Command Palette
Search for a command to run...
NeurIPS 2024 の提出経験を共有してください!浙江大学チームはタンパク質の最適化を支援するために DePLM モデルを使用し、最初の論文のデモがオンラインで表示されます

米国国立工学アカデミーの外国人学者、沈祥陽氏はかつてこう強調した、「今日私たちがしなければならないことがあるとすれば、それは科学のための AI です。今日、AI よりも重要なものを想像するのは困難です。この法律の公布は、AI によるものです。」今年のノーベル賞が最良の証拠だ。」
これまで科学者は手動でデータを整理し、主題の理論に基づいて仮説を立てることに依存していましたが、現在では AI の支援を受け、大量のデータに基づいて直接研究を実施できるようになり、科学研究の効率が向上するだけでなく、科学研究のパラダイム全体も変わります。特にタンパク質研究の分野では明らかです。
5 回目の Meet AI4S ライブ ブロードキャストで、HyperAI は幸運にも浙江大学知識エンジン研究所の博士課程候補者、王澤源氏を招待しました。彼は、「タンパク質最適化における大規模モデルを支援するための拡散ノイズ除去プロセスの使用」というタイトルで、NeurIPS 2024 のためにチームによって選ばれた論文を詳しく紹介しました。 「DePLM: プロパティ最適化のためのタンパク質言語モデルのノイズ除去」。
AI 分野のトップカンファレンスである NeurIPS は、最も難しく、最高レベルで、最も影響力のある AI 学術カンファレンスの 1 つとして知られており、今年のカンファレンスには合計 15,671 件の有効な論文投稿があり、昨年より 27% 増加しました。しかし、最終的な採択率はわずか 25.8% でした。選ばれた論文はどれも学習価値が非常に高いものです。この共有の中で、Wang Zeyuan 博士は、ノイズ除去タンパク質言語モデル DePLM の設計コンセプト、実験結果、デモ操作方法、および将来の展望を詳細に紹介し、さらに、トップカンファレンスに論文を提出した経験も共有しました。みんなの役に立つように。
具体的には、原稿を投稿するときは、テーマの選択、革新性、論文執筆、学際的なレビューへの対応などの側面から始めることができると王博士は述べました。
まず、テーマ選びですが、コミュニティが現在懸念しているより有意義な研究の方向性を理解するために、主要な会議の記事を幅広く読むことができます。たとえば、DePLM の論文を準備しているときに、Wang 博士はタンパク質工学、特にタンパク質予測タスクが昨年の ICLR および NeurIPS カンファレンスで人気の方向であることを発見しました。
第二に、イノベーションの観点からは、サイエンスAIの分野では、まずサイエンス分野の知識を深く理解し、AI分野の内容と比較することが重要だと考えています。 AIがまだ探索していない空白領域を見つけるためです。
エッセイの書き方に関して言えば、彼は、記事を理解しやすくするために、論理的に明確かつ詳細に書く必要があり、また、自分の考えに陥らないように、家庭教師やクラスメートともっとコミュニケーションをとる必要があると述べました。
最後に、AI for Science の論文は 2 つの異なる背景を持つ査読者によって査読される可能性があることを考慮すると、一方の当事者は AI テクノロジーにより多くの注意を払い、もう一方の当事者は科学への応用に重点を置いています。したがって、論文を書く際には論文の核となる位置付けを明確にする必要があります。つまり、この論文が AI コミュニティ向けであるか科学コミュニティ向けであるかに応じて、内容がトピックと密接に結びついていることを保証する論理フレームワークを構築します。
彼の意見では、大規模モデル研究の現在の傾向は、単純な採用主義から大規模モデルの深い理解へと移行しました。以前は、大規模モデルをさまざまな下流タスクに適応させていましたが、現在は、下流タスクを大規模モデルの事前トレーニング段階とよりよく一致させる方法をより検討しています。2 つの間の適合度が高いほど、より良い結果が得られます。モデルのパフォーマンスが向上します。
たとえば、適応的なランドスケープを予測する場合、従来の単純な微調整手法では一般化機能がうまく機能しません。その場合、大規模なモデルと教師なし学習パラダイムをより深く理解し、それらの欠点を特定し、改善する必要があります。さらに、モデルのバイアスを排除してモデルのパフォーマンスを最適化する方法を模索するなど、大規模モデル自体の欠点にも注意を払う必要があります。
モデルはオープンソースでテスト可能です
今日は、NeurIPS 2024 で発表した論文を共有したいと思います。この論文では、拡散ノイズ除去モデルを使用して大規模言語モデルのタンパク質の最適化を支援する方法を検討しています。この論文では、新しいノイズ除去タンパク質言語モデル (DePLM) を提案します。その核心は、タンパク質言語モデルによって捕捉された進化情報を、ターゲットの特性に関する関連情報と無関係な情報の混合物と見なすことであり、無関係な情報は「ノイズ」とみなされて除去されます。提案されたランキングベースのノイズ除去プロセスは、強力な一般化機能を維持しながら、タンパク質の最適化パフォーマンスを大幅に向上できることがわかりました。
現在、DePLM はモデルの構成環境が複雑なため、オープンソースです。HyperAI 公式 Web サイトのチュートリアル セクションに「DePLM: Optimizing Protein (Small Sample) using Denoising Language Model」を開始しました。私たちの作業をよりよく理解して再現できるように、DePLM モデルがどのように実行されるか、およびその関連構成ファイルとは何か、モデルの拡散ステップを微調整する方法、独自のデータを使用して DePLM モデルを実行する方法について説明します。モデルがどのように機能するかを説明しましょう。
DePLM オープンソース アドレス:
https://github.com/HICAI-ZJU/DePLM
DePLM チュートリアルのアドレス:
背景の紹介: 進化情報を最大限に活用し、データバイアス信号の導入を最小限に抑える
本研究の対象となるタンパク質は、20種類のアミノ酸が連なった生体高分子であり、体内で触媒作用や代謝、DNA複製などの機能を担っており、生命活動の主体でもあります。生物学者は通常、その構造を 4 つのレベルに分けます。第 1 レベルではタンパク質がどのように構成されているかが説明され、第 2 レベルでは一般的な α ヘリックスや β シートなどのタンパク質の局所構造が説明され、第 4 レベルではタンパク質間の相互作用が考慮されます。タンパク質。
現在、AI+ タンパク質の研究のほとんどは、自然言語処理の研究に遡ることができます。これは、たとえば、タンパク質の四次構造を文字、単語、文章などと比較できるためです。自然言語では段落は相対的なものです。文中に文字ミスが発生すると、その文の意味が失われます。同様に、タンパク質のアミノ酸に変異が発生すると、タンパク質が安定した構造を形成できなくなり、その機能が失われることがあります。
以下の図に示すように、「言語モデルを使用した制御可能なタンパク質設計」という論文で、研究者は自然言語をタンパク質にマッピングしました。この方法は 2020 年以来、タンパク質研究が爆発的な成長を示しています。
原紙:
https://www.nature.com/articles/s42256-022-00499-z
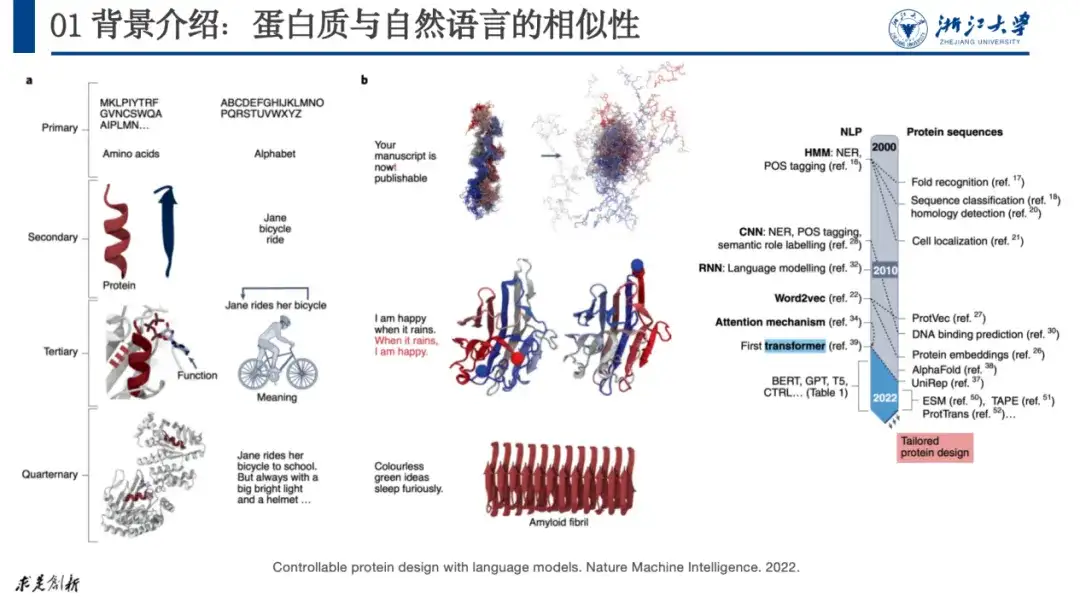
今回議論するのは、AI+タンパク質の最適化、つまり、期待どおりに機能しないタンパク質があった場合に、そのアミノ酸配列をどのように調整して期待通りの機能を実現するかという問題です。
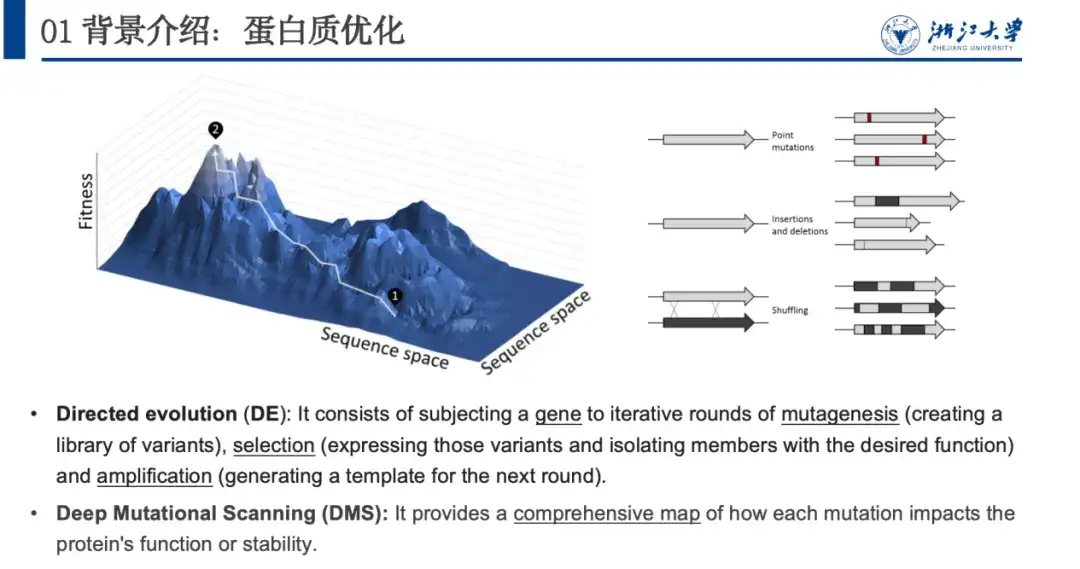
自然界では、タンパク質はランダムな変化 (点の挿入、欠失、点突然変異など) を通じて常に最適化されます。生物学者は、このプロセスを模倣することにより、タンパク質を最適化するための指向性進化と深い突然変異スキャンを提案しました。これら 2 つの方法の問題は、実験リソースを大量に消費することです。したがって、私たちは計算手法を使用して、タンパク質とその特性の適合性の関係をモデル化します。つまり、タンパク質の最適化に重要な適合性の状況を予測します。
この問題をモデル化するには、通常、データセット、評価指標 (メトリクス)、および計算方法を使用します。以下の図に示すように、タンパク質最適化データセットには通常、野生型配列 xwt、複数の変異ペア μi、および変異後の予測適応度 yi が含まれます。評価モデルは主にスピアマンの相関係数に依存しており、予測の特定の値ではなく、実際の突然変異 R(Y) が予測された適応度スコアでランク付けされます。値が近いほど、モデルはより適切にトレーニングされています。
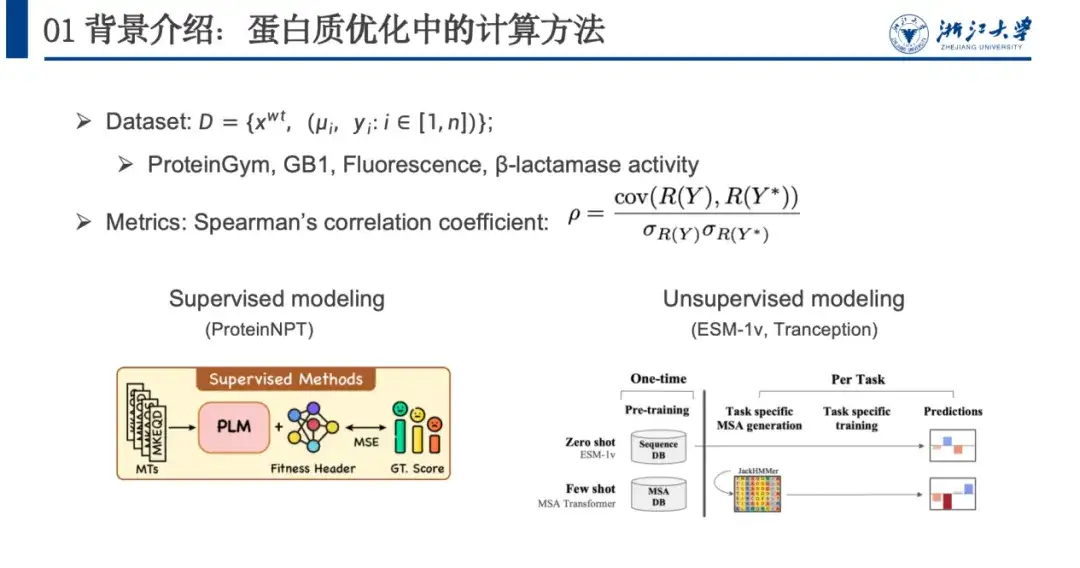
計算手法は教師あり学習(教師ありモデリング)と教師なし学習(教師なしモデリング)に大別されます。教師あり学習では、ラベル付きデータに依存して損失関数を最適化することでモデルをトレーニングし、適応度の予測能力を向上させます。教師なし学習にはラベル データは必要ありませんが、適応度に依存しない大規模なタンパク質データ セットに対して自己教師あり学習を実行します。モデルは 1 回トレーニングするだけで済み、さまざまなタンパク質予測タスクに一般化できます。
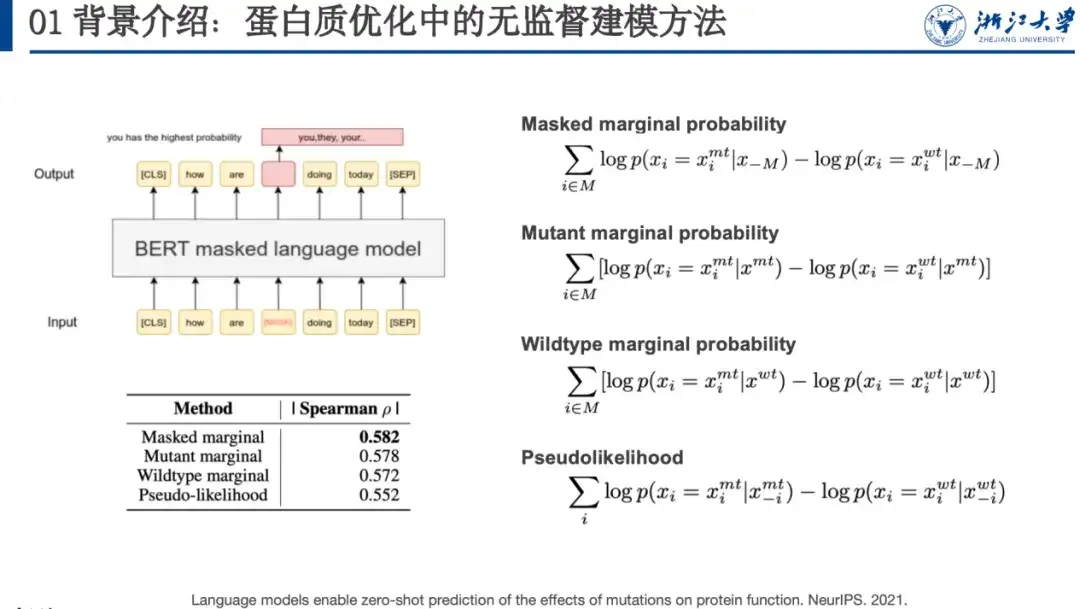
たとえば、マスクされた言語モデリングは教師なし学習方法であり、モデルをトレーニングするときに、特定の単語 (下の赤いボックス内の単語) をマスクするか、ランダム化する必要があります。別の単語を入力し、言語モデルにそれを復元させます。つまり、元のシーケンスを復元します。 NeurIPS 2021 の論文で、研究者らは、このようなモデルによって予測されるタンパク質の変異の確率とフィットネスランドスケープの間に一定の相関関係があることを発見しました。このため、図の右側に示すように、4 つの変異スコア計算式を設計しました。以下は側面に表示されています。
原紙:
https://proceedings.neurips.cc/paper/2021/file/f51338d736f95dd42427296047067694-Paper.pdf
要約すると、教師ありメソッドはパフォーマンスは良好ですが、汎化能力が限られており、教師なしメソッドはパフォーマンスがわずかに劣りますが、汎化能力は強力です。両方の利点を組み合わせるために、以下の図に示すように、NLP の分野での事前トレーニング + 微調整戦略から教訓を引き出します。いくつかの試みを行った結果、この方法はパフォーマンスは良好であることがわかりました。一般化能力が低く、教師あり学習に似ています。そこで私たちは、なぜ教師なし手法が優れた汎化能力をもつのかを分析し、この汎化能力は進化情報 (EI) に由来するものであり、生物は自然進化を通じてタンパク質を最適化することができ、その進化した変異も保持しているためであると仮説を立てました。したがって、突然変異確率と適応度ランドスケープの間には正の相関があると考えられます。

しかし、モデルを微調整しようとすると、実際には埋め込み情報が使用され、進化情報が十分に活用されていません。また、ウェット実験データには無関係な情報の偏りが存在します。進化情報には、安定性、活性、発現、結合など、さまざまな方向の総合的な情報が含まれていると考えています。タンパク質の安定性を最適化する場合、活性、発現、結合の進化は、これを取り除くことができれば、重要な情報ではなくなります。興味のない情報の確率値はモデルのパフォーマンスを向上させることができ、プロセス全体が尤度空間で実行されるため、モデルの汎化能力には影響しません。したがって、データセットに導入されるバイアス信号を最小限に抑えながら、微調整プロセス中に進化情報を最大限に活用する必要があります。
DePLM アルゴリズム フレームワーク: ソート スペースに基づくノイズ除去モデル
これに基づいて、我々は DePLM モデルを提案しました。その中心的なアイデアは、タンパク質言語モデルによって捕捉された進化情報を興味深い信号と興味のない信号の融合と見なすことであり、後者はターゲット属性の最適化タスクでは「ノイズ」と見なされます。排除する必要がある。 DePLM は、属性値のランキング空間で拡散プロセスを実行することで進化情報をノイズ除去し、それによってモデルの汎化能力を強化し、突然変異の影響を予測します。
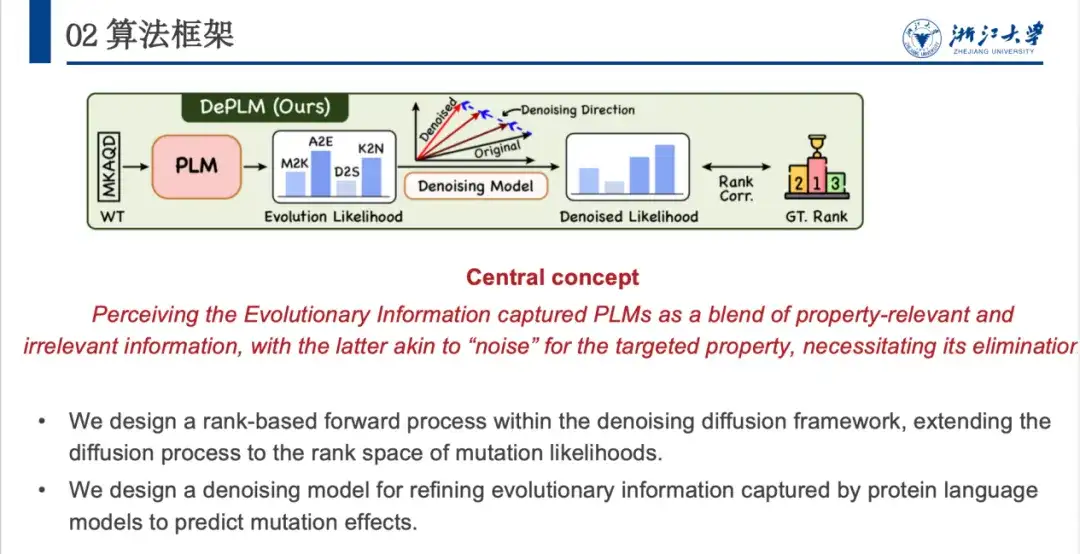
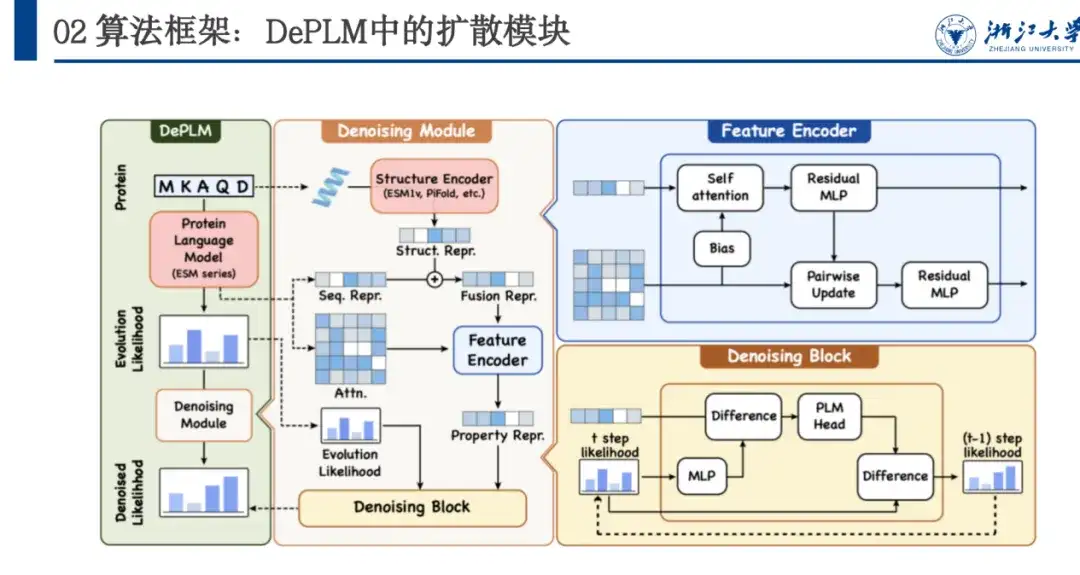
タンパク質のアミノ酸配列が与えられると、モデルは各位置でのさまざまなアミノ酸への突然変異の確率を予測し、進化的尤度を使用して、デノシング モジュールを通じて目的の特性の尤度を生成します。具体的には、DePLM は主に、前方拡散プロセスと逆ノイズ除去学習プロセスの 2 つの部分で構成されます。順方向のプロセスでは、実際の状況に少量のノイズが徐々に追加されます。逆方向のノイズ除去プロセスでは、蓄積されたノイズが徐々に除去され、実際の状況が復元されます。
以下の図に示すように、DePLM は ESM シリーズをベースにしており、Transformer アーキテクチャを採用しています。その Denosing Module モジュールは拡散プロセス トレーニングに基づいており、ネットワーク アーキテクチャには、Feature Encoder と Denosing Block が含まれています。このうち、Feature Encoder はタンパク質言語モデル (Protein Language Model) から配列特徴を抽出し、ESM 1v モデルを通じて構造特徴を抽出します。 、これら 2 つの特徴を組み合わせて、アンカー ポイントとして、ノイズ除去ブロックの複数回の反復を通じて徐々にノイズを除去することによって、ノイズ除去された尤度が取得されます。
これまで、ノイズ除去手法は主に画像生成の分野、特に拡散モデルで使用されていました。下図に示すように、元の画像 x0 は、主に定義されたノイズ処理を通じてガウス分布に近いノイズ空間 (xT) に変換され、モデルは逆ノイズ除去処理を学習します。
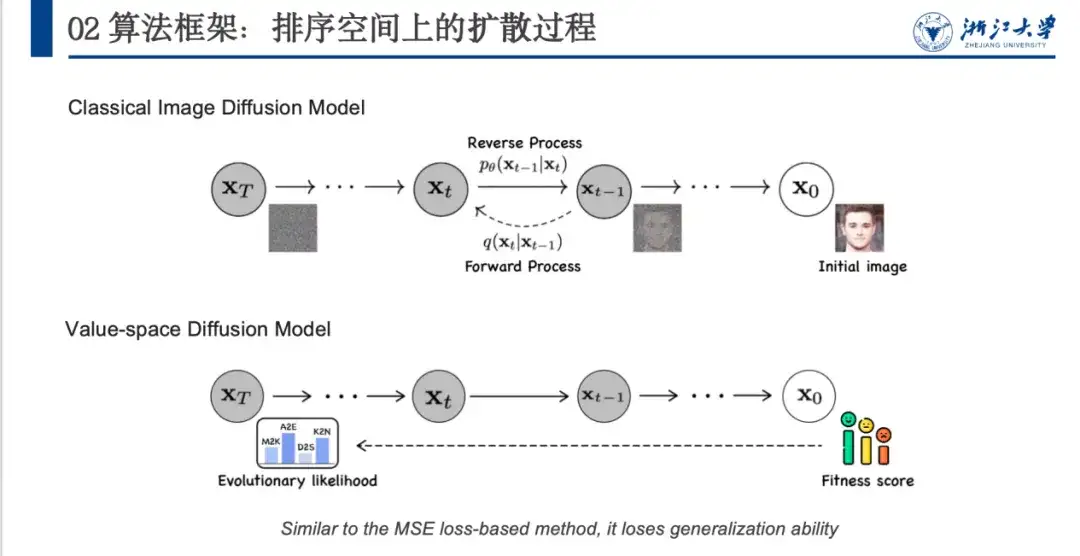
ただし、画像ノイズ除去モデルをタンパク質分野に直接適用するにはいくつかの問題があります。上の図に示すように、画像ノイズ除去モデルはランダム ノイズを追加して分離できないノイズ空間 (x0 から xT まで) を形成できますが、タンパク質にはフィットネス スコアと進化尤度 (進化尤度)、および初期状態と最終状態が存在します。したがって、ノイズを追加するプロセスは慎重に設計する必要があります。次に、モデルは適合度スコアに合わせて調整されるため、パフォーマンスは向上しますが、一般化能力は低くなります。
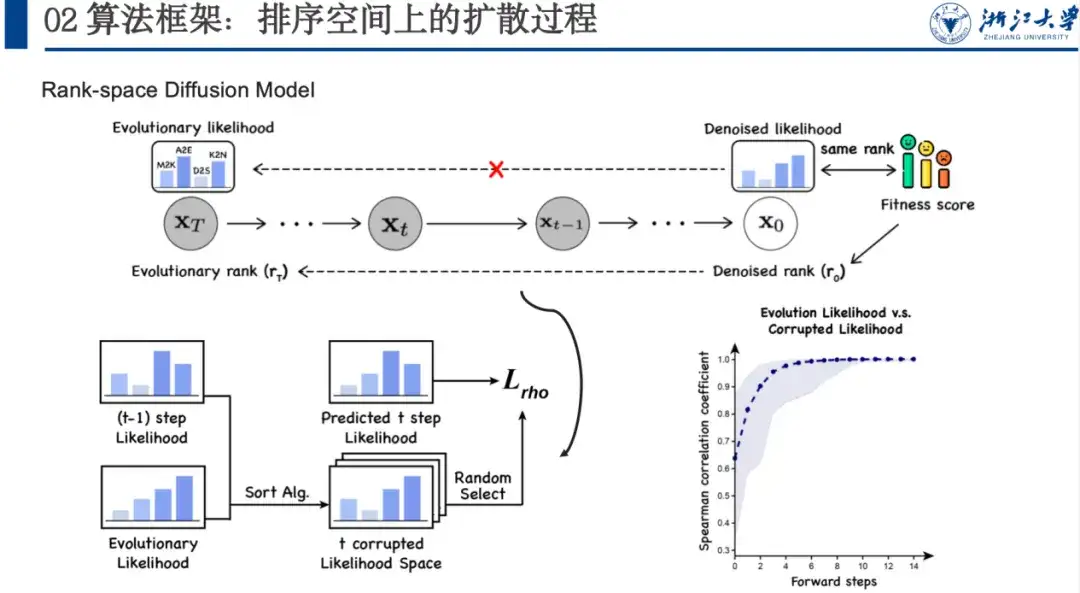
したがって、ランキング相関を最大化することに焦点を当て、ランキング空間に基づいたノイズ除去モデルを提案します。これは、対象のプロパティ空間に対して進化尤度のノイズを除去したいためです。この空間の具体的な状況はわかりませんが、そのソートが適応度ソートと一致していることはわかっています。
この空間にノイズを追加し、モデルに多数のデータセットを学習させ、適合性スコアを直接調整するのではなく、デノシド尤度がどのようになるべきかを徐々に学習します。この順方向ノイズ追加プロセスでは、ソートの各ステップを最終状態に近づけるためにソート アルゴリズムを使用し、モデルは逆の段階的ソートのアイデアも学習します。具体的には、以下の図に示すように、xt-1 がある場合、ステップ t のソート空間を取得した後、ソート アルゴリズム xt-1 および xT を複数回ソートすることができ、そのソート空間をランダムにサンプリングできます。ステップ t のランキング変数により、モデルはステップ t+1 からステップ t までの尤度を予測し、スピアマン損失を計算できます。画像のノイズ除去など多くの手順を追加する必要がないため、通常、並べ替えプロセスは 5 ~ 6 つの手順で完了でき、効率も向上します。
実験の結論: DePLM は優れたパフォーマンスと強力な汎化能力を備えています
タンパク質工学タスクにおける DePLM のパフォーマンスを評価するために、比較のためにゼロからトレーニングされたタンパク質配列エンコーダーや自己教師モデルなどと比較しました。結果を以下の図に示します。比較すると、DePLM はベースライン モデルよりも優れたパフォーマンスを示します。私たちは、高品質の進化情報が微調整された結果を大幅に改善できることを発見しました。これは、私たちが提案したノイズ除去トレーニングプロセスの有効性を示しており、タンパク質工学タスクにおいて進化情報と実験データを統合することの利点も裏付けています。
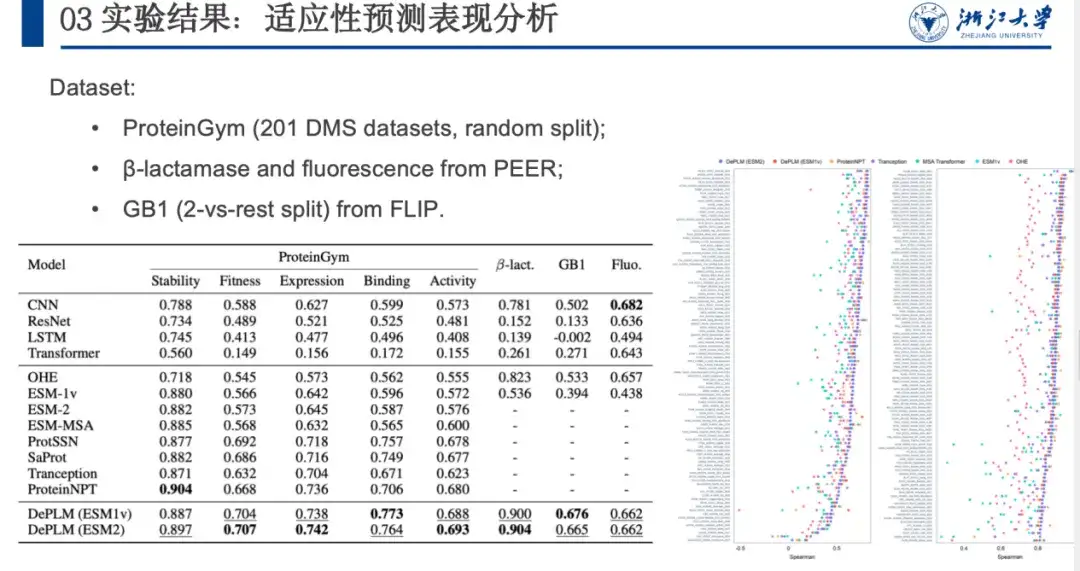
次に、DePLM の汎化能力をさらに評価するために、ProteinGym は、測定したタンパク質の特性 (安定性、適合性、発現、結合、活性) に基づいて DMS データセットを 5 つのカテゴリに分類しました。これを他の自己教師ありモデル、構造ベースのモデル、教師ありベースライン モデルと比較します。結果は下の図に示されており、DePLM はすべてのベースライン モデルを上回っています。これは、フィルタリングされていない進化情報のみに依存するモデルの欠点を示しています。DePLM は、複数のターゲットを同時に最適化するため、ターゲットの特性を弱めることがよくあります。無関係な要因の影響を排除することで、パフォーマンスが大幅に向上します。
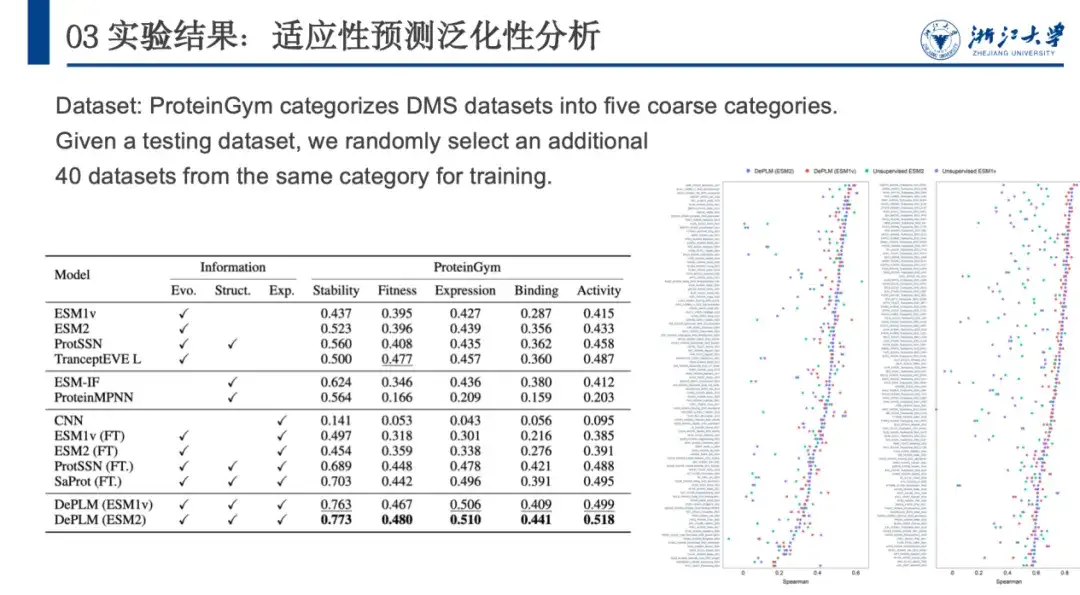
一般化パフォーマンスをさらに分析し、属性に無関係な情報を除外する重要性を判断するために、ほとんどの場合、モデルがプロパティでトレーニングされるときに、プロパティ間のトレーニングとテストの間で相互検証を実行しました。 A およびプロパティ B でテストすると、同じプロパティ (つまり A) でのトレーニングとテストに比べてパフォーマンスが低下します。これは、さまざまなプロパティの最適化方向が一貫しておらず、相互に干渉していることを示しており、最初の仮説が裏付けられています。
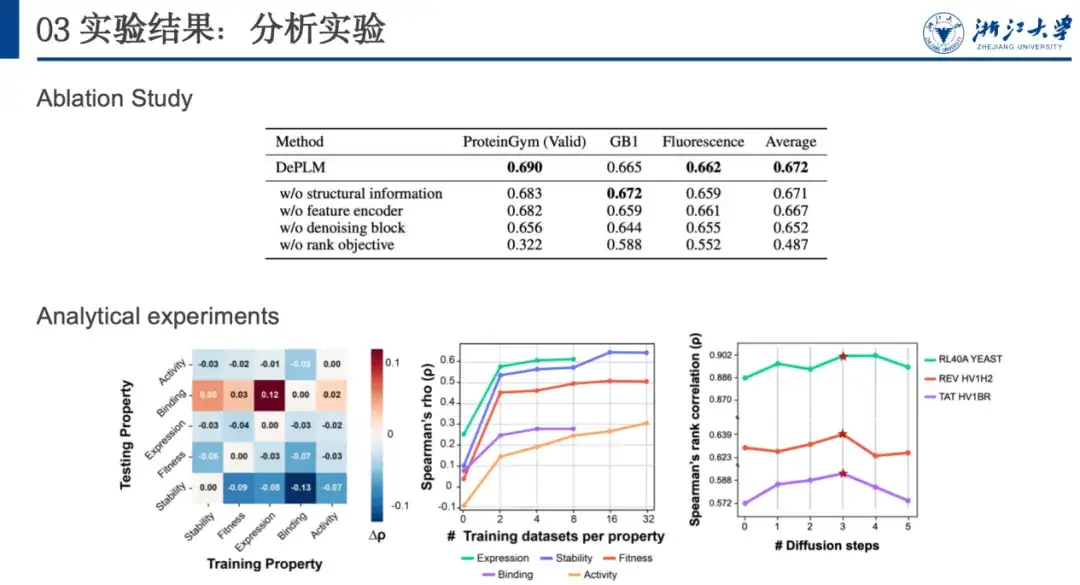
さらに、他のプロパティ データ セットでのトレーニングとバインディング データ セットでのテストによってモデルのパフォーマンスが向上することがわかりました。これは、バインディング データ セットのデータ量が限られていてデータ品質が低く、その結果、バインディング データ セット自体の汎化能力が不十分であることが原因である可能性があります。これは私たちにインスピレーションを与え、新しい特性を持つタンパク質を最適化するときに、その特性に関連するデータ セットがほとんどない場合は、ノイズ除去とトレーニングに関連する特性を持つデータを使用して、より優れた一般化機能を取得することを検討できます。
プロテインの分野を深掘りし続ける
このライブブロードキャストのゲストは、浙江大学ナレッジエンジン研究室の博士候補者である王澤源氏です。彼のチームは、陳華軍教授、張強研究員らが率いる大規模なナレッジグラフの分野での学術研究に取り組んでいます。言語モデル、AI for Science などの分野で、NeurIPS、ICML、ICLR、AAAI、IJCAI などの主要な AI カンファレンスで多くの論文を発表しました。
張強の個人ホームページ:
https://person.zju.edu.cn/H124023
タンパク質の分野では、チームはタンパク質を最適化するための DePLM などの高度なモデルを提案しただけでなく、生物学的配列と人間の言語の間のギャップを埋めるためにも取り組みました。この目的のために、彼らは InstructProtein モデルを提案しました。知識命令を使用してタンパク質言語と人間の言語を調整し、タンパク質言語と人間の言語の間の双方向生成機能を調査し、生物学的配列を大規模な言語モデルに統合し、2 つの言語間のギャップを効果的に橋渡しします。多数の双方向プロテインテキスト生成タスクに関する実験では、InstructProtein が既存の最先端の LLM よりも優れていることが示されています。
クリックして詳細を表示: ACL2024 メインカンファレンスに選ばれました InstructProtein: 知識命令を使用したタンパク質言語と人間の言語の調整 |
さらに、チームは「事前トレーニングとヒンティング」フレームワークに基づいた多目的タンパク質配列設計手法である PROPEND も提案しました。スケルトン、ブループリント、フィーチャ ラベル、およびそれらの組み合わせに関するヒントを使用して、複数のプロパティを直接制御できるため、アプローチに広範な実用性と正確性が与えられます。インビトロでテストされた 5 つの配列の中で、PROPEND の最大機能回復率は 105.2% に達し、古典的な設計パイプラインの 50.8% を大幅に上回りました。
原紙:
https://www.biorxiv.org/content/10.1101/2024.11.17.624051v1
現在、チームが発表した成果の多くはオープンソース化されており、長期にわたって優秀なポスドク、研究開発エンジニア、その他のフルタイム研究者を募集しています。
研究室のGithubホームページ:
http://github.com/zjunlp









