Command Palette
Search for a command to run...
オンラインチュートリアル | YOLOシリーズは10年間で11バージョン更新され、最新モデルは複数のターゲット検出タスクでSOTAに到達しました
YOLO (You Only Look Once) は、コンピューター ビジョンの分野で最も影響力のあるリアルタイム オブジェクト検出アルゴリズムの 1 つです。高精度と高効率が業界で高く評価されており、自動運転、セキュリティ監視、医療画像などの分野で広く使用されています。
このモデルは、ワシントン大学の大学院生ジョセフ・レドモン氏によって 2015 年に初めて公開されました。このモデルは、物体検出を単一の回帰問題として扱うという概念の先駆者となり、エンドツーエンドの物体検出を実現し、開発者の間で急速に広く認知されました。その後、Alexey Bochkovskiy、Glenn Jocher (Ultralytics チーム)、Meituan Visual Intelligence Department などのチームがいくつかの重要なバージョンをリリースしました。
現在、GitHub 上の YOLO シリーズ モデルのスターの数は数十万に達しており、コンピューター ビジョンの分野における影響力を示しています。

YOLO シリーズのモデルは、1 段階の検出アーキテクチャを特徴としており、複雑な領域候補ボックスの生成を必要とせず、単一の順方向伝播でターゲット検出を完了できるため、検出速度が大幅に向上します。従来の2段階検出器(Faster R-CNNなど)と比較して、YOLOは推論速度が速く、高フレームレート画像のリアルタイム処理を実現し、ハードウェアの適応性を最適化します。、組み込みデバイスやエッジ コンピューティングのシナリオで広く使用されています。
現在のところ、HyperAI公式サイトの「チュートリアル」セクションでは、YOLOシリーズの複数のバージョンが公開されており、ワンクリックで展開して体験できます〜
この記事の最後では、最新バージョンの YOLOv11 を例に、ワンクリック デプロイのチュートリアルについて説明します。
1. YOLOv2
発売時期:2017年
重要な更新:アンカーボックスが提案され、速度と精度を向上させるために、Darknet-19 がバックボーン ネットワークとして使用されました。
TVM を使用して DarkNet モデルで YOLO-V2 をコンパイルします。
2. YOLOv3
発売時期:2018年
重要な更新:Darknet-53をバックボーンネットワークとして使用することで、リアルタイム速度を維持しながら精度を大幅に向上させ、マルチスケール予測(FPN構造)を提案し、異なるサイズのオブジェクトの検出や複雑な画像の処理において大幅な改善を実現しました。
TVM を使用して DarkNet モデルで YOLO-V3 をコンパイルします。
3 、 YOLOv5
発売時期:2020年
重要な更新:自動アンカーフレーム調整機構の導入により、リアルタイム検出機能を維持し、精度が向上します。トレーニングとデプロイを容易にするために、軽量の PyTorch 実装が使用されます。
ワンクリック展開:https://go.hyper.ai/jxqfm
4 、 YOLOv7
発売時期:2022年
重要な更新:拡張された効率的なレイヤー集約ネットワークに基づいて、パラメータの使用率と計算効率が向上し、より少ない計算リソースでより優れたパフォーマンスを実現します。 COCO キーポイント データセットでのポーズ推定などの追加タスクを追加しました。
ワンクリック展開:https://go.hyper.ai/d1Ooq
5 、 YOLOv8
発売時期:2023年
重要な更新:
新しいバックボーン ネットワークを採用し、新しいアンカーフリー検出ヘッドと損失関数を導入することで、平均精度、サイズ、レイテンシの点で以前のバージョンよりも優れたパフォーマンスを発揮します。
ワンクリック展開:https://go.hyper.ai/Cxcnj
6 、 YOLOv10
発売時期:2024年5月
重要な更新:非最大抑制 (NMS) 要件を排除し、推論の遅延を削減します。大規模なカーネル畳み込みと部分的な自己注意モジュールを組み込むことで、計算コストを大幅に増やすことなくパフォーマンスが向上します。効率と精度を向上させるために、さまざまなコンポーネントが完全に最適化されています。
YOLOv10 ターゲット検出のワンクリック展開:
YOLOv10 オブジェクト検出のワンクリック展開:
7 、 YOLOv11
発売時期:2024年9月
重要な更新:検出、セグメンテーション、ポーズ推定、追跡、分類などの複数のタスクで最先端 (SOTA) のパフォーマンスを提供し、幅広い AI アプリケーションとドメインの機能を活用します。
ワンクリック展開:https://go.hyper.ai/Nztnq
YOLOv11 ワンクリック デプロイメント チュートリアル
HyperAI HyperNeural チュートリアル セクションで、「YOLOv11 のワンクリック デプロイメント」が開始されました。チュートリアルでは、すべてのユーザー向けに環境がセットアップされています。コマンドを入力する必要はありません。クローンをクリックするだけで、YOLOv11 の強力な機能をすぐに体験できます。
チュートリアルのアドレス:https://go.hyper.ai/Nztnq
デモの実行
1. hyper.ai にログインし、「チュートリアル」ページで「YOLOv11 のワンクリック展開」を選択し、「このチュートリアルをオンラインで実行する」をクリックします。
2. ページがジャンプしたら、右上隅の「クローン」をクリックしてチュートリアルを独自のコンテナにクローンします。
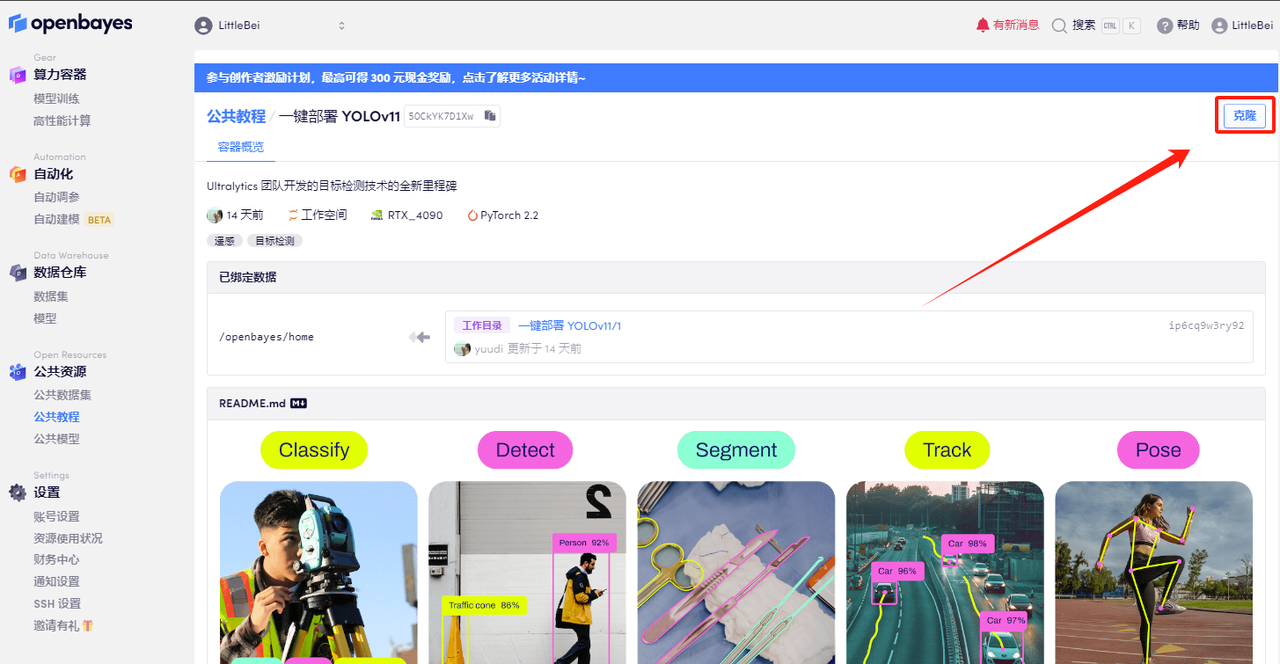
3. 右下隅の「次へ: コンピューティング能力の選択」をクリックします。
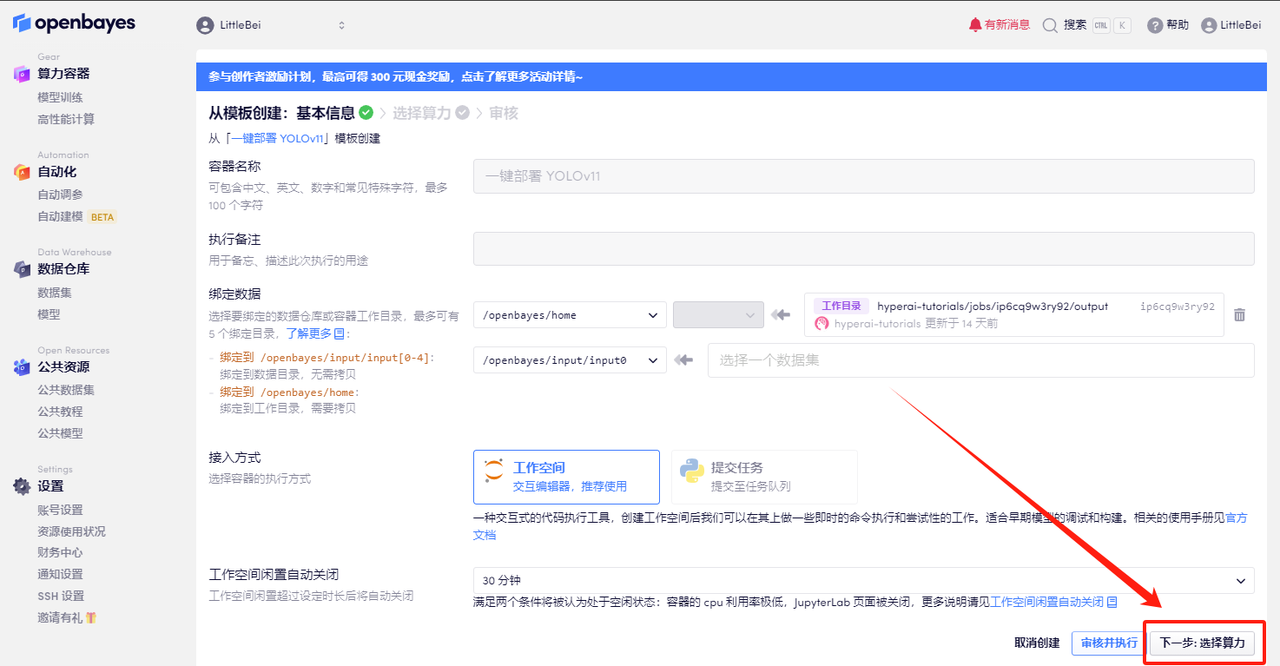
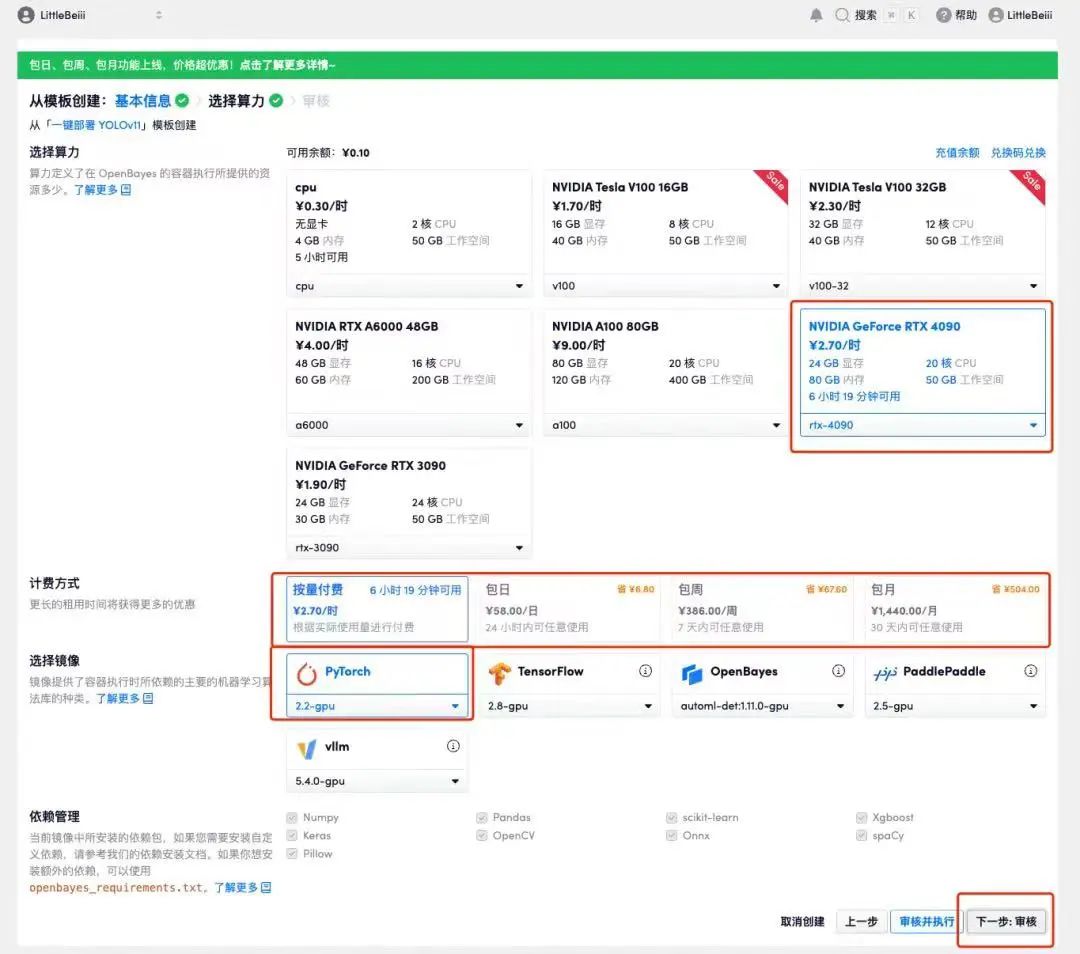
4. ページがジャンプしたら、「NVIDIA RTX 4090」と「PyTorch」のイメージを選択します。ユーザーは、必要に応じて「従量課金制」または「日次/週次/月次パッケージ」を選択できます。選択が完了したら、「次へ: レビュー」をクリックします。以下の招待リンクを使用してサインアップした新規ユーザーは、4 時間の RTX 4090 + 5 時間の CPU を無料で入手できます。
HyperAI ハイパーニューラルの専用招待リンク (ブラウザに直接コピーして開きます):
https://openbayes.com/console/signup?r=Ada0322_QZy7
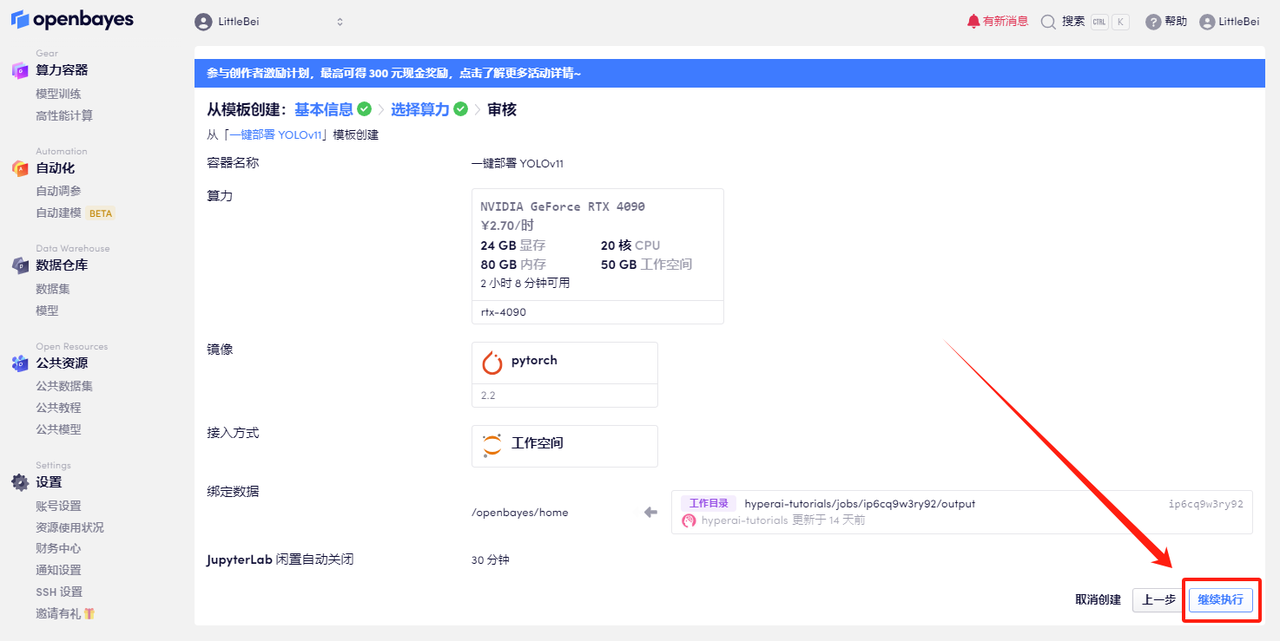
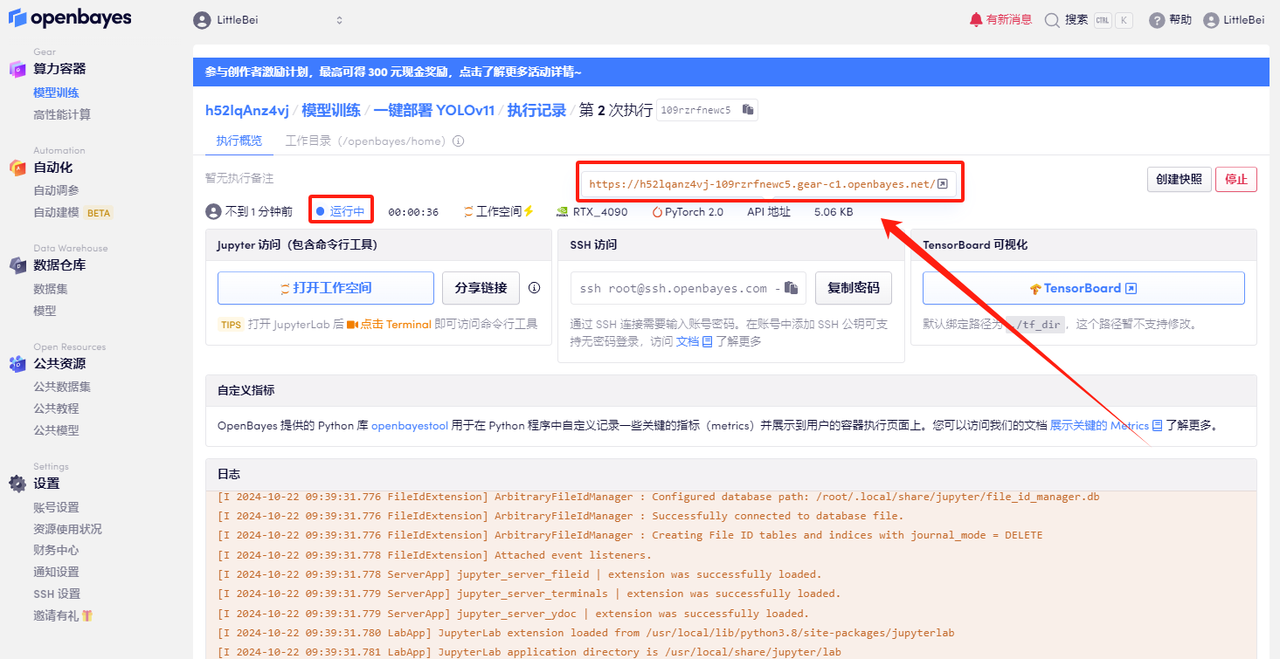
5. 確認後、「続行」をクリックし、リソースが割り当てられるのを待ちます。最初のクローン作成プロセスには約 2 分かかります。ステータスが「実行中」に変わったら、「API アドレス」の横にあるジャンプ矢印をクリックしてデモ ページに移動します。 APIアドレスアクセス機能を使用する前に、ユーザーは実名認証を完了する必要がありますのでご注意ください。
効果実証
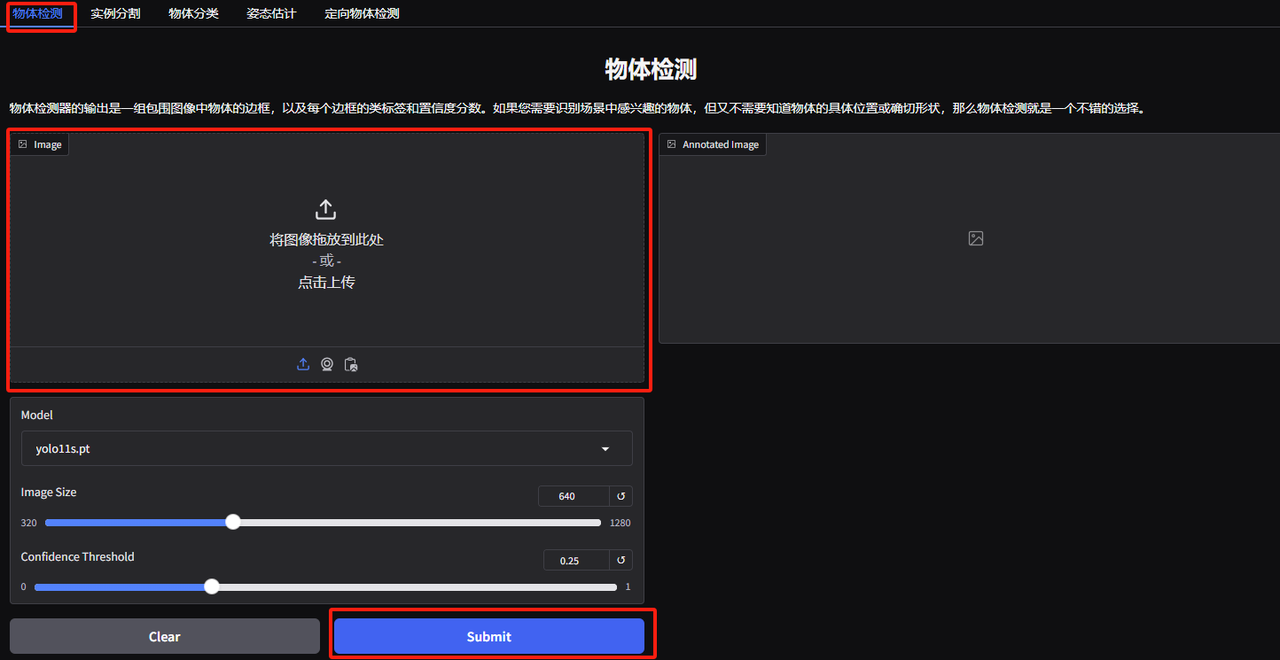
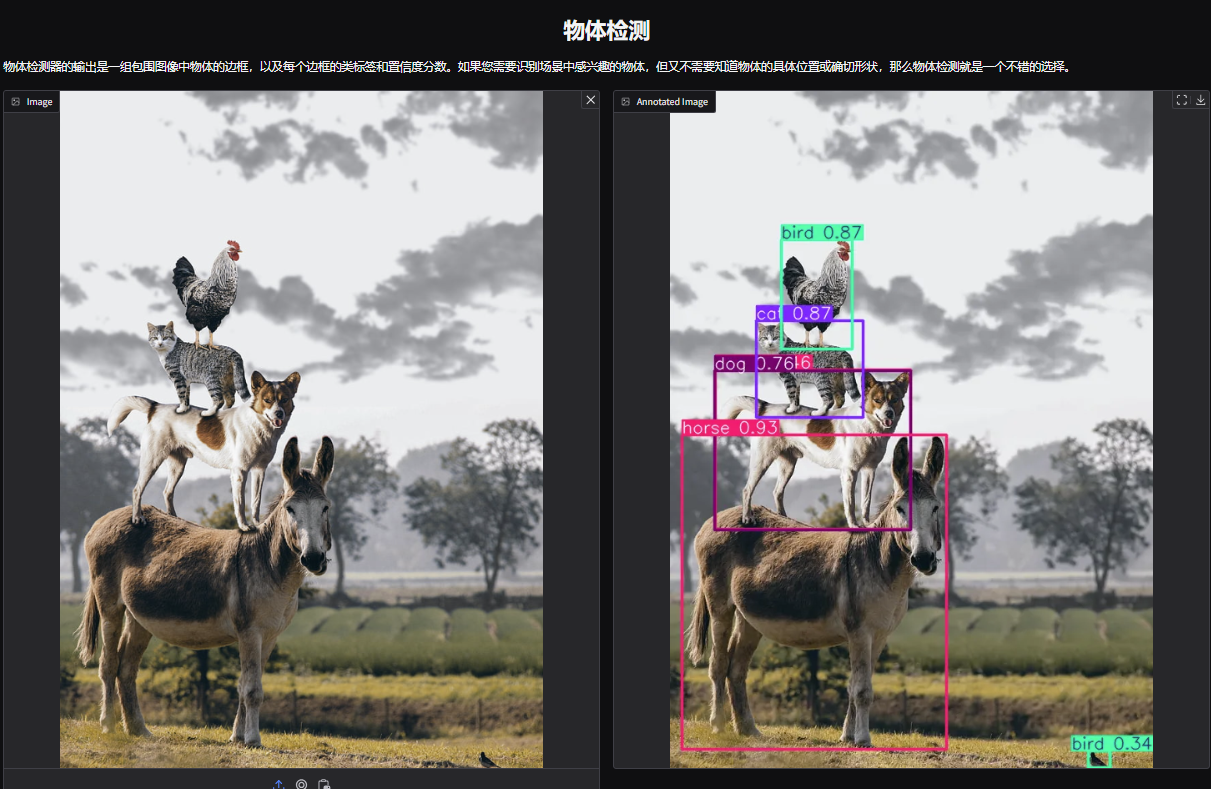
1. YOLOv11 オブジェクト検出デモ ページを開きます。編集者は、動物を重ね合わせた写真をアップロードし、パラメーターを調整して、[送信] をクリックします。YOLOv11 が写真内のすべての動物を正確に検出したことがわかります。右下に小鳥が隠れていることが分かりました!気づいてましたか〜
以下のパラメータはそれぞれ次のことを表します。
* モデル:使用するために選択された YOLO モデルのバージョンを指します。
※画像サイズ:画像のサイズを入力します。モデルは検出中に画像をこのサイズに調整します。
* 信頼度の閾値:信頼しきい値は、モデルがターゲット検出を実行するときに、この設定値を超える信頼レベルを持つ検出結果のみが有効なターゲットとみなされることを示します。
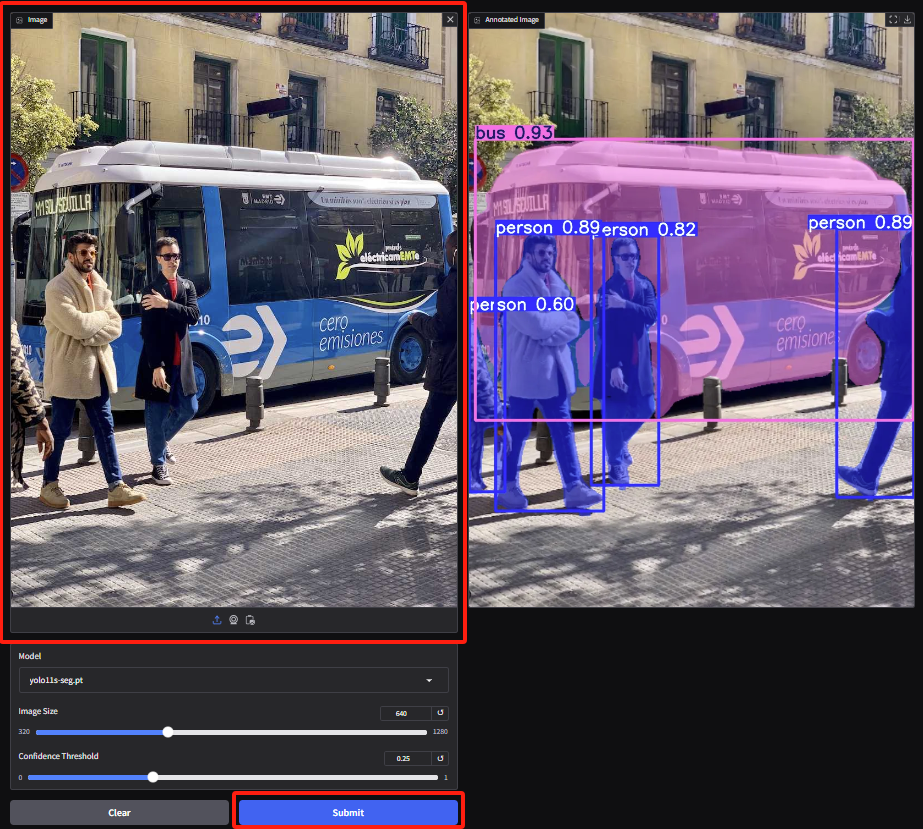
2. インスタンス分割のデモ ページに入り、画像をアップロードしてパラメータを調整し、[送信] をクリックして分割操作を完了します。オクルージョンが存在する場合でも、YOLOv11 は優れた仕事をし、人々を正確にセグメント化し、バスの輪郭を描きます。
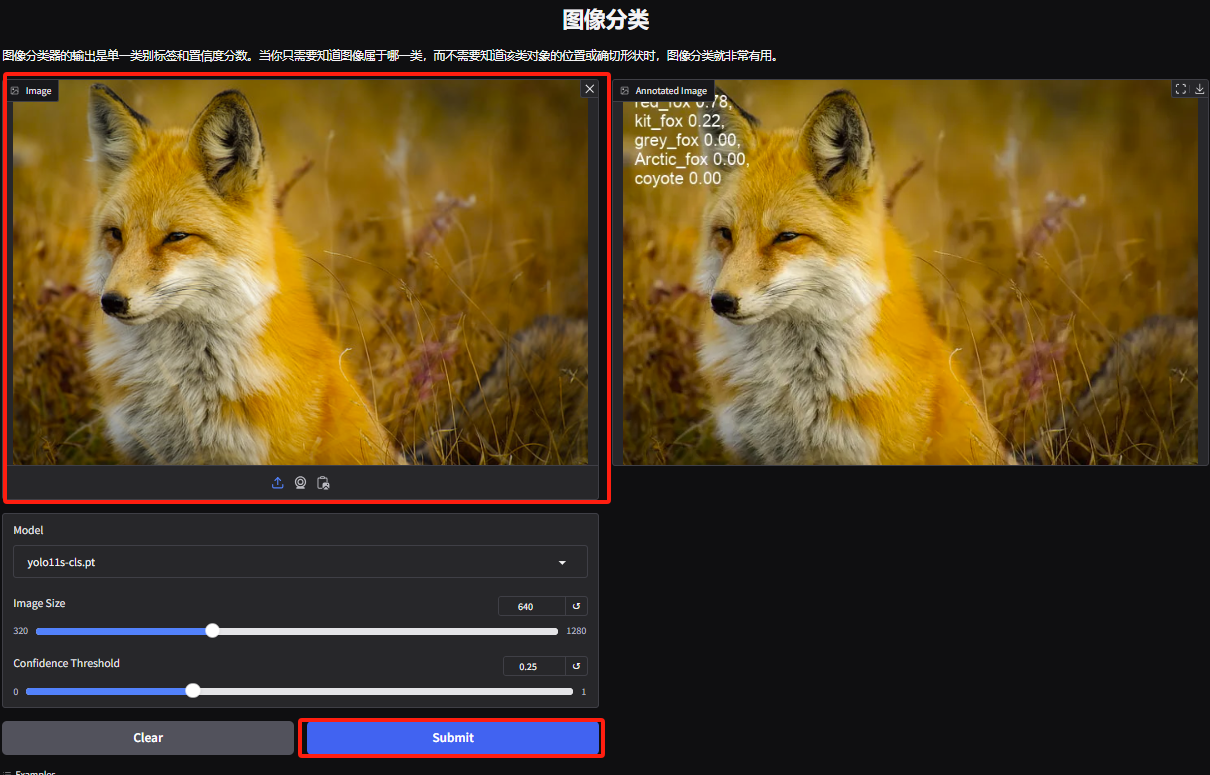
3. オブジェクト分類のデモ ページに入り、編集者がキツネの写真をアップロードすると、YOLOv11 は写真内の特定の種類のキツネがアカギツネであることを正確に検出できます。
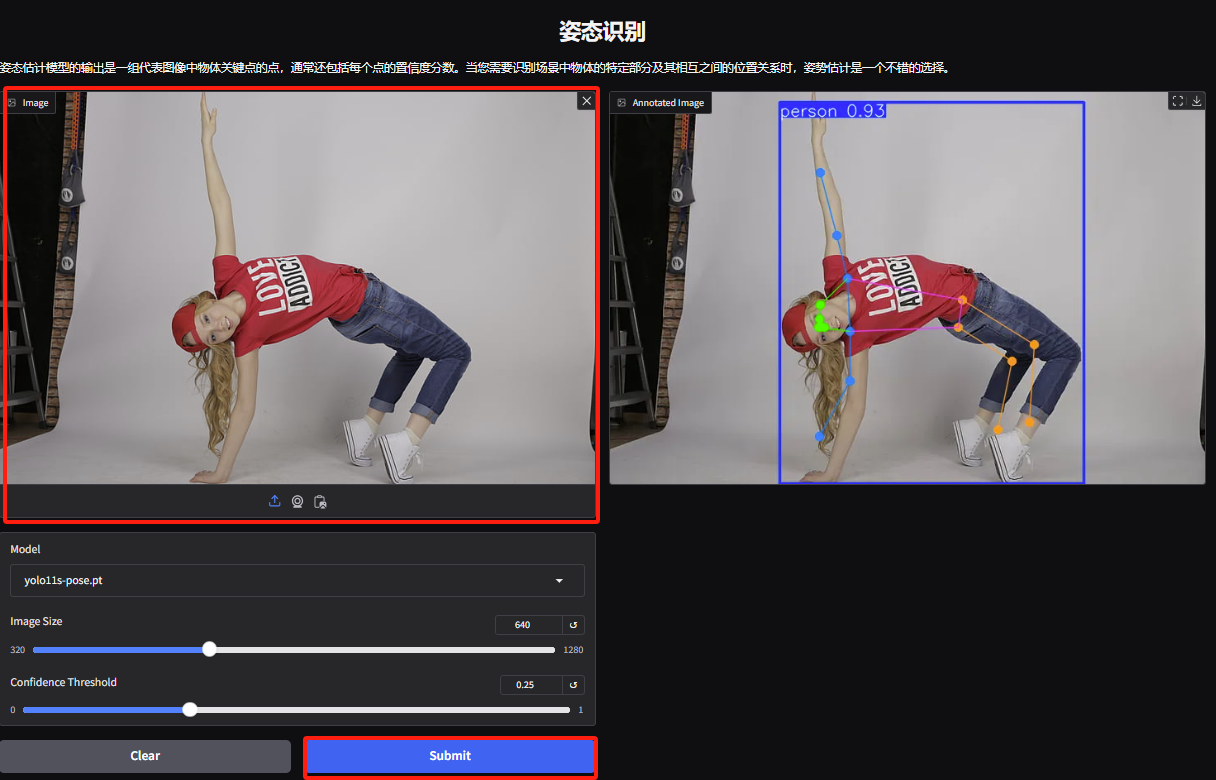
4. ジェスチャー認識デモページに入り、画像をアップロードし、画像に従ってパラメーターを調整し、「送信」をクリックしてジェスチャーアクション分析を完了します。キャラクターの誇張された体の動きを正確に分析していることがわかります。
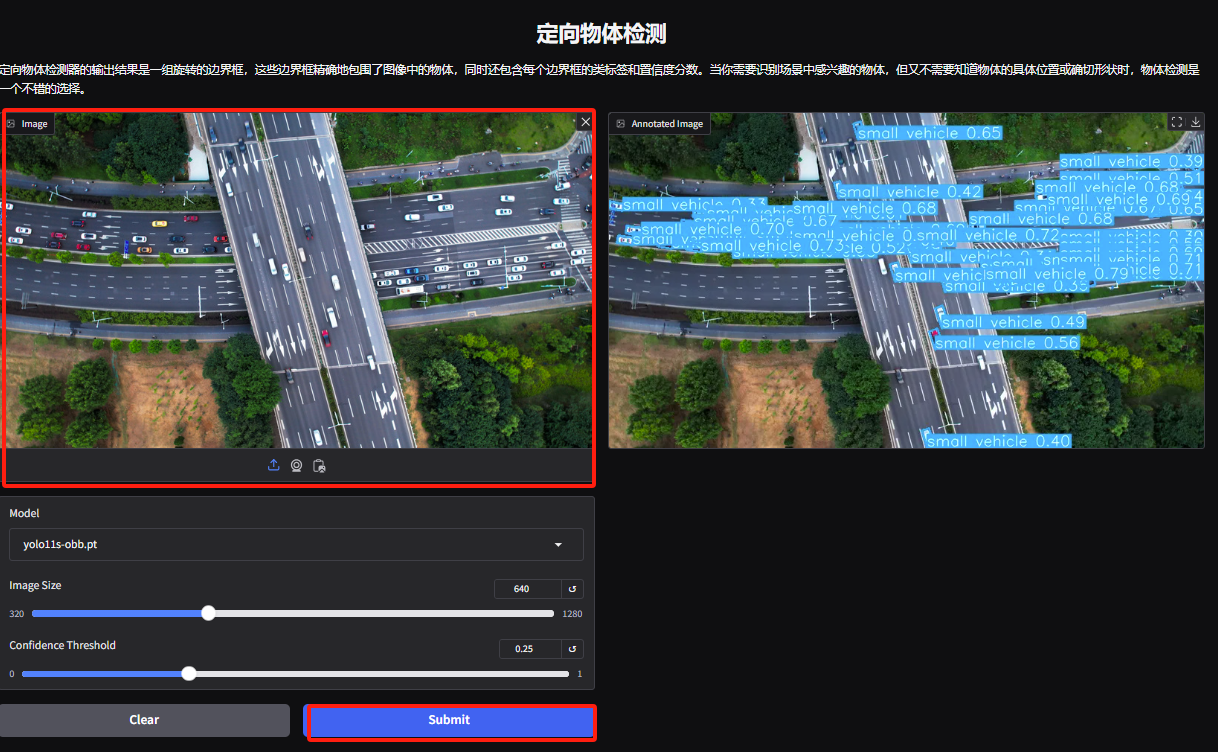
5. 指向性物体検出のデモ ページで、画像をアップロードしてパラメータを調整し、[送信] をクリックして物体の特定の位置と分類を特定します。