Command Palette
Search for a command to run...
NeurIPS 2024に選出されました!中国科学院のチームが、脳とコンピューターのインターフェースと認知モデルの開発の基礎を築く、非侵襲的な脳解読のための新しいフレームワークを提案
視覚化されることを見たり、考えたり、夢を見たりすることさえ想像できますか?これは突飛な想像ではありません。カリフォルニア大学バークレー校の神経科学者であるジャック・ギャラント氏は、非侵襲的な脳機能イメージング技術である機能的磁気共鳴画像法 (fMRI) を使用したという仮説を発表しました。被験者の脳の視覚野の活動を読み取り、視覚再構成を通じて被験者が見ているものを視覚的に提示します。それは、脳を解読することを世界中の科学者に求める明白な呼びかけでした。
fMRIに代表される非侵襲的脳解読技術は、侵襲的脳解読技術と比較して、より簡単かつ安全な方法で脳解読を実現できるため、認知神経科学研究、脳とコンピュータのインターフェース応用、臨床などで広く利用されています。医療診断は、他の多くの分野で大きな潜在的な応用価値を持っています。
しかし、個人差や神経信号表現の複雑さのため、非侵襲的な脳信号の解読は脳解読プロセスにおいて依然として重要な課題となっています。従来の手法は、カスタマイズされたモデルと膨大な費用のかかる実験に依存する一方で、正確なセマンティクスと解釈可能性が欠如しているため、視覚再構築タスクにおいて個人の視覚体験を正確に再現することが困難です。 。
これに関して、中国科学院オートメーション研究所のZeng Yi教授のチームは、脳活動の視覚的再構成の問題を解決するために、fMRI特徴抽出器と大規模言語モデルを統合するマルチモーダル統合フレームワークを革新的に設計した。。研究者は、Vision Transformer 3D (ViT3D) を使用して、3 次元の脳構造と視覚セマンティクスを組み合わせ、効率的な統合特徴抽出機能を通じて fMRI 特徴をマルチレベル視覚埋め込みと調整し、特定のモデルを必要とせずに単一の実験データから情報を抽出します。さらに、エクストラクターはマルチレベルの視覚機能を統合し、大規模言語モデル (LLM) との統合を簡素化し、fMRI 画像に関連付けられたテキスト データで fMRI データセットを拡張することにより、マルチモーダル大規模モデルの開発を可能にします。
この成果は「Neuro-Vision to Language: Enhancing Brain Recording-based Visual Reconstruction and Language Interaction」と題され、NeurIPS 2024 に受理されました。
研究のハイライト:
* この研究は、脳信号から視覚刺激を再構成する能力を大幅に向上させ、関連する神経メカニズムの理解を深め、脳活動を解釈する新しい方法を開きます。
* Vision Transformer 3D に基づく fMRI 特徴抽出機能は、3 次元の脳構造と視覚セマンティクスを組み合わせて複数のレベルで調整するため、被験者固有のモデルの必要性がなくなり、たった 1 回の実験で有効なデータを抽出できるため、トレーニングが大幅に削減されます。コストを削減し、実際のシナリオでの使いやすさを向上
* fMRI画像関連のテキストデータを拡張することで、fMRIデータをデコードできるマルチモーダル大規模モデルが構築され、脳のデコード性能が向上するだけでなく、視覚的再構成、複雑な推論、概念の位置特定などを含む応用範囲が拡大します。タスク
用紙のアドレス:
https://nips.cc/virtual/2024/poster/93607
公式アカウントをフォローし、バックグラウンドで「脳信号解読」に返信すると全文PDFが入手できます
オープンソース プロジェクト「awesome-ai4s」は、100 を超える AI4S 論文の解釈をまとめ、大規模なデータ セットとツールを提供します。
https://github.com/hyperai/awesome-ai4s
データセット:自然風景のデータセットに基づき、テストの信頼性を厳密に評価
実験で使用されるデータ セットには、Natural Scenes Dataset (NSD) データ セットと COCO データ セットが含まれます。NSD データセットには、8 人の健康な成人参加者から収集された高解像度 7 テスラ fMRI スキャンが含まれていますが、具体的な実験分析では、研究者らは主にすべてのデータ収集を完了した 4 人の被験者を分析しました。
研究者らはまた、NSD データセットを前処理して、スライス タイミングの違いを補正するための時間的リサンプリングと、頭部の動きと空間的な歪みを調整するための空間補間を可能にしました。トリミングなどの変更を行うと、以下に示すように、元のタイトルとインスタンスの境界ボックスの間に不一致が生じる可能性があります。データの一貫性を確保するために、研究者らは、BLIP2 を使用して各画像に 8 つのキャプションを生成し、DETTR を使用してこれらの画像の境界ボックスを生成し、トリミングされた画像に再アノテーションを付けました。

一部の画像の操作クリッピングにより、元のキャプションとインスタンスの境界ボックスの間に不一致があります
さらに、fMRI データと LLM 間の互換性を確保し、指示の遵守と多様なインタラクションを実現するために、チームは自然言語を使用して NSD に注釈を付ける際の 7 種類の対話、つまり、簡単な説明、詳細な説明、継続的な対話、複雑な対話を拡張しました。推論タスク、命令の再構築、概念のローカリゼーション。
最後に、データの正規化を確実にするために、研究者らは三線形補間を使用してデータを均一な寸法に調整し、fMRI 正規化を 83 × 104 × 81 に設定し、エッジにゼロ パディングを適用した後、データを 14 × 14 × 14 のパッチに分割しました。ローカル情報を保持するため。
モデル アーキテクチャ: fMRI 特徴抽出と LLM を統合するマルチモーダル統合フレームワーク
脳活動の視覚的再構成を解決し、LLMとマルチモーダルデータの融合の問題を解決するために、研究チームは、fMRI特徴抽出と大規模言語モデルを統合するマルチモーダル統合フレームワークを革新的に設計しました。以下に示すように:
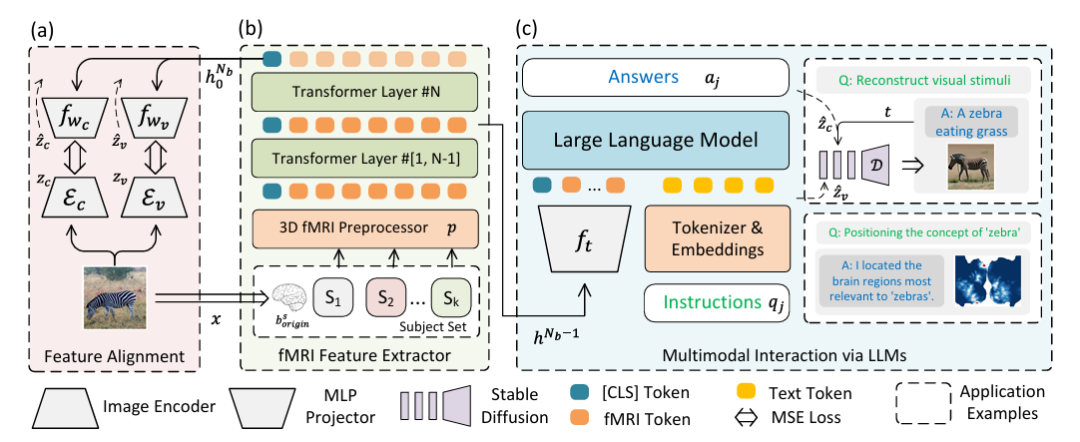
具体的には、上図のパート (a) は、変分オートエンコーダー (VAE) と CLIP 埋め込みを使用した特徴アライメントの 2 ストリーム パスを示しています。実験セットアップでは、画像特徴抽出器として CLIP ViT-L/14 と AutocoderKL が統合されており、隠れ次元 1024 の 2 つの二重層パーセプトロン fwc と fwv がそれぞれ VAE (zv = Ev) と CLIP (zc = Ec) で使用されます。機能の調整。
上図のパート(b)は、3D fMRIプリプロセッサpおよびfMRI特徴抽出器(fMR1 Feature Extractor)を説明する。fMRI データの場合、隠れサイズ 768 の 16 層変換エンコーダーを使用して特徴を抽出し、最後の層のクラス ラベルが出力として使用されます。次に、図 (a) に戻って位置合わせを行い、高品質の視覚的再構成を実現します。
上図のパート (c) は、fMRI と統合されたマルチモーダル LLM を示しています。つまり、LLM を介したマルチモーダルな対話が実現されます。主に、抽出された特徴は LLM に入力され、自然言語命令を処理し、応答または視覚的な再構成を生成するために使用されます。この部分は、ネットワークの最後から 2 番目の隠れ状態 hᴺᵇ⁻¹ を fMRI データのマルチモーダル ラベルとして使用します。fₜ は 2 層パーセプトロンで、「命令」は自然言語命令を表し、「応答」は LLM によって生成された応答を表します。 。
命令ベースの微調整後、モデルは自然言語を介して直接通信することができ、視覚的再構成には UnCLIP を、概念の位置決めには GradCAM をそれぞれ介して、自然言語で表現された概念の視覚的再構成と位置認識をサポートします。図の D はフリーズを表します。アンクリップ。
実験結果: 3 つの主要な実験と複数の比較により、新しいフレームワークが脳信号の解読において良好に機能することが示されました。
提案されたフレームワークのパフォーマンスを評価するために、研究者らは、字幕や質問応答、視覚的再構成、概念のローカリゼーションなどのさまざまな種類の実験を実施し、他の異なる方法と比較することにより、フレームワークの実現可能性と効率性を検証しました。
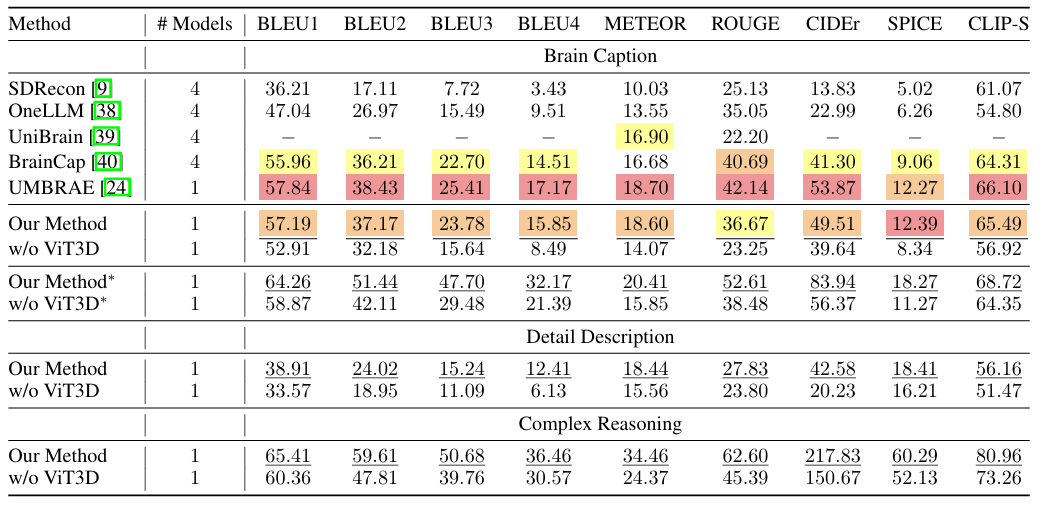
以下の図に示すように、提案されたフレームワークは、Brain Caption タスクのほとんどの指標で優れたパフォーマンスを示します。さらに、このフレームワークは、被験者ごとに個別のモデルをトレーニングしたり、被験者固有のパラメーターを導入したりする必要がなく、適切に一般化されます。研究者らはまた、詳細説明と複雑な推論のタスクを組み合わせ、このフレームワークでも最高のパフォーマンスを達成し、単純なタイトルを生成するだけでなく、詳細な説明を実現し、複雑な推論を実行できることを示しました。
視覚再構成実験では、下図のようになります。この研究で提案された方法は、高レベルの特徴マッチングで良好に機能し、LLM を効果的に利用して複雑な視覚データを説明するモデルの能力を実証しています。さまざまな視覚刺激に対するロバスト性は、提案された方法による fMRI データの包括的な理解を裏付けます。 LLM や VAE シグネチャなどの主要コンポーネントを含まない実験のスコアの低下は、最先端の結果を得るために不可欠な、研究方法論における各要素の重要性を浮き彫りにしています。
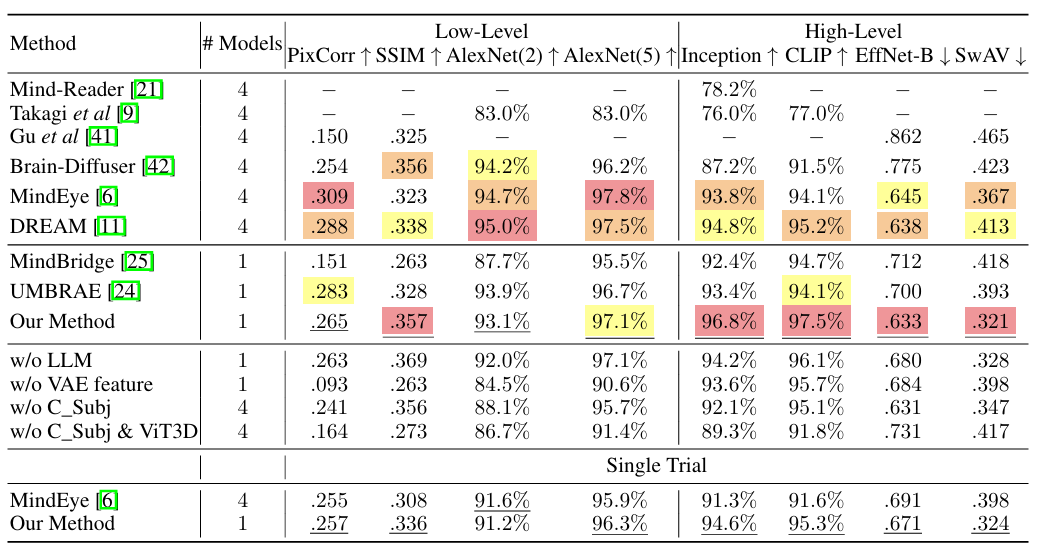
さらに研究者らは、MindEyeの方法と同様に、最初の視覚刺激のみを使用することを選択した単一試行検証も実施した。結果は、より厳しい条件下でも、提案された方法はパフォーマンスのわずかな低下しか示さないことを示しています。実用化の可能性が証明された。
概念ローカリゼーションの実験では、研究者らはまず自然言語からターゲット概念を抽出するために LLM を微調整しました。この概念は、CLIP テキスト エンコーダによってエンコードされると GradCAM のターゲットになります。測位精度を向上させるために、研究者らは異なるパッチ サイズ (14、12、10) で 3 つのモデルをトレーニングし、すべてのモデルの最後から 2 番目の層を使用して意味的特徴を抽出しました。以下の図に示すように、これは提案された方法は、同じ視覚刺激の脳信号内のさまざまな意味の位置を区別することができます。

この方法の有効性を検証するために、研究者らは意味概念に関するアブレーション研究を実施しました。元の脳信号内の概念を特定した後、識別されたボクセル内の信号がゼロ化され、修正された脳信号が特徴抽出と視覚的再構成に使用されます。下の図に示すように、特定の意味概念に関連する特定の脳領域の神経活動を除去すると、対応する意味概念が視覚的再構成で無視されます。これは、脳信号における概念位置特定のためのこの方法の有効性を確認し、脳活動における意味情報を抽出および変更するこの方法の能力を実証する。これは、脳における意味情報処理を理解するために重要である。

全体として、このフレームワークは、LLM の統合によって強化された fMRI データを備えた Vision Transformer 3D の機能を活用して、視覚刺激の脳信号再構成の大幅な改善を達成し、根底にある神経メカニズムの理解についてより正確で解釈可能な洞察を提供します。この成果は、脳活動を解読して解釈するための新たな研究の道を提供するものであり、神経科学および脳とコンピューターのインターフェースにおいて非常に重要です。
人間の脳の働きに関する真実を解読し、自然界で最も神秘的な道具を探索しましょう
人間の最も重要な生物学的器官である脳は、自然界で最も洗練された器官でもあり、数千億の神経細胞と数千億の接続シナプスがあり、さまざまな脳機能を支配する神経ネットワークと神経回路を形成しています。生命科学技術と人工知能の継続的な発展に伴い、脳の働きに関する真実がますます明らかになってきています。
この論文の出典である中国科学院自動化研究所は、我が国の人工知能開発のリーダーとして、脳科学の分野で長年研究を行ってきたことは言及する価値がある。特に人間の脳の視覚情報のエンコードとデコードの研究において。前述の曽毅教授のチームに加えて、同研究所は脳科学に関連したハイレベルな論文を多数発表しており、それらの論文は国際的に有名な学術誌に掲載されています。
たとえば、2008 年末に、同研究所の何恵光教授率いるチームが発表した「ベイズ深層多視点学習による人間の脳活動からの知覚画像の再構成」というタイトルの関連研究結果が、国際的に権威のある IEEE トランザクションに掲載されました。ニューラル ネットワークと機械学習の分野のジャーナル。
この研究で、研究チームは科学的かつ合理的な方法で視覚画像と脳反応の関係を確立しました。視覚画像再構成問題を、マルチビュー潜在変数モデルの欠落ビューに対するベイズ推論問題に変換します。この研究は、脳の視覚情報処理メカニズムを探索するための強力なツールを提供するだけでなく、脳とコンピューターのインターフェイスおよび脳のような知能の開発を促進する上でも一定の役割を果たします。
中国科学院オートメーション研究所に加え、シンガポール国立大学の研究チームも、fMRIを使用して被験者が見た画像を記録し、機械学習アルゴリズムを使用して画像を復元する研究を行っている。関連する結果は、「Seeing Beyond the Brain: Conditional Diffusion Model with Sparse Masked Modeling for Vision Decoding」というタイトルで arXiv に公開されました。

さらに、多くの営利企業も「脳の世界」の開拓を急いでいる。少し前に、イーロン・マスク氏も、2024 年の脳神経外科医会議で、自身のブレイン・コンピューター・インターフェース会社 Neuralink とブレイン・コンピューター・インターフェース技術に関する洞察を共有しました。ブレイン・コンピュータ・インターフェースのコストは高すぎるべきではないとさえ示唆されている。
全体として、脳の解読技術は継続的かつ急速な開発プロセスであると言えます。科学研究機関が推進しているのか、営利企業が推進しているのかに関係なく、人工知能と機械学習の東風に乗って加速し続けています。インテリジェント・ブレインの到来。また、科学の進歩が、脳とコンピューターのインターフェースの開発、損傷した神経系の患者を助けるための機械の使用など、応用分野にもフィードバックされるだろうと信じる価値があります。









