Command Palette
Search for a command to run...
オックスフォード大学、アマゾン、ウェストレイク大学、テンセントらは、ゼロサンプルの臨床診断に使用できるマルチモーダル、マルチドメイン、マルチ言語の医療モデルM³FMを提案した。

マーベル映画を愛する多くの友人がこのシーンに驚いたと思います。映画「アイアンマン2」では、人工知能執事ジャービスがスタークの血液サンプルを収集し、ディープラーニングアルゴリズムを使用してサンプルデータを迅速にモジュール化しました。スタークの体内のパラジウム含有量を正確かつ迅速に分析し、「既存の元素はパラジウム金属に代わるものではなく、新しい元素を合成する必要がある」などのレポートを発行しながら、領域を越えた提案さえしました。これはわずか数十秒の映像ですが、スマートヘルスケアの自動化、インテリジェンス、プロセスベースの機能を完璧に示しています。
しかし、現実には、同じ結果を得るためには、医療スタッフは採血や検査、画像分析、データの比較、レポートの発行、病気の分類などの複雑なプロセスを経る必要があります。これはマクロ的な視点で見ただけの話です。細かく見れば、状況はさらに悪化するでしょう。臨床診断で最も一般的なタイプである医療画像を例にとると、医療画像は臨床所見を説明し、病気のさらなる診断の基礎を提供することができます。しかし、医療画像に関するレポートを自然言語で正確かつ簡潔に、完全に、首尾一貫して記述することになると、多くの医療スタッフはそれを頭痛の種で退屈なものだと感じます。統計によると、経験豊富な医師であっても、レポートを完成させるのに平均 5 分以上かかるのが普通です。
幸いなことに、SFはまだ現実を完全に照らし出していないものの、暗闇の隙間から一筋の光がすでに見え始めています。人工知能と医療保健の交差点では、ますます多くの科学研究者が広範な研究を行い、自動レポート生成の方法を開発しています。これらの方法は、医療スタッフが確認、修正、参照するためのドラフトレポートを自動的に生成します。一方では、医療スタッフの時間と労力がかかる作業タスクを効果的に解決でき、他方では、自動化によって人為的エラーの可能性を減らすことができます。
最近、国際的に有名な学術誌「Nature Portfolio」傘下の雑誌「npj Digital Medicine」に、「ゼロショット臨床診断のためのマルチモーダル、マルチドメイン、多言語医療基盤モデル」と題する研究が掲載されました。マルチモーダル(画像とテキスト)、マルチドメイン(CTとCXR)、多言語(中国語と英語)の医療基盤モデルM³FM(マルチモーダル・マルチドメイン・マルチリンガル基盤モデル)について言及しており、ゼロサンプルの臨床診断に使用でき、疾患報告と疾患分類をサポートできます。研究者らは、2 つの感染症と 14 の非感染性疾患に関する 9 つのベンチマーク データセットでこの方法の有効性を実証し、従来の方法よりも優れた結果を示しました。
この研究には豪華な著者陣が名を連ねている。オックスフォード大学、ロチェスター大学、アマゾンなどの研究チームに加え、ウェストレイク大学医療人工知能研究所の鄭葉鋒博士や、テンセントYoutuラボの天眼研究センター所長の呉賢博士も参加している。

用紙のアドレス:
https://www.nature.com/articles/s41746-024-01339-7
オープンソース プロジェクト「awesome-ai4s」は、200 を超える AI4S 論文の解釈をまとめ、膨大なデータ セットとツールを提供します。
https://github.com/hyperai/awesome-ai4s
既存の方法ではデータ損失が依然として問題となっている
医用画像は、医用画像レポートや病気の分類の基礎となり、その後の臨床診断において重要な役割を果たしているため、関連する自動化手法の研究は、当然ながら科学研究分野の研究焦点の 1 つとなっています。しかし、実りある研究結果にもかかわらず、実用的な観点から見るとまだ多くの欠陥が残っています。その中で、データの不足、あるいは完全な欠如が大きな課題となっています。
一方では、病気レポートの生成は、入力画像を説明する説明文を生成することを目的とした画像ベースの言語生成タスクに似ています。従来の基本的な方法は、臨床医が注釈を付けた大量の高品質の医療トレーニング データに大きく依存することが多く、特に希少疾患や英語以外の言語の場合、収集にコストと時間がかかります。
具体的には、新しい病気や希少な病気の場合、初期段階ではトレーニングに有効なデータが十分にない場合がほとんどです。たとえば、2019年後半に世界中で猛威を振るい始めた新型コロナウイルス肺炎では、初期段階で収集できるデータが限られていたため、システムのトレーニング時間が流行の最初の数波の期間をはるかに超える結果となりました。 「2024年中国希少疾患産業動向観察レポート」によると、世界には7,000以上の希少疾患が知られています。控えめな証拠に基づくデータによると、人口における希少疾患の有病率は約3.5%から5.9%であり、世界中で希少疾患に罹患している人の数は約2億6,000万人から4億5,000万人と推定されています。このような大規模かつ非典型的な疾患は、間違いなく上記の問題をより困難なものにします。
さらに、グローバルヘルスケアシステムには、さまざまな地域、さまざまな人口、さまざまな言語が関係しています。英語以外の言語の場合、関連するラベル付きデータは通常非常に不足しているか、まったく欠落しています。したがって、ラベル付きデータが限られていることは、既存の方法を使用する非英語言語トレーニングシステムにとって間違いなく大きな課題となります。同時に、これにより、既存の方法では一般的でない言語への対応が困難になり、AI の公平性の目標にさらに影響を及ぼし、過小評価されているグループに十分な利益をもたらすことができなくなります。
一方で、病気を効果的に分類するために、現在の高度なモデルは主に、BioViL、REFERS、MedKLIP、MRM などの CLIP の成功に触発されており、これらはすべて医療マルチモーダル データをよりよく理解するために開発されています。実装では、これらの方法は対照学習を活用し、医療データを使用して CLIP モデルを事前トレーニングしますが、ほとんどのモデルは胸部 X 線 (CXR) に特化しているため、通常、単一のフレームワーク内でマルチドメイン、マルチ言語の医療画像とテキストを処理することはできません。同時に、これまでの研究では、言語や画像のさまざまな領域でゼロショットの疾患報告を行うこともできませんでした。
* CLIP モデルは、OpenAI によって開発された対照的な言語と画像の事前トレーニング モデルであり、自然言語の監督から学習するための効果的な方法です。 CLIP は主に対照学習を通じて画像とテキストの関連性を学習し、大規模な画像とテキストのペアを事前トレーニングすることで、モデルがさまざまなモダリティからの情報を理解して関連付けることができるようにします。
このような状況では、少数のサンプルまたはサンプルなしで、マルチモーダル、マルチドメイン、およびマルチ言語の臨床診断を実行できるモデルの開発が急務となっています。この研究で提案された具体的なイノベーションは次のとおりです。
* 提案された M³FM は、トレーニング用のラベル付きデータが不足しているか、まったく存在しない場合に、ゼロショットのマルチモーダル、マルチドメイン、マルチ言語の臨床診断を実施する最初の試みです。
* M³FM は、CXR と CT という 2 つの医療画像データ領域、中国語と英語という 2 つの異なる言語、疾患報告と疾患分類という 2 つの臨床診断タスク、および 2 つの感染症と 14 の非感染症を含む複数の疾患を含む 9 つのデータセットでその有効性を検証しました。
M³FM: 複数のデータセットによって検証された2つの主要モジュール
この研究では、提案されたM³FMの主要なアイデアは、モダリティ、ドメイン、言語にわたる公開医療データでモデルを事前トレーニングして広範な知識を学習し、この知識を活用してラベル付けされたデータを必要とせずに下流のタスクを達成することです。 M³FMフレームワークの主なコンポーネントには、2つの主要モジュールが含まれます。つまり、MultiMedCLIP と MultiMedLM です。次の図に示すように:
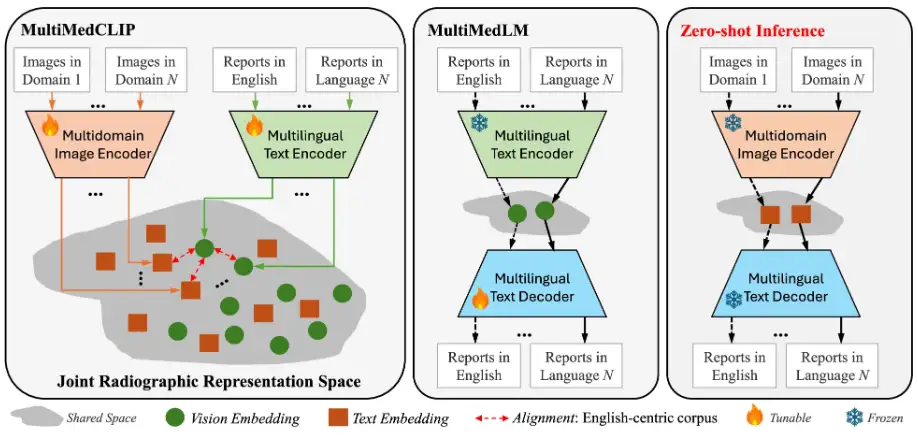
このプロセスでは、MultiMedCLIP は、共有された共通の潜在空間内でさまざまな言語と画像を整列させ、橋渡しします。次に、MultiMedLM は共有潜在空間内のテキスト表現に基づいてテキストを再構築し、最後に M³FM は統合潜在空間内の異なるドメインからの入力画像の視覚表現に基づいて直接多言語レポートを生成します。
具体的には、MultiMedCLIP は、マルチドメイン ビジュアル エンコーダーとマルチ言語テキスト エンコーダーを導入した共同表現を学習するモジュールであり、さまざまな医療画像ドメインとさまざまな言語からのビジュアル表現とテキスト表現を整合させるための共有潜在空間を作成することを目的としています。対照学習法にヒントを得て、研究者らはInfoNCE(情報ノイズ対照推定)損失とMSE(平均二乗誤差)損失をトレーニング目標として使用し、正のサンプルペア間の類似性を最大化し、負のサンプルペア間の類似性を最小化することで、異なる分野の視覚表現と異なる言語のテキスト表現間の整合を実現し、下流のゼロショット推論の強固な基盤を築きました。
MultiMedLM は、多言語レポートを生成するためのモジュールです。MultiMedCLIP によって抽出された表現に基づいて最終的な医療レポートを生成することを学習することを目的とした多言語テキスト デコーダーが導入されています。この部分は、中国語テキストまたは英語テキストである入力テキストを再構築することによってトレーニングされ、自然言語生成損失 - XE(クロスエントロピー)損失をトレーニングターゲットとして使用します。注目すべきは、再構築トレーニングの導入は教師なしトレーニングとみなすことができ、トレーニングにはラベル付けされていないプレーンテキスト データのみが必要であることです。したがって、下流のタスクでタスク注釈データをトレーニングする必要はありません。さらに、MultiMedLMトレーニングの安定性を確保するために、研究チームはランダムドロップアウトとガウスノイズをさらに導入しました。
実験では AdamW オプティマイザーが使用され、学習率は 1e-4、バッチ サイズは 32 に設定されました。実験は、混合精度トレーニングを使用して、PyTorch と V100 GPU で実施されました。
データセットに関しては、事前トレーニングは、MIMC-CXR および COVID-19-CT-CXR データセットで実行されました。MIMC-CXR は、377,110 枚の CXR 画像と 227,835 枚の英語の放射線レポートで構成されており、これまでに公開されたデータセットの中で最大のものです。COVID-19-CT-CXR には、1,000 枚の CT/CXR 画像と対応する英語のレポートが含まれています。さらに、研究者らは2つのデータセットから英語コーパスの半分を抽出し、Google Translatorを使用して中国語-英語のトレーニングチームを構築しました。結果は、この方法により機械翻訳テキストの結果を改善できることを示しました。
評価フェーズでは、IU-Xray、COVID-19 CT、COV-CTR、深圳結核データセット、COVID-CXR、NIH ChestX-ray、CheXpert、RSNA肺炎、SIIM-ACR肺気腫などのデータセットが使用され、モデルのパフォーマンスを包括的に評価することができました。
* IU-X線:含まれていたのは、CXR 画像 7,470 枚と英語の放射線レポート 3,955 件でした。データセットは、トレーニング、検証、テストのために 80% – 10% – 10% にランダムに分割されます。
* COVID-19 CT:1,104 枚の CT 画像と 368 件の中国語放射線レポートが含まれています。同様に、データセットはトレーニング、検証、テストのために 80% – 10% – 10% にランダムに分割されます。
*COV-CTR:中国語と英語のレポートにリンクされた 726 枚の COVID-19 CT 画像が含まれています。
* 深セン結核データセット:662 枚の CXR 画像が含まれており、トレーニング セット、検証セット、テスト セットは 7:1:2 に分割されています。
* COVID-CXR:900 枚を超える CXR 画像を含むデータセットは、トレーニング、検証、テストのために 80% – 10% – 10% にランダムに分割されます。
* NIH胸部X線:112,120 枚の CXR 画像が含まれており、各画像には 14 種類の一般的な放射線病の発生がラベル付けされており、トレーニング セット、検証セット、テスト セットの比率は 7:1:2 です。
* チェエキスパート:220,000 枚を超える CXR 診断画像が含まれています。前処理後、トレーニング セットに 218,414 枚の画像、検証セットに 5,000 枚の画像、テスト セットに 234 枚の画像が得られました。
* RSNA肺炎:約 30,000 枚の放射線画像で構成され、トレーニング、検証、テスト セットの比率は 85% – 5% – 10% です。
* SIIM-ACR肺気腫:これには 12,047 枚の CXR 画像が含まれており、トレーニング セット、検証セット、テスト セットの比率は 70% – 15% – 15% です。
実験により、M³FM は従来の高度な方法を上回る優れたパフォーマンスを発揮することが示されました。下の図の通りです。病気報告の結果に示されているように、従来の方法ではゼロショット設定で病気報告タスクを処理できませんでしたが、M³FM は単一のフレームワークで同時に複数言語、複数ドメインの病気報告を実行できます。少数ショットの設定では、10% の下流ラベル付きデータを使用してトレーニングすると、M³FM は最先端の結果を達成し、CT から中国語へのレポート生成において、1.5% の CIDEr と 1.2% の ROUGE-L スコアで、完全教師ありアプローチの R2Gen を上回りました。これは、ラベル付けされたデータが不足している場合でも、M³FM が正確で有効な多言語レポートを生成できることを示しており、希少疾患や新興疾患の場合に特に役立ちます。
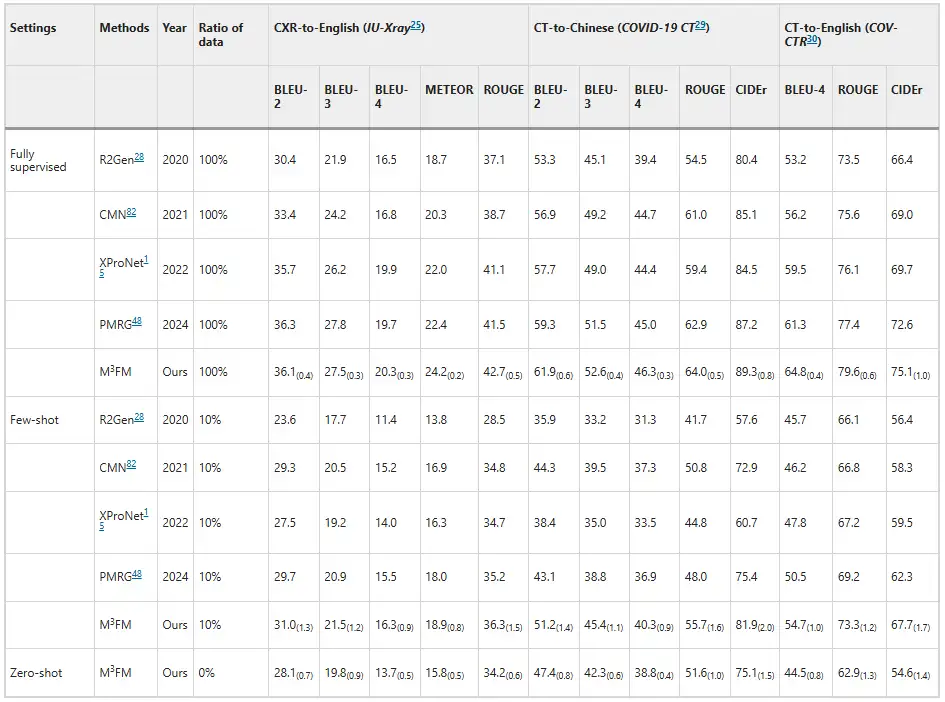
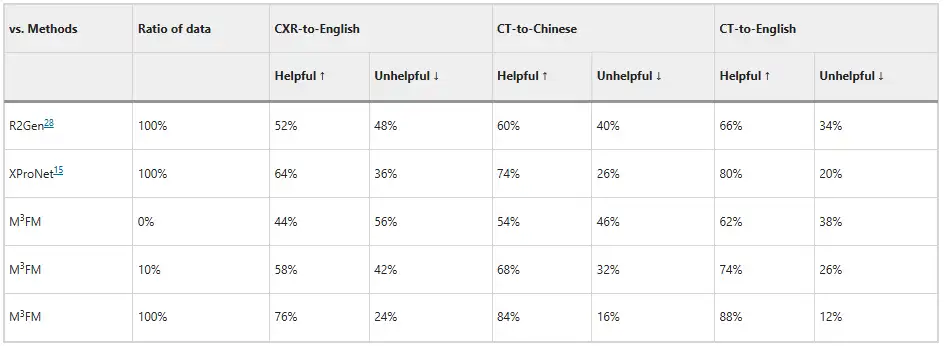
さらに、研究者らは 2 人の臨床医を招いてモデルを評価し、その結果を下の図に示します。 M³FM は、ラベル付きデータのトレーニングなしで、理想的な多言語およびマルチドメイン レポートを生成できます。10% のラベル付きデータのみをトレーニングに使用すると、CXR から英語、CT から中国語、CT から英語のタスクで、M³FM は完全教師あり方式の R2Gen よりもそれぞれ 6%、8%、8% 高くなります。完全なトレーニング データを使用すると、M³FM は 3 つのタスクで R2Gen を 20% 以上向上でき、XProNet よりもそれぞれ 12%、10%、8% 高くなります。これは、M³FM が、時間と労力を要するレポート作成作業から臨床医を解放する可能性を示しています。
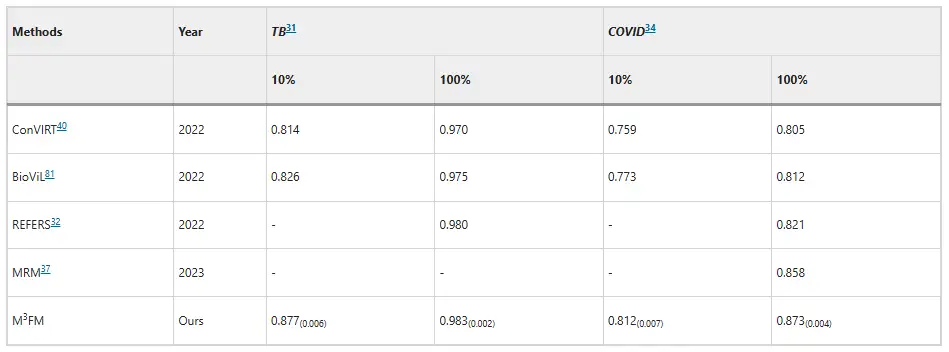
疾患分類の面では、M³FM は感染症の診断において優位性を示しています。深セン結核データセットと COVID – CXR データセットでは、10% のトレーニング データを使用した場合、M³FM の AUC スコアはそれぞれ既存の最高結果よりも 5.1% と 3.9% 高くなります。トレーニング データをすべて使用した場合、M³FM は 2 つの感染症で最高の結果を達成しました。非感染性疾患に関しては、データセットは NIH ChestX-ray から取得され、M³FM はわずか 1% のトレーニング ラベルで、完全教師あり方式の Model Genesis と同等の結果を達成しました。10% では、M³FM は複数の疾患の診断においてベースライン方式の MRM および REFERS を上回り、疾患診断における M³FM の有効性と一般化能力も確認されました。
AIがスマートヘルスケアをリードし、鄭葉峰のチームがその先頭に立つ
これまで、多くの研究室がこの問題に焦点を当ててきましたが、各研究室が提案したモデルにはそれぞれ異なる焦点と利点があります。
例えば、レポートの自動生成については、大連海事大学情報科学技術学院が医療および生物画像分析分野の専門フォーラム「医療画像分析」で「DACG:放射線レポート生成のための二重注意およびコンテキストガイダンスモデル」と題する研究論文を発表しました。この論文では、放射線レポートの自動生成のための二重注意およびコンテキストガイダンス(DACG)モデルを提案しており、視覚データとテキストデータの偏りを軽減し、長いテキストの生成を促進することができます。
用紙のアドレス:
https://www.sciencedirect.com/science/article/abs/pii/S1361841524003025
複数の言語向けに設計されたモデルもあります。たとえば、上海交通大学の王延鋒教授と謝衛迪教授のチームは、255億トークンを含む多言語医療コーパスMMedCを作成し、6つの言語をカバーする多言語医療質疑応答評価標準MMedBenchを開発し、複数のベンチマークテストで既存のオープンソースモデルを上回り、医療アプリケーションシナリオにより適した8BベースモデルMMed-Llama 3を構築しました。関連する研究成果は、「医療のための多言語モデルの構築に向けて」というタイトルでNature Communicationsに掲載されました。
クリックチェック詳細レポート:医療分野のベンチマークテストはLlama 3を超え、GPT-4に迫る。上海交通大学チームが6言語をカバーする多言語医療モデルを発表
それに比べて、マルチモダリティ、マルチドメイン、マルチ言語などの面でのM³FMの優れたパフォーマンスは、間違いなく人工知能とヘルスケアの交差点に新たな活力をもたらすでしょう。もちろん、この研究について語るとき、この記事の著者の一人である鄭葉鋒博士について言及しなければなりません。
実際、この論文は新しく生み出された成果であるとも言え、鄭葉鋒博士にとって新たな始まりの兆しとも言える。 2024年7月29日、IEEEフェロー、AIMBEフェロー、医療人工知能科学者の鄭葉鋒が西湖大学にフルタイムで加わり、工学部の教授として採用され、医療人工知能研究所を設立しました。研究室の研究分野には、医療画像解析、医療自然言語理解、バイオインフォマティクスなどが含まれます。この論文は、研究室初年度の重要な成果の一つです。
この成果に加えて、研究室は医療保健分野でもいくつかの論文を発表しており、その中には「弱くラベル付けされたデータの潜在能力を解き放つ:異常検出とレポート生成のための共進化学習フレームワーク」と題する研究があり、この研究では、CXR 異常検出とレポート生成という 2 つのタスクの相互発展を促進するために、完全にラベル付けされたデータと弱くラベル付けされたデータを使用する協調的異常検出およびレポート生成 (CoE-DG) フレームワークが紹介されています。この研究はIEEE Transactions on Medical Imagingに掲載されました。
もちろん、当研究室では、EMNLP 2024 で発表された「対照デコーディングによる医療情報抽出における大規模言語モデルの幻覚の緩和」という研究など、現在人気の大規模言語モデルに関する研究成果も持っています。この論文では、LLM が医療のシナリオで「幻覚」を起こしやすいという現象に対する解決策を示し、「代替コントラスト デコーディング」(ALCD) を提案しています。この方法は、モデルの認識機能と分類機能を分離し、予測プロセス中に 2 つの重みを動的に調整することで、エラーの発生を大幅に削減できます。この技術は、さまざまな医療タスクで優れた性能を発揮します。
現在、これらの成果はまだ研究段階であったり、実装に向けての勢いがあったりするかもしれませんが、最終的には AI がヘルスケア分野をインテリジェンス、インテリジェンス、自動化へと推進することになります。鄭葉鋒博士は「医療用人工知能は急速に発展している分野です。10~15年後には、人工知能が医師の診断や治療の精度を備え、広く利用できるようになると予測しています」と述べています。
参考文献:
1.https://www.nature.com/articles/s41746-024-01339-7
2.https://mp.weixin.qq.com/s/pMNXAvzgGRpPwqVtCWjXbA
3.https://mp.weixin.qq.com/s/6hw6EJY6slAIRbGGN9XY9g








