Command Palette
Search for a command to run...
405B に匹敵するパフォーマンスを備えた唯一のオープンソース 70B モデルである Llama 3.3 をオンラインで実行してください。 LaTeX OCR データセットはオンラインであり、数式の識別に役立ちます

ちょうど今月、Meta は Llama 3.3 の唯一のオープンソース モデルである Llama-3.3-70B-Instruct をリリースしました。パラメータ サイズはわずか 70B ですが、405B モデルのパフォーマンスに匹敵します。これは Llama 3 シリーズの最後のモデルです、Xiao Zha は言いました、さよなら Llama 4!
Hyper.ai 公式 Web サイトのチュートリアル セクションで「Llama-3.3-70B-Instruct のワンクリック展開」を開始しました。Llama 3 の最終作業を一緒に体験しましょう。
オンラインでの使用:https://go.hyper.ai/TthEw
12 月 23 日から 12 月 29 日までの hyper.ai 公式 Web サイトの更新の概要:
* 高品質の公開データセット: 10
* 高品質なチュートリアルのセレクション: 3
* コミュニティ記事の選択: 6 記事
* 人気のある百科事典のエントリ: 5
※1月提出締切:9日
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
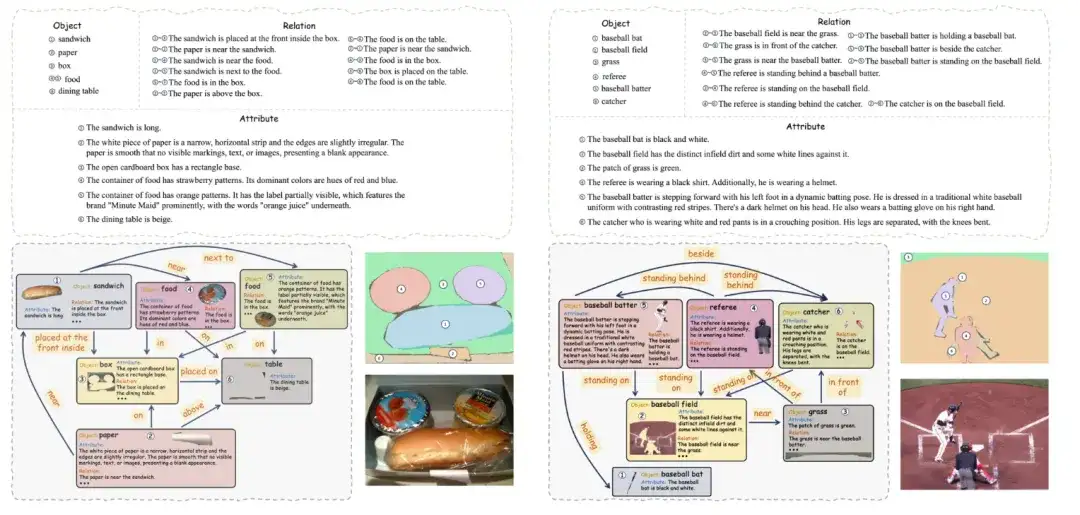
データセットには 560 の画像が含まれており、それぞれの画像にはオブジェクト、属性、関係性の細かいセマンティック セグメンテーションと注釈が付けられており、完全な有向シーン グラフ構造を形成しています。
直接使用します:https://go.hyper.ai/icfaH
2. HelmetViolations ヘルメット認識データセット
データ セットには、YOLOv9 形式で注釈が付けられた合計 1,004 枚の画像が含まれており、ナンバー プレート (Plate)、ヘルメット着用 (WithHelmet)、ヘルメット未着用 (WithoutHelmet) の 3 つのカテゴリが含まれています。トレーニング セットには 363 個の画像 (オリジナル + 拡張) があり、検証セットには 53 個の画像があり、モデル評価用のエクスポートに含まれます。
直接使用します:https://go.hyper.ai/N0Yyg

3. SynCamVideo-Dataset マルチカメラ同期ビデオデータセット
データセットには 1,000 の異なるシーンが含まれており、それぞれが 36 台のカメラで撮影され、合計 36,000 のビデオが作成され、50 の異なる動物を「主要被写体」として使用し、ポリ ヘブンの 20 の異なる場所を背景として利用しています。
直接使用します:https://go.hyper.ai/oIJns

このデータ セットは 3,371 枚の航空機画像を含むデータ セットであり、これらの画像は 10 のカテゴリ フォルダーに分割されており、各カテゴリは特定の航空機モデル (A10、A400M、AG600、AH64、AV8B、An124、An22、An225、An72、B1 など) に対応しています。 。
直接使用します:https://go.hyper.ai/IL3uP

MangaZero データセットは、コミック生成タスク用に特別に設計された大規模なマルチキャラクター、マルチステートのコミック画像データセットで、具体的には 43,264 ページのコミックと 427,147 の注釈付きパネルが含まれており、さまざまなキャラクターの相互作用や連続フレームでの相互作用の視覚化をサポートしています。アクションは、複数のキャラクターおよび複数の状態のコミック生成タスクに適しています。
直接使用します:https://go.hyper.ai/IpkjL
LaTeX OCR データセットは、光学式文字認識 (OCR) の分野における複雑な数式認識問題に焦点を当てたデータセットです。 LaTeX OCR データセットには複数の構成が含まれており、それぞれに異なる特性とデータ分割が含まれています。
直接使用します:https://go.hyper.ai/lyK1J
7. FSQ OS Places オープンソースの場所データセット
このデータセットには、200 以上の国と地域をカバーする 1 億以上の世界各地の名所 (POI) が含まれており、研究者、開発者、企業が豊富な地理空間データにアクセスできるようになります。 地名、住所、経度、緯度などの主要な情報を含む 22 のコア属性が提供され、地理空間分析や測位サービスなどのさまざまなアプリケーションがサポートされます。
直接使用します:https://go.hyper.ai/7oN5M
8. ProcessBench の数的推論ベンチマーク データ セット
このデータ セットには、競技会やオリンピックの難易度の高い数学の問題に焦点を当てた 3.4k のテスト インスタンスが含まれています。各例には段階的な解決策が付属しており、ドメインの専門家が何が問題になったのかを正確に指摘します。
直接使用します:https://go.hyper.ai/fk3hq
この中国医療データセットは、医療分野で専門的な対話とアドバイスを提供できる言語モデルを開発およびトレーニングするための包括的なリソースです。百科事典的な知識、教科書のテキスト、実際の医師と患者の会話、評価データなど複数のデータを組み合わせて、モデルの精度と実用性の向上を目指しています。
直接使用します:https://go.hyper.ai/wkAXX
10. splsoNet 異方性補正および位置ずれ補正チュートリアル データ セット
spIsoNet は、優先配向の問題によって引き起こされるマップの異方性と粒子の位置ずれの問題を解決する、エンドツーエンドの自己教師あり深層学習ソフトウェアです。このデータセットは研究に使用されており、関連する結果は国際学術誌 Nature Methods に掲載されています。
直接使用します:https://go.hyper.ai/tFOqJ
選択された公開チュートリアル
1. Llama-3.3-70B-Instruct のワンクリック展開
Llama-3.3-70B-Instruct は、2024 年に Meta によって発表された大規模な言語モデルです。現在、Llama 3.3 シリーズの唯一のオープンソース モデルであり、命令の微調整バージョンは特別に最適化されています。
モデルはその環境と依存関係を構成しました。API アドレスを入力してモデルとの会話を開始できます。
オンラインで実行:https://go.hyper.ai/TthEw
2. HunyuanVideo Tencent Hunyuan Wensheng ビデオ デモ
HunyuanVideo は、ユーザーが人工知能テクノロジーを通じて高品質のビデオ コンテンツを生成できるようにすることを目的としています。 HunyuanVideo は現在、オープンソース モデルの中で最も多くのパラメータを備えた Vincent ビデオ モデルであり、130 億のパラメータを持ち、高い物理的精度とシーンの一貫性を備えたビデオ コンテンツを生成し、ユーザーに超現実的な視覚体験を提供し、現実のものを組み合わせることができます。と仮想スタイル間の自由な変換。
このプロジェクトは便利な Web インターフェイスを提供しており、ユーザーは簡単なテキスト説明を入力するか条件を指定するだけで、さまざまなスタイルのビデオを生成できます。
オンラインで実行:https://go.hyper.ai/hEkOw
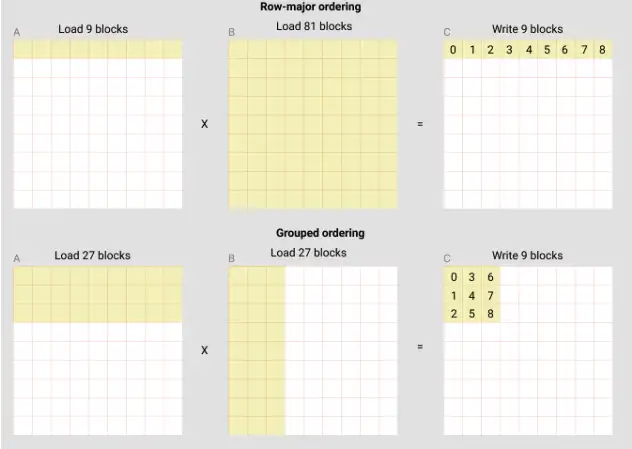
このチュートリアルでは、cuBLAS または rocBLAS に匹敵するパフォーマンスを持つ、非常に短く高性能の FP16 行列乗算カーネルを作成します。具体的には、レベル行列の乗算、多次元ポインター演算、L2 キャッシュ ヒット率を向上させるためのプログラムの並べ替え、および自動パフォーマンス チューニングを学習します。
オンラインで実行:https://go.hyper.ai/riM7b
注目のコミュニティ記事
1. AI が材料化学を破壊する、2024 年に最も注目すべき科学研究結果を要約
HyperAI は、2023 年から 2024 年に解釈された 26 の最先端の論文を厳選して分類しました。この記事は、材料化学分野における AI の研究に焦点を当てたものです。クリックするとすぐに読むことができます。
レポート全体を表示します。https://go.hyper.ai/XnzcN
2. 化学の世界でチューリングマシンを作ることを決意! AI製薬会社Chemifyが世界初の化学コンパイラーを開発、米国市場に参入
Chemify は英国のハイテク化学会社として、世界初の「化学チューリング マシン」と世界初の化学コンパイラーを開発し、化学コンピューティング、人工知能、ロボット工学、オートメーションなどを医薬品の研究開発と促進に統合することに取り組んでいます。化学のデジタル開発。この記事は会社に関する詳細なレポートです。クリックしてすぐに読んでください。
レポート全体を表示します。https://go.hyper.ai/V5VWB
3. 超大規模病理画像解析に!華中科技大学がシェーグレン症候群の診断精度を向上させる医療画像セグメンテーションモデルを提案
華中科技大学の Tu Wei 教授と Lu Feng 教授は、この方法によりシェーグレン症候群患者の病理学的画像内のリンパ球凝集巣を正確に特定でき、医師がより迅速かつ正確な診断を行えるようにすることを提案しました。この記事は、論文の詳細な解釈と共有です。
レポート全体を表示します。https://go.hyper.ai/EetpB
4. 未来の身体化知性の触覚革命! TactEdgeセンサーによりロボットの微細な触覚認識が可能となり、生地の欠陥検出や機敏な動作制御が可能になります
中国地質大学(北京)のZhang Shixin氏のチームは、2014年から視覚センサーと触覚センサーの研究を行っており、複数世代のセンサー技術を探索、開発しており、それを最先端の触覚技術であるTactEdgeと呼んでいる。この記事は関連する研究結果を詳しく紹介しています。クリックしてすぐに読んでください。
レポート全体を表示します。https://go.hyper.ai/nOE2a
5. 2024 年の医療 AI のブレークスルーの目録。見逃せない 35 件の最先端の論文が含まれています
この記事は、医療および健康分野における AI の研究に焦点を当てており、2023 年から 2024 年に解釈された 35 の最先端の論文を選択しています。共有するのに非常に役立ちます。クリックしてすぐに読んでください。
レポート全体を表示します。https://go.hyper.ai/CZdYT
6. LeCun によって転送され、UC Berkeley らは、配列と全原子タンパク質構造を同時に生成するマルチモーダルタンパク質生成法 PLAID を提案しました。
カリフォルニア大学バークレー校やMicrosoft Researchなどは、より豊富なデータモダリティからより希少なモダリティを生成し、マルチモーダル生成を実現できるマルチモーダルタンパク質生成法PLAIDを提案している。この記事は、論文の詳細な解釈と共有です。
レポート全体を表示します。https://go.hyper.ai/nwnDy
人気のある百科事典の項目を厳選
1. シグモイド関数
2. 相互ソーティング融合 RRF
3. 核の規範
4. 大規模言語モデル大規模言語モデル
5. 長期短期記憶長期短期記憶
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。

主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!








