Command Palette
Search for a command to run...
AAAI2025に選出されました!国内の主要2大学が共同提案したBSAFusionにより、マルチモーダル医用画像の位置合わせと融合を実現できます。
2024 年末、人工知能に関する最高の国際会議である第 39 回 AAAI 年次人工知能会議 (AAAI 2025) は、この会議への論文の受理結果を発表しました。最終的に、12,957 件の投稿のうち、合計 3,032 件が採択されました。論文も含まれていましたが、採択率はわずか 23.4% でした。
で、昆明理工大学情報工学自動化学部のLi Huafeng氏、Zhang Yafei氏、Su Dayong氏のチームと、コンピュータサイエンス学部情報科学部のCai Qing氏のチームが共同研究したテーマ。中国海洋大学工学部——「BSAFusion: 非整列医用画像融合のための双方向段階的特徴整列ネットワーク」は、AI for Science 研究者の注目を集めています。このトピックでは、近年空前の人気を誇る医用画像処理の分野に焦点を当て、双方向段階的特徴位置合わせ (BSFA) 非整列医用画像融合手法を提案します。
従来の方法と比較して、この研究では、単一段階の方法を通じて、統一された処理フレームワーク内で、位置合わせされていないマルチモーダル医用画像の同時位置合わせと融合を実現します。これは、二重タスクの調整を実現するだけでなく、複数の独立した特徴エンコーダーの導入によって引き起こされるモデルの複雑さの問題も効果的に軽減します。

公式アカウントをフォローし、バックグラウンドで「Multimodal Medical Images」に返信すると、完全な PDF が表示されます
オープンソース プロジェクト「awesome-ai4s」は、100 を超える AI4S 論文の解釈をまとめ、大規模なデータ セットとツールを提供します。
https://github.com/hyperai/awesome-ai4s
Medical Focus - マルチモーダル医用画像融合
いわゆるマルチモーダル医用画像融合 (MMIF)、CT、MRI、PETなどのさまざまな画像法からの医用画像データを融合して、より包括的かつ正確な病変情報を含む新しい画像を生成することです。この方向の研究は、現代医学および臨床応用において非常に価値があります。
理由は単純です。数十年にわたる技術開発と発展を経て、医療画像処理の形式がより豊富になっただけでなく、使用方法もより一般的になりました。例えば、大きく転倒した場合、まず病院に行って骨折の有無を判断するために「フィルムを撮る」ということが考えられますが、「フィルムを撮る」とは通常X検査などの医用画像検査を指します。放射線、CTまたはMRI。
しかし、臨床医学において、特に腫瘍やがん細胞などの困難で複雑な疾患に直面する場合、単一の医用画像から臨床診断の正確性を保証するのに十分な情報を抽出するだけでは明らかに十分ではありません。マルチモーダル医用画像の融合は、現代の医用画像の開発における重要なトレンドの 1 つとなっています。マルチモーダル医用画像融合は、異なる時間とソースからの画像を 1 つの座標系に統合して登録します。これにより、医師の診断効率が大幅に向上するだけでなく、マルチモーダル医用画像融合からより価値のある情報が得られ、医師の診断にも役立ちます。より専門的に疾患をモニタリングし、効果的な治療計画を提供します。
医療画像が応用される前から、多くの科学研究者はすでに画像融合の問題に気づいており、マルチソース画像のレジストレーションと融合を、有名な MURF などの統一フレームワークに初めて統合する方法をさらに研究しました。 、画像の位置合わせと融合は 1 次元で議論され、解決されます。そのコア モジュールには、共有情報抽出モジュール、マルチスケールの粗い位置合わせモジュール、および詳細な位置合わせと融合モジュールが含まれます。
しかし、前述したように、第一に、これらの方法はマルチモーダル医用画像融合用に設計されておらず、医用画像の分野で期待される利点を示していない。第二に、これらの方法はマルチモーダルの問題を解決できない。医療画像の融合という最も重要な課題に直面しています。融合に使用されるフィーチャと位置合わせに使用されるフィーチャ間の非互換性の問題。
具体的には、特徴の位置合わせでは、対応する特徴が一貫していることが必要ですが、特徴の融合では、対応する特徴が相補的であることが必要です。
これは実際には理解するのが難しいことではありません。特徴アライメントは、さまざまな技術的手段を通じて異なるモーダル データのマッチングと対応を実現することです。一方、特徴融合は、異なるモダリティ間の相補性を最大限に活用して抽出することができます。さまざまなモダリティからの情報を安定したマルチモーダル モデルに統合します。
したがって、MMIF にとってその困難は容易に想像できます。このギャップは誰かが埋める必要があるだけでなく、先行技術に基づいてより効率的かつ便利なマルチモーダル医用画像融合を達成できる必要もあります。論文では、Li Huafeng 教授のチームと Cai Qing 准教授のチームは、研究実験を通じてこの当初の意図を実証し、実践しました。
技術的な観点から見ると、この方法ではいくつかの革新的な設計が提案されています。
* まず、特徴エンコーダーを共有することで、この方法は、登録用の追加エンコーダーの導入によって引き起こされるモデルの複雑さの増加の問題を解決し、特徴クロスモーダルの位置合わせと融合を統合する統一された効果的なフレームワークを設計することに成功し、位置合わせとブレンディングがシームレスに行われることを実現します。
* 第 2 に、統合されたモーダル不一致のない特徴表現 (MDF-FR) 手法は、各入力画像にモダリティ特徴表現ヘッド (MFRH) を追加することでグローバルな特徴統合を実現し、モーダルの違いやマルチモーダル情報の不一致の影響を大幅に軽減します。機能の調整について。
* 最後に、2 点間のベクトル変位経路の独立性に基づく双方向段階的変形場予測戦略が提案されます。これにより、従来の 1 段階アライメント法で発生する大きなスパンと不正確な変形場予測の問題を効果的に解決できます。
BSAFusion は医療画像融合の新たな方向性を開拓します
研究グループが提案した一段階マルチモーダル医用画像登録・融合フレームワークは、これは主に、MDF-FR、BSFA、MMFF (Multi-Modal Feature Fusion) という 3 つのコア コンポーネントで構成されています。詳細を以下の図に示します。
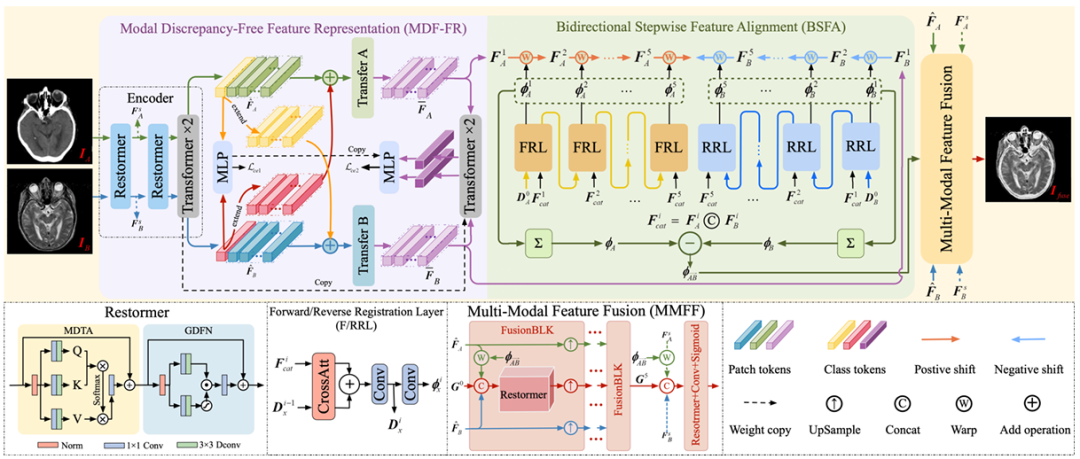
MDF-FR でそれを見るのは難しくありません。Restormer 層と Transformer 層はネットワークのエンコーダーを形成し、位置合わせされていない画像ペアから特徴を抽出します。 Restormer 層と Transformer 層にはそれぞれ 2 つの層があります。 2 つの特徴の位置合わせと融合の後、後続の MLP に入力することで予測結果が得られます。
ここで、得られた 2 つのモダリティ間の大きな違いにより、これらの特徴のクロスモーダル マッチングと変形フィールド予測も大きな課題に直面することになります。したがって、この方法では、モダリティ固有の特徴表現ヘッドが生成されるだけでなく、モードの違いが変形場の予測に及ぼす影響を軽減するだけでなく、共有情報の抽出による非共有情報の損失も防ぎます。
その後、チームは引き続き Transfer A と Transfer B を使用して、モード間の差異を排除しました。各 Transfer ブロックは 2 つの Transformer レイヤーで構成されており、変形部位の予測に必要な特徴をさらに抽出するために、それらの間でパラメーターは共有されません。
BSFAに来てください。研究チームは、入力画像の特徴を 2 つの方向から予測する変形フィールド (双方向の段階的特徴アライメント法) を設計しました。これは、前方予測と逆予測の両方に対応する 5 層の変形フィールド予測演算を設計しました。 2 つの入力ソース画像と 5 つの中間ノードを使用するこのアプローチにより、位置合わせプロセスの全体的な堅牢性が向上します。順方向登録層を担当するのは FRL であり、逆方向登録層を担当するのは RRL です。
最後に、MMFF モジュールに移動します。予測された変形フィールドを適用して特徴を位置合わせし、次に複数の FusionBLK モジュールを使用して特徴を融合します。最後に、融合された画像が再構成レイヤーを通じて取得され、さまざまな損失関数がネットワーク パラメーターを最適化します。
もちろん、実験の有効性と厳密性を確保するために、研究チームは実験の詳細に細心の注意を払いました。このモデルに基づく実験では、研究チームは既存の方法のプロトコルに従いました。モデルのトレーニングには、ハーバード大学の CT-MRI、PET-MRI、SPECT-MRI データセットが使用されました。これらのデータセットは、それぞれ 144、194、および 261 の厳密に登録された画像ペアで構成され、各オブジェクト ペアのサイズは 256 x 256 です。
実際のシーンで収集された位置ずれした画像ペアをシミュレートするために、この実験では MRI 画像が参照として特に指定され、剛体変形と非剛体変形が混合して非 MRI 画像に適用されて、必要なトレーニング セットが作成されました。さらに、研究チームは、厳密に位置合わせされた画像の 20、55、および 77 ペアにも同じ変形を適用して、位置合わせされていないテスト セットを構築しました。
トレーニング プロセスはエンドツーエンド方式を採用し、各データ セットで 3,000 エポックをトレーニングし、バッチ サイズは 32 です。同時に、Adam オプティマイザーを使用して、初期学習率 5 x 10⁻⁵ でモデル パラメーターを更新します。コサイン アニーリング学習率 (LR) を使用します。これは時間の経過とともに 5 x 10⁻⁷ に減少します。
実験では PyTorch フレームワークを使用し、単一の NVIDIA GeForce RTX 4090 GPU でトレーニングされました。
研究グループの正確な実験の詳細とトレーニングとしての標準データセットに基づいて、この方法は実験結果においても優れた結果を示しました。
実験の比較対象は、UMF-CMGR、superFusion、MURF、IMF、PAMRFuse の 5 つの最先端の結合登録方式です。最後のグループを除いて、最初の 4 つはマルチモーダル医用画像融合用に特別に設計された方法ではありませんが、現時点では最良の画像融合方法であり、MMIF に適しています。以下に示すように:
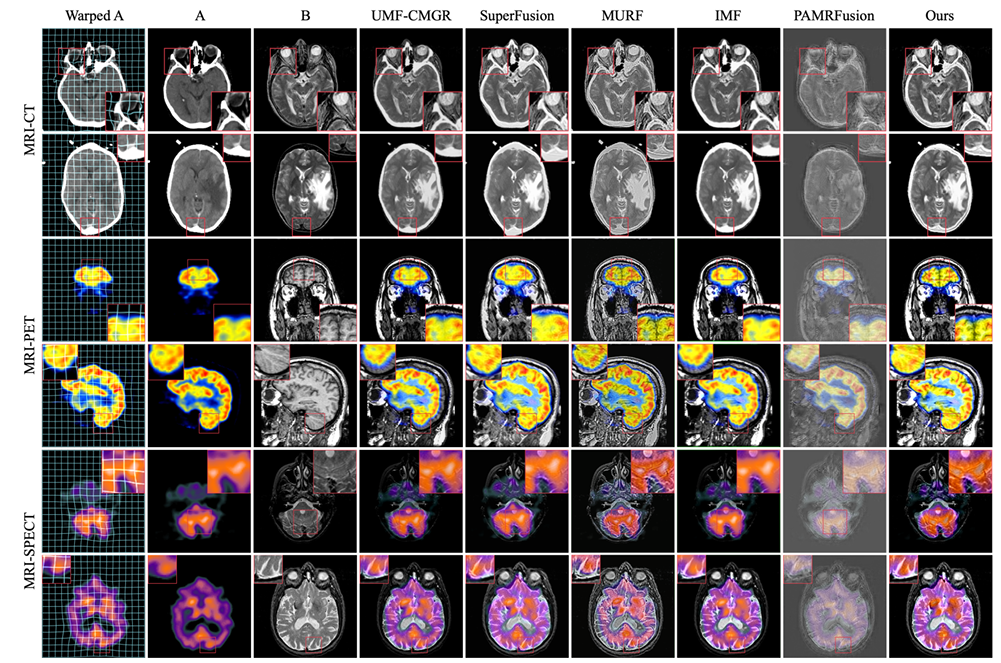
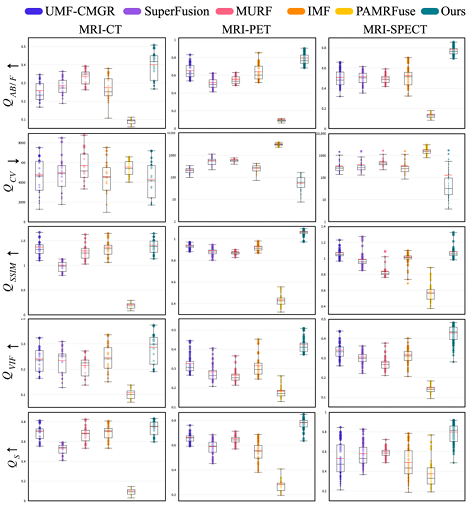
結果は明らかであり、研究チームが提案した方法は、特徴の位置合わせ、コントラストの維持、ディテールの保持の点でより優れた優位性を示しており、すべての指標の中で最高の平均パフォーマンスを示しています。
チームは協力して医療臨床アプリケーションを保護します
この研究テーマの責任著者の 1 人である Cai Qing は、中国海洋大学情報科学工学部コンピュータ科学技術学部の准教授であり、中国海洋大学でも勤務しています。中国コンピュータ連盟 (CCF) の准教授であり、多くの重要な学術機関で重要な地位を占めています。
Cai Qing 教授の主な研究方向は、深層学習、コンピュータ ビジョン、医療画像処理などです。医用画像処理の下位分野としてのマルチモーダル医用画像融合には専門知識の壁があり、Cai Qing の長年の経験がこのトピックに関する指導と支援を提供します。
注目すべきは、蔡青准教授が昨年AAAI 2024の論文の筆頭著者に選ばれた後、今年も再び共同筆頭著者および責任著者を務め、合計3本の研究論文が掲載されたことである。 AAAI 2025で再び。これには、「SGTC: まばらに注釈を付けた半教師あり医用画像セグメンテーションのためのセマンティックガイド付きトリプレット共同トレーニング」というタイトルの医用画像処理に関する別の研究が含まれています。この論文では、研究者らは、セマンティックガイド付きトリプル共同トレーニングフレームワークが達成できる新しいフレームワークを提案しました。少数のボリュームサンプルの 3 つの直交スライスにラベルを付けるだけで信頼性の高い医用画像セグメンテーションを実現し、時間と労力のかかる画像ラベル付けプロセスの問題を解決します。
用紙のアドレス:
https://arxiv.org/abs/2412.15526
このプロジェクトに参加するもう 1 つのチームは、昆明科技大学情報工学自動化学部の Li Huafeng 教授と Zhang Yafei 教授のチームです。その中で、李華峰教授は、2021 年の世界トップ 2% 科学者の最新リストに選ばれました。彼は主にコンピューター ビジョン、画像処理などの研究に従事しています。この記事のもう一人の責任著者、Zhang Yafei 准教授は、主に画像処理とパターン認識に従事しており、中国国立自然科学財団の地域プロジェクトや雲南省自然科学財団の一般プロジェクトを主宰してきました。回。
このテーマにおける重要な学術的責任の 1 つである Li Huafeng 教授は、医療画像処理に関する研究を何度も発表しています。たとえば、2017 年には「スパース表現に基づく医療画像融合」というタイトルの研究を発表しました。 「赤外可視画像融合のための特徴量の動的位置合わせと改良:トランスレーションロバストフュージョン」などの研究。
用紙のアドレス:
https://liip.kust.edu.cn/servletphoto?path=lw/00000311.pdf
用紙のアドレス:
https://www.sciencedirect.com/science/article/abs/pii/S1566253523000519
さらに、Li Huafeng教授はZhang Yafei教授と何度も提携して、2022年に共同出版された「医用画像融合のためのマルチスケール特徴学習とエッジ強化」というタイトルの研究など、関連研究を共同出版している。この研究では、チームは、医用画像融合における異なる臓器間の境界がぼやける問題を軽減できる、マルチスケール特徴学習とエッジ強調に基づく医用画像融合モデルを提案しました。提案された方法によって得られた結果は、主観的かつ主観的なものです。視覚的または客観的な定量的評価、どちらも比較方法よりも優れています。
用紙のアドレス:
https://researching.cn/ArticlePdf/m00002/2022/59/6/0617029.pdf
格言にあるように、強力な力の組み合わせは完璧であり、医療画像処理分野における李華峰教授、張雅飛教授、蔡青准教授のチームの専門的学力がこのプロジェクトの成功の鍵であることは間違いありません。私たちは、今後も両当事者の協力を継続し、科学のための AI の分野で最先端の成果を発表し続けることを期待しています。
ハイブリッド・マルチモーダル医用画像融合手法がトレンドになっている
マルチモーダル医療画像融合の役割がますます重要になるにつれ、その技術開発は融合とインテリジェンスの方向に進むことは間違いありません。
このトピックで述べたように、深層学習に基づく融合手法の研究では、CNN ベースの手法と Transformer 手法が相補的な利点を持っていることに研究者が気づき、DesTrans、DFENet、MRSC-Fusion などの結果を提案しています。研究では、ハイブリッド アプローチを通じて 2 つのテクノロジーの利点を補完し、それによって融合法の効率を向上させています。
深層学習ベースの融合方法に加えて、マルチモーダル医用画像融合方法には、マルチスケール変換、スパース表現、部分空間ベース、顕著な特徴ベース、ハイブリッド モデルなどの従来の融合方法も含まれます。同様に、ディープラーニング + 従来の手法をベースとしたハイブリッド手法も登場しています。
上記の研究傾向に基づいて、次のことがわかります。将来的には、マルチモーダル医用画像融合手法は、ディープラーニングを主流とし、同時に複数の技術の支援を組み合わせた開発傾向を示すことは避けられません。









