Command Palette
Search for a command to run...
上海交通大学の謝偉迪氏は、コンピュータービジョンから医療AIまで、数々の成果を発表し、Natureサブジャーナル/NeurIPS/CVPRなどに掲載された。

近年、科学向け AI の開発が加速しており、科学研究分野に革新的な研究アイデアをもたらしただけでなく、AI の実装チャネルを拡大し、より困難なアプリケーション シナリオを提供しています。この過程で、AI分野の研究者がますます多くなり、医療、材料、生物学などの伝統的な科学研究分野に注目し、研究の難しさや業界の課題を探求し始めています。
上海交通大学の常任准教授である謝偉迪氏は、コンピュータビジョンの分野に深く関わっており、2022年に中国に帰国し、医療用人工知能の研究に専念した。HyperAIとHyperAIが共同で開催したCOSCon'24 AI for Scienceフォーラムでは、Xie Weidi教授が「医療向けジェネラリストモデルの開発に向けて」と題して、オープンソースのデータセット構築やモデル開発など複数の観点からチームの成果を共有した。

HyperAI Super Neural は、その詳細な共有を、当初の意図に違反することなく編集および要約しました。以下はスピーチの要点です。
医療用人工知能は一般的なトレンドになっている
医学研究はすべての人の生命と健康にとって不可欠です。一方で、医療資源の偏りの問題は長らく解決されていません。したがって、私たちは国民皆保険を推進し、誰もが質の高い診断と治療を受けられるようにしたいと考えています。
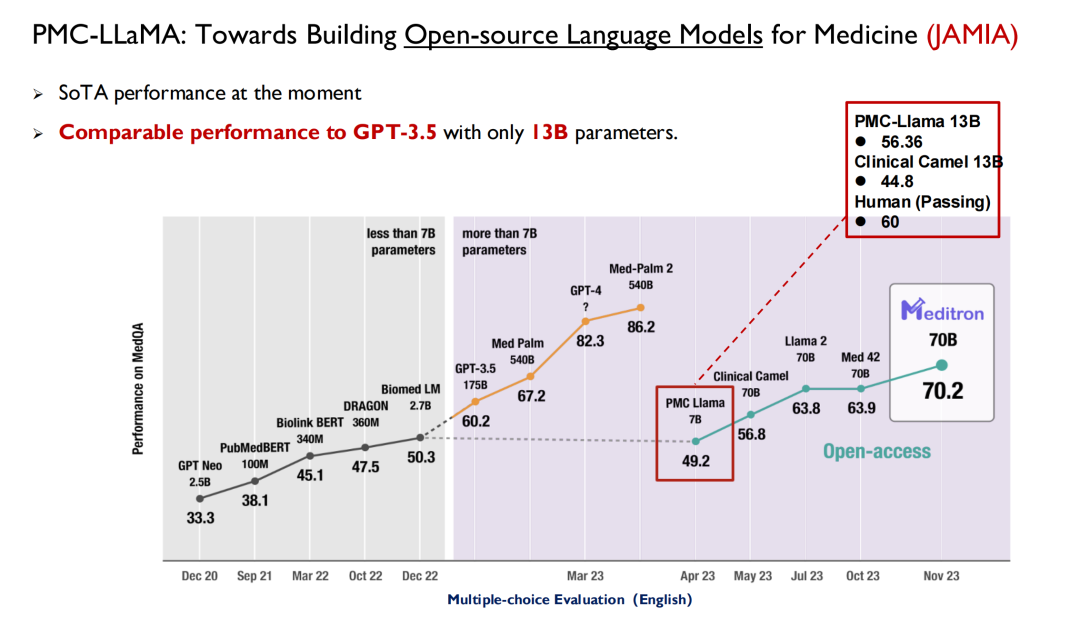
近年登場したChatGPTなどの大型モデルでは、医療を主戦場とした性能テストが行われています。以下の図に示すように、米国の医師免許試験では、大型モデルは 2022 年までに 50 点のレベルに達する可能性があり、それまでに人間は 70 点に達する可能性があるため、AI は医師の間でそれほど大きな懸念を引き起こしていません。
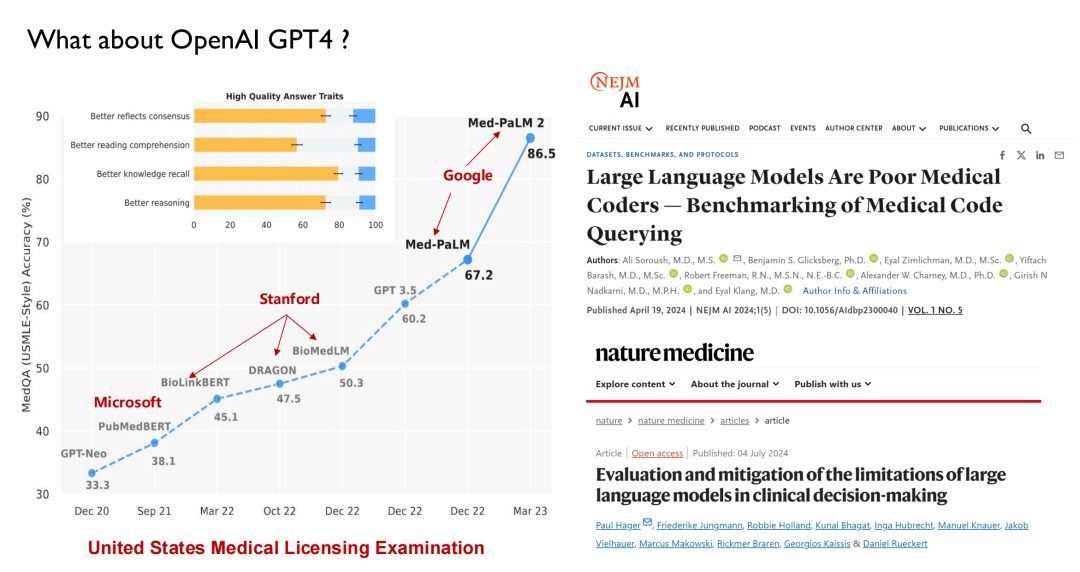
GPT 3.5 のリリースにより、そのスコアは 60.2 に達し、大幅に改善されました。その後、Google は Med-PaLM とその更新版をリリースし、今日の GPT-4 の最高スコアは 90 ポイントに達します。このような高いパフォーマンスと反復速度により、医師は AI に注目し始めています。現在、多くの医学部がインテリジェント医療という新しい科目を提供しています。
同様に、人工知能について学ぶ必要があるのは医学生だけではありません。AIの学生は最終学年のコースで学校医学を履修することもできます。ハーバード大学などのAI専攻はすでに関連コースを開設している。
しかしその一方で、Nature Medicine などの学術誌の研究によると、大きな言語モデルは実際には医療を理解していません。例えば、現状では大型モデルはICDコード(国際疾病分類システムにおける診断コード)を理解できず、医師が患者の検査結果に基づいて次の段階の医療指導をタイムリーに行うことが困難である。医療分野では、大型モデルには依然として多くの制限があることがわかります。それが医師の代わりになるとは決して思わない。私たちのチームがやりたいのは、これらのモデルが医師をより良く支援できるようにすることだ。
チームの主な目標: 一般的な医療用人工知能システムを構築する
私は 2022 年に中国に戻り、医療用人工知能に関連する研究を開始する予定です。そのため、今日私が共有するのは主に過去 2 年間のチームの成果です。医療業界は多岐にわたり、私たちが開発するモデルは普遍的とは言えませんが、重要な課題をできる限りカバーしていきたいと考えています。
以下の図に示すように、入力側では、複数のモダリティをサポートしたいと考えています。たとえば、画像、音声、患者の健康記録などです。 Multi-modal Generalist Model for Medicine に入力すると、医師はそれを操作できるようになります。モデルの出力には少なくとも 2 つの形式があり、1 つは視覚的な形式、セグメンテーション、検出、その他の方法を通じて病変の位置を見つけます。2つ目はテキスト(Text)、診断結果(Diagnostic)またはレポート(Report)を出力します。
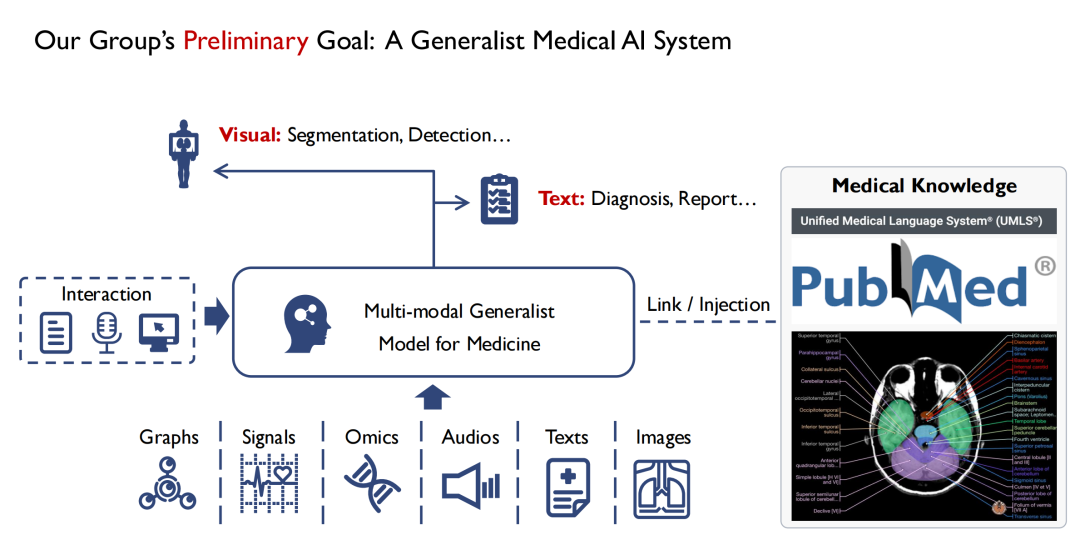
私は個人的にコンピュータービジョンの経験がありますが、視覚と医学の大きな違いは、医学、特に科学的根拠に基づいた医学の分野における知識は、初心者ができる限り人間の経験から要約されているということです。したがって、すべての医学書を読めば、少なくとも理論的な医学の専門家になることができます。モデルのトレーニング プロセス中に、すべての医学知識をモデルに注入したいと考えています。モデルに基礎的な医学知識が欠けていると、医師や患者の信頼を得ることが難しくなるからです。
要約すると、私たちのチームの主な目標は、マルチモーダルな普遍的な医療モデルを構築し、そこに医療知識を可能な限り包括的に注入することです。
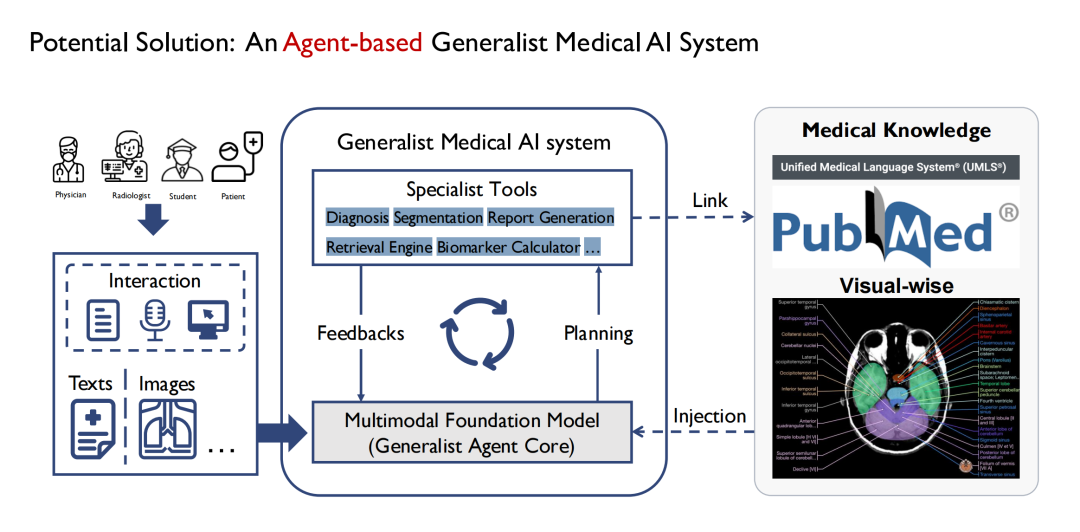
当初、私たちは一般的なモデルの定義を開始しましたが、GPT-4 のような全能の医学モデルを構築するのは現実的ではないことが徐々にわかりました。病院には多くの部門があり、部門ごとに業務が異なるため、一般的なモデルですべての業務をカバーすることは困難です。したがって、エージェントを介して実装することを選択します。以下の図に示すように、中央の一般モデルは複数のサブモデルで構成され、各サブモデルは基本的にエージェントになります。最終的に、一般モデルはマルチ エージェントの形式で構築されます。
利点は、異なるエージェントが異なる入力を受け入れることができるため、モデルの入力側をより複雑で多様にすることができることです。また、複数のエージェントが異なるタスクを段階的に処理する過程で思考の連鎖を形成することもできます。たとえば、1 つのエージェントで CT や MRI などの複数の種類の医療画像のセグメンテーションを同時に完了でき、拡張性も優れています。
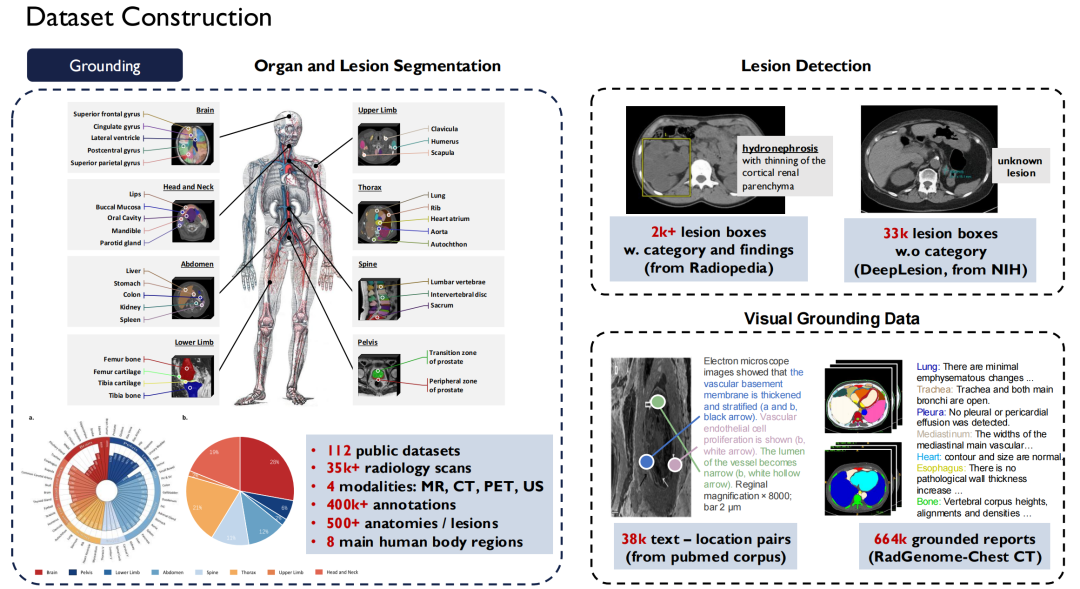
高品質のオープンソース データセットを提供する
マルチモーダルな普遍的な医療モデルを構築するという全体的な目標に焦点を当て、オープンソースのデータセット、大規模な言語モデル、疾患診断エージェントなどのさまざまな側面からチームの成果を紹介します。
1 つ目は、オープンソース データセットへの貢献です。
医療分野ではデータセットが不足しているわけではありませんが、プライバシーバイデザインの懸念により、オープンに利用できる高品質のデータは比較的不足しています。私たちは学術チームとして、より高品質のオープンソース データを業界に貢献したいと考えています。そこで、中国に帰国後、大規模な医療データセットの構築を始めました。
テキストに関しては、40 億のトークンを含む 30,000 冊以上の医学書を収集し、インターネット上の 480 万の論文と 750 億のトークンを含むすべての医学文献をクロールしました。 、日本語など8か国語の医学書をテキスト化します。
また、医療分野におけるスーパーインストラクションも構築しました。タスクの多様性を考慮して、1,350 万サンプルを含む 124 の医療タスクがリストされています。

テキスト データは比較的簡単に入手できますが、Vision-Language (画像とテキストのペア) は入手がより困難です。私たちは Radiopaedia の Web サイトで約 200,000 件の症例をクロールし、論文の画像とそのキャプション、放射線科の基本報告書から入手した 30,000 冊以上も収集しました。
現在、当社のデータのほとんどはオープンソースです。
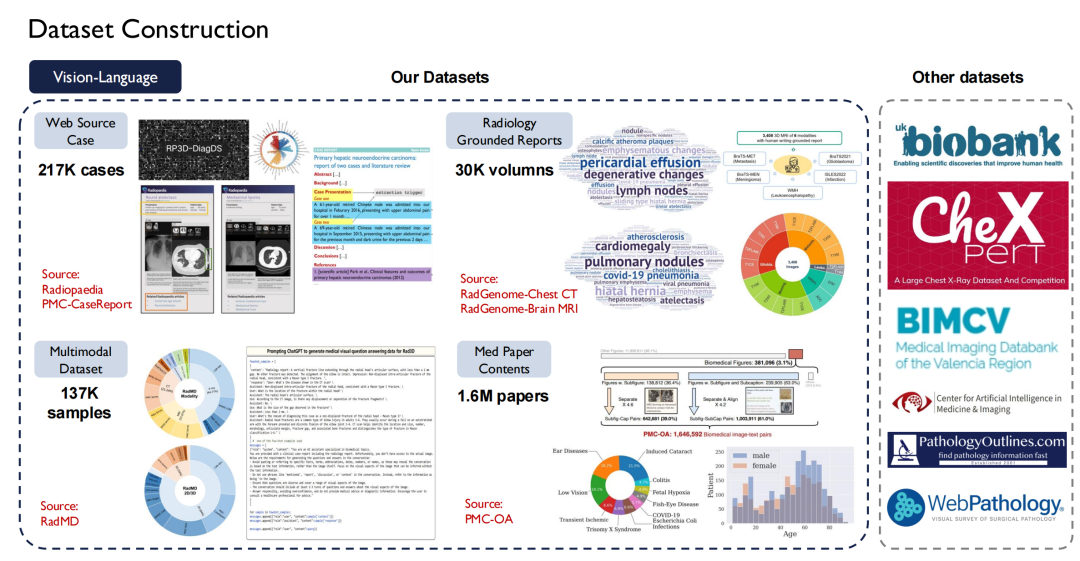
上の図の右側に示されているのは、英国バイオバンクなどの他の公開データ セットです。英国バイオバンクでは、英国の約 100,000 人の患者から 10 年間にわたってデータを購入しました。さらに、Pathology Outlines は包括的な病理学の知識を提供します。
グラウンディングデータに関しては、それは先ほど述べたセグメンテーション (Segmentation) と検出 (Detection) データです。当社は、市場に流通している約 120 の公共放射線画像データ セットを 1 つの標準に統合し、35,000 を超える 2D/3D 放射線スキャン画像を取得しました。MR、CT、PET、US の 4 つのモダリティをカバーする 400,000 のきめ細かい注釈があり、これらのデータは身体の 500 の器官をカバーします。同時に、病変の説明も拡張し、これらすべてのデータセットをオープンソース化しました。
大規模な専門的な医療モデルを作成するための継続的な反復
言語モデル
高品質のオープンソース データセットのみが、学生や研究者がより優れたモデル トレーニングを行うのに役立ちます。次に、モデルに関するチームの結果を紹介します。
1 つ目は言語モデルです。これは人間の知識をモデルに迅速に注入する方法です。昨年 4 月に、私たちは PMC-LLaMA と呼ばれるモデルを立ち上げ、関連する研究が「医学のためのオープンソース言語モデルの構築に向けて」というタイトルで JAMIA に掲載されました。
用紙のアドレス:
https://academic.oup.com/jamia/article/31/9/1833/7645318
これは、私たちが開発したオープンソースの医療分野における最初の大規模言語モデルです。すべての医療データと先ほど述べた論文データがモデルにトレーニングされ、自己回帰トレーニングが実行され、その後、命令が微調整されて言語モデルに変換されます。データを質問と回答のペアに変換します。
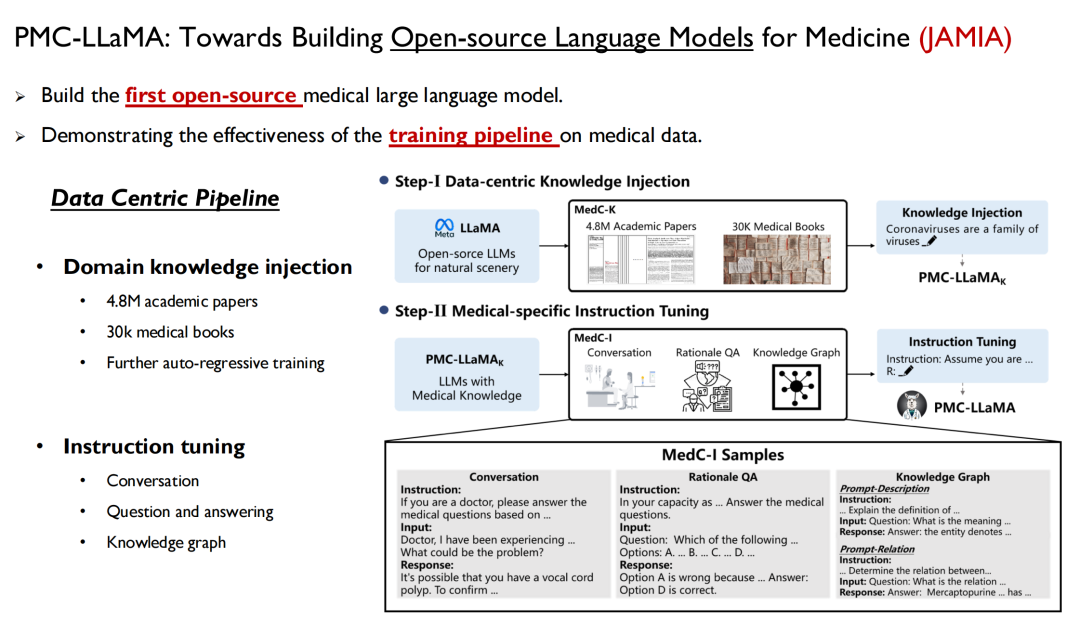
イェール大学の研究者は論文の中で次のように述べています。 PMC-LLaMA は、この分野で開始された最も初期のオープンソース医療モデルです。将来的には、多くの研究者がこれをベースラインとして使用することになりますが、私の意見では、PMC-LLaMA とクローズドソース モデルの間にはまだギャップがあるため、今後もこのモデルを繰り返しアップグレードしていくつもりです。
その後、我々は別の成果「医学のための多言語言語モデルの構築に向けて」を Nature Communications に発表しました。英語、中国語、日本語、フランス語、ロシア語、スペイン語の 6 言語をカバーする大規模な多言語医療モデルが開始され、250 億の医療関連トークンを使用してトレーニングされました。統一された多言語標準テスト セットが存在しないため、誰もがテストできる関連ベンチマークも構築しました。
クリックして詳細レポートを表示: 医療分野のベンチマーク テストは Llama 3 を超え、GPT-4 に迫る 上海交通大学のチームが 6 か国語をカバーする多言語医療モデルをリリースしました。
実際に、基本モデルがアップグレードされ、そこに医療知識が注入されると、結果として得られる大規模な医療モデルのパフォーマンスも向上することがわかりました。
上記のタスクのほとんどは「多肢選択式の質問」ですが、医師が実際の業務で多肢選択式の質問のみを行うのは不可能であることは誰もが知っています。フリーテキスト形式のワークフロー。これを考慮して、新しい研究では、臨床タスクにさらに焦点を当て、関連するデータセットを収集し、モデルの臨床拡張性を向上させます。
関連する論文はまだ審査中です。
視覚言語モデル
同様に、私たちは医療分野で視覚言語モデルの研究を始めた初期のチームでもあります。上記のデータに基づいて、私たちは 3 つのオープンソース データセットを構築しました。
* PMC-OA データセットを構築するために、160 万の大きな画像とタイトルのペアが PubMed Central から収集されました。
* 227,000 の医療視覚的な質問と回答のペアが PMC-OA から生成され、PMC-VQA が形成されました。
* Rad3D データセットは、Radiopedia 種から収集された 53,000 の症例と 48,000 のマルチ画像キャプションのペアから構築されました。
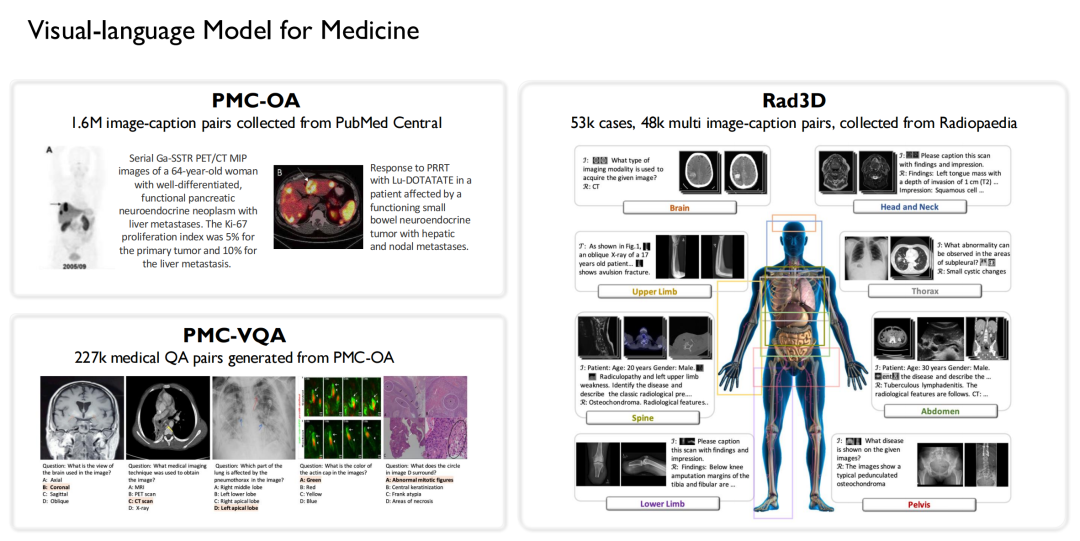
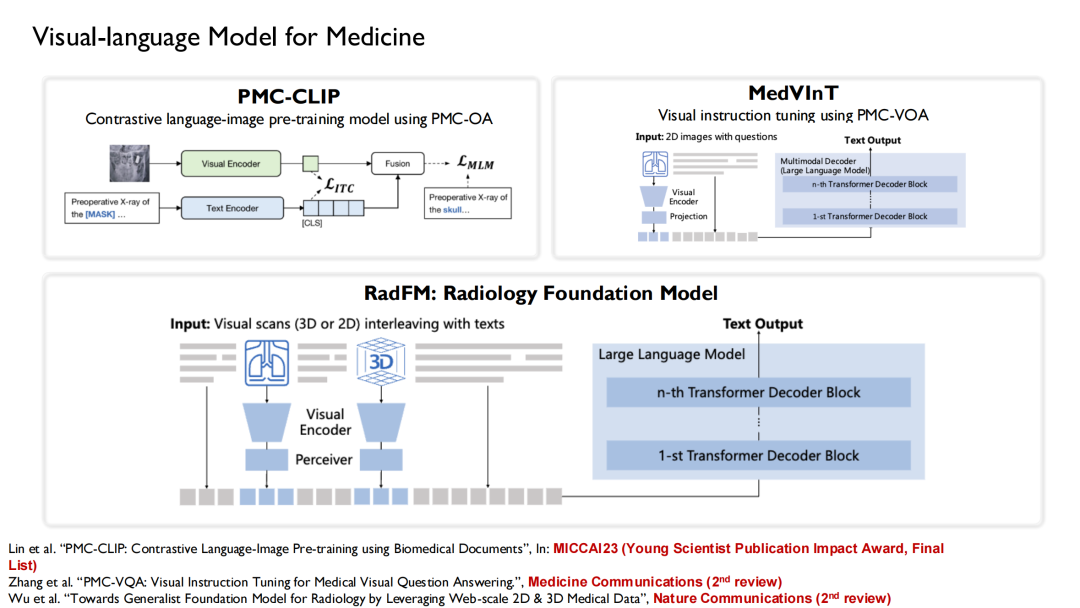
これらのデータセットに基づいて、トレーニングされた言語モデルを組み合わせます。PMC-CLIP、MedVInT、および RadFM の 3 つのバージョンの視覚言語モデルがトレーニングされました。
PMC-CLIPは、医療用人工知能画像処理分野のトップカンファレンスであるMICCAI 2023で発表した成果です。ついに「若手科学者出版インパクト賞 最終リスト」を受賞、この賞は、過去 5 年間の 3 ~ 7 件の受賞論文の選出に基づいています。
現在、RadFM (Radiology Foundation Model) の人気が高まっており、多くの研究者がそれをベースラインとして使用しています。トレーニングの過程で、テキストと画像が混在した形式をモデルに入力し、質問に基づいて回答を直接生成できます。
ドメイン固有の知識を強化し、モデルのパフォーマンスを向上させる
いわゆる知識強化表現学習 (Knowledge-Enhanced Representation Learning) では、医学知識をモデルに注入する方法を解決する必要があります。私たちは、この課題に関して一連の研究も行ってきました。
まず、「知識」がどこから来るのかを解決する必要があります。一方で、一般的な医学知識があります。医療分野最大のナレッジ グラフである UMLS によって外部販売されているインターネットおよび関連論文および書籍をソースとしています。一方、ドメイン固有の知識は、たとえば、症例、放射線画像、超音波など、また、一部の Web サイトから得られる解剖学に関する知識 (Anatomy Knowledge) については、著作権の問題に特に注意する必要があります。使用されます。

この「知識」を獲得した後、知識マップを描くことができ、このように、病気と病気、薬と薬、タンパク質とタンパク質の関係が、具体的な説明とともに確立されます。
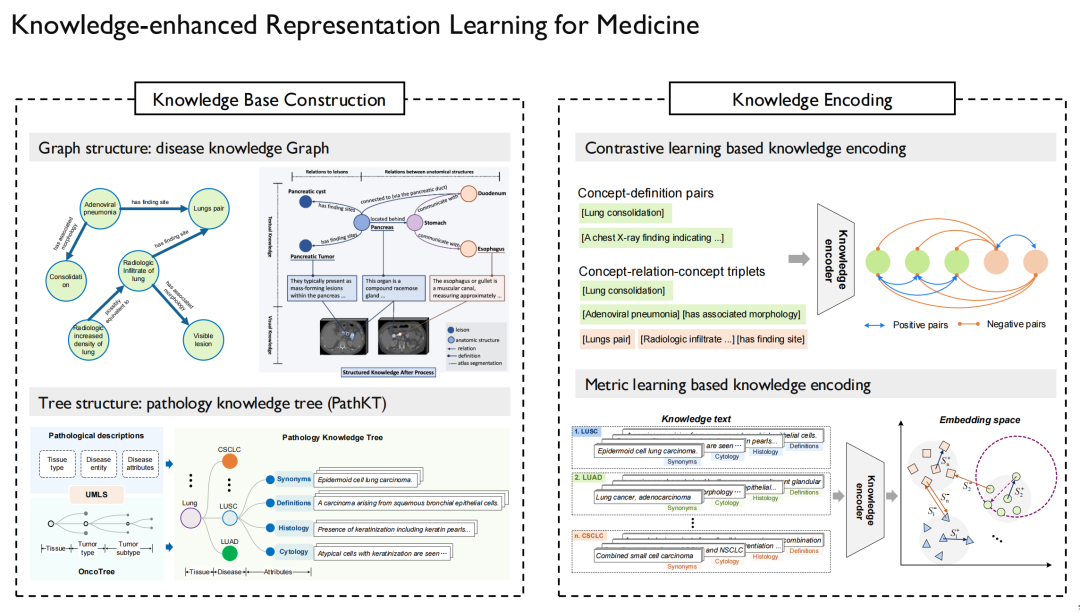
上の図の左側は、私たちが構築した病理知識グラフ (Knowledge Graph) と知識ツリー (Knowledge Tree) です。がんの位置は人体のさまざまな臓器にあり、さまざまなサブタイプにも分類されるため、ツリーの構造化形式に作成するのに適しています。同様に、マルチモーダル病理学に加えて、マルチモーダル放射線学およびマルチモーダル X 線に関する関連研究も実施しました。
次のステップでは、この知識を言語モデルに注入し、グラフとグラフ内の点の関係をモデルに記憶させます。言語モデルがトレーニングされたら、視覚モデルを言語モデルに合わせて調整するだけで済みます。
この結果をマイクロソフトおよびスタンフォード大学の関連結果と比較したところ、次のことがわかりました。ドメイン知識が追加されたモデルのパフォーマンスは、ドメイン知識のない他のモデルよりもはるかに高くなります。
病理学に直面して、私たちの論文「計算病理学のための知識強化視覚言語事前トレーニング」がトップの機械学習カンファレンス ECCV 2024 (口頭) に選ばれました。この作業では、知識ツリーを構築してモデルのトレーニングに注入し、視覚と言語を調整します。
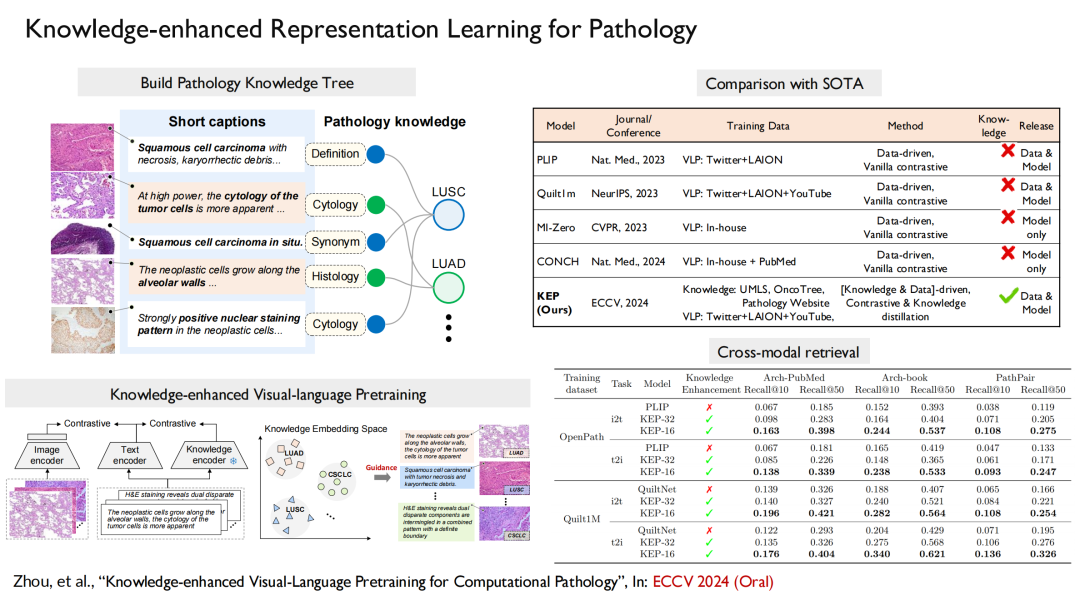
さらに、同様の手法を用いてマルチモーダル放射線画像モデルを構築し、その結果は「放射線画像上の大規模なロングテール疾患診断」というタイトルでNature Communications誌に掲載されました。モデルは、患者の放射線画像に基づいて、対応する疾患を直接出力できます。
総括する、私たちの取り組みは完全なプロセスを実行しました。まず、930 の疾患をカバーする 200,000 枚の画像、41,000 人の患者画像を含む最大のオープンソース放射線画像データ セットを構築しました。次に、特定の分野の知識を強化するシステムを構築しました。最終的に、マルチモーダルおよびマルチ言語モデルが構築されました。
謝偉迪教授について
上海交通大学常任准教授、国内(海外)ハイレベル若手人材、上海海外ハイレベル人材プログラム、上海モーニングスタープログラム受賞者、科学技術省科学技術イノベーション2030 - の青少年プロジェクトリーダー「新世代人工知能」主要プロジェクト 中国国家財団の総合プロジェクトリーダー。
彼は、オックスフォード大学の Visual Geometry Group (VGG) で博士号を取得し、アンドリュー ジッサーマン教授とアリソン ノーブル教授に師事して卒業しました。彼は、Google-DeepMind 全額奨学金受給者、中国オックスフォード奨学金受給者の第一期生の 1 人です。オックスフォード大学工学部優秀賞受賞。
彼の主な研究分野はコンピュータ ビジョンと医療人工知能で、CVPR、ICCV、NeurIPS、ICML、IJCV、Nature Communications などを含む 60 以上の論文を発表しています。Google Scholar で 12,500 回以上引用され、受賞しています。数々のトップ国際会議セミナーで最優秀論文賞、最優秀ポスター賞、最優秀ジャーナル論文賞、MICCI Young Scientist Publication Impact Award ファイナリスト、Nature Medicine、Nature Communications招待査読者、CVPR、NeurIPS、ECCV、コンピュータビジョンおよび人工知能分野の主力カンファレンスのエリアチェア。
※個人ホームページ:










