Command Palette
Search for a command to run...
GPT-4oを超えて! HTML からマークダウンまで、複雑な Web ページをワンクリックで整理します。AI ダイアログはもう冷たいものではなく、大規模なモデルダイアログの微調整データセットにより応答がスムーズになります。

情報が冗長な Web コンテンツに直面して、包括的なコア情報を迅速に抽出するにはどうすればよいでしょうか? Reader-LM モデルは、プロフェッショナルなソリューションを提供します。 Reader-LM は、最大 256K バイトの超長いコンテンツを効率的に処理し、HTML を明確な Markdown 形式に正確に変換できます。そのパフォーマンスは GPT-4o などの大規模な言語モデルをも上回っており、その軽量設計により、リソースに制約のあるシナリオにも適しています。
現在のところ、Reader-LM モデルが hyper.ai 公式 Web サイトで開始されました。ワンクリックで効率的な変換を体験できます。もう Web ページの情報を整理する必要はありません。
1 月 13 日から 1 月 17 日までの hyper.ai 公式 Web サイトの更新の概要:
* 高品質の公開データセット: 10
*厳選された高品質なチュートリアル: 9
* コミュニティ記事の選択: 5 記事
* 人気のある百科事典のエントリ: 5
※1月締切:5日
公式ウェブサイトにアクセスしてください: hyper.ai
公開データセットの選択
1. Human Like DPO データセット 大規模モデル対話微調整データセット
このデータセットは、より人間らしい応答を生成するようにモデルをガイドすることを目的として、大規模な言語モデルにおける会話の流暢さと関与を向上させるために特別に設計されたデータセットです。このデータセットは 256 のトピックをカバーしており、テクノロジー、日常生活、科学、歴史、芸術などの複数の分野に分散された 10,884 個のサンプルが含まれています。
直接使用します:https://go.hyper.ai/zDsGL

2. MedQA 医療テキストの質問と回答のデータ セット
MedQA データセットは、米国医師免許試験 (USMLE) のスタイルをシミュレートし、医療知識を理解し、適用するモデルの能力を評価するように設計されています。このデータセットは専門的な健康診断から収集され、英語、簡体字中国語、繁体字中国語をカバーしており、それぞれ 12,723、34,251、14,123 の質問が含まれています。
直接使用します:https://go.hyper.ai/cV2ei
3. 野菜識別 野菜画像認識データセット
このデータセットには、ナス、インゲン、オクラ、尖ったメロン、ジャガイモ、タマネギの 6 種類の野菜の画像が含まれており、野菜の検出、分類における機械学習とコンピューター ビジョンを強化するように設計されています。そして識別機能。
直接使用します:https://go.hyper.ai/mCZr4

4. 中国のストリートビュー交通標識データセット
このデータセットは 9,898 枚のストリート ビュー画像で構成されています。各写真には少なくとも 1 つ以上の交通標識が含まれており、交通標識の座標とカテゴリに注釈が付けられます。データは中国交通標識検出データベースから取得されています。
直接使用します:https://go.hyper.ai/9wb5f

5. 前処理されたヘビ画像 前処理されたヘビ画像データセット
このデータ セットには、キタウォータースネーク、コモンガータースネーク、デリックブラウンスネーク、クマネズミスネーク、ニシガラガラヘビの 5 種類のヘビが含まれています。データセットは明るさとコントラストを高めるために前処理され、画像は手動で削除およびトリミングされて、画像がよりきれいで均一になり、使いやすくなりました。
直接使用します:https://go.hyper.ai/YAgyI

6. 中国の交通標識 中国の交通標識画像データ
このデータセットには、58 カテゴリの 5,998 個の交通標識画像が含まれています。各画像は 1 つの交通標識を拡大したものです。注釈は、画像のプロパティ (ファイル名、幅、高さ) に加えて、画像およびカテゴリ内の交通標識の座標 (制限速度 5 km/h など) を提供します。
直接使用します:https://go.hyper.ai/Tvvh8

7. Human Style Preferences Images 画像生成設定データセット
このデータセットは、テキストから画像への生成モデルを評価するための人による注釈付きデータセットです。これは、2 つの画像を表示し、どちらの画像が奇妙または不自然に見えないかを参加者に尋ねることによって、画像生成モデルの人間の一貫性評価を収集しており、120 万件を超える人間の一貫性投票が含まれています。
直接使用します:https://go.hyper.ai/dErEz
8. M²E: 複数行の数式データセット
このデータセットには、99,956 個の複数行の数式画像とその注釈が含まれています。すべての画像は、現実世界のシナリオから携帯電話を使用してキャプチャされており、数学の試験問題や問題集から複数行の数式が抽出されており、数式認識タスクに使用できます。
直接使用します:https://go.hyper.ai/5BMnN
9. 中国語対句データセット 中国語対句データセット
このデータ セットには約 740k ペアのカプレットが含まれており、fixed_couplets_in.txt が上部のカプレット、fixed_couplets_out.txt が下部のカプレットです。
直接使用します:https://go.hyper.ai/oPxHl
10. オーディオ ノイズ データセット オーディオ ノイズ データ セット
このデータセットには 10 の異なるカテゴリのノイズが含まれており、音声分類、音声認識、音声生成、および音声関連の機械学習におけるノイズ フィルタリング、ノイズ生成、およびノイズ識別に使用できます。
直接使用します:https://go.hyper.ai/MXXZy
選択された公開チュートリアル
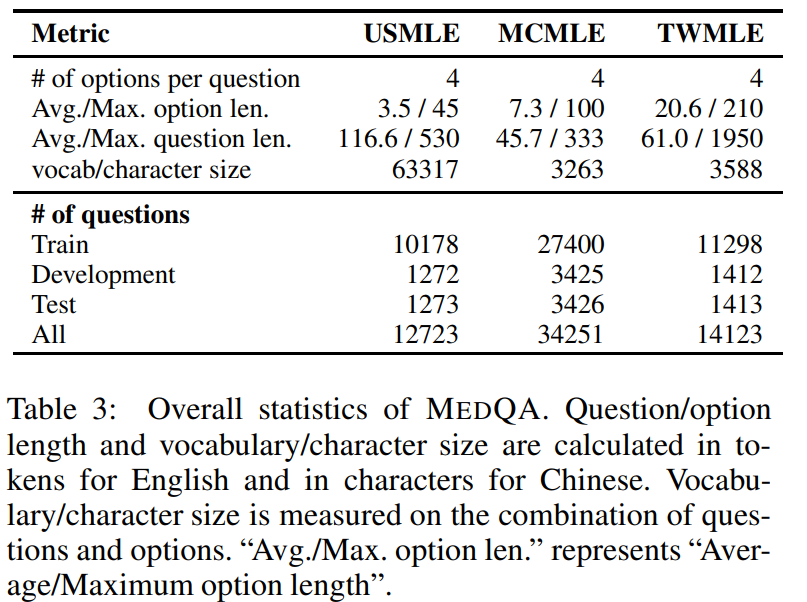
1. Reader-LM: HTML を迅速かつ効率的に MarkDown に変換します
Reader-LM モデルは、Web 上の生の HTML コンテンツを明確で整った Markdown 形式に変換するように特別に設計されています。長いテキストと多言語コンテンツの処理に優れており、最大 256K バイトのコンテキスト長をサポートします。ノイズの多い Web コンテンツから効率的かつコスト効率よくデータを抽出するニーズに対応するように設計されています。
このチュートリアルでは、reader-lm-1.5b または Reader-lm-0.5b を使用して HTML をマークダウンに変換する方法を説明します。以下のリンクをクリックし、チュートリアルの指示に従って体験してください。
オンラインで実行:https://go.hyper.ai/S15IL
2. DeepSeek-V2-Lite-Chat のワンクリック導入
DeepSeek-V2 は、経済的なトレーニングと効率的な推論を特徴とする強力な専門家混合 (MoE) 言語モデルです。これには合計 236B のパラメータが含まれており、各トークンは 21B のパラメータをアクティブにします。
このチュートリアルは、DeepSeek-V2-Lite-Chat のワンクリック展開デモです。コンテナを複製して起動し、生成された API アドレスを直接コピーするだけで、モデルの推論を体験できます。
オンラインで実行:https://go.hyper.ai/AD6XU
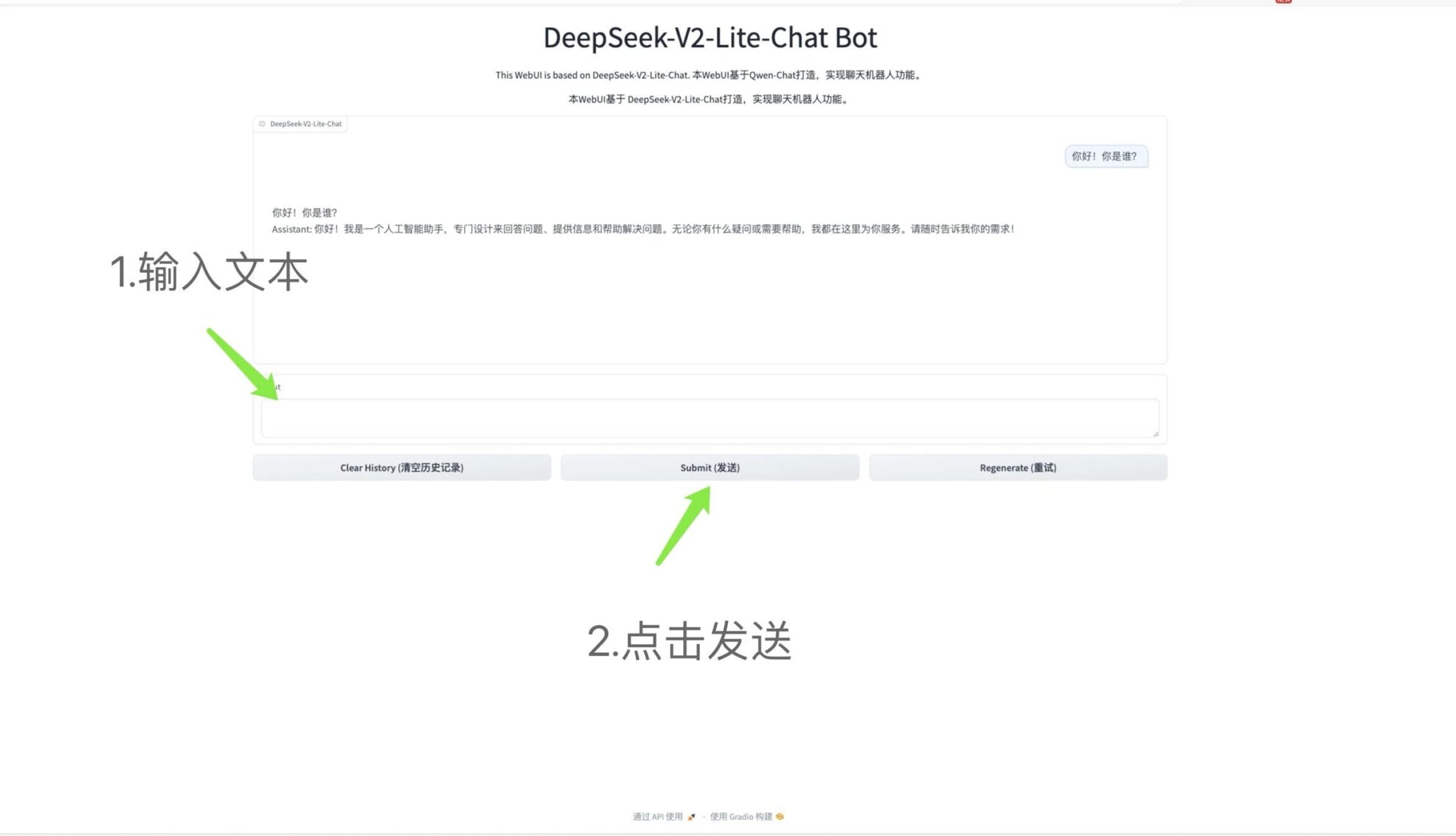
3.ワンクリックで ChemVLM-26B を導入
ChemVLM は、化学分野向けのオープンソースのマルチモーダル大規模言語モデルです。このモデルは、ビジュアルトランスフォーマー (ViT)、多層パーセプトロン (MLP)、および大規模言語モデル (LLM) の利点を組み合わせることにより、化学画像の理解とテキスト分析の間の非互換性の問題を解決することを目的としています。総合的な推論。
チュートリアルの手順に従い、生成された API アドレスを直接コピーして ChatVLM-26B を使用します。
オンラインで実行:https://go.hyper.ai/NRBXG
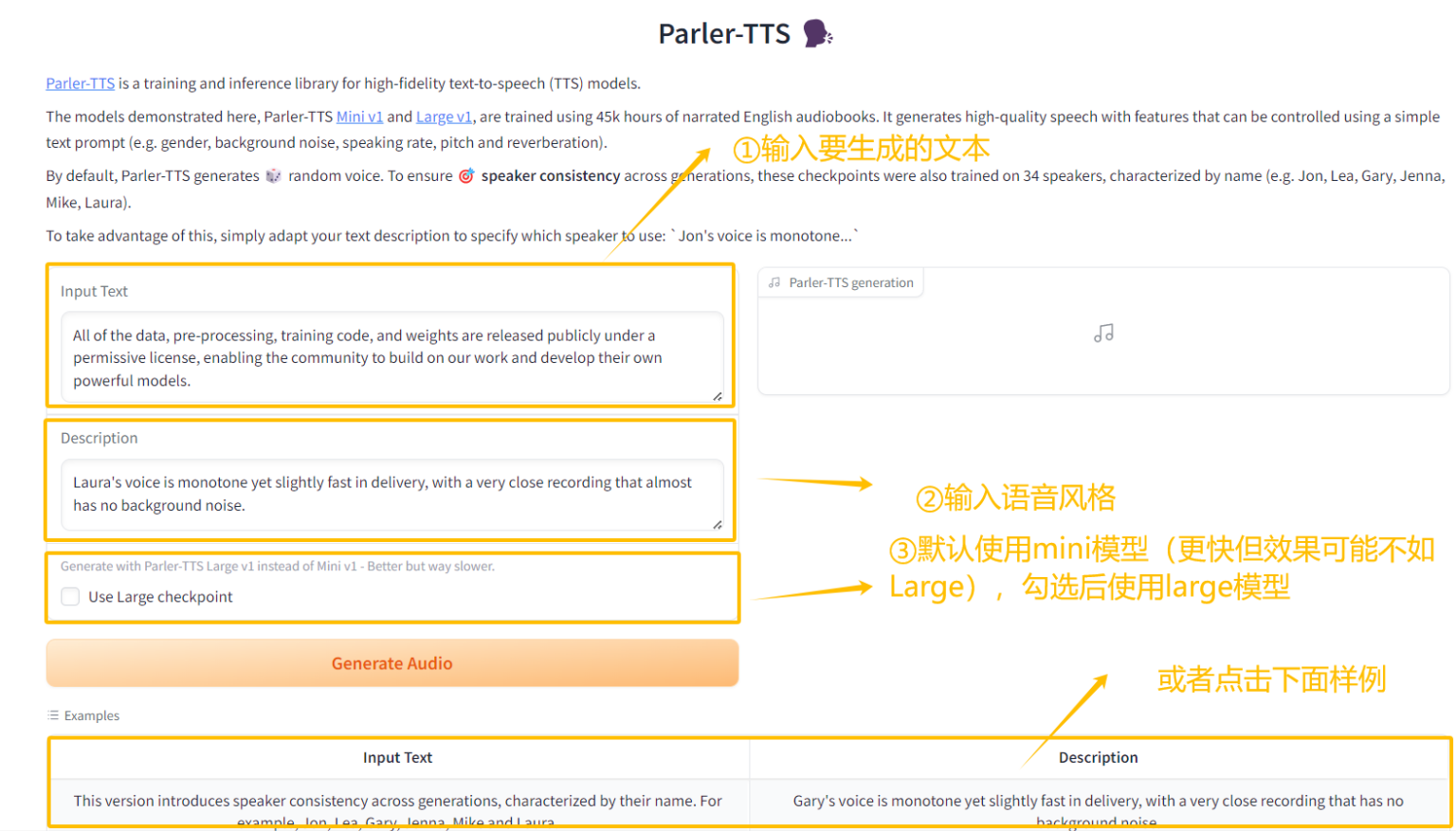
4. ワンクリックで Parler-TTS を導入します
Parler-TTS は、特定の話者のスタイルで高品質で自然な音声を生成できる軽量のテキスト読み上げ (TTS) モデルです。高い自由度と革新性があり、プロンプトを通じて話者の性別を制御できます。 、音色、イントネーション、シーン(屋内、屋外、路上、コンサートホールなど)。
このプロジェクトでは、Gradio インターフェイスを通じてフロントエンドのインタラクティブ インターフェイスを生成でき、関連するモデルと依存関係がデプロイされており、ワンクリックでウォーター オーディオ ファイルを生成できます。
オンラインで実行:https://go.hyper.ai/pk6lF
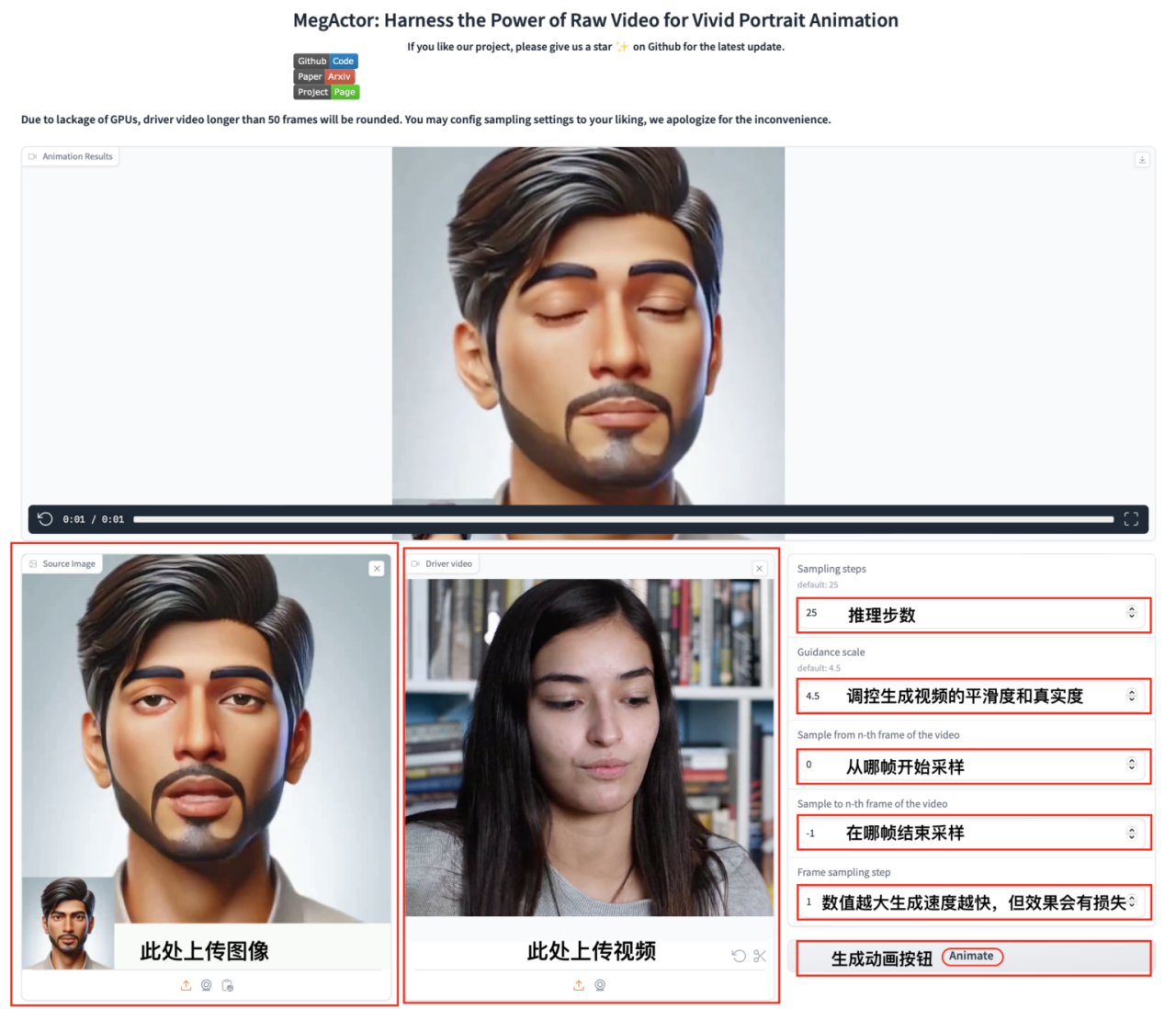
5. MegActor ポートレート アニメーション ジェネレーターのデモ
MegActor は、生のビデオをドライバーとして使用して、トーキングヘッドのリアルなアニメーションビデオを生成するポートレートアニメーションジェネレーターです。
チュートリアルの手順に従い、スタートアップのクローンを作成して API アドレスを開くだけで、元のビデオ コンテンツに基づいて鮮明な合成ビデオを生成できます。
オンラインで実行:https://go.hyper.ai/wkCPo
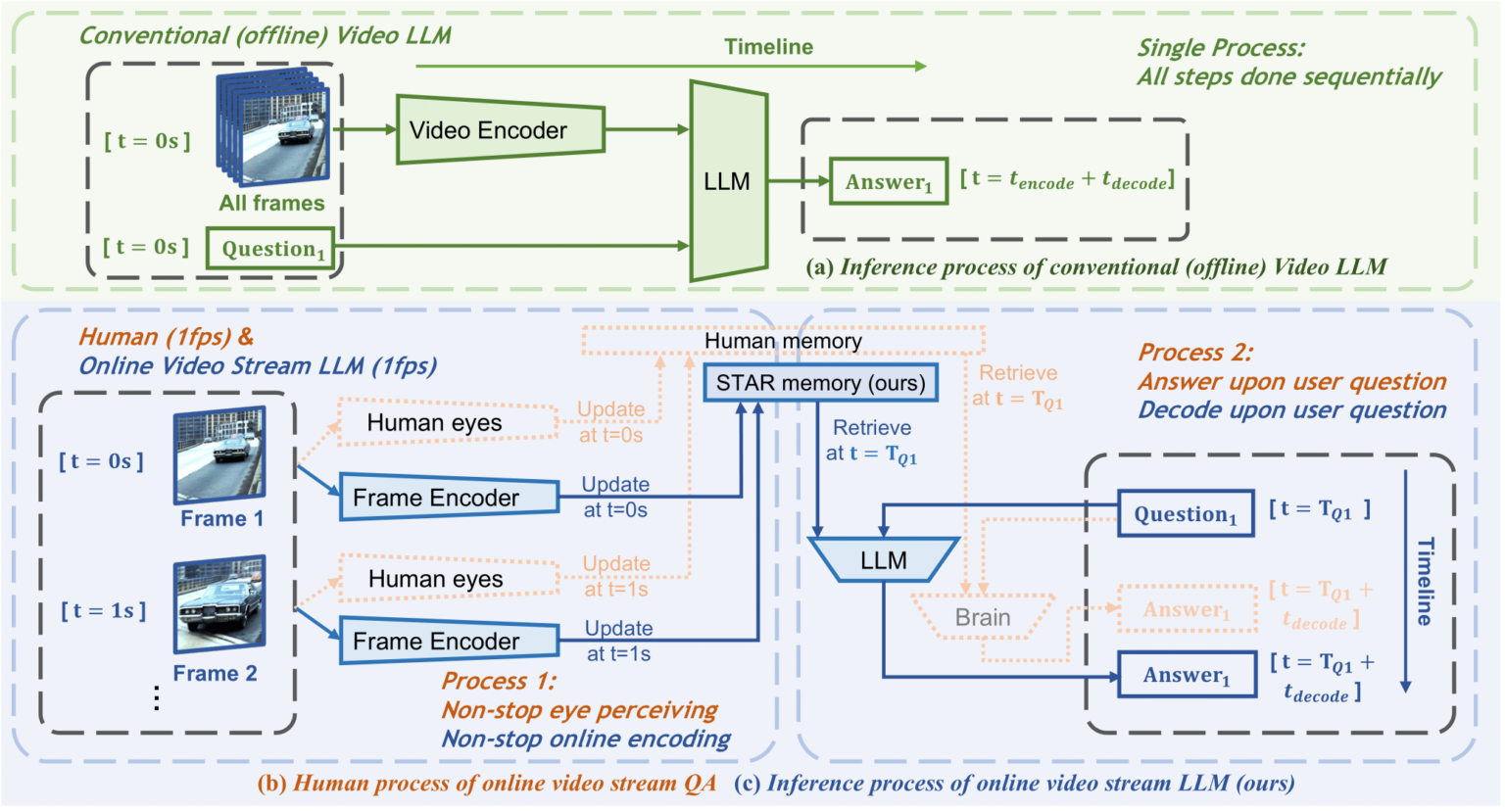
6. Flash-VStreamビデオ理解デモ
Flash-VStream は、人間の記憶メカニズムをシミュレートするビデオ言語モデルです。非常に長いビデオ ストリームをリアルタイムで処理し、同時にユーザーのクエリに応答することができます。
このチュートリアルは、Flash-VStream のワンクリック実行デモです。クローンを作成してワンクリックで開始することで、関連する環境と依存関係がインストールされています。
オンラインで実行:https://go.hyper.ai/M3pBO
7. PhotoMaker V2 はパーソナライズされた写真を数秒で生成します デモ
PhotoMaker は、2024 年に Tencent チームによってオープンソース化された効率的なポートレート カスタマイズ モデルです。ポートレートに基づいてカスタマイズされた芸術的なスタイルの写真を迅速に生成できます。パーソナライズされた人物の写真を生成するだけでなく、人物の年齢や性別を変更したり、さまざまな人物の特徴を統合して新しい人物情報を作成したりすることもできます。
このチュートリアルは PhotoMaker のバージョン 2.0 であり、V1 に比べて文字の一貫性と操作性が大幅に向上しています。
オンラインで実行:https://go.hyper.ai/VcewN

8. StoryDiffusion コミックビデオジェネレーターのデモ
StoryDiffusion は、長距離画像とビデオの生成に焦点を当てた AI ツールです。このテクノロジーは、一貫したセルフアテンション メカニズムを利用して、漫画や漫画のキャラクターを作成するプロセスでも、長いビデオを生成するプロセスでも、画像とビデオのコンテンツの連続性と一貫性を確保し、スタイルの統一性を維持できます。
このチュートリアルは、StoryDiffusion ワンクリック実行パッケージの最新バージョンです。ワンクリッククローンで StoryDiffusion を体験できます。
オンラインで実行:https://go.hyper.ai/HPu2p

9. 分子動力学シミュレーター LAMMPS を簡単に開始: npt 温度制御により FCC Cu 融点を推定
LAMMPS は固体材料 (金属、半導体)、生体分子、ポリマー、その他の材料のモデル化に使用でき、さまざまな材料に対してさまざまな粒子相互作用モデルを提供できます。
このチュートリアルは、LAMMPS の入門チュートリアルです。npt 温度制御により、FCC Cu の融点を推定します。LAMMPS の CPU バージョンを使用して実行し、分子動力学シミュレーションを体験できます。
オンラインで実行:https://go.hyper.ai/qQSqr
💡安定拡散チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] にメモし、グループに参加してさまざまな技術的な問題について話し合い、アプリケーションの効果を共有してください。

注目のコミュニティ記事
1. 活動レビュー | コンピューティング・ネットワーク・ソフトウェア・アルゴリズム・エコロジーの共同開発、2024 Meet AI Compiler が無事終了しました。
Meet AI Compiler の第 6 回テクニカル サロンのレビューはこちらです。Horizon、Zhiyuan、ByteDance、Lingchuan Technology の 4 人の上級コンパイラー エキスパートが、それぞれのチームの最新の研究結果を示し、豊富な実践経験も併せて示しました。アプリケーション ケースでは、アプリケーション プロセスについて説明しました。これらの効果により、実践的な問題をシンプルかつ分かりやすく解決します。
イベントの概要を確認してください:https://go.hyper.ai/KDzY3
2. コンピューター ビジョンから医療 AI まで、上海交通大学の謝偉迪氏との会話: 問題を解決することよりも問題を定義することが重要
HyperAI は、上海交通大学の常任准教授である Xie Weidi 教授に詳細なインタビューを実施し、彼の個人的な経験に基づいて、コンピューター ビジョンからヘルスケア向け AI への変革に関する経験を共有しました。業界の将来の発展傾向を深く分析します。インタビューの詳細レポートです。
レポート全体を表示します。https://go.hyper.ai/LqpqE
触覚知覚は、インテリジェントロボットおよび人間とコンピューターのインタラクションの重要な機能の 1 つですが、高精度で高速応答の触覚センシングを実現する方法には依然として多くの課題があります。フランス国立科学研究センターのヤン・ユーカン博士は、柔軟な磁気フィルムに基づく触覚センサーの設計と応用について共有し、直交磁化ハルバッハアレイを使用して三次元力の自己分離を実現する方法を紹介しました。この記事は、共有された内容の詳細なレポートです。
レポート全体を表示します。https://go.hyper.ai/Y5uA0
4.AAAI2025に選出されました!国内の主要2大学が共同提案したBSAFusionにより、マルチモーダル医用画像の位置合わせと融合を実現できます。
マルチモーダル医用画像フュージョンは、多くの貴重な情報を収集し、医師がより専門的な病気の診断を行うのに役立ちますが、現在直面している大きな課題は、フュージョンに使用される機能と位置合わせに使用される機能に互換性がないことです。昆明科学技術大学と中国海洋大学は、マルチモーダル医療画像の位置合わせと融合を実現できる双方向の段階的特徴位置合わせ方法BSAFusionを提案しました。この記事は、論文の詳細な解釈と共有です。
レポート全体を表示します。https://go.hyper.ai/sTySj
医療資源の不足は世界の医療システムを悩ませている長期的な問題であるため、4大大学の研究チームがKG4Diagnosisを提案した。これは、医療知識グラフの構築、診断、治療、推論を自動化するために使用できる新しい階層型マルチエージェント フレームワークで、肥満など複数の医療分野にわたる 362 の一般的な病気の診断に役立ちます。この記事は、論文の詳細な解釈と共有です。
レポート全体を表示します。https://go.hyper.ai/0CPhV
人気のある百科事典の項目を厳選
1. 拡散損失拡散損失
2. 因果関係への注意
3. コルモゴロフ・アーノルド表現定理
4. 大規模マルチタスク言語理解MMLU
5. 対照学習
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。
1月の締め切り会議

主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!
HyperAIについて Hyper.ai
HyperAI(hyper.ai)は、中国をリードする人工知能とハイパフォーマンス・コンピューティングのコミュニティである。国内データサイエンス分野のインフラとなり、国内開発者に豊富で質の高い公共リソースを提供することに注力しています。
* 1700 を超える公開データ セットに対して国内の高速ダウンロード ノードを提供
* 500 以上の古典的で人気のあるオンライン チュートリアルが含まれています
* 200 以上の AI4Science 論文ケースを解釈
* 600 以上の関連用語クエリをサポート
*Apache TVM の最初の完全な中国語ドキュメントを中国でホストします
学習の旅を始めるには、公式 Web サイトにアクセスしてください。
最後に、「クリエイター インセンティブ プログラム」をおすすめします。興味のあるお友達はコードをスキャンして参加してください。









