Command Palette
Search for a command to run...
少量のウェット実験データを使用してタンパク質言語モデルを微調整するにはどうすればよいでしょうか?浙江大学チームの成果がNeurIPS 2024に選ばれ、最初の論文で設計思想が詳細に説明されている

生放送「Meet AI4S」シリーズの第 5 回エピソードは、12 月 10 日の 19:00 に定刻に放送されます。HyperAI は、幸運にも浙江大学知識エンジン研究室の博士課程候補者である王澤源氏を招待し、そのテーマを共有します。今回は「拡散によるノイズ除去 このプロセスは、大規模モデルのタンパク質の最適化に役立ちます」です。
浙江大学のChen Huajun教授、Zhang Qiang研究員、Wang Zeyuan博士らが提案した新しいノイズ除去タンパク質言語モデル(DePLM)。タンパク質言語モデルによって捕捉された進化情報は、関連するターゲット特性と無関係なターゲット特性の混合物と見なすことができ、無関係な情報は「ノイズ」とみなされ除去されるため、タンパク質の適応状況が予測され、タンパク質の最適化に役立ちます。
研究により、DePLM はタンパク質変異の影響を予測する点で既存の手法を上回っており、新しいタンパク質に対する強力な一般化能力があることが示されており、この結果はトップカンファレンス NeurIPS 2024 に選ばれました。この生放送では、王澤源博士がこの論文の革新的なアイデアを詳しく説明します。
HyperAI は、すべての人に価値のあるコンピューティング能力のメリットを特別に用意しました。ライブ ブロードキャスト ルームの抽選に参加すると、40 元相当の 10 時間分の NVIDIA RTX A6000 を受け取る機会が得られます。このリソースは 1 か月間有効です。ぜひライブ配信を予約してください!
クリックしてライブブロードキャストをスケジュールします:
ディスカッショングループに参加するには、QR コードをスキャンして「AI4S」とメモしてください⬇️

ゲスト紹介

トピックを共有する
拡散ノイズ除去プロセスを使用して、大規模モデルのタンパク質の最適化を容易にする
内容紹介
この研究グループは、大規模モデルと拡散ノイズ除去モデルを組み合わせ、少量のウェット実験データを通じて微調整する方法を提案し、優れた汎化能力を維持しながらタンパク質適応景観予測タスクにおける大規模モデルの精度を向上させました。モデル自体の。
視聴者のメリット
1. プロテインフィットネスランドスケープ予測の方法、データセット、指標を理解する
2. 適応型景観予測に拡散モデル拡張言語モデル (DePLM) を使用する方法を理解する
3. 進化情報、湿式実験、その他のデータを AI モデルのトレーニングにどのように組み合わせることができるかを探索する
論文レビュー
HyperAI は以前、筆頭著者である Wang Zeyuan 博士による研究論文「DePLM: Denoising Protein Language Models for Property Optimization」を解釈しました。
研究のハイライト
* DePLM は、PLM に含まれる進化情報を最適化することで、ターゲットの特性に無関係な情報を効果的にフィルタリングし、タンパク質の最適化を向上させることができます。
* DePLM は、変異効果の予測において現在の最先端モデルを上回る性能を発揮するだけでなく、新しいタンパク質に対する強力な一般化機能も実証します。
* この研究は、ノイズ除去拡散フレームワークでランキングベースのフォワードプロセスを設計し、拡散プロセスを突然変異の可能性のランキング空間に拡張すると同時に、学習目標を数値誤差の最小化からランキング相関の最大化に変更し、データセット独立学習を促進し、モデルの強力な一般化能力
データセットの取得
ProteinGym タンパク質変異データ セットがこの研究用に選択され、長すぎる野生型タンパク質データ セットを除外した後、最終的に 201 個のディープ ミューテーション スクリーニング (DMS) データ セットが保持されました。
データセットは直接使用されます。
https://hyper.ai/datasets/32818
モデルアーキテクチャ
下図の左側に示すように、DePLM は PLM から導出された進化尤度を入力として使用し、特定の属性のノイズ除去尤度を生成します。これは、下図の中央と右側で、突然変異の影響を予測するために使用されます。一方、ノイズ除去モジュールは、一次構造と三次構造を考慮して、特徴エンコーダーを使用してタンパク質の表現を生成し、その後、これらの表現を使用してノイズ除去モジュールを通じてノイズをフィルタリングします。
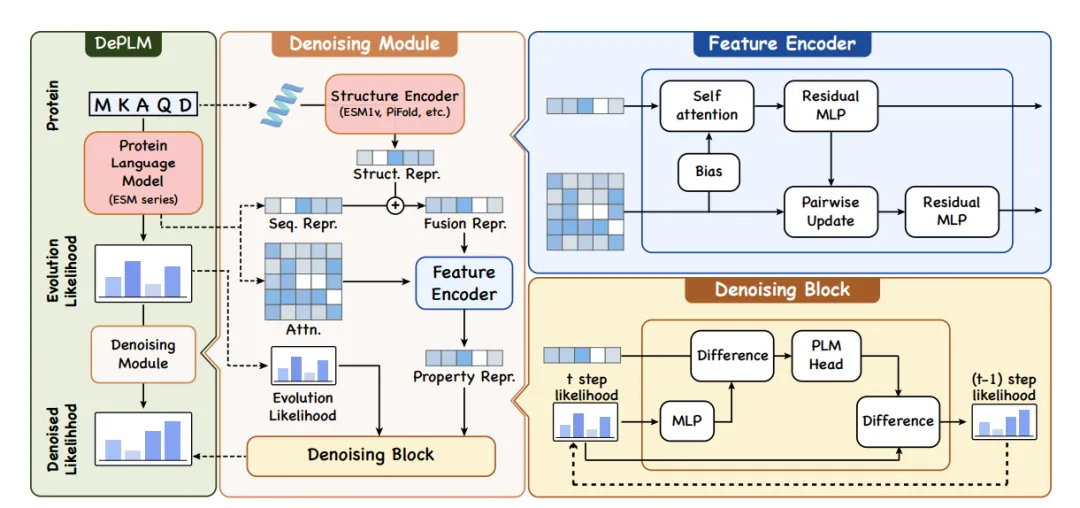
データセットに依存しない学習を実現し、強力なモデル汎化能力を確保するために、研究者らは特徴値のランキング空間で拡散プロセスを実行し、従来の数値誤差目標の最小化をランキング相関の最大化に置き換えました。
浙江大学知識エンジン研究所
ナレッジエンジン研究室は、浙江大学コンピュータ科学技術学部およびソフトウェア学部などに依存しています。ナレッジ グラフ、大規模言語モデル、科学用 AI の分野における学術研究、オープンソース、産業革新アプリケーションに注力しています。共同建設には、浙江大学アントグループナレッジグラフ共同研究開発センター、浙江大学アリババナレッジエンジン共同実験室などが含まれる。
このチームは、優秀なポスドク、何百人もの研究者、研究開発エンジニア、その他のタイプの常勤研究者を長期的に採用しています。どなたでも参加できます。
研究室のGithubホームページ:
AI4S ライブ シリーズを紹介します
HyperAI (hyper.ai) は、データサイエンス分野における中国最大の検索エンジンであり、AI for Science の最新の科学研究結果に焦点を当てており、Nature や Science などのトップジャーナルの学術論文をほぼリアルタイムで追跡しています。これまでに 200 件の AI for Science 論文を解釈。
さらに、中国で唯一の AI for Science オープンソース プロジェクト awesome-ai4s も運営しています。
* プロジェクトアドレス:
https://github.com/hyperai/awesome-ai4s
AI4S の普遍化をさらに促進し、学術機関の科学研究成果の普及障壁をさらに引き下げ、より幅広い業界の研究者、技術愛好家、産業界と共有するために、HyperAI は「Meet AI4S」ビデオ コラムを企画しました。 AI に深く関わっている人々を招待し、科学研究分野の研究者や関連部門を招待し、研究結果や方法論的アイデアをビデオの形式で共有し、科学研究の進歩の過程で AI 科学が直面する機会と課題について共同で議論します。 AI for Science の科学的普及と普及を促進します。
これまでに、地理情報科学、生命科学、タンパク質工学の分野をカバーする Meet AI4S ライブ中継を 4 回開催し、成功を収めてきました。
高効率の研究グループや研究機関は、ライブブロードキャストに参加することを歓迎します。QRコードをスキャンして「Neural Star」WeChatを追加すると詳細がご覧いただけます↓









