Command Palette
Search for a command to run...
SynthID の目に見えないウォーターマークへの早期アクセス! AI 生成コンテンツをより制御しやすくするため、600 万個の音声ファイルを含む大規模な音声字幕データ セットがリリースされました。

AI によって生成されたコンテンツがますます普及する時代において、コンテンツが手動で作成されたものであるか、AI によって生成されたものであるかをどのように迅速に見分けるかが話題になっています。これはニュースの信頼性や著作権保護だけでなく、ネットワーク セキュリティとも密接に関係しています。
最近、Google DeepMind は SynthID-Text テクノロジーを発表しました。これは、テキスト生成プロセスでトークン確率スコアを最適化することで、テキストの品質に影響を与えることなく、ロスレスにウォーターマークを埋め込むことができ、非常に高い検出効率を実現します。従来のテクノロジーよりも低い遅延コストで高い分類精度を実現し、AI コンテンツ規制のための革新的なソリューションを提供します。
hyper.ai 公式 Web サイトでは、SynthID-Text の使用チュートリアルを開始しました。ワンクリックでクローンを作成して AI 生成に電子透かしを追加できます。
ワンクリック起動リンク:
11 月 18 日から 11 月 22 日までの hyper.ai 公式 Web サイトの更新の概要:
* 高品質の公開データセット: 10
* 高品質なチュートリアルのセレクション: 3
* コミュニティ記事選択: 4 記事
* 人気のある百科事典のエントリ: 5
※11月~12月締切会議:3回
公式ウェブサイトにアクセスしてください: hyper.ai
公開データセットの選択
1. マルチモーダルなオブジェクトとエンティティの関係抽出データセットの詳細
データセットには 21 の異なる関係タイプが含まれており、20,000 を超えるマルチモーダルな関係事実をカバーしており、3,559 組のテキスト タイトルと対応する画像に注釈が付けられています。
直接使用します:https://go.hyper.ai/LlfTx

2. グアバ果実の病気 グアバ果実の病気のデータセット
データセットには 473 枚のラベル付きグアバ果実画像が含まれており、アンシャープ マスキングや CLAHE (Contrast Limited Adaptive Histogram Equalization) などの前処理ステップを経て、画像数が 3,784 枚に増加しました。各画像は RGB 形式で 512 × 512 ピクセルの一定サイズに前処理されます。 。
直接使用します:https://go.hyper.ai/RRLEd

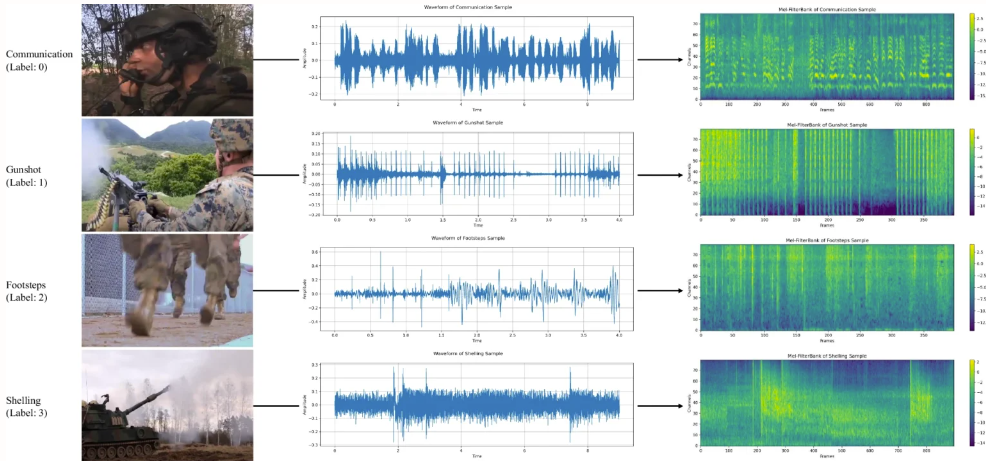
3. MAD 軍事音声データセット
MAD データセットは、音声分類システム、特に銃声、砲撃、爆発などの軍事活動に関連する音声分類タスクのトレーニングと評価をサポートするように設計されています。このデータセットは複数の軍事ビデオから抽出されたもので、7 つのカテゴリに分類された 8,075 個の音声サンプルが含まれており、合計約 12 時間の音声になります。
直接使用します:https://go.hyper.ai/kxqH3
4. MMPR マルチモーダル推論設定データセット
MMPR データ セットには、明確な正解がない 750,000 個のサンプルと、明確な正解がある 250 万個のサンプルが含まれています。サンプルは、多様性を確保するために、VQA、科学、チャート、数学、OCR、ドキュメントなどの複数の分野をカバーしています。このデータセットは、トレーニング中の潜在的な悪影響を回避しながら、マルチモーダル推論タスクにおけるモデルのパフォーマンスを向上させるように設計されています。
直接使用します:https://go.hyper.ai/bbHH0

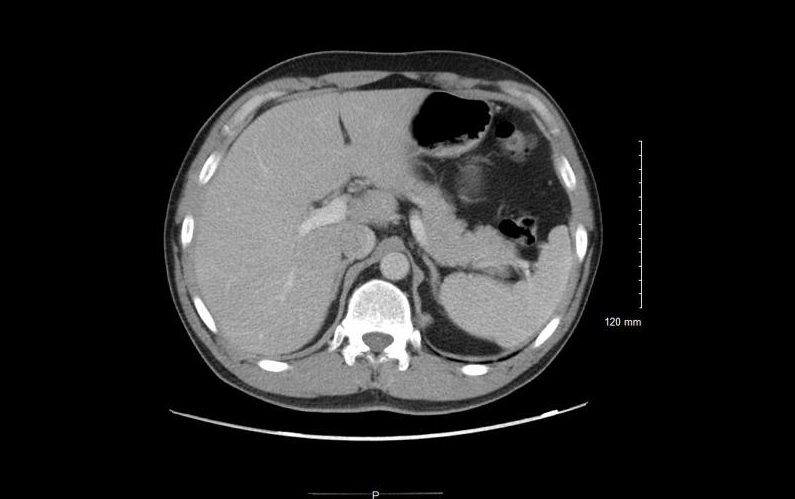
5.ROCOv2 放射線学マルチモーダル医療画像データセット
ROCOv2 データ セットは、放射線画像と関連する医療概念および説明を組み合わせたもので、さまざまな臨床パターン、解剖学的領域、および方向性 (X 線の場合) をカバーする 70,000 を超える放射線画像が含まれています。
直接使用します:https://go.hyper.ai/XgqCa
6. PDFM 地理的にインデックス付けされたデータセット
PDFM 地理インデックス付きデータ セットは、人口動態ベースの埋め込みを評価するために使用される実際のデータであり、地図、検索傾向の概要、天候や大気質などの環境要因から取得された豊富な人間行動の概要情報が含まれています。
直接使用します:https://go.hyper.ai/jpzY1
7. Mantis-Instruct マルチイメージ命令チューニング データ セット
このデータセットは、マルチイメージ命令のチューニングに焦点を当てた、テキストとイメージがインターリーブされたマルチモーダル データセットであり、14 のサブセットで構成され、Mantis モデル シリーズのトレーニングに使用される 721K のサンプルが含まれています。このデータセットは、共参照、推論、比較、時間的理解を含む、さまざまなマルチ画像スキルをカバーします。
直接使用します:https://go.hyper.ai/dOtuR
8. MASSW 科学的ワークフロー データセット
MASSW データセットには、過去 50 年間をカバーする 17 の主要なコンピューター サイエンス会議からの 152,000 を超える査読済み出版物が含まれています。このデータセットは、科学ワークフローの 5 つの主要な側面 (コンテキスト、主要なアイデア、手法、結果、および予想される影響) を定義します。これらの側面は、各出版物から情報を抽出して構造化し、構造化された概要を作成するために使用されました。
直接使用します:https://go.hyper.ai/2pUy8
9. AudioSetCaps オーディオ字幕データセット
AudioSetCaps オーディオ サブタイトル データセットには、611 万を超える 10 秒オーディオ ファイルが含まれています。各オーディオ ファイルには、最終的なタイトルを生成するためのメタデータとして、説明的なタイトルと 3 つの Q&A ペアが付いています。
直接使用します:https://go.hyper.ai/3QCQP
10. 伝統的な中国医学データセット SFT 伝統的な中国医学診断データセット
このデータセットには、中医学の各分野の臨床症例、名著、医学事典、用語解説などの質の高いコンテンツが約1GB収録されています。データセットは主に非ネットワークソースからの内部データで構成されており、優れた品質とかなりの情報密度を備えた簡体字中国語コンテンツであり、事前トレーニングまたは継続的な事前トレーニングの目的に適しています。
直接使用します:https://go.hyper.ai/zb7Uf
選択された公開チュートリアル
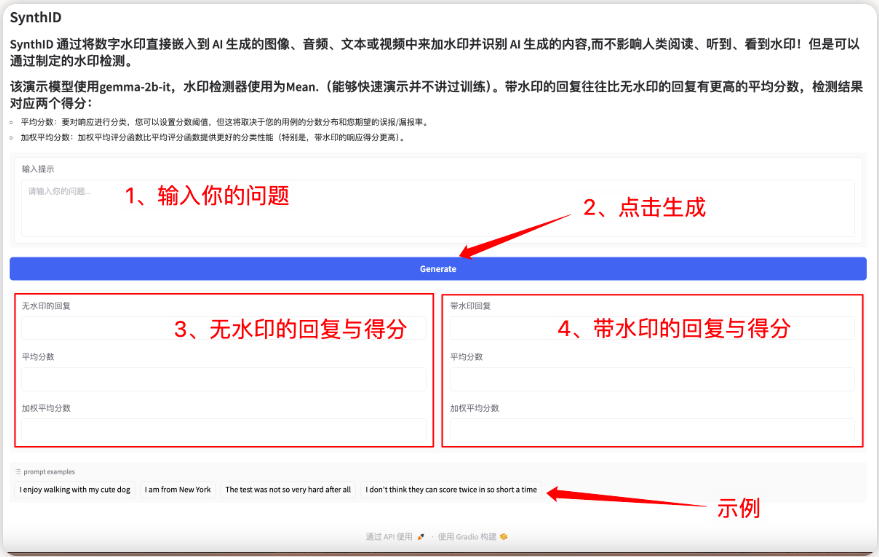
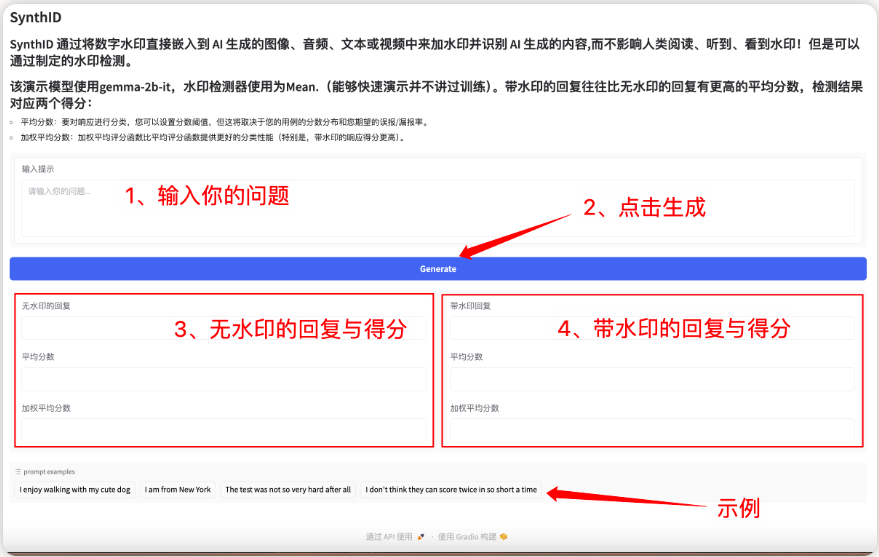
1. SynthID-Text AI テキスト生成透かしツール
このモデルは、大規模言語モデル (LLM) によって生成されたテキストを識別および検証するための透かし技術であり、テキストの品質を維持し、遅延コストを最小限に抑えながら高い検出精度を実現します。その核心は、テキストの品質とユーザーエクスペリエンスを損なうことなく、生成プロセス中にトークン確率スコアを微調整することにより、ほとんど知覚できない透かしを埋め込み、それによって高い検出精度を達成することにあります。
このプロジェクトでは、Gradio インターフェイスを通じてフロントエンドのインタラクティブ インターフェイスを生成でき、関連するモデルと依存関係がデプロイされており、ワンクリックで透かしテキストを生成できます。
オンラインで実行:https://go.hyper.ai/lQ1UK
2. Evo: 分子スケールからゲノムスケールまでの配列予測と生成
Evo は、DNA、RNA、タンパク質といった生物学の基本言語全体を一般化できる生物学に基づいたモデルです。このモデルは、分子からゲノム全体までのスケールでの配列予測と生成をカバーする、予測タスクと生成的設計を実行できます。
以下のリンクをクリックし、チュートリアルの指示に従ってゲノムスケールの配列を予測します。
オンラインで実行:https://go.hyper.ai/LgFWm
3. VASP チュートリアル: 1-1. 孤立酸素原子の DFT 計算
VASP は、電子構造計算および量子力学・分子動力学シミュレーションのためのソフトウェア パッケージです。現在、材料シミュレーションおよび計算材料科学研究において最も人気のある商用ソフトウェアの 1 つであり、その高精度と強力な機能により、研究者が材料特性を予測および設計するための重要なツールとなっており、固体物理学や材料科学で広く使用されています。 、化学、分子動力学などの分野。
このチュートリアルは、VASP 公式チュートリアルの最初の部分です: 孤立した酸素原子の DFT 計算。以下のリンクをクリックし、チュートリアルのガイドラインに従って、DFT ハイパフォーマンス コンピューティングを最初から始めてください。
オンラインで実行:https://go.hyper.ai/pa2NX
💡安定拡散チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] にメモし、グループに参加してさまざまな技術的な問題について話し合い、アプリケーションの効果を共有してください。

注目のコミュニティ記事
分子の逆フォールディングは医薬品や材料の設計において重要な役割を果たしていますが、これまでの研究では普遍的な分子の逆フォールディングにはほとんど注目がありませんでした。これに応えて、ウェストレイク大学未来産業研究センターのチームは、すべての分子の逆フォールディングのための統一モデル UniIF を提案しました。実験結果は、UniIF がタンパク質設計、RNA 設計、材料設計などの複数のタスクで最先端のパフォーマンスを達成することを示しています。この記事は、論文の詳細な解釈と共有です。
レポート全体を表示します。https://go.hyper.ai/efhze
2. 300%により安定した材料生成効率が向上! Meta FAIR がマテリアル生成モデル FlowLLM をリリース、データセットは 450,000 を超えるマテリアルをカバー
AI 技術の学際的応用においては、離散変数と連続変数をどのように組み合わせて結晶材料生成の品質を向上させるかが、結晶材料生成分野における中心的な問題となっています。これを受けてメタFAIR研究所はマテリアル生成モデルFlowLLMをリリースした。従来モデルに比べ、安定素材の生成効率が300%以上向上し、SUN素材の生成効率も約50%向上しました。この記事は、論文の詳細な解釈と共有です。
レポート全体を表示します。https://go.hyper.ai/KJzjz
3. PLM における大きな進歩です。上海交通大学と上海AI研究所の最新の成果がNeurIPS 24に採用されました。ProSSTはタンパク質の構造情報を効果的に統合します。
最近、上海交通大学と上海人工知能研究所は、構造認識機能を備えた事前トレーニング済みタンパク質言語モデル ProSST の開発に成功しました。このモデルは、1,880万個のタンパク質構造を含む大規模なデータセットで事前トレーニングされており、タンパク質構造とアミノ酸配列情報を効果的に融合することができ、教師あり学習タスクにおいて既存のモデルを大幅に上回ります。この記事は、論文の詳細な解釈と共有です。
レポート全体を表示します。https://go.hyper.ai/qi5ei
4. 18 の臨床タスクをカバーする 284 のデータセットを含む、Shanghai AI Lab などがマルチモーダル医療ベンチマーク GMAI-MMBench をリリース
上海人工知能研究所などの多くの科学研究部門は、GMAI-MMBench ベンチマークを提案しています。このベンチマークは、38 の医用画像モダリティ、18 の臨床関連タスク、18 部門、視覚的な質疑応答形式を含む、世界中の 284 の下流タスク データ セットをカバーしています。 4 つの知覚粒度、これまでで最も包括的な普遍的な医療ベンチマーク。さらに、この記事では、ワンクリック接続など、他の医療分野のデータセットもすべての人向けにまとめています。
レポート全体を表示します。https://go.hyper.ai/csr2M
人気のある百科事典の項目を厳選
1. シグモイド関数
2. 核の規範
3. 人工ニューラルネットワーク NN
4. データの拡張
5. 量子ニューラルネットワーク 量子ニューラルネットワーク
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。
主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!
HyperAIについて Hyper.ai
HyperAI(hyper.ai)は、中国をリードする人工知能とハイパフォーマンス・コンピューティングのコミュニティである。国内データサイエンス分野のインフラとなり、国内開発者に豊富で質の高い公共リソースを提供することに注力しています。
* 1,300 を超える公開データセットに対して国内の高速ダウンロード ノードを提供
* 400 以上の古典的で人気のあるオンライン チュートリアルが含まれています
* 200 以上の AI4Science 論文ケースを解釈
* 500 以上の関連用語クエリをサポート
*Apache TVM の最初の完全な中国語ドキュメントを中国でホストします
学習の旅を始めるには、公式 Web サイトにアクセスしてください。
最後に、「クリエイター インセンティブ プログラム」をおすすめします。興味のあるお友達はコードをスキャンして参加してください。









