Command Palette
Search for a command to run...
推論速度が1.7倍に向上したvLLM v1バージョンをリリースしました! 4,000以上の注釈ステップを備えた初のマルチモーダルステップバイステップ推論ベンチマークVRC-Benchがリリースされました。

先月、大規模モデル推論の需要の急増を背景に、AI大規模モデル推論フレームワークvLLMが正式にバージョンv1.0を発表しました。以前のバージョンと比較して、コンピューティング効率が大幅に最適化され、API設計がより安定し、ハードウェアの潜在能力が十分に発揮され、推論速度が1.7倍に向上しました。数百億のパラメータを持つモデルの効率的な展開をより強力にサポートします。
現在のところ、hyper.ai公式サイトにてvLLM入門チュートリアルを公開しました。インストールから操作まで解説しているので、すぐにvLLMを使いこなすことができます!
vLLM 入門チュートリアル:https://go.hyper.ai/qHl62
vLLM中国語ドキュメントとチュートリアルの詳細については、こちらをご覧ください→ https://vllm.hyper.ai
2月5日から2月14日まで、hyper.ai公式サイトが更新されます。
* 高品質の公開データセット: 10
*厳選された高品質なチュートリアル: 6
* コミュニティ記事の選択: 5 記事
* 人気のある百科事典のエントリ: 5
* 2月に締め切りを迎えるトップカンファレンス: 3
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
このデータセットは、視覚的推論、数学的および論理的推論、科学的推論、文化的および社会的理解など、8 つの異なる分野の課題をカバーしています。手動で検証された 4,000 を超える推論ステップが含まれており、多段階推論におけるモデルの精度と論理的一貫性を総合的に評価できます。
直接使用します:https://go.hyper.ai/AV43N

Terra は、全世界をカバーするマルチモーダル時空間データセットであり、世界中の 45 年分の時空間データを提供し、648 万の高解像度グリッド ポイントをカバーし、時空間データ マイニングの将来の研究を促進し、より広範な時空間インテリジェンスの実現を促進することを目的としています。
直接使用します:https://go.hyper.ai/9eev3

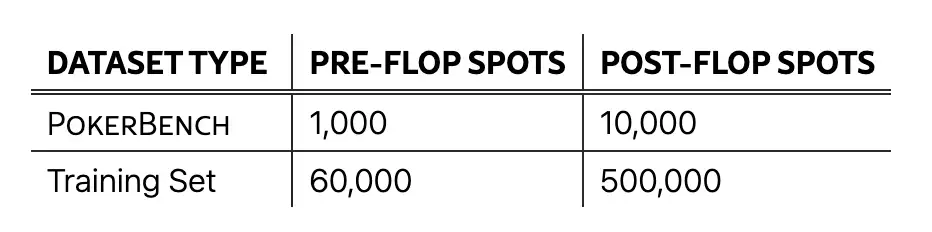
このデータセットには、11,000 個の主要シーンが含まれており、1,000 個のプリフロップ シーンと 10,000 個のポストフロップ シーンに分かれており、幅広いゲーム状況をカバーし、複雑で戦略的なポーカー ゲームにおける大規模言語モデル (LLM) のパフォーマンスを評価するように設計されています。
直接使用します:https://go.hyper.ai/HK73H
このデータセットには、中国の 352 都市の観光名所データが含まれています。各都市の csv ファイルには 100 か所の場所が含まれています。データには、場所の名前、Web サイト、住所、観光名所の紹介、営業時間、画像 URL、評価、推奨訪問期間、推奨訪問シーズン、チケット情報、ヒント、その他の情報が含まれます。
直接使用します:https://go.hyper.ai/uZ5Wh
このデータセットは、事前に定義されたランダムなアクション シーケンスを実行して 70 時間のゲーム ビデオを収集し、注釈を付けます。データセットは、3 つのバイオーム (森林、平原、砂漠)、3 つの気象条件 (晴れ、雨、雷雨)、および 6 つの時間帯 (日の出、正午、真夜中など) で事前設定されており、2,000 を超えるビデオ クリップが生成されます。
直接使用します:https://go.hyper.ai/25DAe
このデータセットは、建築、衣服、工芸、食品、エチケット、言語、習慣の 7 つの主要分野をカバーする 151,159 のデータ項目を含む、大規模モデル用の国家文化の微調整データセットです。
直接使用します:https://go.hyper.ai/Vd6ZP
7. AceMath Instructトレーニングデータ数学的推論データセット
このデータセットは、数学的推論タスクにおけるモデルのパフォーマンスを向上させることを目的として、AceMath モデルのトレーニング用に NVIDIA が 2025 年にリリースしたデータセットです。
直接使用します:https://go.hyper.ai/pT5Tr
8. ComplexFuncBench 複合関数呼び出し評価データセット
データセットは、5 つの実際のシナリオにおける 1,000 個の複雑な関数呼び出しサンプルをカバーしており、これには 600 個の単一ドメイン サンプル、ホテル、フライト、レンタカー、アトラクションがそれぞれ 150 個、および 400 個のクロスドメイン サンプルが含まれます。タクシードメインには 2 つの機能しかないため、ドメイン間でのみ使用されます。
直接使用します:https://go.hyper.ai/v0p4c
このデータセットには、厳選された 1,225 件の計画意図と参照プランが含まれています。データセットは旅行計画のコンテキストで設定されており、言語エージェントが特定のクエリに基づいて、交通手段、毎日の食事、観光スポット、宿泊施設などを含む包括的な旅行計画を生成する必要があります。
直接使用します:https://go.hyper.ai/22AhZ
このデータセットには、数百種類の無機化合物の水溶性実験データが含まれています。データは複数の参考文献から得られたもので、材料情報学の分野に適しています。すべての溶解度データは、水 100 グラムあたりの溶質のグラム数で表されます。
直接使用します:https://go.hyper.ai/dqL1y
選択された公開チュートリアル
1. vLLM入門チュートリアル: 初心者向けのステップバイステップガイド
vLLM は、大規模言語モデルの推論を高速化するために特別に設計されたフレームワークであり、優れた推論効率とリソース最適化機能により世界中で注目を集めています。研究者らは、高スループットの分散 LLM サービス エンジン vLLM を構築し、KV キャッシュ メモリの無駄をほぼゼロにし、大規模言語モデル推論におけるメモリ管理のボトルネック問題を解決しました。
このチュートリアルでは、vLLM を設定して実行する方法を段階的に説明し、インストールから起動までの完全な入門ガイドを提供します。以下のリンクをクリックし、チュートリアルに従って vLLM を展開してください。
オンラインで実行:https://go.hyper.ai/qHl62
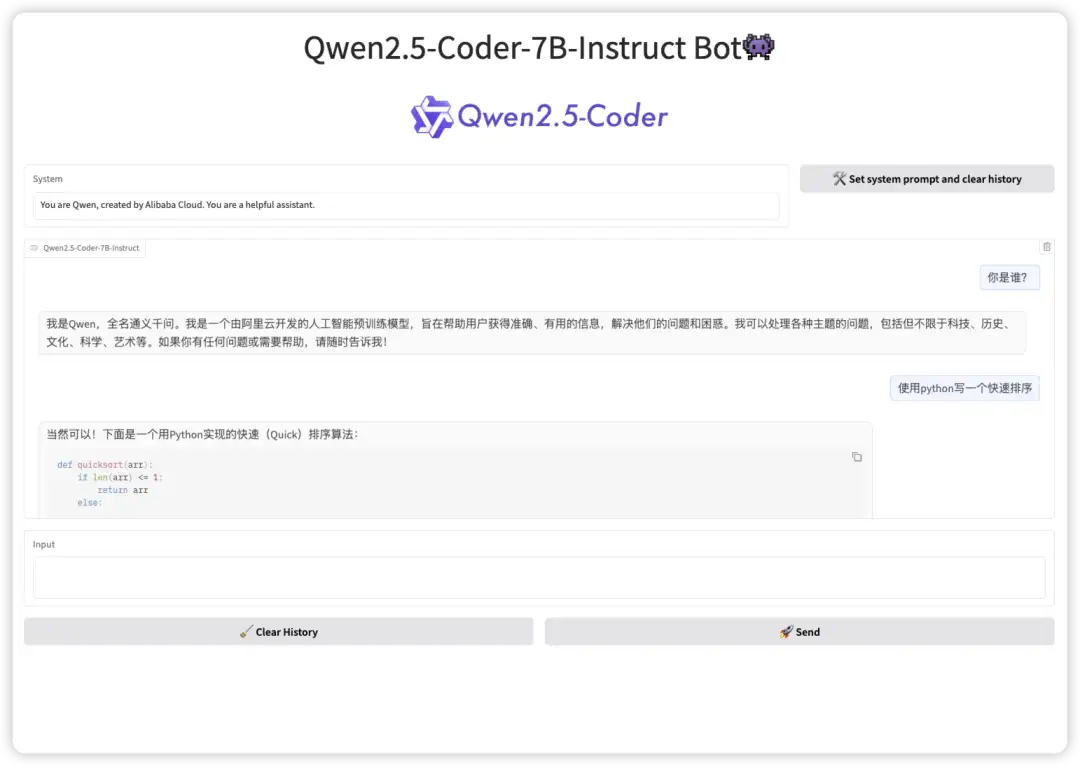
Qwen2.5-Coder は、強力なコード生成機能を備えた人工知能アシスタントです。明確なロジックと標準化された構文によるコード出力をサポートし、ユーザーがさまざまなビジュアル プロジェクトを迅速に構築および実装できるようにアーティファクト機能を提供します。ミニゲーム開発の面では、Qwen2.5-Coder は、ゲームのルール、グラフィック スタイル、ユーザー エクスペリエンスの要件に基づいてゲーム コードを生成できます。開発者はこれに基づいてカスタマイズおよび最適化し、独自のゲーム作品を迅速にリリースできます。
このプロジェクトでは、Gradio インターフェースを介してフロントエンドのインタラクティブ インターフェースを生成できます。関連するモデルと依存関係がデプロイされています。モデルに指示を入力し、ワンクリックで必要なコードを生成できます。
オンラインで実行:https://go.hyper.ai/JVOTN
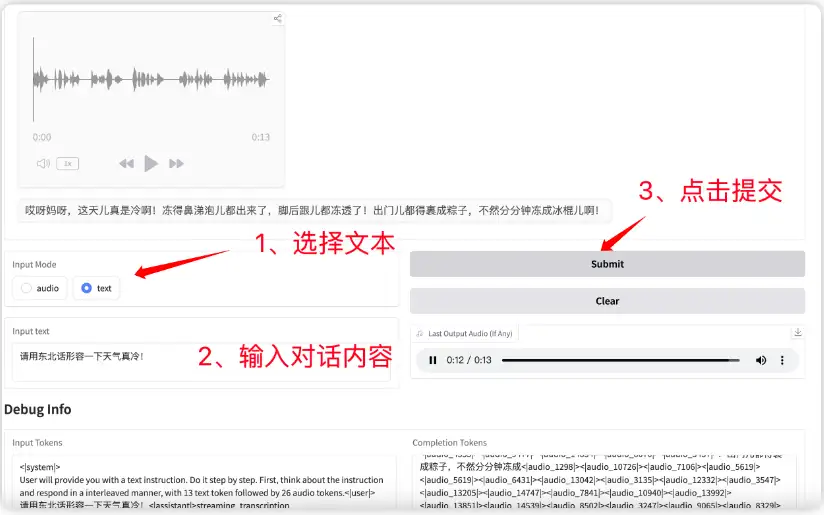
3. GLM-4-Voice エンドツーエンド中国語-英語会話モデル
GLM-4-Voice は、中国語と英語の音声を直接理解して生成し、リアルタイムの音声会話を実施し、ユーザーの指示に従って感情、イントネーション、発話速度、方言などの音声属性を変更できるエンドツーエンドの音声モデルです。
公式 Web サイトにアクセスしてコンテナーをクローンして起動し、API アドレスを直接コピーすると、モデルと通信できるようになります。
オンラインで実行:https://go.hyper.ai/s4MId
4. Linly-Dubbing ワンクリックでビデオをダウンロード + 翻訳 + 吹き替え + 字幕
Linly-Dubbing は、ビデオ コンテンツを複数の言語に自動翻訳し、字幕を生成できるインテリジェントなビデオ多言語 AI 吹き替えおよび翻訳ツールです。
以下のリンクをクリックして、今すぐクリエイティブな旅を始めて、ビデオの多言語 AI 吹き替えと翻訳を実現しましょう。
オンラインで実行:https://go.hyper.ai/xEAzn
5. DrawingSpinUp: 2Dキャラクター描画→3Dアニメーション
DrawingSpinUp は、オリジナルのアートワークのスタイルと特徴を慎重に維持しながら、平面的なキャラクターの描画を 3D 効果のあるダイナミックなアニメーションに変換する革新的な 3D アニメーション生成テクノロジーです。
チュートリアルの手順に従って、リアルで詳細な 3D アニメーションを作成します。
オンラインで実行:https://go.hyper.ai/H9fV1
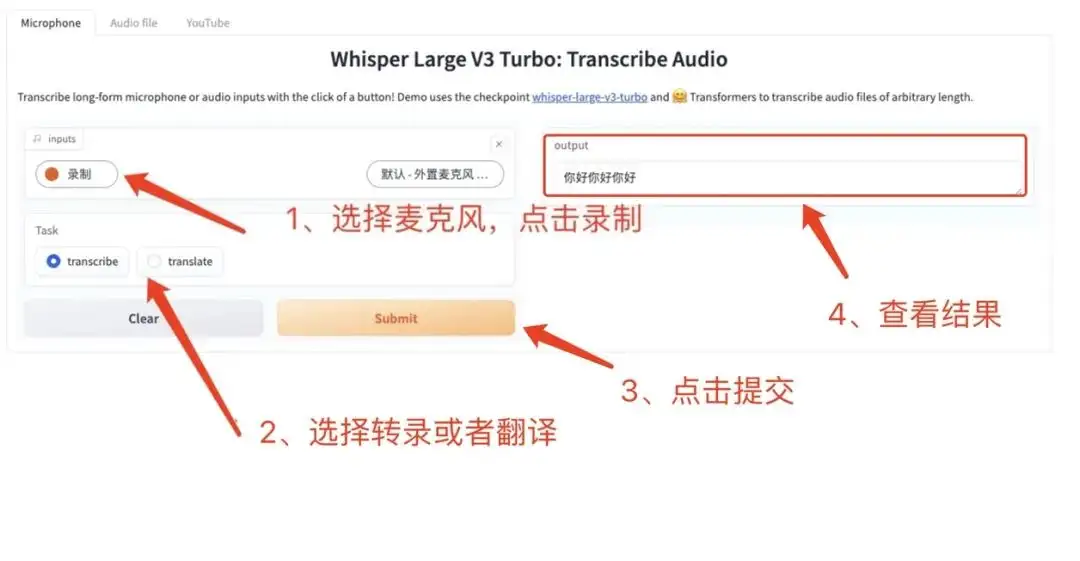
6. Whisper-large-v3-turbo 音声認識と翻訳のデモ
Whisper は汎用の音声認識モデルです。大規模で多様なオーディオ データセットでトレーニングされており、多言語音声認識や音声翻訳などの複数のタスクを実行できます。
このチュートリアルは、whisper-large-v3-turbo のワンクリック デプロイメント チュートリアルです。whisper-large-v3 よりも 8 倍高速で、品質の低下はほとんどありません。関連する環境と依存関係がインストールされており、ワンクリックでクローンして起動するだけで体験できます。
オンラインで実行:https://go.hyper.ai/3P9nk
注目のコミュニティ記事
1. NVIDIAとSamsungからの投資により、Generateは100万以上のタンパク質を作成し、ゼロから設計された生成モデルを開発しました。
AI バイオ医薬品企業 Generate: Biomedicines は、独自のプログラム可能な生物学プラットフォームを備え、人工知能をタンパク質工学に深く統合するだけでなく、従来は薬物治療が困難だったターゲットに対して科学者がより効率的なソリューションを設計できるように支援します。最近、GenerateはSamsung Science & Life Science Fundから戦略的投資を受けたと発表しました。その意味は明らかです。この記事は同社に関する詳細なレポートです。クリックするとすぐに読めます。
イベントの概要を確認してください:https://go.hyper.ai/fVtKK
2. 甲骨文字の高精度データが中国に返還され、AIが古文書の解釈を支援し、新たな甲骨文字の画像が発見された
近年、中国古代文学の研究分野ではAIが徐々に深く応用されてきました。 2024年6月、安陽師範大学は華中科技大学、華南理工大学などと共同で、甲骨文解読に最適化された条件拡散モデルを提案しました。その成果はACL 2024に選ばれただけでなく、最優秀論文賞も受賞しました。これは、AIが研究者の作業効率を加速させていることを示しています。AIが甲骨文字を解釈する仕組みの詳細については、次のとおりです。
レポート全体を表示します。https://go.hyper.ai/xzw4c
3. 10 の主要な中国医学データセットの概要: 神農中国医学、古代中国医学書、医学的推論、医学的質問と回答などを網羅...
医療用人工知能の急速な発展は、高品質のデータセットのサポートと切り離すことはできません。病気の診断から医薬品の開発、個別化医療まで、医療分野におけるマシンビジョンや大規模モデルなどの応用を促進する上でデータセットは欠かせない役割を果たしています。この記事は、神農漢方医学、古代中国医学書、医学推論、医学質問と回答など、医療分野の10のデータ セットを整理しています。クリックすると直接ダウンロードできます。
レポート全体を表示します。https://go.hyper.ai/NHlJ0
4. 成功率は100%に達する可能性がある。医薬品開発会社CellarityはNVIDIAと提携し、強化学習に基づいて標的分子を最適化した。
人工知能の急速な発展は、医薬品の発見に新たな可能性をもたらしました。最近、ライフサイエンス企業 Cellarity と NVIDIA の研究者が共同で、潜在強化学習 (MOLRL) に基づく新しい標的分子最適化手法を提案しました。この手法は、特に標的分子の生成とマルチパラメータの最適化において、創薬関連のタスクで優れたパフォーマンスを示しました。この記事は、その論文を詳細に解釈して共有したものです。
レポート全体を表示します。https://go.hyper.ai/YBhnM
5. 南開大学の鄭偉教授:AlphaFoldは完璧ではなく、学術界にはまだ「曲線を追い抜く」チャンスがある
「Meet AI4S」ライブ放送シリーズの第6回では、南開大学統計・データサイエンス学院の鄭偉教授が、AlphaFoldの限界と将来の最適化の方向性、そして学術界で探求する価値のあるアルゴリズムと研究テーマについて皆さんと共有しました。詳細については下記をご覧ください。
レポート全体を表示します。https://go.hyper.ai/YgCip
人気のある百科事典の項目を厳選
1. 相互ソーティング融合 RRF
2. モデルパラメータ
3. コルモゴロフ-アーノルド表現定理
4. 大規模マルチタスク言語理解MMLU
5. 対照学習
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。

主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!








