Command Palette
Search for a command to run...
オープンソースのトッププレイヤーが集結! QwQ-32B は複数のゲームプレイ モードのロックを解除し、OpenManus は低コストで AI エージェントを構築します。 vLLM v1は効率的なモデル推論を可能にします

人工知能分野における継続的なブレークスルーの波の中で、320億のパラメータを備えたQwenチームの最新モデルQwQ-32Bは、オープンソースの大規模モデルに対する業界の認識を改めて刷新しました。このモデルは、コード生成や複数ラウンドの対話などのタスクで優れたパフォーマンスを発揮し、その推論能力は DeepSeek-R1 の完全版に匹敵します。
つい最近、大規模モデルの推論を高速化するために特別に設計された vLLM コア アーキテクチャが大幅に更新されました。実行ループ、統合スケジューラ、ゼロオーバーヘッドのプレフィックスキャッシュを最適化することで、スループットとレイテンシのパフォーマンスが最大 1.7 倍向上し、QwQ-32B をデュアルカード A6000 グラフィックス カードに効率的に導入できるようになります。
AIエージェントの分野では、OpenManusが立ち上げ以来勢いを増しています。「Manusの代替」として知られるこのオープンソースプロジェクトは、技術の再現を通じて閉鎖的なエコシステムに対する外部の疑問に応えるだけでなく、モジュール設計とツールチェーンの統合を通じて低コストでインテリジェントなエンティティを構築するための「マスターキー」を開発者に提供します。
現在、HyperAI は「vLLM を使用して QwQ-32B を展開する」と「OpenManus + QwQ-32B を使用して AI エージェントを実装する」という 2 つのチュートリアルを公開しています。ぜひお試しください。
vLLMを使用してQwQ-32Bをデプロイする
オンラインでの使用:https://go.hyper.ai/8nPfC
OpenManus + QwQ-32BはAIエージェントを実装します
オンラインでの使用:https://go.hyper.ai/GIX1H
3月10日から3月15日まで、hyper.ai公式サイトが急速に更新されました。
* 高品質の公開データセット: 10
* 高品質なチュートリアルの選択: 4
* コミュニティ記事の選択: 6 記事
* 人気のある百科事典のエントリ: 5
* 3月に締め切りを迎えるトップカンファレンス: 4
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
Big-Math は、言語モデルにおける強化学習 (RL) の応用のために設計された大規模で高品質な数学データセットです。データセットには、それぞれ検証可能な解答を持つ 25 万件を超える高品質な数学問題が含まれています。
直接使用します:https://go.hyper.ai/qtlbQ
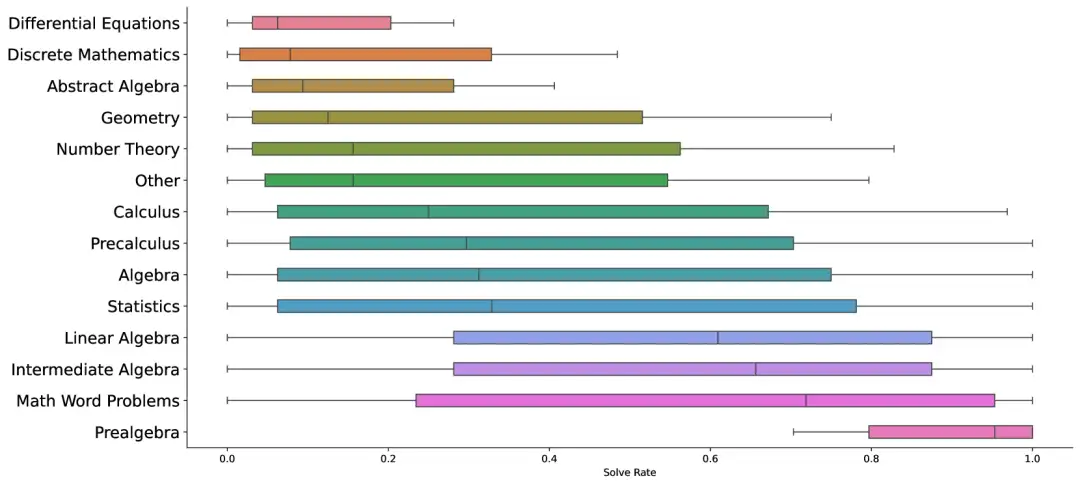
JMED データセットは、実際の医療データの分布に基づいた新しいデータセットです。このデータセットは、JD Health Internet Hospital における匿名の医師と患者の会話から抽出され、標準化された診断ワークフローに従った診察が保持されるようにフィルタリングされています。
直接使用します:https://go.hyper.ai/FjZsa
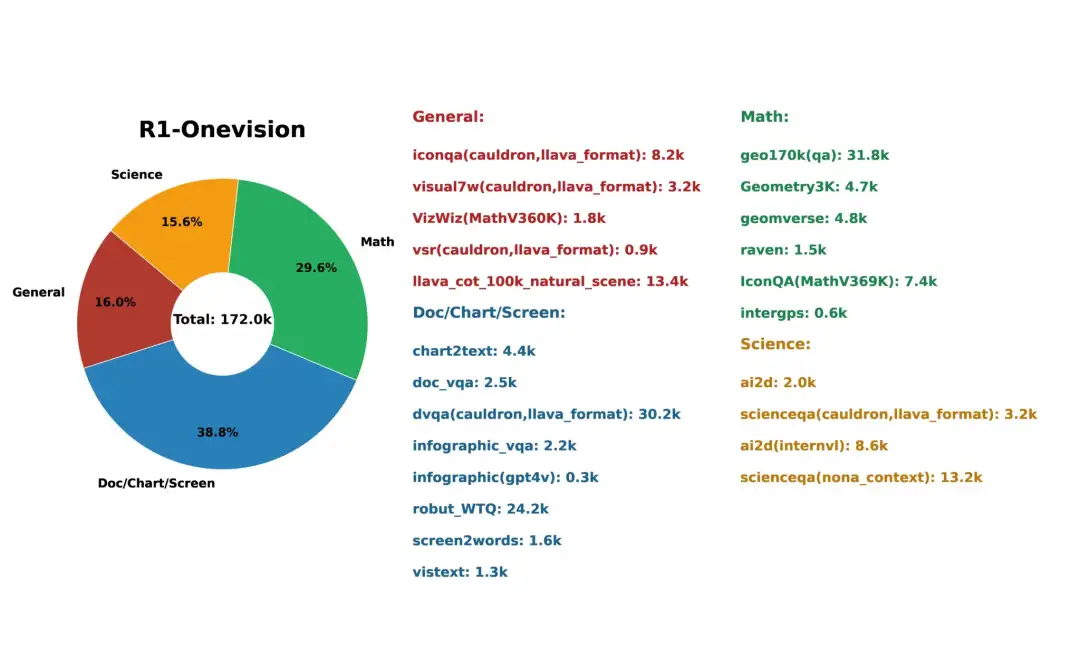
3. R1-Onevision マルチモーダル推論データセット
R1-Onevision データセットは、モデルに高度なマルチモーダル推論機能を与えるように設計されています。自然の風景、科学、数学の問題、OCR ベースのコンテンツ、複雑な図表など、複数の領域における豊富なコンテキスト認識推論タスクを通じて、視覚的理解とテキスト理解の間のギャップを埋めます。
直接使用します:https://go.hyper.ai/jLbSI
4. NaturalReasoning 自然推論データセット
NaturalReasoning データセットは、STEM 分野 (物理学、コンピューター サイエンスなど)、経済学、社会科学などの複数の分野を網羅する 280 万の難しい質問を含む、大規模で高品質な推論データセットです。このデータセットは、事前にトレーニングされたコーパスと大規模言語モデル (LLM) を活用して、人間による追加の注釈を必要とせずに、多様で難しい推論の質問とその参照回答を生成することを目的としています。
直接使用します:https://go.hyper.ai/Mb6Cd
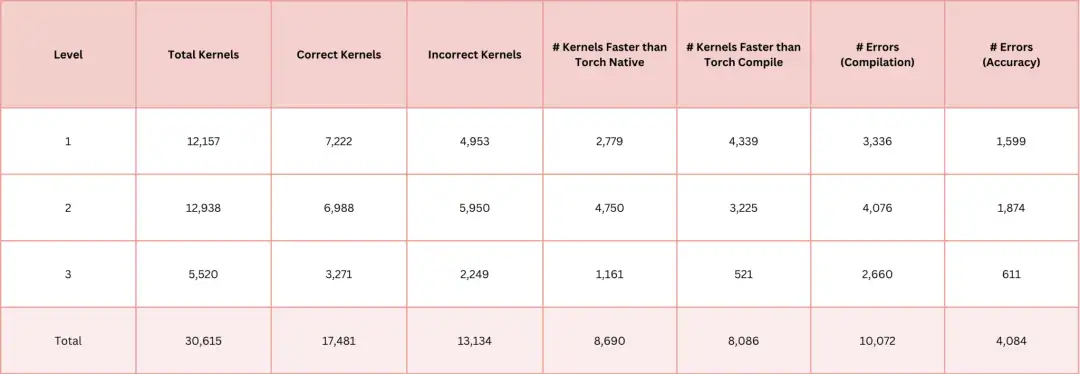
5. AI-CUDA-Engineer-Archive カーネルコレクションデータセット
AI-CUDA-Engineer-Archive データセットは、AI によって生成された CUDA カーネルのコレクションであり、オープンソース モデルのその後のトレーニングと、より優れた CUDA 関数モジュールの開発を容易にすることを目的としています。このデータセットには 30,000 を超える CUDA カーネルが含まれており、それらはすべて AI 主導の CUDA エンジニアによって生成され、そのうち 17,000 を超えるカーネルが正しいことが検証されており、約 50% のカーネルが PyTorch のネイティブ ランタイムよりも優れています。
直接使用します:https://go.hyper.ai/3lPrI
QM9 データセットは、約 134,000 個の有機小分子の量子化学計算結果を含む、広く使用されている量子化学データセットです。これらの分子は、炭素、水素、窒素、酸素、フッ素の元素で構成されており、分子量は 900 ダルトン以下です。
直接使用します:https://go.hyper.ai/PZdz7
GEOM-Drugs データセットは、430,000 個の分子を含む大規模な 3D 分子構造データセットです。各分子は平均 44 個の原子を持ちます。データ処理後、各分子には最大 181 個の原子が含まれる可能性があります。実験では、研究者らは各分子のエネルギーが最も低い30の配座を収集し、各ベースライン手法にこれらの分子を構成する原子の3D位置とタイプを生成するよう依頼した。
直接使用します:https://go.hyper.ai/5B3U8
このデータセットには、風水や八字などに関する 207 の質問が含まれており、各質問には一意の対応する回答があります。
直接使用します:https://go.hyper.ai/31k1P
9.SuperGPQA 科目領域評価ベンチマークデータセット
SuperGPQA は、高度な質問応答システムのパフォーマンスを評価するためのベンチマーク データセットです。自然言語処理と機械学習評価の分野に焦点を当て、複雑な学際的な質問を通じてモデルの推論能力と知識レベルをテストすることを目的としています。このデータセットは、生物学、物理学、化学、その他の科学分野を含む、多様な質問タイプを持つ大学院レベルの 285 の科目領域をカバーしています。
直接使用します:https://go.hyper.ai/oP1pb
10. olmOCR-mix-0225 大規模PDF文書データセット
olmOCR-mix-0225 は、光学式文字認識 (OCR) モデルのトレーニングと最適化のために設計された、大規模で高品質の PDF ドキュメント データセットです。このデータセットには、学術論文、法律文書、マニュアルなど、さまざまなタイプを網羅した約 25 万ページの PDF コンテンツが含まれています。データセットにはテキスト コンテンツだけでなく、各ページの主要要素 (テキスト ブロックや画像など) の座標情報も抽出されます。この情報はモデル プロンプトに動的に挿入されるため、モデルの幻覚が大幅に軽減されます。
直接使用します:https://go.hyper.ai/dXNkk
選択された公開チュートリアル
QwQ-32BはQwenシリーズの推論モデルです。従来の命令チューニングモデルと比較して、QwQは思考力と推論力を備えており、下流のタスク、特に難しい問題で大幅なパフォーマンス向上を実現できます。DeepSeek-R1やo1-miniなどの高度な推論モデルに匹敵します。
このプロジェクトの関連モデルと依存関係がデプロイされました。コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります。
オンラインで実行:https://go.hyper.ai/Q8HmJ

vLLM は、大規模な言語モデルを効率的に展開するために設計されたオープンソースの推論フレームワークです。そのコアテクノロジーは、メモリ管理とコンピューティング効率を最適化することで、モデル推論のハードウェアしきい値を大幅に削減します。このチュートリアルでは、vLLM を使用して QwQ-32B モデルを展開し、展開コストをさらに削減し、よりインタラクティブなシナリオのニーズを満たします。
このプロジェクトの関連モデルと依存関係がデプロイされました。コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります。
オンラインで実行:https://go.hyper.ai/8nPfC
3.OpenManus + QwQ-32BはAIエージェントを実装します
OpenManus は、MetaGPT チームによって立ち上げられたオープンソース プロジェクトです。Manus のコア機能を複製し、招待コードなしでローカルに展開できるインテリジェント エージェント ソリューションをユーザーに提供することを目的としています。
公式ウェブサイトにアクセスしてコンテナをクローンして起動し、ワークスペースに入り、対応するコマンドを入力してモデルを体験してください。
オンラインで実行:https://go.hyper.ai/GIX1H
4. Step-Audio-TTS-3B 実用レベルの方言音声生成モデル
Step-Audioは、音声理解と生成制御を統合した業界初の製品レベルのオープンソースリアルタイム音声対話システムです。2025年にStepfun-AIチームによってオープンソース化されました。多言語生成(中国語、英語、日本語など)、音声感情(喜びや悲しみなど)、方言(広東語、四川語など)をサポートしています。発話速度やリズムスタイルを制御でき、RAPやハミングなどをサポートしています。
公式サイトにアクセスしてコンテナをクローンして起動し、API アドレスを直接コピーすると、多機能な音声合成を実行できます。
オンラインで実行:https://go.hyper.ai/WiyVK
注目のコミュニティ記事
1. 精度は97%に達する。オーストラリアチームの新たな成果は、ディープラーニングに基づいて頭蓋骨CTで性別を識別し、人間の法医学者を上回るものである。
西オーストラリア大学などのチームは、ディープラーニングに基づく自動化フレームワークの使用を提案した。この研究では、インドネシアの病院の頭蓋骨CTスキャン200枚を使用して、3つのディープラーニングベースのネットワーク構成をトレーニングおよびテストした。最も正確なディープラーニングフレームワークは、性別と頭蓋骨の特徴を組み合わせて判断することができ、分類精度は97%で、人間の観察者の82%を大幅に上回った。この記事は、その論文を詳細に解釈して共有したものです。
レポート全体を表示します。https://go.hyper.ai/0rfjM
2. 1.7K深センの住宅価格を例にとると、浙江大学GIS研究所は注目メカニズムを使用して地理的コンテキストの特徴をマイニングし、空間非定常回帰の精度を向上させます。
浙江省GIS重点研究室の研究者らは、注目メカニズムに基づくディープラーニングモデルCatGWRを提案した。このモデルは、サンプル間の空間距離とコンテキストの類似性を組み合わせて空間の非定常性をより正確に推定するための注意メカニズムを導入します。これにより、特に複雑な地理的現象を扱う場合に、地理空間モデリングに新たな視点が提供され、空間の異質性とコンテキストの影響をより適切に捉えることができます。この記事は、研究の詳細な解釈と共有です。
レポート全体を表示します。https://go.hyper.ai/irDAo
3. 数学/コード/科学/パズルを網羅した高品質の推論データセットがまとめられ、DeepSeekの強力な推論機能を再現するのに役立ちます。
HyperAI は、数学、コード、科学、パズルなど、複数の分野を網羅する最も人気のある推論データセットを慎重にまとめました。これらのデータセットは、大規模モデルの推論機能を大幅に向上させたいと考えている実務家や研究者にとって優れた出発点となります。この記事はデータセットのダウンロードアドレスです。
レポート全体を表示します。https://go.hyper.ai/XGIi8
4. ICLR 2025に選出されました!浙江大学の沈春華らがボルツマンアライメント技術を提案し、タンパク質結合自由エネルギーの予測がSOTAに到達
浙江大学らは、事前学習済みの逆折り畳みモデルの知識を結合自由エネルギーの予測に転用する「ボルツマンアラインメント」という手法を提案した。この手法は優れたパフォーマンスを示し、人工知能分野の最高峰の国際学術会議であるICLR2025に採用された。この記事は、その論文を詳細に解釈して共有したものです。
レポート全体を表示します。https://go.hyper.ai/MsUDj
NVIDIA は、MIT などと共同で、新しいタイプの大規模フロー タンパク質バックボーン ジェネレーターである Proteina を開発しました。 Proteina は RFdiffusion モデルの 5 倍のパラメータ数を持ち、トレーニング データを 2,100 万の合成タンパク質構造に拡張しました。de novo タンパク質バックボーン設計で SOTA パフォーマンスを達成し、最大 800 残基という前例のない長さの多様で設計可能なタンパク質を生成しました。その成果は ICLR 2025 Oral に選出されました。この記事は、研究の詳細な解釈と共有です。
レポート全体を表示します。https://go.hyper.ai/n4fWv
6. 政府活動報告では再び「人工知能+」について言及され、2つのセッションにおける技術リーダーの提案は、AI+医療/AI変顔・変声/大型モデル錯覚に焦点を当てていました...
雷軍、周紅毅、劉青鋒などの業界リーダーは時代の波をしっかりと追い、新エネルギー車、大型模型幻覚、AI医療、AI変顔、AI教育など多くの重要な分野で積極的に提案や提言を行った。詳細については下記をご覧ください。
レポート全体を表示します。https://go.hyper.ai/EazuY
人気のある百科事典の項目を厳選
1.ダルイー
2. 相互ソーティング融合 RRF
3. パレートフロント パレートフロント
4. 大規模マルチタスク言語理解MMLU
5. 対照学習
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。
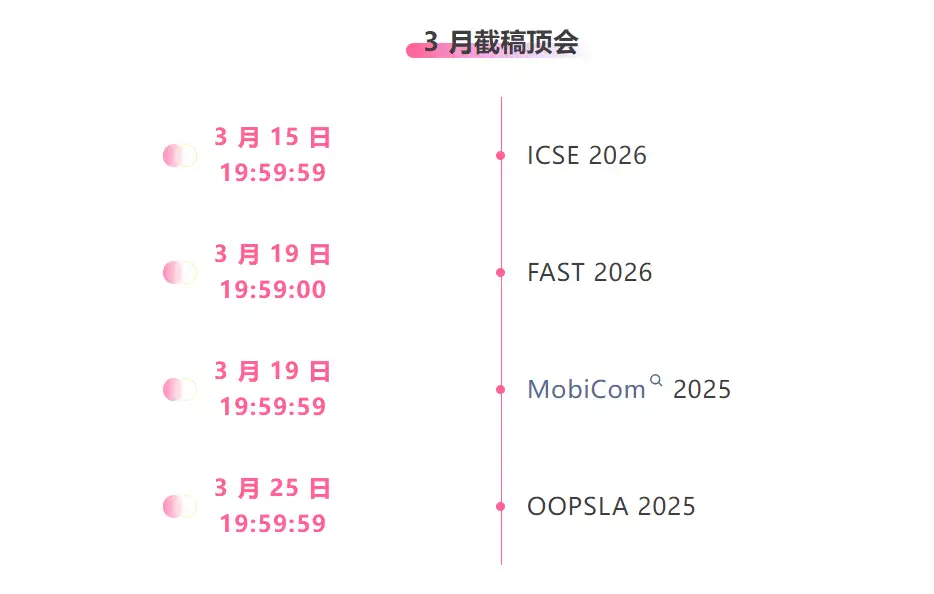
主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!








