Command Palette
Search for a command to run...
18 の臨床タスクをカバーする 284 のデータセットを含む、Shanghai AI Lab などがマルチモーダル医療ベンチマーク GMAI-MMBench をリリース

「このようなスマート医療機器を使用すると、患者はスマート医療機器の上に横たわるだけで、スキャン、診断、治療、修理の全プロセスを完了でき、健康的な再スタートを実現できます。」これは2013年に公開されたSF映画『エリジウム』のあらすじです。

現在、人工知能技術の急速な発展により、SF映画に登場する医療シーンが現実のものとなることが期待されています。医療分野では、大規模視覚言語モデル (LVLM) は、イメージング、テキスト、さらには DeepSeek-VL、GPT-4V、Claude3-Opus、LLaVA-Med、MedDr、DeepDR などの生理学的信号などの複数のデータ タイプを処理できます。 -LLMなど、病気の診断や治療において大きな発展の可能性を秘めています。
ただし、LVLM を実際に臨床実践する前に、モデルの有効性を評価するためのベンチマークを確立する必要があります。しかし、現在のベンチマーク テストは通常、特定の学術文献に基づいており、主に 1 つの分野に焦点を当てており、知覚的な粒度が異なるため、実際の臨床シナリオにおける LVLM の有効性とパフォーマンスを包括的に評価することが困難になっています。
これに応えて、上海人工知能研究所は、ワシントン大学、モナシュ大学、華東師範大学などのいくつかの科学研究機関と協力して、GMAI-MMBench ベンチマークを提案しました。 GMAI-MMBench は、世界中の 284 の下流タスク データ セットから構築されており、38 の医用画像モダリティ、18 の臨床関連タスク、18 部門、および完全なデータ構造分類を備えた Visual Question Answering (VQA) 形式の 4 つの知覚粒度をカバーしています。そしてマルチ認識の粒度。
「GMAI-MMBench: 一般的な医療 AI に向けた包括的なマルチモーダル評価ベンチマーク」と題された関連研究は、NeurIPS 2024 データセット ベンチマークに選択され、arXiv でプレプリントとして公開されました。

用紙のアドレス:
https://arxiv.org/abs/2408.03361v7
HyperAI Super Neural 公式サイトにて、ワンクリックでダウンロードできる「GMAI-MMBench Medical Multi-modal Assessment Benchmark Dataset」を公開しました!
データセットのダウンロードアドレス:
https://go.hyper.ai/xxy3w
GMAI-MMBench: これまでで最も包括的でオープンソースの一般医療 AI ベンチマーク
GMAI-MMBench の全体的な構築プロセスは、次の 3 つの主要なステップに分けることができます。
まず、研究者らは世界中の公開データセットと病院データから数百のデータセットを検索し、フィルタリング、画像形式の統一、ラベル表現の標準化を経て、284 個の高品質のラベル付きデータセットが保持されました。
これら 284 のデータ セットは、2D 検出、2D 分類、2D/3D セグメンテーションなどのさまざまな医用画像タスクをカバーしており、専門の医師によって注釈が付けられているため、医用画像タスクの多様性と高度な臨床検査が保証されていることは注目に値します。関連性と正確さ。
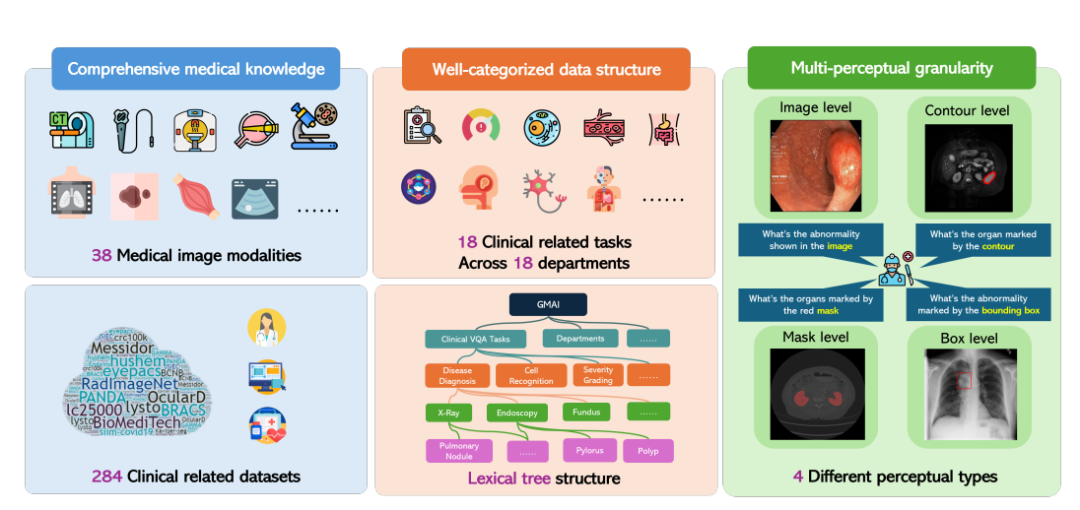
次に、研究者らはすべてのラベルを 18 の臨床 VQA タスクと 18 の診療部門に分類しました。これにより、LVLM の長所と短所をあらゆる側面で包括的に評価できるようになり、モデル開発者や特定のニーズを持つユーザーにとって便利になります。
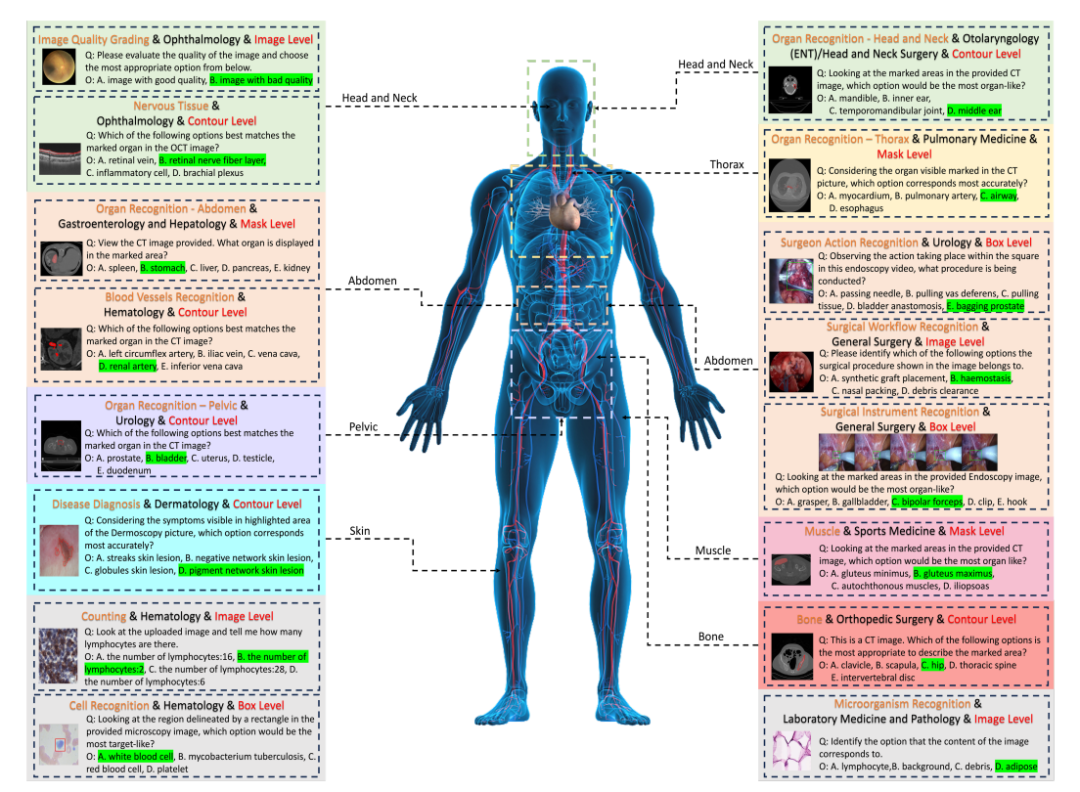
具体的には、研究者らは、すべての症例を 18 の臨床 VQA タスク、18 の部門、38 のモダリティなどに分類するための語彙ツリー構造と呼ばれる分類システムを設計しました。 「臨床 VQA タスク」「部門」「モダリティ」は、評価に必要な症例を検索するために使用できる単語です。たとえば、腫瘍科では腫瘍関連の症例を選択して腫瘍学タスクにおける LVLM のパフォーマンスを評価でき、特定のニーズに対する柔軟性と使いやすさが大幅に向上します。
最後に、研究者らは、各ラベルに対応する質問と選択肢のプールに基づいて、質問と回答のペアを生成しました。各質問には、画像モダリティ、タスク プロンプト、および対応する注釈の粒度情報が含まれている必要があります。最終的なベンチマークは、追加の検証と手動スクリーニングを通じて取得されました。
50 のモデル評価、GMAI-MMBench ベンチマークを上回るのは誰でしょうか?
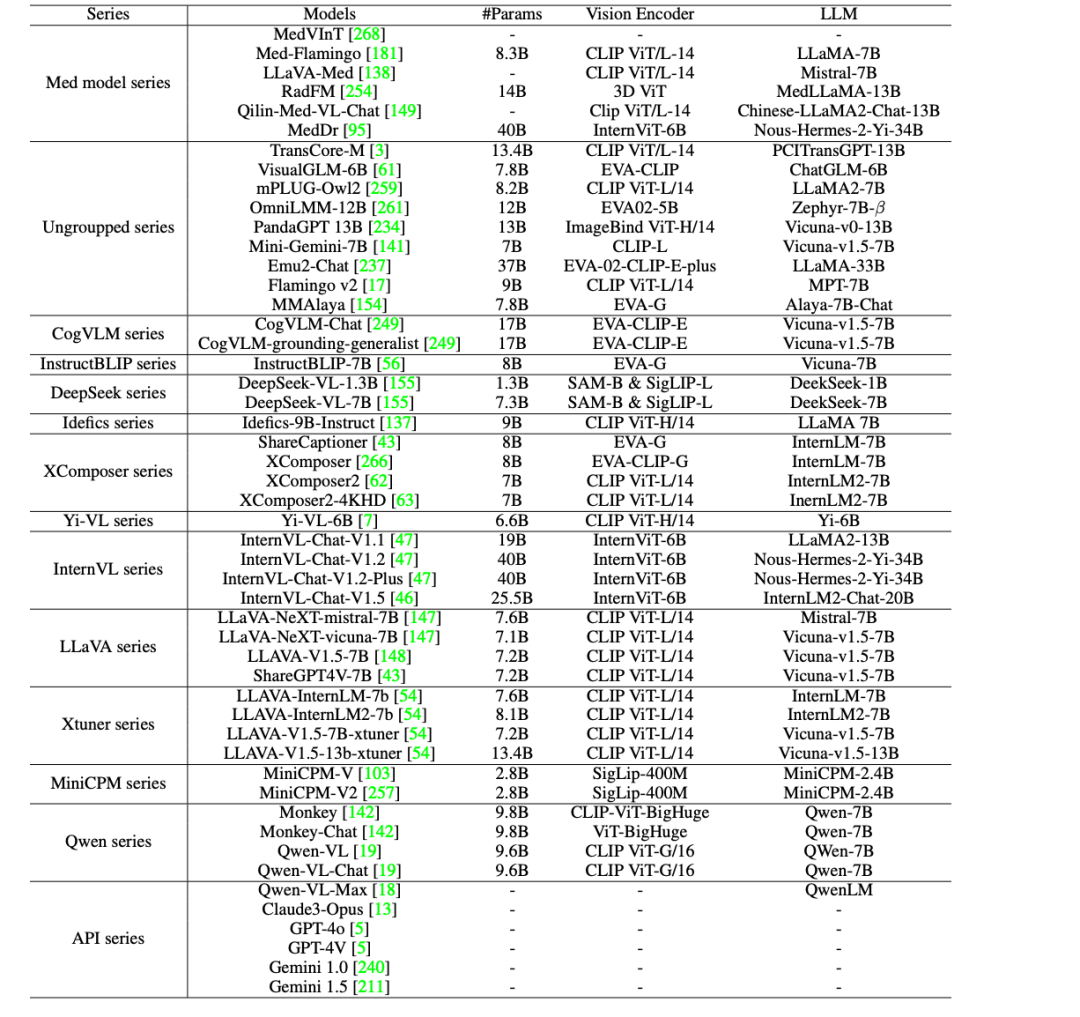
医療分野におけるAIの臨床応用をさらに推進するために、研究者らは、GPT-4o、GPT-4V、Claude3-Opus、Gemini 1.0などの商用クローズドソースLVLMだけでなく、GMAI-MMBenchで44のオープンソースLVLM(38の一般モデルと6の医療固有モデルを含む)を評価しました。 、Gemini 1.5 および Qwen-VL-Max。
現在の LVLM には、次の 5 つの主要な欠陥がまだあることが判明しました。
* 臨床応用にはまだ改善の余地があります。最高性能のモデル GPT-4o でさえ、実際の臨床応用の要件を満たしていますが、その精度はわずか 53.96% であり、現在の LVLM が医療専門家の問題を処理するには不十分であることを示しています。改善の余地はまだ大きくあります。
* オープンソース モデルと商用モデルの比較: MedDr や DeepSeek-VL-7B などのオープンソース LVLM の精度は約 44% で、一部のタスクでは商用モデルの Claude3-Opus や Qwen-VL-Max よりも優れています。 Gemini 1.5 と一致しており、GPT-4V も同等のパフォーマンスを発揮します。ただし、最高のパフォーマンスを誇る GPT-4o と比較すると、依然として大きなパフォーマンスの差があります。
* ほとんどの医療専用モデルは、精度が 43.69% に達する MedDr を除き、汎用 LVLM の一般的な性能レベル (精度約 30%) に達することが困難です。
* ほとんどの LVLM は、異なる臨床 VQA タスク、部門、および知覚の粒度にわたってパフォーマンスが不均一です。特に、知覚の粒度が異なる実験では、ボックスレベルでのアノテーション精度は常に最低であり、画像レベルでのアノテーション精度よりもさらに低くなります。
* パフォーマンスのボトルネックにつながる主な要因には、知覚エラー (画像コンテンツの認識エラーなど)、医療分野の知識の欠如、無関係な回答内容、セキュリティ プロトコルによる質問への回答の拒否などが含まれます。
総合すると、これらの評価結果は、医療用途における現在の LVLM の性能にはまだ多くの改善の余地があり、実際の臨床ニーズを満たすにはさらなる最適化が必要であることを示しています。
スマート医療の徹底的な開発を促進するために医療オープンソース データセットを収集する
医療分野では、高品質のオープンソース データセットが医学研究と臨床実践の進歩の重要な原動力となっています。この目的のために、HyperAI はすべての人のためにいくつかの医療関連データ セットを選択しました。簡単に説明すると次のとおりです。
PubMedVision 大規模医療 VQA データセット
PubMedVision は、深センビッグデータ研究所、香港中文大学、国家健康データ研究所の研究チームによって 2024 年に作成された大規模かつ高品質の医療マルチモーダル データセットであり、130 万の医療 VQA が含まれていますサンプル。
グラフィックデータとテキストデータの整合性を改善するために、研究チームは大規模なビジュアルモデル(GPT-4V)を使用して画像を再記述し、10のシーンのダイアログを構築しました。グラフィックデータとテキストデータは質問に書き直されました。解答形式により、医療の視覚的知識が強化されました。
直接使用します:https://go.hyper.ai/ewHNg
MMedC 大規模多言語医療コーパス
MMedC は、上海交通大学人工知能学部のスマート医療チームによって 2024 年に構築された多言語医療コーパスで、英語、中国語、日本語、フランス語、ロシア語、スペイン語の主要 6 言語をカバーする約 255 億のトークンが含まれています。
研究チームはまた、多言語医療ベースモデル MMed-Llama 3 をオープンソース化しました。これは、複数のベンチマーク テストで良好なパフォーマンスを示し、既存のオープンソース モデルを大幅に上回り、医療垂直分野でのカスタマイズされた微調整に特に適しています。
直接使用します:https://go.hyper.ai/xpgdM
MedCalc-Bench 医療コンピューティング データ セット
MedCalc-Bench は、大規模言語モデル (LLM) の医療コンピューティング機能を評価するために特に使用されるデータセットで、2024 年に国立衛生研究所の国立医学図書館とバージニア大学を含む 9 機関によって共同リリースされる予定です。このデータ セットには、55 の異なるコンピューティング タスクをカバーする 10,055 のトレーニング インスタンスと 1,047 のテスト インスタンスが含まれています。
直接使用します:https://go.hyper.ai/XHitC
OmniMedVQA 大規模医療 VQA 評価データセット
OmniMedVQA は、医療分野に焦点を当てた大規模な Visual Question Answering (VQA) 評価データ セットです。このデータセットは、香港大学と上海人工知能研究所が 2024 年に共同で立ち上げたものです。これには、人体の 20 以上の異なる臓器や部分を含む 12 の異なるモダリティをカバーする 118,010 の異なる画像が含まれており、すべての画像は実際の医療シナリオに基づいて、医療マルチモーダル大規模モデルの開発の評価ベンチマークを提供することを目的としています。
直接使用します:https://go.hyper.ai/1tvEH
MedMNIST 医療画像データセット
MedMNIST は、2020 年 10 月 28 日に上海交通大学によってリリースされました。これは、合計 450,000 の 28*28 医療マルチモーダル画像データを含む 10 の医療公的データ セットのコレクションであり、さまざまなデータ モードをカバーし、関連する問題を解決するために利用できます。医療画像解析まで。
直接使用します:https://go.hyper.ai/aq7Lp
上記は、この号で HyperAI が推奨するデータ セットです。高品質のデータ セット リソースを見つけた場合は、メッセージを残すか、投稿してお知らせください。
さらに高品質のデータセットをダウンロードします。https://go.hyper.ai/jJTaU
参考文献:
https://mp.weixin.qq.com/s/vMWNQ-sIABocgScnrMW0GA









