Command Palette
Search for a command to run...
1760億パラメータの汎用医療言語モデルをオープンソース化! BUPT/PKU/中国三峡大学は、専門医に近い推論能力を持つMedFoundを提案した。

「人は誰でも間違いを犯す」という古い諺がありますが、医療の分野では誤診のような間違いが悲惨な結果を招く可能性があります。一方、患者にとって最悪のシナリオは誤報であり、最悪のシナリオは病気の治療の遅れです。どちらの場合も、患者は精神的、財産的、さらには生命的損害を被ることになります。一方、医師にとって、誤った判断は命を救う医師のイメージを傷つけ、医療システム全体の信頼性に影響を与える可能性があります。しかし、予想に反して、誤診は国内外で依然として頻発している。
雑誌「臨床誤診と誤診」の元編集長であり、医学論文集「誤診」の著者の一人である陳暁紅氏は、インタビューで、国内外の文献でサンプルサイズで言及されている誤診率は、一般的に20%から40%程度であると述べた。また、彼の著書『誤診』には、例えば、1973年から1980年にかけて国内の代表的な医学雑誌数誌が報告した200件の臨床病理学討論データでは、誤診率が48 %にも達したことなど、関連する統計が掲載されている。誤診は人類の医学の進歩における大きな障害の一つとなっていると言ってもいいでしょう。
誤診の問題を解決するために、古代では『中西医合一医録』『医過』『医正』などの医学書が、誤診の教訓を医療記録に盛り込み、後世に警告しようと全力を尽くしました。現代では、B超音波、CT、MRIなどの現代医療手法の助けを借りて、臨床診断の手段はますます豊富で洗練されています。しかし、医学は実践科学であり探究的な学問であるため、誤診を完全に避けることはできません。したがって、誤診率をさらに減らし、病気の診断の正確性とアクセス性を向上させることによってのみ、医学のさらなる発展への道を切り開くことができます。
AI for Science を新しいパラダイムとして取り入れることで、上記の問題を解決するための新しいアイデアが提供されます。数日前、北京郵電大学の王光宇教授、北京大学第三病院の宋春麗教授、中国三峡大学の楊建教授からなる医療工学の学際チームが、パラメータ数が最も多い生物医学言語モデルMedFound(176B)を導入し、検証しました。さらに、私たちは、専門家に近い知識と推論能力を持ち、医療のシナリオ全体にわたって効率的で正確な診断サポートを提供できる、総合的な医療診断のための大規模言語モデルである MedFound-DX-PA を作成しました。
関連する結果は、「病気の診断を支援するための汎用的な医療言語モデル」というタイトルで Nature Medicine に掲載されました。

用紙のアドレス:
https://www.nature.com/articles/s41591-024-03416-6
公式アカウントをフォローし、「MedFound」と返信すると完全なPDFが手に入ります。
オープンソース プロジェクト「awesome-ai4s」は、200 を超える AI4S 論文の解釈をまとめ、膨大なデータ セットとツールを提供します。
https://github.com/hyperai/awesome-ai4s
MedFound のイノベーションとは何ですか?
最大のパラメータ数を持つ最大のオープンソース生物医学言語モデル
研究チームは、実際の臨床現場に特化して設計された、公開されているLLMが不足していることが、LLMがバイオメディカル分野でまだ初期段階にある主な理由であると述べた。 MedFound は、パラメータスケールが 1760 億の一般的な医療用大規模言語モデルである一般ドメイン大規模言語モデル BLOOM-176B に基づいて事前トレーニングされています。
モデルが包括的な一般医学知識を獲得できることを保証するために、研究チームは膨大な医学知識と臨床実践を統合した医療コーパスデータセットMedCorpusを特別に構築しました。これは、MedText、PubMed Central Case Report(PMC-CR)、MIMIC-III-Note、MedDX-Noteの4つのデータセットから合計63億のテキストトークンで構成されています。これらのデータセットには、中国語と英語の医学文献、専門書、および 870 万件の実際の電子医療記録が含まれており、さまざまな分野の診断にモデルを適用するための重要な基盤となります。
研究チームによれば、MedFound は現在オープンソースであり、世界中の研究者、臨床医、医療機関に基盤となる基本的な大規模モデル サービスを提供できるようになっていることも特筆に値します。
プロジェクトアドレス:
https://github.com/medfound/medfound?tab=readme-ov-file
革新的な臨床診断推論機能により「生きた医師」となる
さらに、機械と人間の重要な違いは、人間の医師は自身の経験と知識の蓄積に基づいて患者の真の状態について合理的な推論を行い、差別化された治療を提供できることです。研究チームは、現在の研究のいくつかは、医学的な質疑応答や会話のために臨床知識をLLMに組み込むだけで、臨床診断推論の能力を反映していないと紹介しました。
たとえば、Sainan Zhang 氏と Jisung Song 氏は、転移学習と GPT-2 の微調整に基づいて Chat Ella という会話型インターフェースを開発したという結果を Nature に発表しました。このシステムは、ユーザーが説明した症状に基づいて慢性疾患を正確に予測できます。しかし、論文の最後で研究者らは研究の欠点にも触れ、推論プロセスを説明できないなど、推論プロセスにおける結果のいくつかの限界を指摘した。この論文のタイトルは「大規模言語モデルに基づく慢性疾患の補助診断のためのチャットボットベースの質疑応答システム」です。
用紙のアドレス:
https://www.nature.com/articles/s41598-024-67429-4
したがって、厳密な病気の診断を達成するためには、大規模モデルが広範な学際的な医学知識を持っているだけでは不十分であり、複雑な推論を実行できることも必要です。研究チームは、MedFound モデルをベースに、2 段階のトレーニング最適化を通じて、専門家に近い知識と推論能力を備えた一般医療診断用の大規模言語モデルである MedFound-DX をさらに作成しました。以下に示すように:
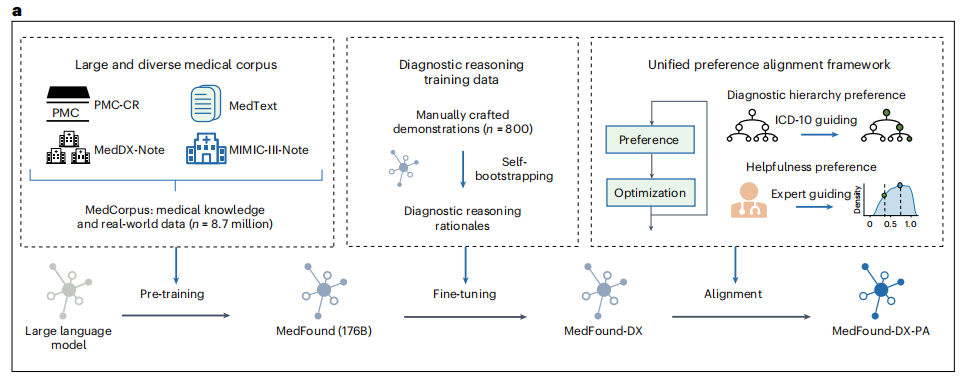
具体的には、第1段階では、研究チームは自己誘導戦略に基づく思考連鎖(CoT)法を使用して、大規模モデルが医療専門家のように診断の根拠と推論プロセスを自動的に生成できるようにしました。しかし、生成的 LLM は「幻覚」を生み出したり、誤った事実を捏造したりする可能性があり、これらの診断が採用された場合、結果は悲惨なものになる可能性があります。
そのため、第 2 フェーズでは、研究チームは、LLM を専門分野の知識システムおよび臨床診断の好みと整合させるための統一された好み整合フレームワークも導入し、モデルが診断を行う際に科学的かつ合理的であるだけでなく、臨床実践における医療専門家の論理と価値観とも一致することを保証しました。このフレームワークは、「診断階層の好み」と「有用性の好み」を統合しており、どちらも強化学習を必要としない単純なアルゴリズムである直接好み最適化 (DPO) アルゴリズムを使用しています。一方では、モデルをガイドして病気の特定のきめ細かい精度を向上させることができ、他方では、モデル推論の有効性と信頼性を向上させ、誤解を招く情報や不正確な情報のリスクを軽減することもできます。
注目すべきは、この部分の微調整と調整において、研究チームが MedDX-FT と呼ばれるデータセットも特別に構築したことです。このデータセットには、トレーニングと微調整のために実際の医療記録に基づいて医師が手動で記述した推論プロセスのデモンストレーションが含まれています。データセットは、手動デモンストレーションと 109,364 件の EHR ノートに基づくシード セットで構成されています。
驚くべきデモンストレーション結果が、その潜在的な応用能力を示している
評価フェーズでは、研究チームは MedDX-Bench データセットも構築しました。これには、MedDX-Test、MedDX-OOD、MedDX-Rare の 3 つの臨床データセットが含まれています。
* MedDX-Test データセットは、さまざまな分野での MedFound-DX-PA の診断性能を評価するために使用され、トレーニング データセットと同じ分布の 11,662 件の医療記録が含まれています。
* MedDX-OOD と MedDX-Rare は外部検証セットであり、前者には一般的な疾患の記録が 23,917 件含まれており、後者にはロングテール分布を持つ 2,105 の希少疾患の記録が 20,257 件含まれています。
評価実験は主に、分布内(ID)評価、分布外(OOD)評価、ロングテール疾患分布評価の3段階から構成されます。比較対象には、MEDITRON-70B、Clinical Camel-70B、Llama 3-70B、GPT-4oなどの主要なオープンソースおよびクローズドソースLLMが含まれます。
結果は、そのパフォーマンスが他の主要な LLM よりも優れていることを示しています。例えば、一般的な疾患の診断性能では、MedFound-DX-PA の平均トップ 3 精度は 84.2% (ID 設定下) であるのに対し、GPT-4o の診断精度はわずか 62% です。希少疾患の診断性能では、8 つの専門分野における MedFound-DX-PA の平均トップ 3 精度は 80.7% であり、GPT-4o は平均 59.1% で 2 位にランクされています。
特筆すべきは、MedFound-DX-PA と内分泌専門医および呼吸器専門医との比較において、診断精度はそれぞれ 74.7% と 72.6% であり、経験年数が短い医師や中程度の医師の診断精度よりもはるかに高く、経験年数が長い医師の診断精度と同等であったことです。補助診断の面では、この 2 つの部門の医師がそれぞれ 11.9% と 4.4% の診断精度を向上させるのに役立ちます。下の図は直感的なモデル診断事例です。
下の図に示すように、医師の最初の診断は急性気管支炎でした。MedFound モデルは、患者の再発性気管支炎の病歴を強調表示しました。モデルのプロンプトにより、医師は診断を慢性気管支炎の急性増悪に修正しました。

下の図に示すように、医師は当初、患者を潜在性甲状腺機能低下症と診断しました。MedFound モデルは、基礎にある自己免疫甲状腺疾患の可能性を示唆し、医師は結果を自己免疫甲状腺炎に修正しました。

MedFound は診断の効率と精度を向上させる可能性を秘めているだけでなく、臨床従事者の診断補助となる可能性も秘めていることがわかります。これは、インテリジェントな臨床診断と治療、および個別化医療の将来の発展を強力にサポートします。
AI4Sは進歩を続け、実装の時代が到来
王光宇率いるチームは前進を続ける
この共同作業では、各チームが最善を尽くし、専門知識を活用してこの成果に貢献しました。北京郵電大学の王光宇教授がこの研究の責任著者の一人であることは特筆に値します。
実は、王光宇教授のチームが AI とバイオメディカルを統合したのは今回が初めてではない。王光宇氏は、90年代以降初の科学探究賞受賞者として長年にわたり名声を博し、国際的に最先端の学術成果を次々と発表してきた。彼の作品は、Cell、Nature Medicine、Nature Biomedical Engineering などのトップクラスの国際学術誌に掲載されています。

例えば、2020年に王光宇教授は第一著者として、トップの国際学術誌Cellに「コンピューター断層撮影法を用いたCOVID-19肺炎の正確な診断と予後のための臨床応用可能なAIシステム」と題する論文を発表しました。この研究は当時猛威を振るっていたCOVID-19肺炎に焦点を当て、合計53万枚以上のCT画像を使用して病変セグメンテーションに基づくAI診断モデルを構築し、診断精度は最大92.49%に達しました。
用紙のアドレス:
https://www.cell.com/pb-assets/products/coronavirus/CELL_CELL-D-20-00656.pdf

2023年、王光宇氏のチームは再びネイチャー・メディシン誌に2つの研究論文を発表した。「SARS-CoV-2の感染性と変異体の進化を予測するためのディープラーニングを活用したタンパク質間相互作用分析」と題された論文では、SARS-CoV-2のスパイクタンパク質変異体が人間に与える影響を効果的かつスケーラブルに予測できる、UniBildと呼ばれる人工知能フレームワークを提案した。
用紙のアドレス:
https://www.nature.com/articles/s41591-023-02483-5

「強化学習による 2 型糖尿病の最適化された血糖コントロール: 概念実証試験」と題された別の論文では、モデルベースの強化学習フレームワーク RL-DITR を提案しています。これには、個々の血糖値の状態を追跡する患者モデルと、長期ケアの多段階計画のためのポリシー モデルが含まれており、医師と患者が動的で柔軟なインスリン治療計画を指定できるようになります。
用紙のアドレス:
https://www.nature.com/articles/s41591-023-02552-9
王光宇氏は「私たちはこれに期待しています。私自身としては、より強力なAI手法を開発し、それを使って突発的な伝染病や癌の克服など、多くの重要な生物医学的問題を解決したいと考えています」と語った。
AIとバイオメディカルの統合が加速している
実際、AIとバイオメディカルの統合は、長い間主要な研究室の焦点となってきました。医療分野の特殊性により、AIがこの分野で役割を果たす機会はより多く、より多くのチームがこの分野をさらに深く探求したいと考えています。
例えば、2024年には香港中文大学のチームも、法学修士号(LLM)に基づいた多段階の相談型仮想医師システム「DrHouse」を開発しました。このシステムは、スマートデバイスの助けを借りて診断の精度と信頼性を向上させると同時に、常に更新される医療知識ベースと高度な診断アルゴリズムを通じて、非常に長い耐用年数を持ち、インテリジェントで信頼性の高い医療評価を提供します。関連論文のタイトルは「DrHouse: センサーデータと専門知識からの結果を活用した LLM 強化診断推論システム」です。
用紙のアドレス:
https://arxiv.org/abs/2405.12541
さらに、上海交通大学の王延鋒氏と謝衛迪氏のチームも2024年に関連する結果を発表しました。この研究では、チームが約255億のトークンを含み、6つの主要言語をカバーする多言語医療コーパスMMedCを構築したことが言及されています。同時に、多言語医療多肢選択式質問ベンチマークMMedBenchも提案しました。研究チームの最終モデルである MMed-Llama 3 は、パラメータが 80 億個しかありませんが、MMedBench および英語のベンチマークでは GPT-4 に匹敵するパフォーマンスを発揮します。
*詳細レポートはこちら:医療分野のベンチマークテストがLlama 3を超えGPT-4に迫る。上海交通大学チームが6言語をカバーする多言語医療モデルをリリース
AIとバイオメディカルの融合の嵐が激しさを増していることがわかります。強力なコンピューティングパワー、斬新なアルゴリズム、そして膨大なデータをより簡単に吸収する能力を備えたAIは、従来の科学研究をより効率的かつインテリジェントなものにしています。さらにエキサイティングなのは、これらの徐々に進歩する結果が最終的に応用をより速く実現させることです。実装が王様の時代が静かに到来したようです。
参考文献:
1.https://mp.weixin.qq.com/s/9mhp6luTzQeNhqpEKw9CWQ
2.https://mp.weixin.qq.com/s/WlamJ7N9YKrOJljvEvE9cA
3.https://mp.weixin.qq.com/s/r-S9qkVU645K-ZdaLGYhBA
4.https://mp.weixin.qq.com/s/BfByFCWC9VN6iABnPq1iDw









