Command Palette
Search for a command to run...
Ebook2Audiobook は電子書籍をワンクリックでオーディオブックに変換します。CVPR 初のクロスドメイン小サンプルオブジェクト検出チャレンジデータセットがオンラインになりました。

情報爆発の時代において、私たちの目は長い間、通勤中に携帯電話の画面を見つめたり、仕事をしながらコンピューターの書類に向き合ったり、寝る前に小説の世界に浸ったりして、圧倒されてきました。朝のジョギング中や料理中、あるいは目を閉じて休んでいるときに聞けるような温かい音声にテキストを変換できれば、情報の取得は視覚に限定されなくなります。
Ebook2Audiobook は、電子書籍 (eBook) をオーディオブック (オーディオブック) に変換するために設計されたオープン ソース ツールです。このプロジェクトでは、高度なテキスト読み上げ (TTS) 技術を使用して、電子書籍のテキスト コンテンツを音声ファイルに変換し、聴くことができるオーディオ ブックを生成します。
現在のところ、「Ebook2Audiobook 電子書籍をオーディオブックにする」チュートリアルがオンラインになりました hyper.ai 公式サイトワンクリックスタートで電子書籍ライブラリが音波で生まれ変わります。ぜひお試しください〜
オンラインでの使用:https://go.hyper.ai/sgLbN
3月3日から3月7日まで、hyper.ai公式サイトが更新されます。
* 高品質の公開データセット: 10
* 高品質なチュートリアルのセレクション: 3
* コミュニティ記事の選択: 6 記事
* 人気のある百科事典のエントリ: 5
* 3月に締め切りを迎えるトップカンファレンス: 5
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
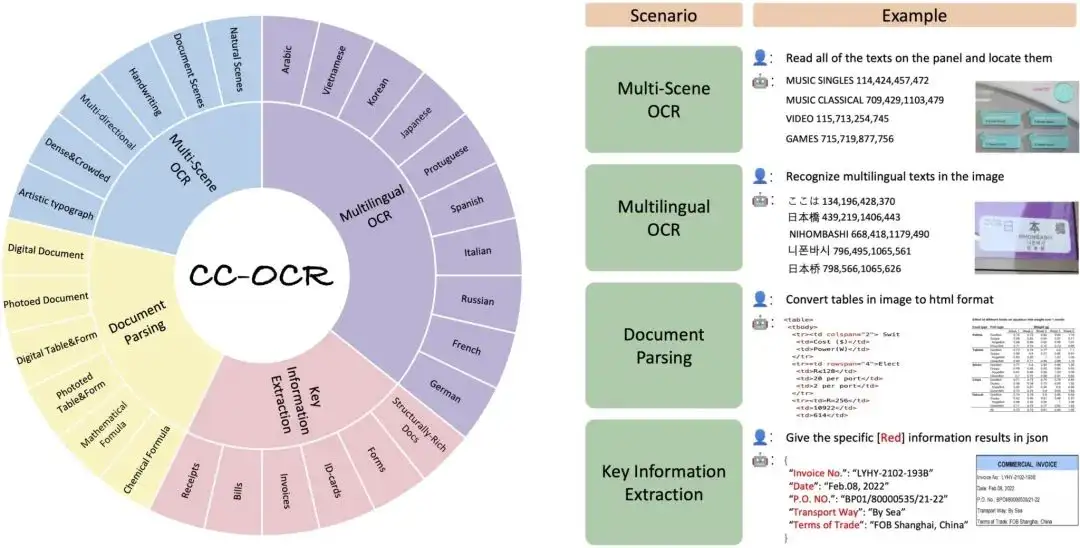
CC-OCR データセットは、マルチシーンテキスト読み取り、多言語テキスト読み取り、ドキュメント解析、キー情報抽出という 4 つのコアタスクをカバーし、39 のサブセットと 7,058 の完全に注釈が付けられた画像が含まれています。 CC-OCR の導入は、複雑な構造やきめ細かい視覚的課題における現在のマルチモーダル モデルの評価のギャップを埋め、実際のアプリケーションにおけるマルチモーダル モデルの進歩を促進する上で大きな意義を持ちます。
直接使用します:https://go.hyper.ai/rQT2y
2. MM-RLHF マルチモーダル嗜好アライメントデータセット
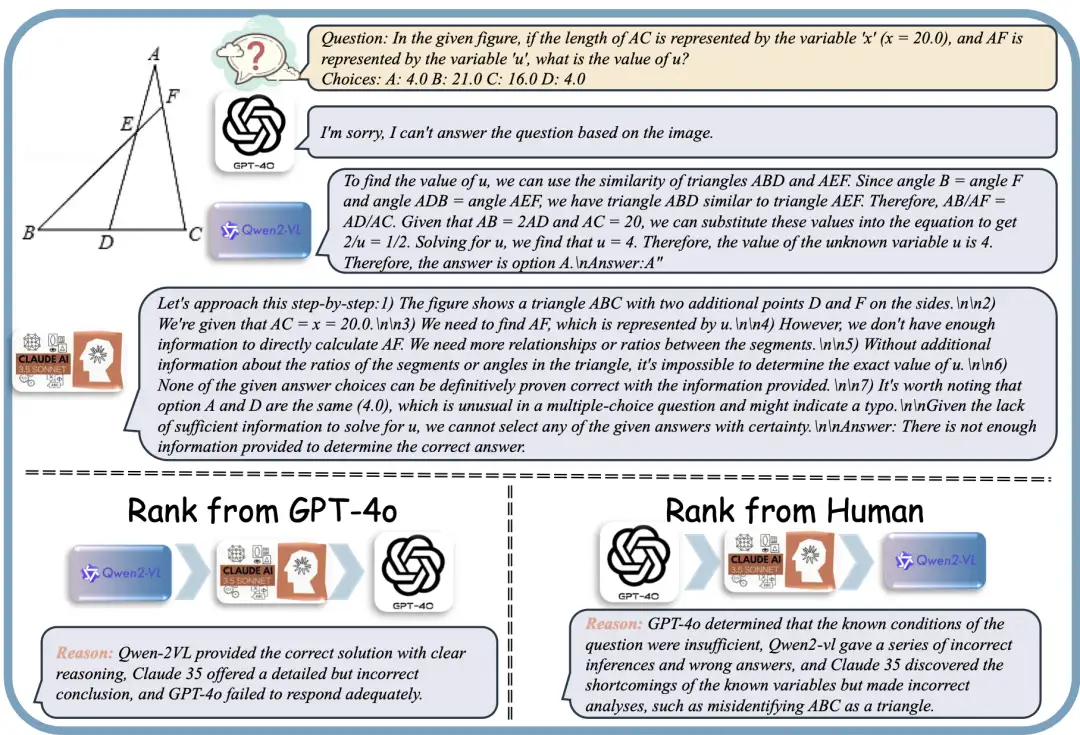
このデータセットには、画像理解、ビデオ分析、マルチモーダル セキュリティの 3 つの領域をカバーする、きめ細かく手動で注釈が付けられた嗜好比較データ 120,000 組が含まれています。データ量は既存のリソースをはるかに超えており、100,000 を超えるマルチモーダル タスク インスタンスをカバーします。各データは 50 人以上の注釈者によって慎重に採点および解釈されており、データの品質と粒度の高さが保証されています。
直接使用します:https://go.hyper.ai/sTfNc
3. GAIA ビジュアル言語リモートセンシング画像理解データセット
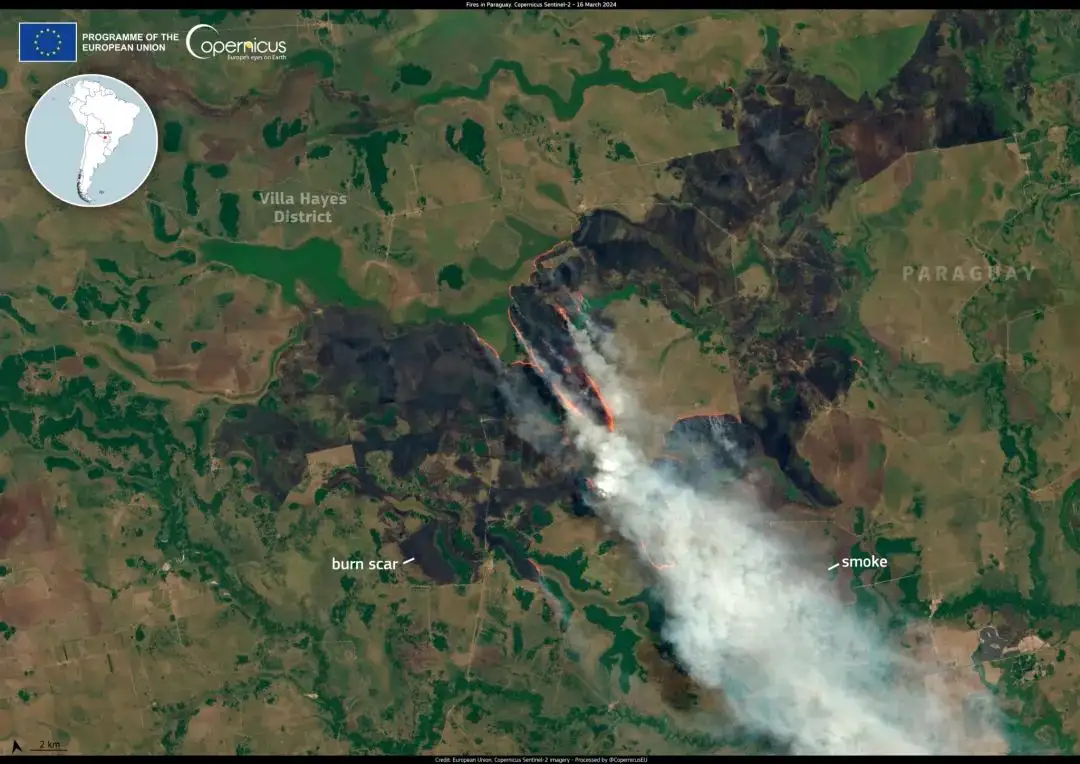
GAIA は、リモート センシング画像分析用のグローバル、マルチモーダル、マルチスケールの視覚言語データセットであり、リモート センシング (RS) 画像と自然言語理解のギャップを埋めることを目的としています。このデータセットは、多様な地理的領域、衛星ミッション、リモートセンシング手法を網羅した 25 年間の地球観測データ (1998 ~ 2024 年) を網羅しています。
直接使用します:https://go.hyper.ai/JHgSb
4. OpenR1-Math-220k 数学推論データセット
OpenR1-Math-220k は、DeepSeek R1 によって生成された 800,000 件の推論トレースから派生した 220,000 件の高品質な数学問題とその推論トレースを含む大規模な数学推論データセットです。
直接使用します:https://go.hyper.ai/VkUMt
JuDGE は、中国の法制度向けに設計された法的文書生成ベンチマーク データセットです。このデータセットは、特に法的推論と文書作成において、高品質の注釈付きデータを通じて法的文書生成モデルのパフォーマンスを向上させることを目的としています。法的インテリジェント システム、法的文書の自動生成、法的質疑応答システムなど、さまざまなアプリケーション シナリオに適しています。
直接使用します:https://go.hyper.ai/Fygtg
6. NTIRE2025 CDFSOD小サンプル物体検出データセット
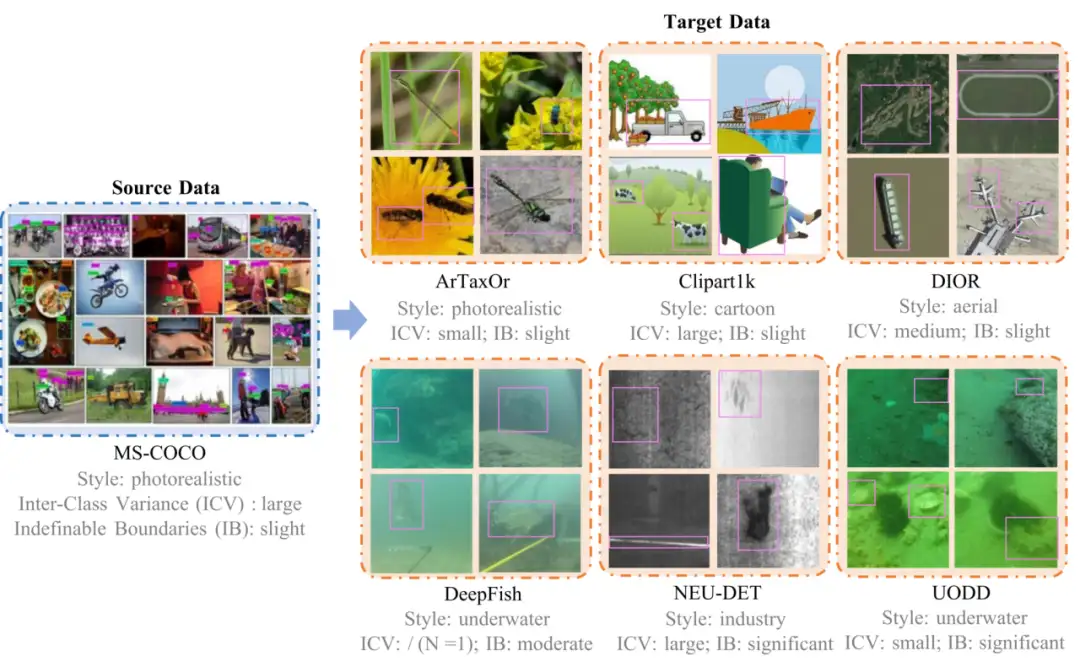
このデータセットは、最初のクロスドメイン小サンプルオブジェクト検出チャレンジ NTIRE 2025 で使用され、ソース データセット COCO と、ArTaxOr、Clipart1k、DIOR、DeepFish、NEU-DET、UODD などの複数の検証データセットが含まれています。このデータセットの中心的な研究課題は、非常に限られた注釈付きターゲット画像のみを使用して、クロスドメイン シナリオでターゲット検出を実行する方法です。
直接使用します:https://go.hyper.ai/kGZhW
7. 猫の引っかき傷YOLO形式検出 猫の引っかき傷オブジェクトYOLO形式検出データセット
このデータセットは、猫が物をひっかいていることを検出するための YOLO 形式のデータセットです。背景付きの画像が約 1,500 枚含まれています。各画像には YOLO と互換性のある .txt ラベル ファイルがあり、猫が何かをひっかいているかどうかを識別するためのオブジェクト検出モデルのトレーニングに使用できます。
直接使用します:https://go.hyper.ai/wkzNJ

8. 中国語 DeepSeek R1 蒸留データ DeepSeek-R1 蒸留データセットに基づく 11 万の中国語
このデータセットは、中国のオープンソースの精錬された完全な R1 データセットです。データセットには数学データだけでなく、大量の一般型データも含まれており、総量は 110K です。
直接使用します:https://go.hyper.ai/5zvRt
このデータセットは、スマート TV ジェスチャー コントロール システム用に特別に構築されており、独立して収集された約 500 個の短いビデオ サンプルが含まれています。各ビデオ クリップは 2 ~ 3 秒間続き、ジェスチャの最初の動きから完全な表示までの動的なプロセスを完全に記録します。これらのジェスチャには、親指を立てる、親指を下げる、左にスワイプする、右にスワイプする、停止するなどがあり、ジェスチャ認識モデルの個別のトレーニング サンプルとして機能します。サンプルは、実際のユーザー間で起こり得る操作習慣の違いを捉えるために、立ったり座ったりといったさまざまなインタラクティブな姿勢をカバーし、さまざまな年齢(18〜65歳)、性別、肌の色の参加者が協力して完成させました。
直接使用します:https://go.hyper.ai/nMdjB

このデータセットは、テキストから画像への生成モデルのトレーニングと評価に豊富なフィードバックを提供するように設計されており、15,000 枚の画像が含まれています。 15 万人を超える人々から提供された 150 万件の注釈を収集し、画像の評価、意味の一貫性、修正の提案などのフィードバックを網羅しています。
直接使用します:https://go.hyper.ai/GhD9w

選択された公開チュートリアル
長い間、YOLO フレームワークのネットワーク アーキテクチャの強化は、コンピューター ビジョンの分野における中心的なトピックでした。注意メカニズムはモデリング機能に優れていますが、注意ベースのモデルは速度面で匹敵することが難しいため、CNN ベースの改善が依然として主流となっています。しかし、YOLOv12 の導入によりこの状況は変わりました。速度面では CNN ベースのフレームワークに匹敵するだけでなく、アテンション メカニズムのパフォーマンス上の利点を最大限に活用し、リアルタイム オブジェクト検出の新たなベンチマークとなります。
このプロジェクトの関連モデルと依存関係がデプロイされました。コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります。
オンラインで実行:https://go.hyper.ai/Wy1So

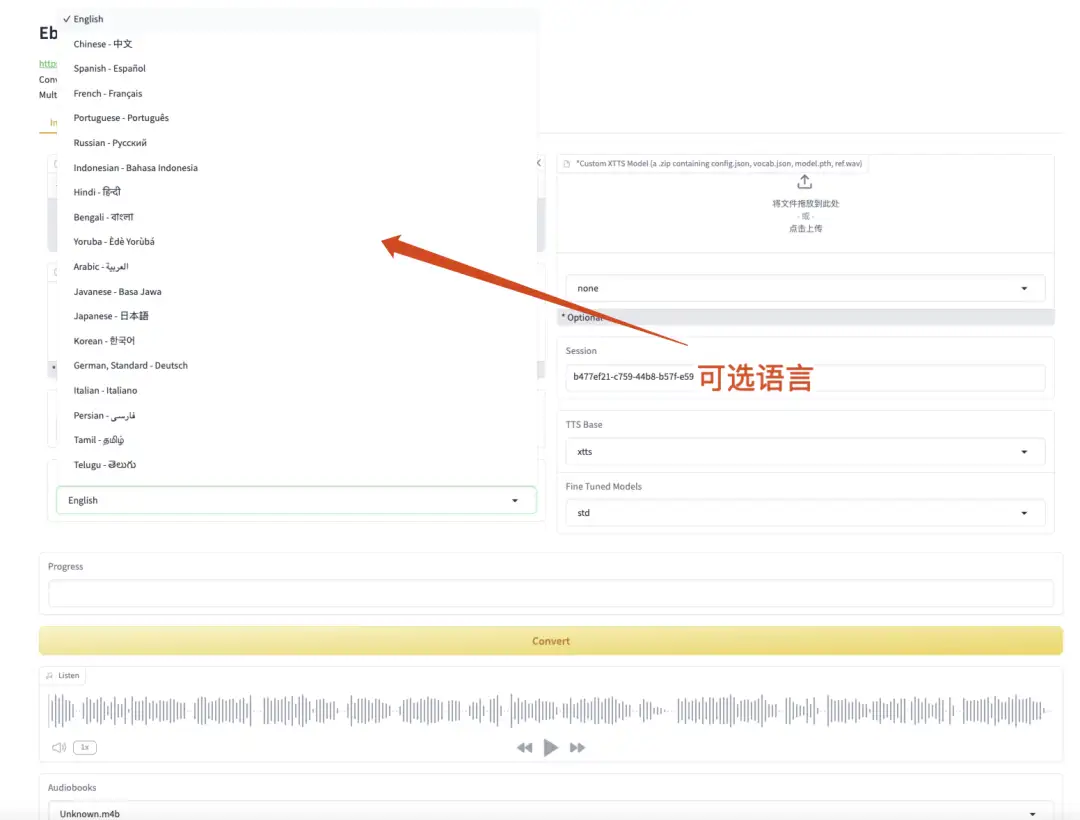
2. Ebook2Audiobook 電子書籍をオーディオブックに変換
Ebook2Audiobook は、電子書籍 (eBook) をオーディオブック (オーディオブック) に変換するために設計されたオープン ソース ツールです。このプロジェクトでは、高度なテキスト読み上げ (TTS) 技術を使用して、電子書籍内のテキスト コンテンツを自動的に音声に変換し、ユーザーが聞くことができるオーディオブックを生成します。 Ebook2Audiobook は、EPUB、PDF、MOBI などの複数の電子書籍形式をサポートし、章の構造とメタデータを保持できるため、生成されたオーディオブックのナビゲートと理解が容易になります。
公式サイトにアクセスしてコンテナをクローンして起動し、API アドレスを直接コピーしてからモデルを起動します。
オンラインで実行:https://go.hyper.ai/sgLbN
注目のコミュニティ記事
1. 精度は97%に達する。オーストラリアチームの新たな成果は、ディープラーニングに基づいて頭蓋骨CTで性別を識別し、人間の法医学者を上回るものである。
西オーストラリア大学などのチームは、ディープラーニングに基づく自動化フレームワークの使用を提案した。この研究では、インドネシアの病院の頭蓋骨CTスキャン200枚を使用して、3つのディープラーニングベースのネットワーク構成をトレーニングおよびテストした。最も正確なディープラーニングフレームワークは、性別と頭蓋骨の特徴を組み合わせて判断することができ、分類精度は97%で、人間の観察者の82%を大幅に上回った。この記事は、その論文を詳細に解釈して共有したものです。
レポート全体を表示します。https://go.hyper.ai/0rfjM
2. 1.7K深センの住宅価格を例にとると、浙江大学GIS研究所は注目メカニズムを使用して地理的コンテキストの特徴をマイニングし、空間非定常回帰の精度を向上させます。
浙江省GIS重点研究室の研究者らは、注目メカニズムに基づくディープラーニングモデルCatGWRを提案した。このモデルは、サンプル間の空間距離とコンテキストの類似性を組み合わせて空間の非定常性をより正確に推定するための注意メカニズムを導入します。これにより、特に複雑な地理的現象を扱う場合に、地理空間モデリングに新たな視点が提供され、空間の異質性とコンテキストの影響をより適切に捉えることができます。この記事は、研究の詳細な解釈と共有です。
レポート全体を表示します。https://go.hyper.ai/irDAo
3. 数学/コード/科学/パズルを網羅した高品質の推論データセットがまとめられ、DeepSeekの強力な推論機能を再現するのに役立ちます。
HyperAI は、数学、コード、科学、パズルなど、複数の分野を網羅する最も人気のある推論データセットを慎重にまとめました。これらのデータセットは、大規模モデルの推論機能を大幅に向上させたいと考えている実務家や研究者にとって優れた出発点となります。この記事はデータセットのダウンロードアドレスです。
レポート全体を表示します。https://go.hyper.ai/XGIi8
4. ICLR 2025に選出されました!浙江大学の沈春華らがボルツマンアライメント技術を提案し、タンパク質結合自由エネルギーの予測がSOTAに到達
浙江大学らは、事前学習済みの逆折り畳みモデルの知識を結合自由エネルギーの予測に転用する「ボルツマンアラインメント」という手法を提案した。この手法は優れたパフォーマンスを示し、人工知能分野の最高峰の国際学術会議であるICLR2025に採用された。この記事は、その論文を詳細に解釈して共有したものです。
レポート全体を表示します。https://go.hyper.ai/MsUDj
NVIDIA は、MIT などと共同で、新しいタイプの大規模フロー タンパク質バックボーン ジェネレーターである Proteina を開発しました。 Proteina は RFdiffusion モデルの 5 倍のパラメータ数を持ち、トレーニング データを 2,100 万の合成タンパク質構造に拡張しました。de novo タンパク質バックボーン設計で SOTA パフォーマンスを達成し、最大 800 残基という前例のない長さの多様で設計可能なタンパク質を生成しました。その成果は ICLR 2025 Oral に選出されました。この記事は、研究の詳細な解釈と共有です。
レポート全体を表示します。https://go.hyper.ai/n4fWv
6. 政府活動報告では再び「人工知能+」について言及され、2つのセッションにおける技術リーダーの提案は、AI+医療/AI変顔・変声/大型モデル錯覚に焦点を当てていました...
雷軍、周紅毅、劉青鋒などの業界リーダーは時代の波をしっかりと追い、新エネルギー車、大型模型幻覚、AI医療、AI変顔、AI教育など多くの重要な分野で積極的に提案や提言を行った。詳細については下記をご覧ください。
レポート全体を表示します。https://go.hyper.ai/EazuY
人気のある百科事典の項目を厳選
1. 拡散損失
2. 因果的注意
3. コルモゴロフ-アーノルド表現定理
4. 大規模マルチタスク言語理解MMLU
5. 対照学習
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。
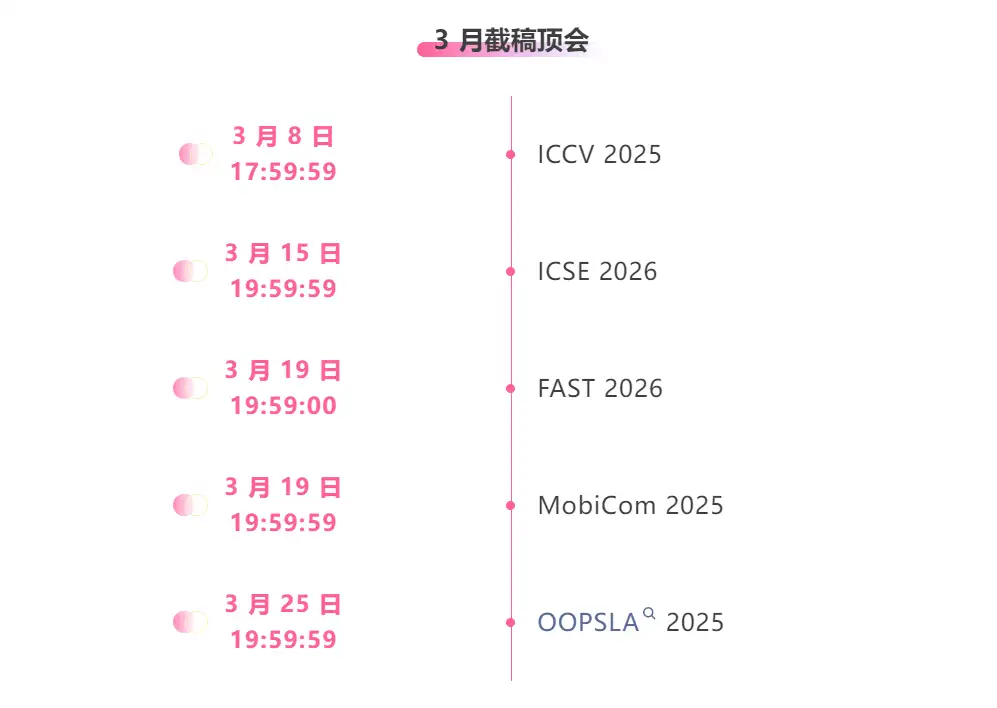
主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!








