Command Palette
Search for a command to run...
ICLR 2025に選出されました!浙江大学の沈春華らがボルツマンアライメント技術を提案し、タンパク質結合自由エネルギーの予測がSOTAに到達

タンパク質間相互作用 (PPI) は、すべての生物がさまざまな生物学的機能を実行するための基礎であり、主に異なるタンパク質分子間の相互作用と影響を通じて実現されます。タンパク質間の相互作用を正確に特定し理解することは、タンパク質の機能の解明、生命活動の解明、疾患のメカニズムの探究、標的薬の開発、生物学的応用の革新にとって極めて重要です。
コンピュータと人工知能の発展に伴い、科学研究コミュニティにおける PPI の研究は、ディープラーニングのサポートにより近年大きく進歩しました。特にDeepMindが2024年にリリースするAlphaFold 3は、一般的なタンパク質複合体の構造予測の成功率は、80% 近くまで向上しました。これにより、何十年にもわたって科学研究コミュニティを悩ませてきた、タンパク質相互作用の高精度計算モデリングの問題も効果的に解決されます。
しかし、タンパク質間の相互作用は結合と解離を含む動的なプロセスであり、静的な構造のみを研究するだけでは、生体分子間の相互作用を完全に捉えることは困難です。結合自由エネルギー(ΔG、結合状態と非結合状態の間のギブス自由エネルギーの差)などのパラメータは、タンパク質間相互作用のダイナミクスを定量的に特徴付けることができます。しかし、結合自由エネルギーの変化(∆∆G、突然変異効果とも呼ばれる)を正確に予測する方法は、科学界がタンパク質間相互作用を理解または制御するための前提条件の 1 つになっています。
これを基に、浙江大学コンピュータ科学技術学部の沈春華教授のチームは、オーストラリアのアデレード大学と米国のノースイースタン大学のチームと共同で、私たちは、事前にトレーニングされた逆フォールディングモデルから ∆∆G の予測に知識を転送するためのボルツマンアライメントと呼ばれる手法を共同で提案します。この研究では、まず∆∆G の熱力学的定義を分析し、ボルツマン分布を導入することでエネルギーとタンパク質の立体配座分布を関連付け、事前トレーニング済みの確率モデルの可能性を強調しました。次に研究チームはベイズの定理を用いて直接的な推定を回避し、タンパク質逆折り畳みモデルによって提供される対数尤度を使用して ∆∆G を推定しました。この導出は、他の以前の実験で観察された逆折り畳みモデルの結合エネルギーと対数尤度との間の高い相関関係を合理的に説明します。
従来の逆折り畳みベースの方法と比較して、SKEMPI v2 データセットでのこの方法の実験結果は優れたレベルを示しています。教師ありおよび教師なしの状態におけるスピアマン係数はそれぞれ 0.5134 と 0.3201 に達しました。以前の SOTA 方法の 0.4324 および 0.2632 よりも大幅に高い値です。
この成果は、「タンパク質間相互作用に対する変異効果の予測因子としてのボルツマン整列逆フォールディングモデル」と題され、人工知能分野における最高峰の国際学術会議である ICLR 2025 に収録されました。今年の ICLR には合計 11,565 件の投稿があり、そのうち 32,08% のみが採択されたことは特筆に値します。

用紙のアドレス:
https://arxiv.org/abs/2410.09543
学術共有イベントを推奨します。最新の Meet AI4S ライブ ブロードキャスト招待は、3 月 7 日の正午です。華中科技大学の黄紅准教授、上海人工知能研究所AI科学センターの若手研究員周東展氏、上海交通大学自然科学研究所の助手研究員周秉馨氏、個人の業績を紹介し、科学研究の経験を共有します。
ディープラーニングは突然変異効果の計算におけるパラダイムシフトを加速する
科学界は長い間、∆∆G の予測を研究してきました。従来の方法は、生物物理学的方法と統計的方法の 2 つのカテゴリに分けられます。その中で、生物物理学的手法は主にエネルギー計算を通じてタンパク質が原子レベルでどのように相互作用するかをシミュレートし、統計的手法は主に記述子を使用してタンパク質の幾何学的、物理的、進化的特性を捉える特徴エンジニアリングに依存しています。
どのような従来の方法を使用する場合でも、人間の専門知識に大きく依存する必要があり、時間と労力がかかるだけでなく、タンパク質間の複雑な相互作用を正確に捉えることができないのは間違いありません。さらに、どちらの方法にもそれぞれ欠点があります。たとえば、生物物理学的方法では、速度と精度のバランスを取ることが課題となることがよくあります。ディープラーニングベースの方法は、タンパク質モデリングにおいて優れた「才能」を発揮するだけでなく、∆∆G 予測パラダイムの変革を加速します。
これを証明する事例はますます増えています。たとえば、中国科学院のチームは、SidechainDiff と呼ばれる表現学習ベースの方法を提案しました。この方法は、リーマン拡散モデルを使用して側鎖コンフォメーションの生成プロセスを学習し、タンパク質間界面における変異の構造的背景表現を提供することもできます。この方法は、学習した表現を使用して、タンパク質間の結合に対する突然変異の影響を予測する上で最先端のパフォーマンスを実現します。
この結果は「側鎖拡散確率モデルによるタンパク質間結合に対する変異の影響の予測」と題され、NeurIPS 2023 に含まれています。
* 紙のアドレス:
ディープラーニングベースの手法はかなりの成果を上げていますが、完璧ではありません。上記の例と偶然にも、この論文では、「結合エネルギーの注釈に関する実験データが不足している」とも述べられています。これは一般に、ディープラーニング手法に基づく大きな課題であると考えられており、突然変異を予測する能力を向上させる前に、多くのチームが大量のラベルなしデータセットで事前トレーニングする傾向に直接つながっています。これには、上記の例のタンパク質逆フォールディング、マスクモデリング、側鎖モデリングなど、さまざまな事前トレーニングエージェントタスクが含まれます。
幸いなことに、これらの「代替」方法は目標を達成しましたが、残念ながら、例外なく弱点も明らかになりました。事前トレーニングベースの方法のほとんどは、教師あり微調整 (SFT) のみを使用します。しかし、彼らはデータの調整の重要性を無視しており、教師ありの微調整によってモデルが教師なしの事前トレーニング中に以前に獲得した一般的な知識を忘れてしまい、過剰適合のリスクが生じる可能性があります。振り返ってみると、これらの「代替」方法は、獲得した知識を正確な突然変異予測に転用することの緊急性を間違いなく浮き彫りにしています。
SOTAモデルを超えるボルツマンアライメントの革新的な開発
具体的には、研究チームはまずボルツマン分布と熱力学サイクルの原理に基づいて、タンパク質が変異したときの結合自由エネルギーの変化は、タンパク質のアミノ酸配列の可能性に関連しています。ボルツマンアライメントが提案されました(下の図の右側に示すように)。その後、研究チームは、逆フォールディングモデルをボルツマンアラインメントに統合し、逆フォールディングモデルを使用してタンパク質配列の尤度を予測することで変異を評価するBA-Cycleと呼ばれる手法を提案しました(下図の左側を参照)。
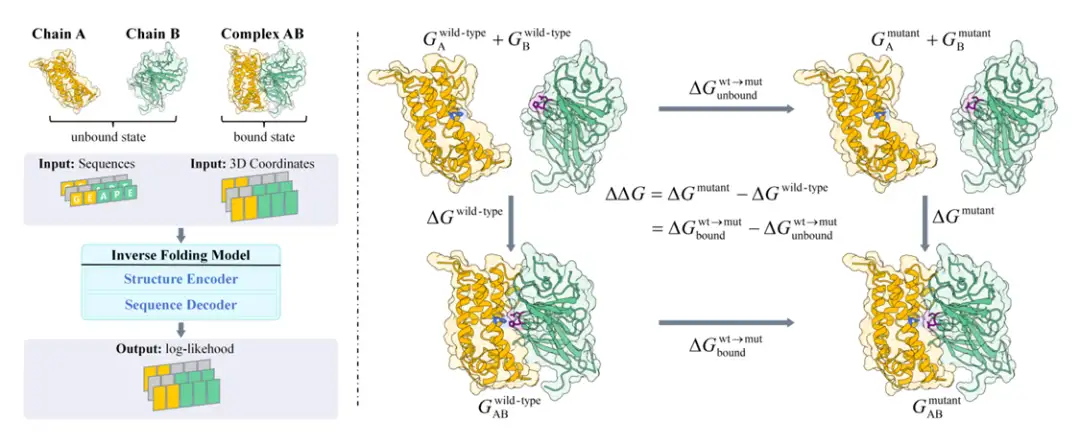
タンパク質結合自由エネルギーとタンパク質配列条件付き確率の関係を確立し、与えられた配列下でのタンパク質構造の確率 p(X|S) を直接推定する際に直面する 2 つの大きな困難を解決するためには、次の点に留意する必要があります。既存のタンパク質構造予測モデルの限界と確率モデルの欠点、研究チームは、結合自由度の計算式p(X|S) = p(S|X) ・ p(X)/p(S)にベイズの定理を代入し、結合自由エネルギーとタンパク質配列の条件付き確率p(X|S)を結び付けることに成功し、p(X|S)を直接推定する困難さを回避しました。これにより、結合自由エネルギーの変化とタンパク質配列の条件付き確率の関係をさらに解析するための基礎が築かれました。
また、変異前後でタンパク質の構造は変化しないと仮定されているため、研究チームは、逆折り畳みモデルを使用して、結合状態と非結合状態の配列確率を評価しました。結合状態のバックボーン構造は通常既知であり、モデルは直接その確率を計算できます。一方、非結合状態のバックボーン構造は明示的に与えられておらず、複合体内の 2 つの鎖を個別に評価することによって確率を推定できます。
これに基づいて、研究チームは、∆∆G の教師なし推定に BA-Cycle と呼ばれる手法を提案しました。∆∆G の教師なし評価は、事前トレーニング済みの逆折り畳みモデル ProteinMPNN を使用して実現されました。これは、熱力学サイクルにおける非結合状態の確率を明示的に考慮しなかった以前の関連研究とはまったく対照的です。
やっと、研究チームはBA-DDGと呼ばれる方法も提案した。BA サイクルは、結合自由エネルギー変化ラベル データを使用してボルツマン アライメントによって微調整されました。 BA-DDG は BA-Cycle と同じフォワード プロセスを使用します。 BA-DDG の目標は、元の事前トレーニング済みモデルの分布を維持しながら、実際の結合自由エネルギー変化と予測された結合自由エネルギー変化のギャップを最小限に抑えることです。
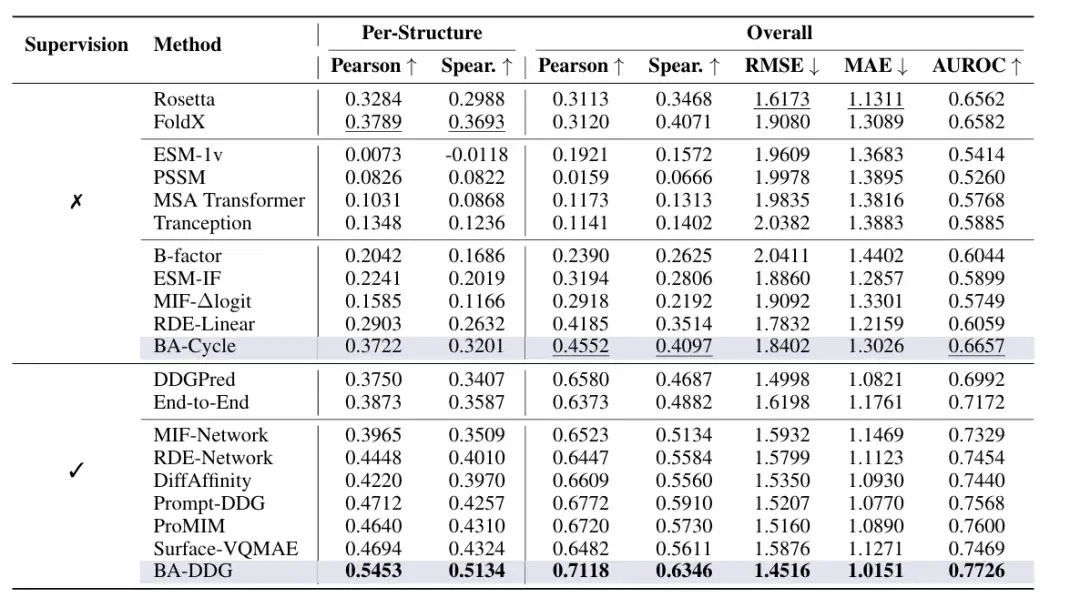
研究チームは、SKEMPI v2 データセットに対して一連の実験検証を実施しました。そのうち、SKEMPI v2 データセットは、7,085 個のアミノ酸変異と熱力学的パラメータおよび運動速度定数の変化を含む 348 個のタンパク質複合体を含む注釈付き変異データセットです。
評価指標は全部で 7 つあり、その中にはピアソン相関係数、スピアマンの順位相関係数、最小二乗平均平方根誤差 (RMSE)、最小平均絶対誤差 (MAE)、AUROC の 5 つの総合指標が含まれます。さらに、研究チームは変異を構造的特徴に応じてグループ分けし、各グループについてピアソン相関係数とスピアマン相関係数を2つの追加指標として計算した。
研究チームはまず、BA-CyaleとBA-DDGをSOTAの教師なしおよび教師あり手法と比較した。教師なし手法には、Rosetta Cartesian ∆∆G や FoldX などの従来の経験的エネルギー関数、ESM-1v、Position-Specific Scoring Matrix (PSSM)、MSA Transformer、Tranception などのシーケンス/進化ベースの手法、および ESM-1F、MIF-∆logits、RDE-Linear、B-factor など、∆∆G ラベルでトレーニングされていない構造情報に基づく事前トレーニング済み手法の 3 種類があります。
教師あり学習法は、DDGPred や End-to-End などのエンドツーエンド学習モデルと、MIF-Network、RDE-Network、DiffAffinity、Prompt-DDG、ProMIM、Surface-VQMAE などの ∆∆G に基づいて微調整された構造情報に基づく事前トレーニング法の 2 つのカテゴリに分けられます。
結果は次のようになります。BA-DDG は、すべての評価メトリックにおいてすべてのベースラインを上回ります。そのうち、教師あり法によるピアソン相関係数とスピアマン相関係数はそれぞれ0.5453と0.5134に達した。各構造の相関関係が大幅に改善されたことで、実際のアプリケーションにおける信頼性が向上しました。BA-Cycle は経験的エネルギー関数と同等のパフォーマンスを実現し、すべての教師なし学習ベースラインを上回ります。以下に示すように:
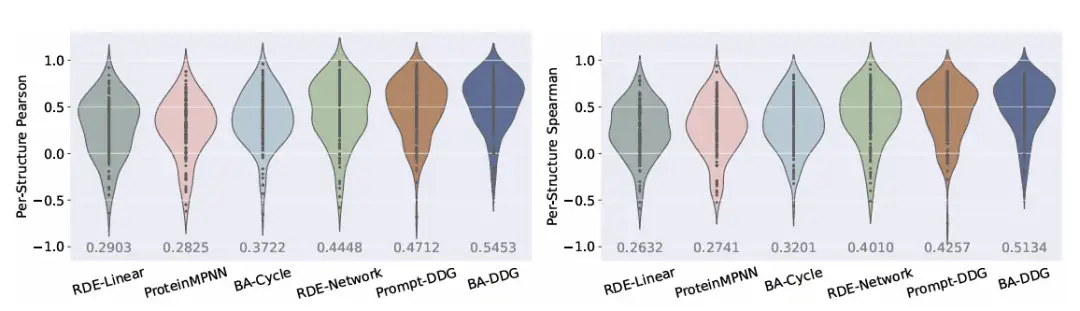
さらに、関連する視覚分析では、BA-DDG は、定性的な視覚化と定量的なメトリックの両方において他の方法よりも優れています。以下に示すように:
さらに、研究者らは結合エネルギー予測、タンパク質間ドッキング、抗体の最適化に関する実験を実施し、その結果は幅広い応用可能性を示しました。これらのプラスの影響は、医薬品の設計や仮想スクリーニングにおいて極めて重要な役割を果たし、将来の実際の応用のための理論的基礎を築くことになります。
機械学習とマシンビジョンを深く育成し、AIの普遍化を実現
本研究では、研究者らは学際的な理論を用いてタンパク質配列解析に新たな視点を提供するとともに、革新的なモデル統合とモデル最適化を通じて体系的な研究枠組みを形成しました。この段階的な研究方法は、タンパク質配列と自由エネルギー変化の関係を十分かつ深く理解するのに役立つだけでなく、その後の研究に新たなアイデアも提供します。
言及する価値があるのはこの研究の主な参加者の一人である沈春華教授は、長年機械学習とコンピュータービジョンの研究に取り組んできました。彼はこれまでに 150 本以上の論文を発表しており、その中には TPAMI や IJCV などの国際的に有名な学術プラットフォームに掲載された論文も含まれています。 2025年に入ってわずか2か月で、沈春華教授率いるチームは重要な成果を上げ、プレプリントプラットフォームarXivに3つの論文を発表しました。
最初の記事では、Shen Chunhua教授の研究グループが、CNNネットワークに基づくDNAベースのモデル「ConvNova」を開発しました。このモデルはデザインがシンプルですが、パフォーマンスは抜群です。関連するヒストンタスクでは、平均スコアが2位の方法5.8%を上回り、より少ないパラメータでより高速な計算を実現しました。同時に、この方法は、CNN ネットワーク アーキテクチャに基づく方法が、Transformer ネットワークおよび SSM ネットワークに基づく方法と比較して、強力な競争の可能性を持っていることも検証します。関連研究は、「DNA 基盤モデルの領域における畳み込みアーキテクチャの再検討」というタイトルで公開されました。
* 紙のアドレス:
https://arxiv.org/abs/2502.18538
2番目の記事では、沈春華教授の研究グループと上海AI研究所が共同で汎用視覚モデルDICEPTIONを開発しました。事前トレーニング済みの拡散モデルは、必要なトレーニング データが少なく、タスクへの適応性が高い、マルチタスク視覚認識問題を解決するために使用されます。このモデルは、わずか 0.06% の SAM データを使用して、セグメンテーションなどのタスクで SOTA モデルに匹敵するレベルを達成し、色分けによってタスク出力を統一することでトレーニング コストを大幅に削減します。関連研究は、「DICEPTION: 視覚知覚タスクのためのジェネラリスト拡散モデル」というタイトルで発表されました。
* 紙のアドレス:
https://arxiv.org/pdf/2502.17157
3 番目の記事では、Shen Chunhua 教授のチームが Alibaba と共同で、物理法則に準拠したビデオを生成するビデオ生成モデルの能力を評価するために使用される PhyCoBench と呼ばれるベンチマークを提案しました。この研究では、オプティカルフローとビデオフレームをカスケード方式で生成する拡散モデルである自動評価モデル PhyCoPredictor も紹介しています。自動選別と手動選別の一貫性評価を比較することにより、実験結果によると、PhyCoPredictor は人間の評価に最も近い能力を持っています。関連研究は、「オプティカルフローガイドフレーム予測によるビデオ生成モデルを評価するための物理的コヒーレンスベンチマーク」というタイトルで公開されました。
* 紙のアドレス:
https://arxiv.org/pdf/2502.05503
沈春華教授のチームは実りある成果を達成しただけでなく、教授個人の影響力も抜群です。沈春華教授が発表した関連論文は、科学研究界において常に重要な引用元となっており、世界的な情報分析会社エルゼビアが発表した「2023年中国高被引用研究者」リストにも選出された。
現在、沈春華教授は浙江大学コンピュータ支援設計と画像システム国家重点実験室の求実主任教授と副所長を3年間務めており、実りある研究成果を上げただけでなく、教育成果も大きく、多くの修士課程と博士課程の学生を育成してきました。また、所在地である国家コンピュータ支援設計・グラフィックスシステム重点研究室は、「産学研」をつなぐインターフェースとしての役割も果たしており、近年多面的な発展を遂げています。アントを含む多くの企業と協力し、科学研究のイノベーション拠点、人材育成拠点、イノベーションインキュベーション拠点となっています。








