Command Palette
Search for a command to run...
清華大学チームは初めて分子生成と物性予測の統合を実現し、二段階拡散生成メカニズムを提案し、ICLR 2025に選出されました。

人工知能技術は医薬品開発のプロセスを大きく変えつつあります。その中で、分子特性予測と分子生成という2つの中核タスクは、長い間、独立した技術的道筋に沿って発展してきました。分子特性予測の目的は、分子構造情報に基づいて分子の多様な化学的・生物学的特性を予測し、薬物スクリーニングを加速することです。分子生成は、分子データの分布を推定し、原子間の相互作用や立体配座情報を学習し、化学的に妥当な新しい分子をゼロから生成できるようにすることで、薬物設計の可能性の境界を広げることを目指しています。近年、これらの分野では多くの研究が行われていますが、それらは大部分が独立して発展してきました。これら 2 つの重要なリンク間の協力チャネルを効果的に開設することはこれまで不可能でした。
これを考慮して、清華大学と中国科学院のチームは、拡散モデルに基づいて 2 つのタスクの共同強化を初めて実現した UniGEM モデルを提案しました。研究チームは、生成と特性予測は高度に相関しており、効果的な分子表現に依存していると指摘した。研究チームは革新的な2段階生成プロセスを提案し、従来の共同トレーニングにおける矛盾を克服し、分子生成と特性予測の分野に新たな道を切り開きました。この成果は、「UniGEM: 分子の生成と特性予測への統一アプローチ」というタイトルで ICLR 2025 に選出されました。

用紙のアドレス:
https://openreview.net/pdf?id=Lb91pXwZMR
QM9量子化学データセット:
GEOM-Drugs 3D分子コンフォメーションデータセット:
オープンソース プロジェクト「awesome-ai4s」は、200 を超える AI4S 論文の解釈をまとめ、膨大なデータ セットとツールを提供します。
https://github.com/hyperai/awesome-ai4s
生成と予測のタスクを統合する動機
研究チームは、生成タスクと予測タスクの両方の本質は分子表現の学習にあると考えています。一方、さまざまな分子事前トレーニング方法の有効性は、分子特性の予測が基盤として堅牢な分子表現に依存していることを示しています。一方、分子生成では、生成プロセス中に適切な表現を作成できるように、分子構造を深く理解する必要があります。
最近の研究結果はこの見解を裏付けています。たとえば、コンピューター ビジョンの研究では、拡散モデル自体が効果的な画像表現を学習する能力を持っていることが示されています。分子領域では、生成的な事前トレーニングによって分子特性の予測タスクを強化できることが研究で示されていますが、これらの方法では、最適な予測パフォーマンスを実現するために追加の微調整が必要になることがよくあります。さらに、予測子は分類器ガイダンス方法を介して分子生成をガイドできますが、予測子のトレーニングによって生成パフォーマンスが直接向上するかどうかは不明です。
そのため、既存の研究では、生成タスクと予測タスクの関係はまだ十分に明らかにされていません。これにより、重要な疑問が生じます。生成タスクと予測タスクの相乗的な強化を実現する統合モデルを構築できるでしょうか?
従来の方法が失敗する理由の分析
これら 2 つのタスクを組み合わせる簡単な方法は、モデルが生成損失と予測損失の両方を最適化する従来のマルチタスク学習フレームワークを使用することです。しかし、研究チームが行った実験では、このアプローチにより、生成タスクと特性予測タスクのパフォーマンスが大幅に低下することがわかりました(生成安定性が6%低下し、予測誤差が1倍以上増加しました)。生成モデルの重みを固定し、プロパティ予測タスク用に別のヘッドを追加して生成パフォーマンスを維持した後でも、研究者は、ゼロからのトレーニングと比較してプロパティ予測パフォーマンスの向上は見られませんでした。
研究者たちは、従来の方法では結果が芳しくないのは、生成タスクと予測タスクの間に本質的に矛盾があるためだと考えている。拡散生成プロセス中、分子構造は無秩序なノイズから微細構造へと徐々に再構築される必要があります。しかし、予測タスクでは、分子構造が基本的に確立された後にのみ、意味のある分子特性を定義できます。したがって、単純なマルチタスク最適化アプローチを採用するだけでは、拡散の初期段階で非常に無秩序な分子構造が誤ってプロパティラベルに関連付けられ、分子生成とプロパティ予測に悪影響を与えることになります。
この点をさらに説明するために、研究者らは、拡散トレーニング中のノイズ除去ネットワーク内の中間表現とターゲット分子間の相互情報量の理論的分析を実施しました。さらに、拡散モデルは中間表現と標的分子間の相互情報量の下限を暗黙的に最大化することが理論的に証明されており、拡散モデル表現学習の能力を示しています。しかし、中間表現とターゲット分子間の相互情報量は単調に減少する傾向を示し、より大きな時間ステップではゼロに近づくため、無秩序段階の中間表現では効果的な予測をサポートできません。したがって、直感と理論の両方から、分子が比較的秩序立った状態にある場合、生成タスクと予測タスクはより小さな時間ステップでのみ調整できることが示唆されます。
二段階拡散生成メカニズム
上記の分析に基づいて、研究チームは、下図に示すように、分子特性の予測と生成を統合することを目的とした新しい2段階生成法を提案しました。
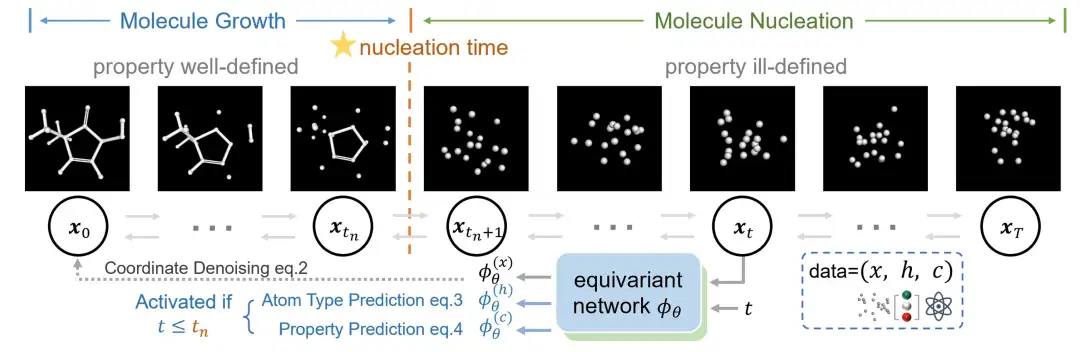
研究者らは分子生成プロセスを2段階に分けた。すなわち「分子核形成段階」と「分子成長段階」である。この部門は物理学における結晶形成プロセスにヒントを得たものです。
分子核形成段階では、分子は完全に無秩序な状態から骨格を形成し、その後、この骨格に基づいて完全な分子が成長します。これら 2 つの段階は、「核生成時間」によって区切られます。研究者らは、これら 2 つの段階を記述するために分子を生成する新しい方法を導入しました。その中で、「核形成時間」の前に、拡散モデルは徐々に分子座標を生成し、核形成後は、モデルは特性と原子タイプの予測損失を最適化しながら分子座標を調整し続けます。
通常、原子の種類と座標の結合拡散を実行する従来の生成モデルとは異なり、この革新的な方法は、座標の拡散のみに焦点を当て、原子の種類を個別の予測タスクとして扱います。研究者たちは、形成された分子の座標から原子の種類を推測できることが多いことに気づいたからです。具体的には、核形成前に拡散プロセスは座標を再構築することを目的としており、核形成後には原子の種類と特性の予測損失を統一された学習フレームワークに統合します。
UniGEMトレーニング戦略
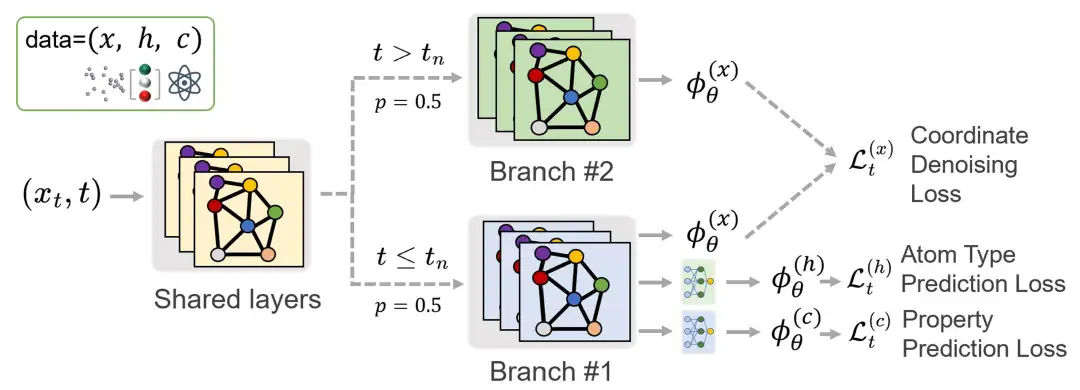
従来の結合拡散法との比較を容易にするために、研究者らはネットワーク構造の骨格としてEGNNを使用したE(3)等変拡散モデル(EDM)を採用した。そのうち、成長段階はトレーニングプロセス全体の約 1% を占めるだけです。標準的な拡散トレーニング手順に従い、時間ステップを均一にサンプリングすると、予測タスクの反復回数はトレーニングプロセス全体の 1% のみになり、このタスクでのモデルのパフォーマンスが大幅に低下します。そのため、予測タスクに適切なトレーニングを確実に行うために、研究者は成長段階の間に時間ステップをオーバーサンプリングしました。
しかし、研究者らは、オーバーサンプリングによって時間ステップの範囲全体でトレーニングのバランスが崩れ、それが生成プロセスの品質に影響を及ぼす可能性があることを観察しました。この問題を解決するために、マルチブランチ ネットワーク アーキテクチャが提案されています。ネットワークは浅い層ではパラメータを共有しますが、深い層ではそれぞれ独立したパラメータ セットを持つ 2 つのブランチに分割されます。これらのブランチはトレーニングのさまざまな段階で活性化されます。1つのブランチは核形成段階に焦点を当て、もう1つは成長段階を扱います。下の図の通りです。この設計により、予測タスクと生成タスクが互いに影響を与えることなく効果的にトレーニングできるようになります。
UniGEMの推論プロセス
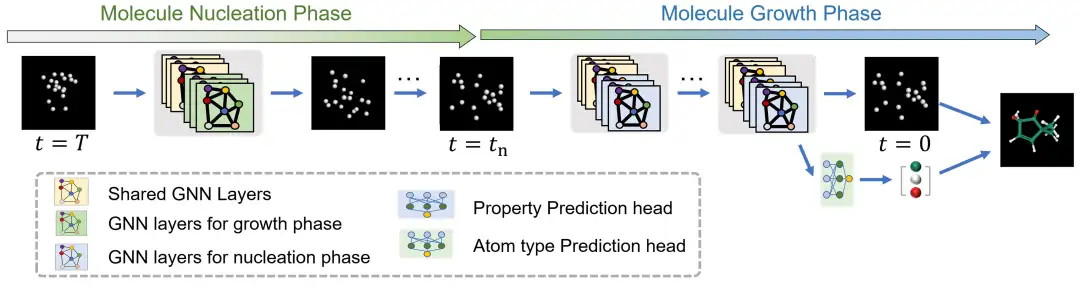
UniGEMでは、分子生成は、逆拡散プロセスを通じて原子座標を再構築し、生成された座標に基づいて原子の種類を予測することによって行われます。写真の通りです。プロパティ予測では、ネットワーク入力時間ステップがゼロに固定され、プロパティ予測ヘッドが使用されます。このアプローチでは、生成タスクと予測タスクの両方で追加の計算オーバーヘッドが発生せず、合計推論時間はベースラインと同じであることは注目に値します。
分子生成タスクでは、研究者らは UniGEM と従来の共同生成方法の間の生成誤差の違いも分析しました。まず、UniGEM における原子タイプ予測損失の誤差は、結合生成における原子タイプノイズ除去生成損失よりも小さいことがわかります。第二に、結合生成プロセス中に、座標生成は原子タイプ予測結果の振動の影響を受け、エラーが増加します。最後に、ジョイント生成法では、より大きな初期分布誤差と離散化誤差も発生します。これらの要素が組み合わさって、UniGEM が優れた生成結果を達成する仕組みが説明されます。
実験結果: 分子生成と特性予測の両方のタスクにおいてベースラインモデルを上回る
分子生成: UniGEM がベンチマーク モデルを上回る
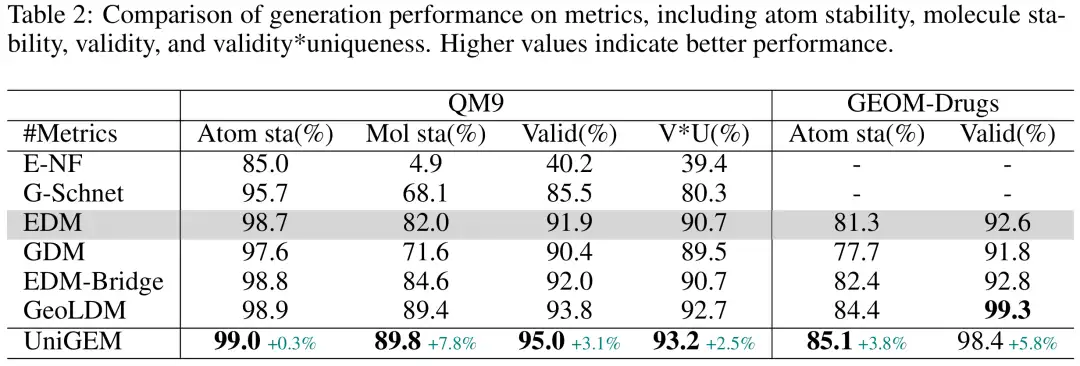
研究者らはまず、QM9 および GEOM-Drugs データセットで EDM ベースの UniGEM と EDM バリアントを比較しました。次の図に示すように、UniGEM はほぼすべての評価指標でベースライン モデルを上回りました。他のEDMの変種と比較して、UniGEM は、事前の知識に依存せず、追加のオートエンコーダトレーニングも必要としないため、大幅にシンプルですが、EDM-Bridge や GeoLDM よりもパフォーマンスが優れており、UniGEM の利点が強調されています。
さまざまな生成アルゴリズムに適応する UniGEM の柔軟性を実証するために、研究者らは UniGEM をベイジアンフローネットワーク (BFN) に適用し、QM9 データセット上で座標と原子タイプを共同生成する GeoBFN を上回り、SOTA 結果を達成しました。
さらに、研究者らは条件付き生成タスクにおける UniGEM のパフォーマンスをテストし、サンプリング プロセス中にモデル独自のプロパティ予測モジュールをガイドとして使用することで、条件付き生成モデルを再トレーニングする必要性を回避しました。
分子特性予測: UniGEM はほとんどの事前トレーニング方法を上回る
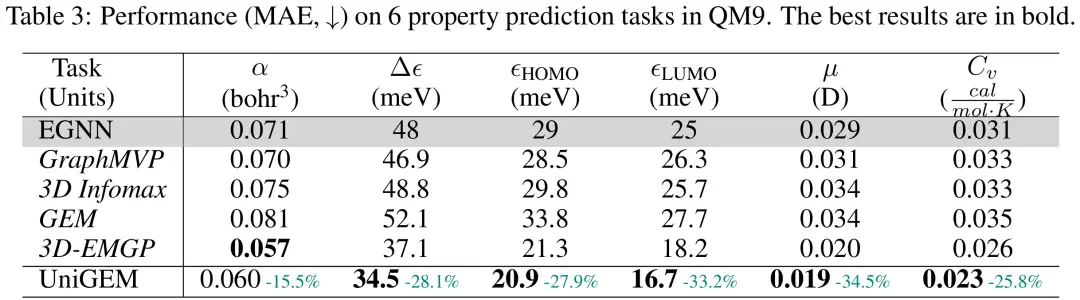
研究者らは、テスト セットの平均絶対誤差 (MAE) を評価基準として使用して、QM9 データセットでの UniGEM プロパティ予測のパフォーマンスを評価しました。図に示すように、UniGEM は、最初からトレーニングされた EGNN を大幅に上回り、統合モデリングの有効性を実証しています。驚くべきことに、UniGEM は、追加の大規模な事前トレーニング データセットを活用しているにもかかわらず、これらの最先端の事前トレーニング方法のほとんどよりも優れたパフォーマンスを発揮します。これは、生成と予測のための統合モデルの利点を強調しており、追加のデータや事前トレーニングの手順を必要とせずに、生成プロセス中に分子表現学習の力を効果的に活用できます。
結論
UniGEM モデルは分子生成と特性予測のタスクを統合し、両方のパフォーマンスを大幅に向上させます。 UniGEM の強化されたパフォーマンスは、堅実な理論的分析と包括的な実験研究によってサポートされています。私たちは、革新的な二段階生成プロセスとそれに対応するモデルが分子生成フレームワークの開発に新たなパラダイムを提供し、より高度な分子生成フレームワークの開発を刺激し、それによってより具体的な応用分野での分子生成に利益をもたらす可能性があると考えています。
この研究はATOM Labが主導しています。同チームは分子事前トレーニング、分子生成、タンパク質構造予測、仮想スクリーニングなどの分野でより多くの研究成果を上げていますので、ぜひご注目ください!
ATOM Labホームページへようこそ:
https://atomlab.yanyanlan.com/
著者について:
* ラン・ヤンヤンは、清華大学インテリジェント産業研究所 (AIR) の教授です。彼女の研究分野には、AI4Science、機械学習、自然言語処理などがあります。
* Shikun Feng 氏は、清華大学インテリジェント産業研究所 (AIR) の博士課程の学生です。彼の研究対象には、表現学習、生成モデル、AI4Science などがあります。
* Yuyan Ni は、中国科学院数学・システム科学アカデミー (AMSS) の博士課程の学生です。彼女の研究対象には、生成モデル、表現学習、AI4Science、ディープラーニング理論などがあります。
この論文の主著者である Shikun Feng 博士と Yuyan Ni 博士は現在、就職活動中です。ご興味のある方はご連絡ください。
* 馮世坤のメールアドレス: [email protected]
* Ni Yuyanのメールアドレス: [email protected]








