Command Palette
Search for a command to run...
最初の vLLM 中国語ドキュメントがオンラインになりました。最新バージョンのスループットは 2.7 倍に向上し、レイテンシーは 5 倍に短縮され、大規模な言語モデルの推論が高速化されました。

現在、大規模言語モデル (LLM) の開発は、スケール パラメーターの反復的なアップグレードから、アプリケーション シナリオの適応と革新へと拡大していますが、その過程で一連の問題も明らかになります。たとえば、推論リンクの効率が低く、複雑なタスクの処理に時間がかかるため、大規模なリソース使用率の観点から、高いリアルタイム性が要求されるシナリオのニーズを満たすことが困難になります。このモデルでは、コンピューティング リソースとストレージ リソースの消費が膨大になり、ある程度の無駄が生じます。
これを考慮して、カリフォルニア大学バークレー校 (UC Berkeley) の研究チームは、2023 年に vLLM (Virtual Large Language Model) をオープンソース化しました。これは、大規模言語モデルの推論を高速化するために特別に設計されたフレームワークであり、その優れた推論効率とリソース最適化機能により、世界中で広く注目を集めています。
国内開発者の皆様にvLLMのバージョンアップや最先端の開発内容をよりわかりやすく知っていただくために、HyperAI Super Neural は、最初の vLLM 中国語ドキュメントを公開しました。技術的な知識から実践的なチュートリアル、最先端のニュースからメジャーアップデートまで、初心者も経験豊富な専門家も、必要な役立つコンテンツを見つけることができます。
vLLM 中国語ドキュメント:
vLLM のトレース: オープンソースの歴史とテクノロジーの進化
vLLM のプロトタイプは、2022 年末に誕生しました。カリフォルニア大学バークレー校の研究チームが「alpa」と呼ばれる自動並列推論プロジェクトを展開したところ、その実行が非常に遅く、GPU 使用率が低いことがわかりました。研究者は、大規模な言語モデルの推論には最適化の余地が大きいことを痛感しています。しかし、市場には大規模言語モデル推論に特化して最適化されたオープンソース システムが存在しなかったため、彼らは大規模言語モデル推論フレームワークを自分たちで作成することにしました。
数え切れないほどの実験とデバッグを経て、彼らはオペレーティングシステムの仮想メモリとページング技術に注目し、これに基づいて2023年にアテンションキーとアテンション値を効果的に管理できる画期的なアテンションアルゴリズム PagedAttend を提案しました。これに基づいて、研究者らは高スループットの分散 LLM サービス エンジン vLLM を構築し、KV キャッシュ メモリの無駄をほぼゼロにしました。大規模言語モデル推論におけるメモリ管理のボトルネック問題を解決します。Hugging Face Transformers と比較して、スループットは 24 倍増加し、このパフォーマンスの向上にはモデル アーキテクチャを変更する必要はありません。
さらに言及する価値があるのは、vLLM はハードウェアや Nvidia GPU に限定されず、AMD GPU、Intel GPU、AWS Neuron、Google TPU などの市場の多くのハードウェア アーキテクチャにもオープンであり、vLLM のアプリケーションを真に促進していることです。さまざまなアプリケーションにおける大規模な言語モデル。ハードウェア環境での効率的な推論とアプリケーション。現在、vLLM は 40 を超えるモデル アーキテクチャをサポートでき、Anyscale、AMD、NVIDIA、Google Cloud を含む 20 社以上の企業からサポートとスポンサーを受けています。
2023 年 6 月に、vLLM のオープンソース コードが正式にリリースされました。わずか 1 年で、Github 上の vLLM スターの数は 21.8,000 を超えました。現時点で、このプロジェクトのスターの数は 31,000 に達しています。
同年 9 月、研究チームは、vLLM の技術的な詳細と利点をさらに詳しく説明する論文「Pagesdtention を使用した大規模言語モデルの効率的なメモリ管理」を発表しました。 vLLM に関するチームの研究は停止しておらず、互換性、使いやすさ、その他の側面を中心に反復的なアップグレードを現在も実行しています。たとえば、ハードウェア適応の観点からは、Nvidia GPU に加えてより多くのハードウェアで vLLM を実行するにはどうすればよいでしょうか? 別の例としては、科学研究の観点から、システム効率と推論速度をさらに向上させる方法などが挙げられます。そしてこれらはvLLMのバージョンアップにも反映されます。
用紙のアドレス:
https://dl.acm.org/doi/10.1145/3600006.3613165
vLLM v0.6.4 アップデート
スループットが 2.7 倍に向上し、レイテンシが 5 倍に短縮
つい先月、vLLM のバージョンが 0.6.4 に更新され、パフォーマンスの向上、モデルのサポート、マルチモーダル処理において重要な進歩が見られました。
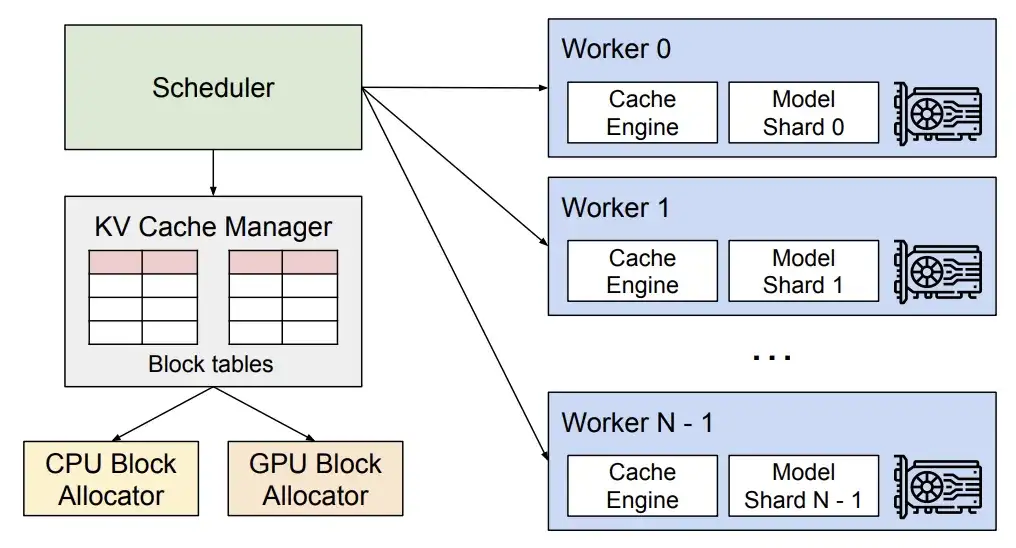
パフォーマンスの面では、新しいバージョンではマルチステップ スケジューリングと非同期出力処理が導入されています。GPU の使用率を最適化し、処理効率を向上させることで、全体的なスループットを向上させます。
vLLMテクニカル分析
* マルチステップ スケジューリングにより、vLLM は複数のステップのスケジューリングと入力準備を一度に完了できるため、GPU は各ステップで CPU 命令を待たずに複数のステップを連続的に処理できるようになり、CPU のワークロードが分散され、アイドル時間が短縮されます。 GPUの。
※非同期出力処理により、出力処理とモデルの実行を並行して実行できます。具体的には、vLLM は出力をすぐには処理しなくなり、処理を遅らせ、n+1 番目のステップの実行中に n 番目のステップの出力を処理します。これにより、リクエストごとにステップが 1 つ増える可能性がありますが、GPU 使用率の大幅な増加により、このコストを補って余りあるものになります。
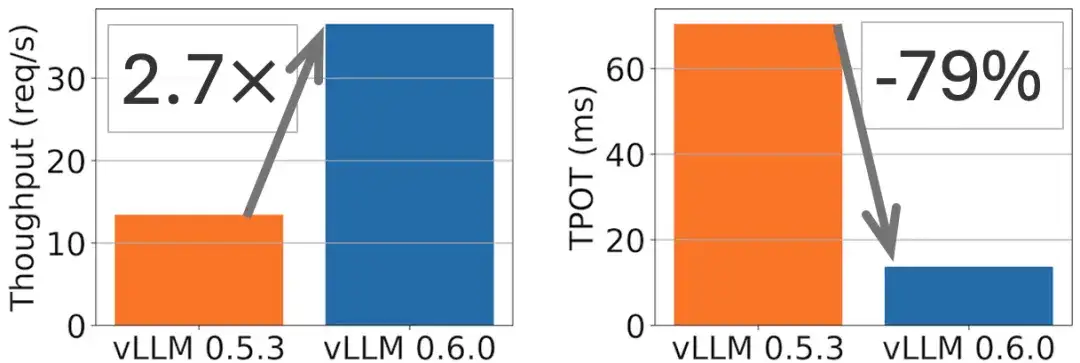
たとえば、次の図に示すように、Llama 8B モデルではスループットが 2.7 倍向上し、TPOT (出力タグあたりの時間) が 5 倍削減されます。
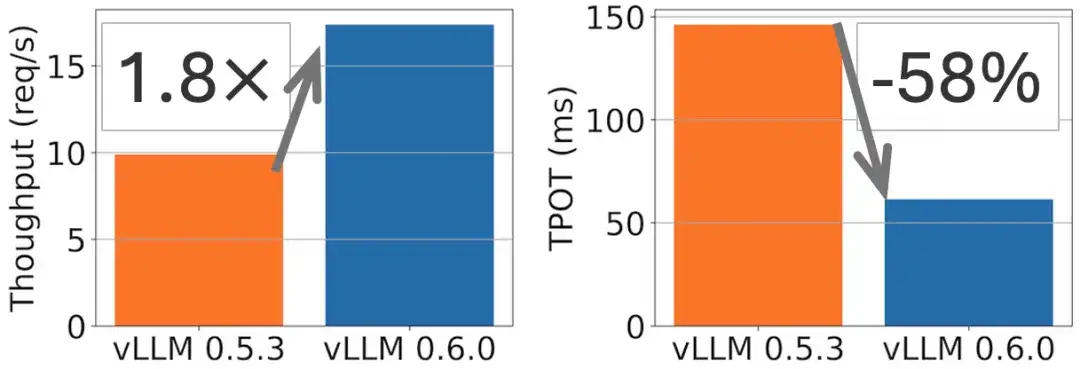
Llama 70B モデルでは、次の図に示すように、スループットが 1.8 倍向上し、TPOT が 2 倍削減されました。
モデルサポートの点では、vLLM には Exaone、Granite、Phi-3.5-MoE などの最先端の大規模言語モデルへの適応が新たに含まれています。マルチモーダル分野では、マルチ画像入力の機能が追加され(公式ドキュメントではPhi-3-visionモデルが例として使用されています)、Ultravoxの複数のオーディオブロックを処理する機能も追加され、さらに拡張されています。さまざまなマルチモーダル タスクにおける vLLM。
vLLM 中国語ドキュメントの最初の完全版がオンラインになりました
vLLM が大規模モデルの分野における重要な技術革新として、効率的な推論の現在の開発方向を表していることは疑いの余地がありません。国内の開発者がその背後にある高度な技術原理をより便利かつ正確に理解できるように、国内の大型モデルの開発にvLLMを導入し、この分野の発展を促進します。 HyperAI のコミュニティ ボランティアは、オープンな協力と翻訳と校正の二重レビューを通じて、最初の vLLM 中国語ドキュメントを完成させることに成功しました。hyper.ai で完全に起動されました。
vLLM 中国語ドキュメント:
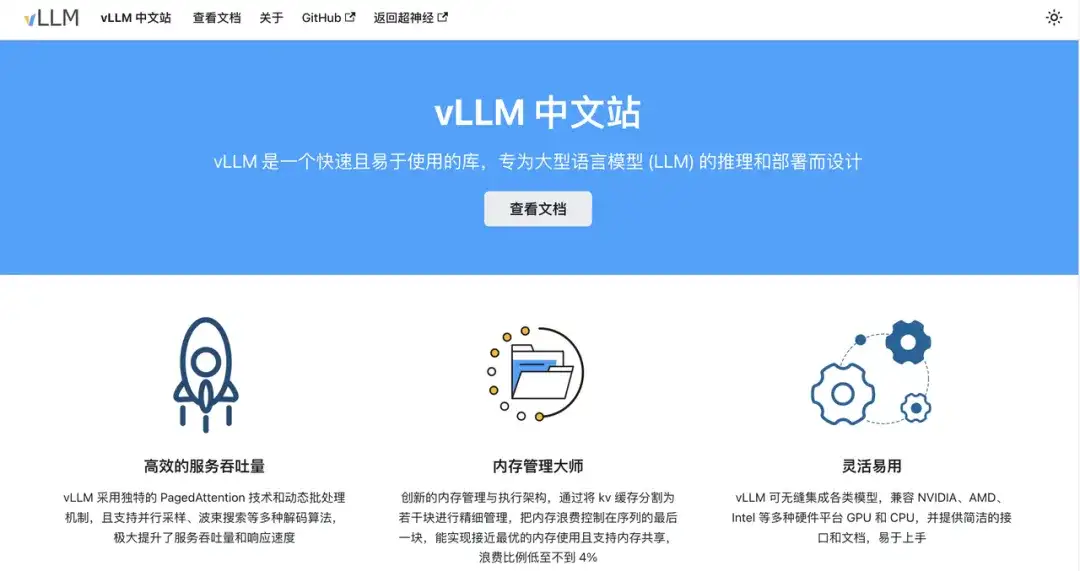
vLLM このドキュメントでは次の内容が提供されます。
※基本概念をゼロから普及
* ワンクリックで簡単に複製できるチュートリアル
* 適時に更新される vLLM ナレッジ ベース
* フレンドリーでオープンな中国人コミュニティの生態
オープンソースのブリッジを構築する:
TVM、Triton、vLLM のコミュニティ構築の旅
2022 年に、HyperAI は中国初の Apache TVM 中国語ドキュメントをリリースします (クリックして原文を表示: TVM 中国局が正式に開始されました!最も完成度の高い機械学習モデル導入の「参考書」はこちら)、国産チップが全盛の時期に、国内のコンパイラエンジニアにTVMを理解し学習するためのインフラを提供します。同時に、Apache TVM PMC の Feng Siyuan 博士らと協力して、中国で最も活発な TVM 中国語コミュニティを形成しました。オンラインおよびオフラインの活動を通じて、国内の主流チップメーカーの参加と支援を集めており、1,000 人以上のチップ開発者とコンパイラーエンジニアが参加しています。

TVM 中国語文書アドレス:
2024 年 10 月に、Triton 中国語 Web サイトを開設しました。 (クリックして原文を表示: 最初の完全な Triton 中国語文書がオンラインになりました! GPU 推論アクセラレーションの新時代を開く)、AI コンパイラー コミュニティの技術的境界とコンテンツの範囲をさらに拡大します。
Triton の中国語ドキュメントのアドレス:
AI コンパイラー コミュニティを構築する過程で、私たちは皆様の声に耳を傾け、業界の動向に注意を払い続けてきました。今回 vLLM の中国語ドキュメントを公開したのは、大規模モデルの急速な開発に伴い、vLLM に対するみんなの注目と需要が高まっていることを観察したためであり、開発者が学び、コミュニケーションし、協力し、共同で普及を促進するためのプラットフォームを提供したいと考えています。中国における最先端技術の開発。
TVM、Triton、vLLM の中国語ドキュメントの更新とメンテナンスは、中国語コミュニティを構築するための基本的な作業です。将来的には、よりオープンで多様性があり、包括的な AI オープンソース コミュニティを構築するために、より多くのパートナーが参加してくれることを楽しみにしています。
vLLM の完全な中国語ドキュメントを参照してください。
GitHub vLLM 中国語:
https://github.com/hyperai/vllm-cn
HyperAI は今月、上海で Meet AI Compiler オフライン技術交流会を開催します。QR コードをスキャンして「AI Compiler」とメモしてイベント グループに参加し、イベントに関する情報をいち早く入手してください。

参考文献:
1.https://blog.vllm.ai/2024/09/05/perf-update.html








