HGX B300 NVL16 は、AI 推論などの複雑なタスクを効率的に処理するための画期的なソリューションを提供します。Hopper と比較して、大規模言語モデルの推論速度が 11 倍、計算能力が 7 倍、メモリ容量が 4 倍向上します。
要約すると、Blackwell Ultra はトレーニング時とテスト時の拡張推論を強化し、加速 AI 推論、AI エージェント、物理 AI などのアプリケーションを強力にサポートします。
この点について、黄仁鈞氏は次のように述べている。「AI技術は大きな飛躍を遂げ、推論やAIエージェントのコンピューティング性能に対する需要が大幅に増加しました。この目的のために、私たちはBlackwell Ultraを設計しました。これは、事前トレーニング、事後トレーニング、推論タスクを効率的に実行できる多機能プラットフォームです。」
Nvidia の次世代 GPU アーキテクチャ Vera Rubin
Nvidia は 1998 年以来、科学者にちなんでアーキテクチャに名前を付けており、今回も例外ではありません。Nvidia の次世代 GPU アーキテクチャである Vera Rubin は、暗黒物質を発見したアメリカの天文学者 Vera Rubin にちなんで名付けられました。

Vera Rubin は、自社開発の CPU と GPU アーキテクチャを初めて深く統合しました。これは、AI コンピューティング アーキテクチャにおける NVIDIA の新たなブレークスルーであり、AI コンピューティング パフォーマンスの限界をさらに広げるものです。
「基本的に、シャーシ以外はすべて新しいものです」と黄仁鈞氏は言う。NVIDIA 初の完全に独立して設計された CPU アーキテクチャである Vera は、カスタマイズされた Arm コア上に構築されている。わずか 50 ワットの小型 CPU だが、メモリが大きく、帯域幅も高い。 NVIDIA の公式データによると、Vera のコンピューティング パフォーマンスは Grace Blackwell と比較して 2 倍直接向上しています。さらに、AI 負荷に対しても深く最適化されています。命令セットを最適化することで、通信遅延が大幅に短縮され、データ処理がより効率的かつスムーズになり、AI のトレーニングと推論を強力にサポートします。
同時に、新しい Rubin GPU は AI コンピューティングに新たな飛躍をもたらします。 Vera で実行すると、Rubin 推論コンピューティングは 50 ペタフロップスを達成でき、これは既存の Blackwell GPU の 2 倍以上のパフォーマンスです。さらに、Rubin は最大 288GB の高速メモリもサポートしており、AI のトレーニングと推論で膨大な量のデータを効率的に処理できます。
黄仁鉉氏はまた、Vera Rubin NVL144 が来年後半に発売されることも明らかにした。NVIDIAは2027年後半に、NVL576テクノロジーを採用し、250万個のコンポーネントで構成されるVera Rubin Ultraを発売する予定です。各ラックの電力は最大600キロワットです。浮動小数点演算の数は14倍の15エクサフロップスに増加し、極めて高いスケーラビリティを実現します。

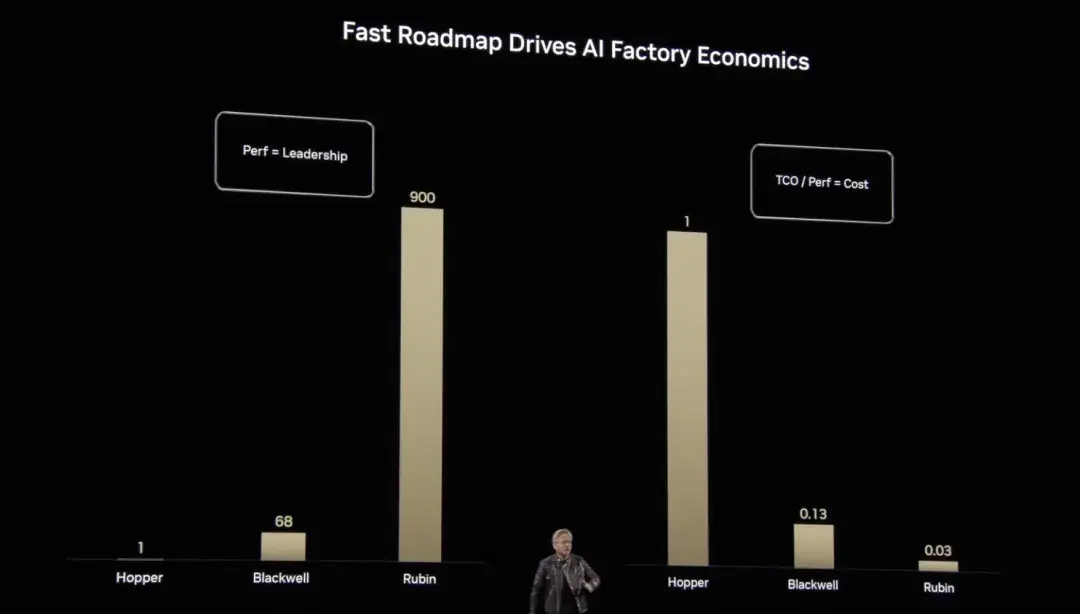
Grace Hopper から Blackwell、そして現在の Rubin まで、Huang Renxun はコンピューティング パフォーマンスとコスト最適化における NVIDIA の飛躍的な進歩を示してきました。ベンチマークの計算能力と比較すると、ホッパーの垂直拡張浮動小数点演算はベンチマークの1倍、ブラックウェルは68倍、ルービンは900倍と飛躍的な成長を遂げています。この画期的な進歩により、AI コンピューティングの単位コストが大幅に削減されるだけでなく、より複雑で大規模な AI モデルのトレーニングと推論が効率的かつ実現可能になります。
NvidiaはAI工場の構築にフルプロセスのサービスを提供
近年、AI分野の焦点は、大規模モデルのトレーニングから推論モデルの広範な応用へと徐々に移行しており、推論はAI経済の急速な成長の核心的な原動力となっています。この変化はテクノロジーの展望を変えるだけでなく、コンピューティングインフラストラクチャに対する新たな要件も生み出します。従来のデータセンターは、新しいAI時代に合わせて設計されていません。AIの推論と展開を効率的に促進するために、AIファクトリー(AI工場)が誕生しました。
AI ファクトリーは、データを保存および処理するだけでなく、大規模に「インテリジェンスを生成」し、生データをリアルタイムの洞察に変換します。 NVIDIAは「AIファクトリーの構築を専門とする企業への投資が将来の市場をリードすることになるだろう」と述べた。
この変革をサポートするために、NVIDIA はフルスタック AI ファクトリーの構成要素を作成し、高性能コンピューティング チップ、高度なネットワーク テクノロジ、インフラストラクチャ管理とワークロード オーケストレーション、最大規模の AI 推論エコシステム、ストレージとデータ プラットフォーム、設計と最適化のブループリント、リファレンス アーキテクチャ、柔軟な展開方法といった主要コンポーネントをパートナーに提供しています。

コンピューティング能力が AI ファクトリーの中核となることは間違いありません。 Hopper から Blackwell アーキテクチャまで、NVIDIA は世界で最も強力なアクセラレーテッド コンピューティングを提供します。 Blackwell Ultra ベースの GB300 NVL72 ラックレベル ソリューションにより、AI ファクトリーは最大 50 倍の AI 推論出力を実現し、複雑なタスクの処理に前例のないパフォーマンス サポートを提供できます。








