Command Palette
Search for a command to run...
清華大学の研究チームは、20 以上の時空間データ セットと 1 億 3,000 万以上のサンプル ポイントを収集し、生成 AI に基づく 3 つの都市複雑システム モデリング手法を提案しました。

都市複雑システム研究の先駆者の一人として知られるマイケル・バティは、かつて著書の中で次のように述べています。「都市は本質的に複雑な適応システムであり、その構造と機能は常に進化しており、高度な非線形性と自己組織化特性を示します。」近代都市の継続的な発展に伴い、都市システムは日に日に複雑化しています。
この複雑さにより、従来のモデリング手法では対処が困難になっています。生成 AI テクノロジーの発展に伴い、生成モデリングは新たな技術手段として、都市システムを研究し理解するための重要なツールになりつつあります。複雑な都市システムの生成モデルは、都市構造の進化をシミュレートするだけでなく、革新的な都市計画ソリューションを生成し、スマートシティと持続可能な開発のための新しいアイデアを提供します。
近年、中国を中心に都市複合システムの生成モデルの研究が著しく進展し、多くの大学や研究機関で成果をあげている。
最近、HyperAI と HyperNeural が共同で開催した COSCon'24 AI for Science フォーラムで、清華大学電子工学部都市科学コンピューティング研究センターの博士研究員である丁静濤氏は、「AI主導の都市複雑システムモデリングと法則発見」と題して講演した。複雑な都市システムの時空間生成モデリング手法とチームの最新の研究の進捗について、参加者全員に詳しく説明しました。
HyperAI Super Neural は、丁静濤博士のこの詳細な共有を、当初の意図に違反することなく編集し、要約しました。以下は講演の書き起こしです。
複雑な都市システムの生成モデリングに焦点を当て、データ分布パターンを発見する
スマートシティとアーバンコンピューティングの分野における私たちのチームの研究は、複雑な都市システムのモデリングに焦点を当てています。複雑なシステムとしての都市は、生態系における自然の営みに似ており、人間はその中で生活し、多次元で都市システムと相互作用し、複雑な相互作用を形成します。例えば、都市建設の過程で、交通網、通信網、電力供給網などのさまざまなネットワークシステムが形成されてきました。物理レベルのネットワーク要素は人間生活の社会的要素と絡み合っており、都市システムの複雑さをさらに悪化させています。

これを受けて、私たちのチームは主に次の 3 つの問題に焦点を当てて研究を行っています。
(1) 都市国家の進化予測の問題、つまり、都市開発は本質的に空間と時間の動的な変化のプロセスであり、これは典型的な時空予測問題であるため、都市の将来の開発の方向とプロセスに注目します。
(2) 都市要素のシミュレーションと推定の問題、デジタル ツインやメタバースの概念と同様に、デジタル環境は実際のデータを通じて構築され、これに基づいて演繹が実行され、仮説的なシナリオにおける「もしも」の問題が解決されます。
(3) 都市ガバナンスの意思決定最適化問題、前述の都市進化の予測とシミュレーション演繹に基づいて、交通渋滞や自然災害などの特定の都市問題を解決するために都市ガバナンスの決定を最適化できます。
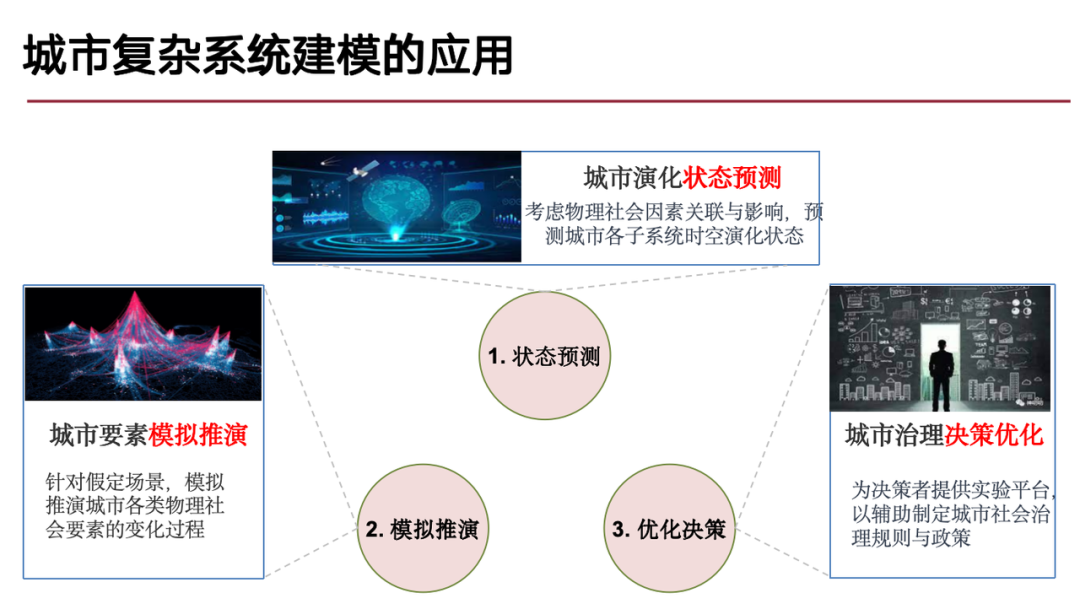
私たちのチームの現在の研究の焦点は、複雑な都市システムの生成モデリングです。生成モデルの核心は、データの背後にある確率分布を学習すること、つまり、観測データに基づいて確率分布をモデル化し、データ生成プロセスを捉えることです。モデルにこの機能があれば、上記の 3 種類の問題を効果的に解決できます。
モデリングの問題を解決するための生成 AI 手法の導入
現在の生成型 AI の急速な発展は、主に 2 つの側面から反映されています。1 つは大規模言語モデルに代表される言語生成技術の発展、もう 1 つは拡散モデルに代表されるビジュアルコンテンツ生成技術の進歩です。複雑な都市システムのモデリングには、生成AI手法が適しているかどうかが研究の鍵となっています。
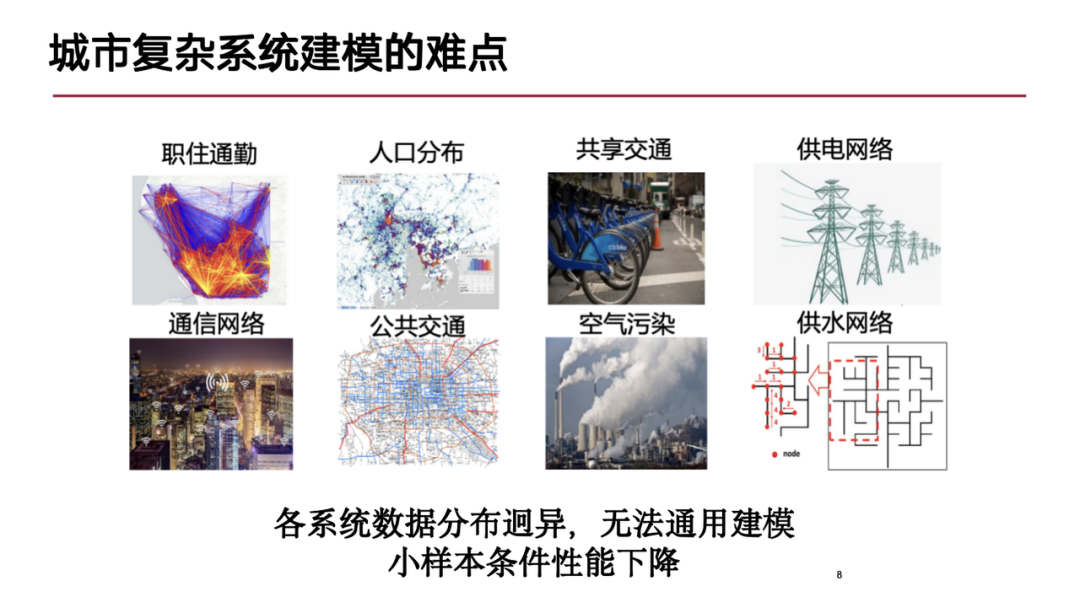
都市の複雑なシステムでは、モデリングの難しさは主に次の側面に反映されます。麺:まず第一に、都市の複雑なシステムは重要な時空間特性を持っており、そのデータモダリティは非常に豊富であり、都市内を移動する人々の軌跡データなど、このデータ形式は自然界のシーケンスデータに似ています。その他、暴走事故を防ぐための時空間グリッドデータや都市の地形構造(道路や速度コイルが形成するグラフ構造など)などもあります。これらの異なるモダリティからの時空間データの混合により、モデリングの課題が生じます。

第二に、都市複合システムの観点から見ると、都市は複数のサブシステムから構成される巨大なシステムです。これらのサブシステム内には複雑な対話関係があり、異なるサブシステム (電力システムや通信ネットワーク システムなど) 間には特定の結合が存在します。これらのサブシステムの相互依存性と複雑な相互作用により、モデリングに対する要求が高くなります。

最後に、都市システムの内部は動的なプロセスであり、さまざまなサブシステムがさまざまなデータを収集する可能性があり、これらのデータはさまざまな形式、モード、分布を持っているため、これも現時点では克服できない問題です。研究段階。
本日は、上記の課題を踏まえ、以下の3つの側面から研究の進捗状況をご紹介します。一つ目は人の流れのシミュレーションで、私たちは、都市における人々の動きをより正確に推定するために、物理的知識に基づいた拡散モデルを提案します。2 つ目は複雑なシステムの復元力の予測、最後は一般的な時空間予測モデルです。
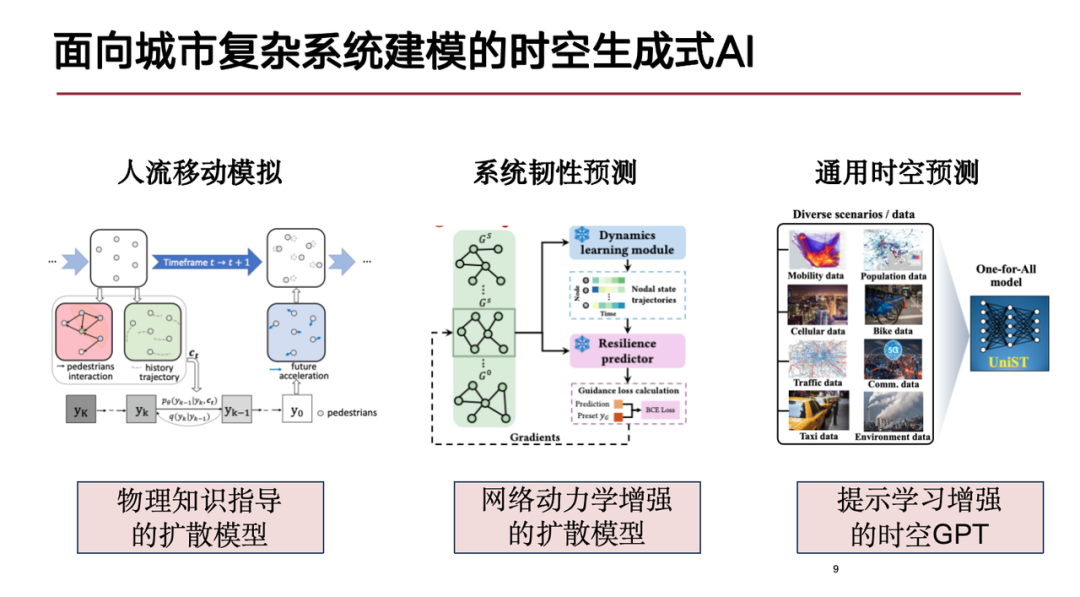
人流シミュレーション ~物理知識に導かれた普及モデル~
歩行者移動シミュレーションは、空間内で多数の歩行者の動的な動きと相互作用のプロセスを再現することを目的としています。その中心的な問題は、歩行者または個人の開始点と終了点が与えられると、その移動中の軌跡を生成することです。このシミュレーションは、ゲーム内の仮想キャラクター (NPC) の経路計画や現実の建物設計の実現可能性分析など、多くのアプリケーション シナリオで非常に価値があります。特定のシナリオで建築設計のパフォーマンスをテストするには、通常、大規模な歩行者の流れのシミュレーションを実行する必要があります。

ただし、人流シミュレーションの主な課題は、シミュレーションの対象が明確な物理法則を持つ分子システムではなく、独立した意思決定を行う能力を持つ個人、つまり人間であることです。人間の意思決定メカニズムは複雑で変化しやすいものです。一方で、個人の好みは周囲の環境の影響を受け、意思決定の継続的な調整につながりますが、他方では、人間の行動は本質的に不確実です。たとえば、障害に直面したとき、人によって対処方法は異なります(左に進むことを選択する人もいれば、右に進むことを選択する人もいます)。この不確実性を決定論的な公式で説明するのは困難です。
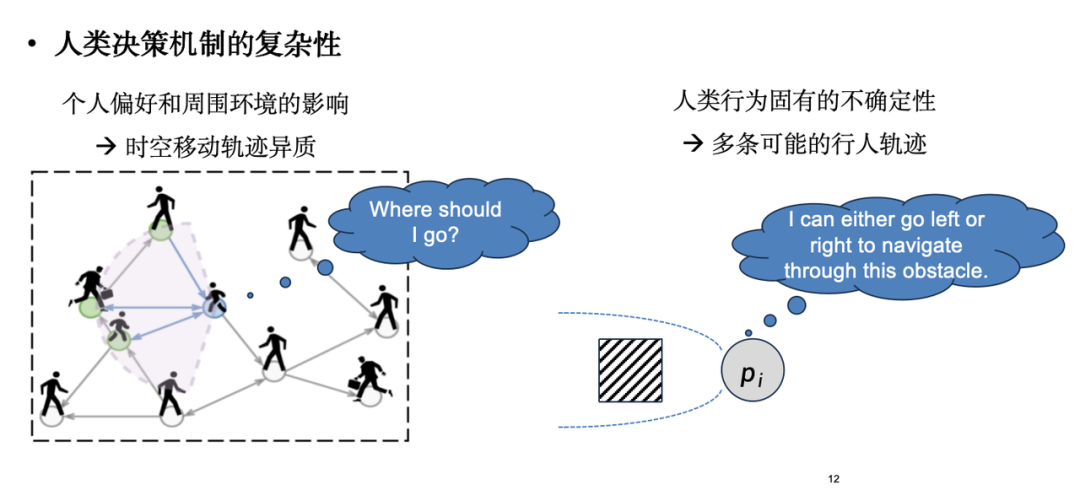
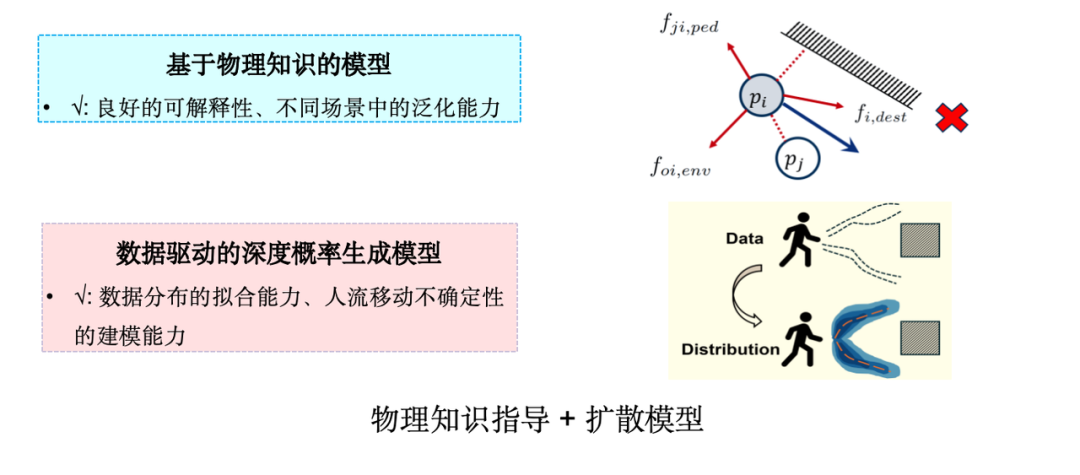
実用化において最も広く使われている人流シミュレーションモデルは「ソーシャルフォースモデル」です。これはニュートン力学の考え方に由来し、ABM(Agent-Based Modeling)に基づく古典的な手法の一つです。社会力モデルでは、以下の図に示すように、人間の移動は、目的地に引き寄せられるだけでなく、障害物や周囲の歩行者によって反発されることもあります。しかし、詳しく見てみると、社会的力モデルでは実際のデータの微妙な特徴を捉えるには不十分であることがわかります。

したがって、私たちは生成 AI テクノロジーをどのように組み合わせるかを検討し、物理的知識を拡散モデルに注入する。拡散モデルを選択する理由は、人間の意思決定メカニズムは本質的に不確実であり、拡散モデルは高次元のデータ分布モデリングで優れた性能を発揮し、そのような不確実な問題のシミュレーションに適しているためです。
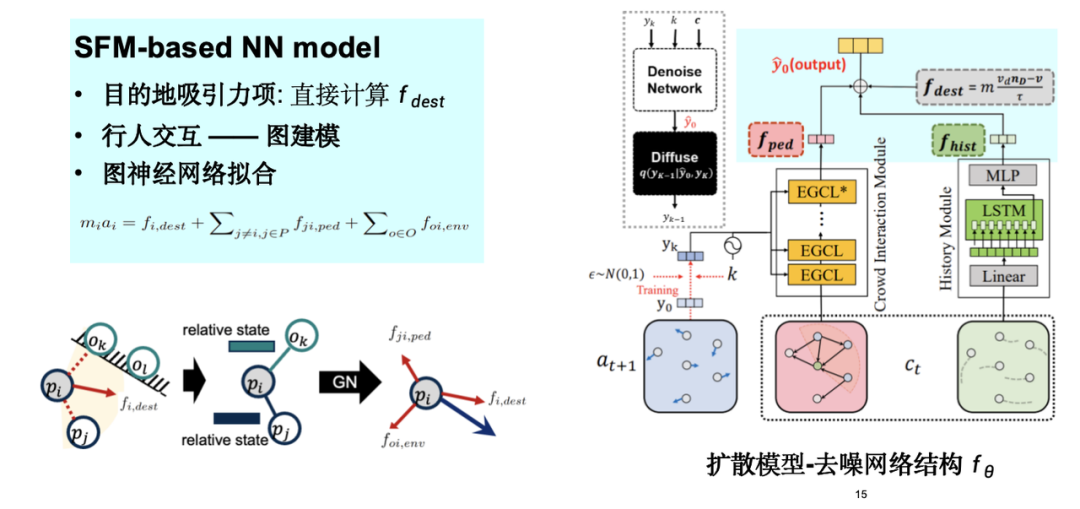
私たちは社会力モデルに基づいてグラフニューラルネットワークを設計し、社会力の引力項と斥力項をモデルに組み込み、人流運動シミュレーションモデルSPDiffを提案しました。
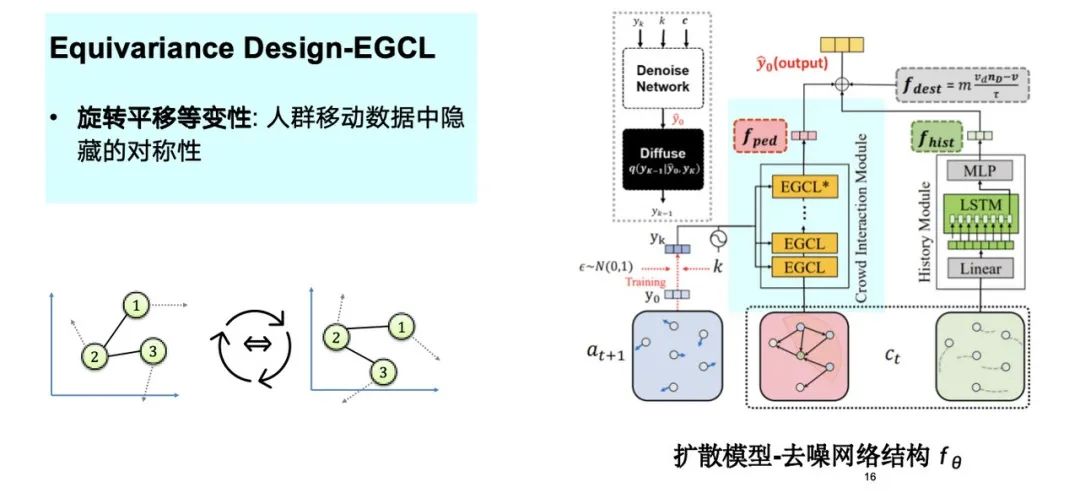
以下の図に示すように、群集の移動データの隠れた対称性 (回転や平行移動など) を考慮し、これらをモデル設計プロセスに統合しました。この誘導バイアスの注入は、シミュレーション プロセス全体の最適化に役立ちます。
モデルのパフォーマンスを評価するために、実際の歩行者の動きのデータセットを選択しました。データソースには、駅前広場や街路における歩行者の動きの監視データが含まれます。
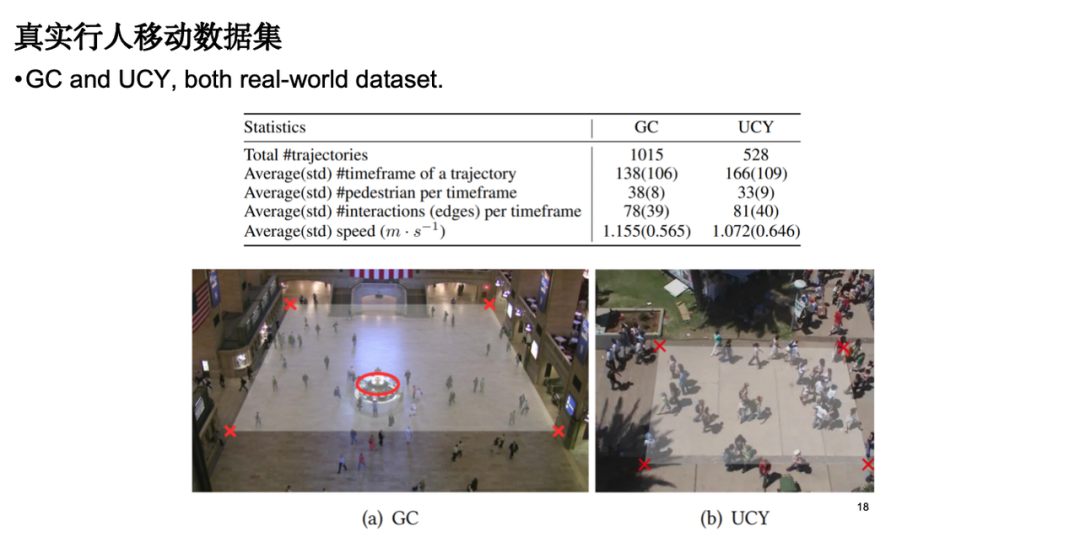
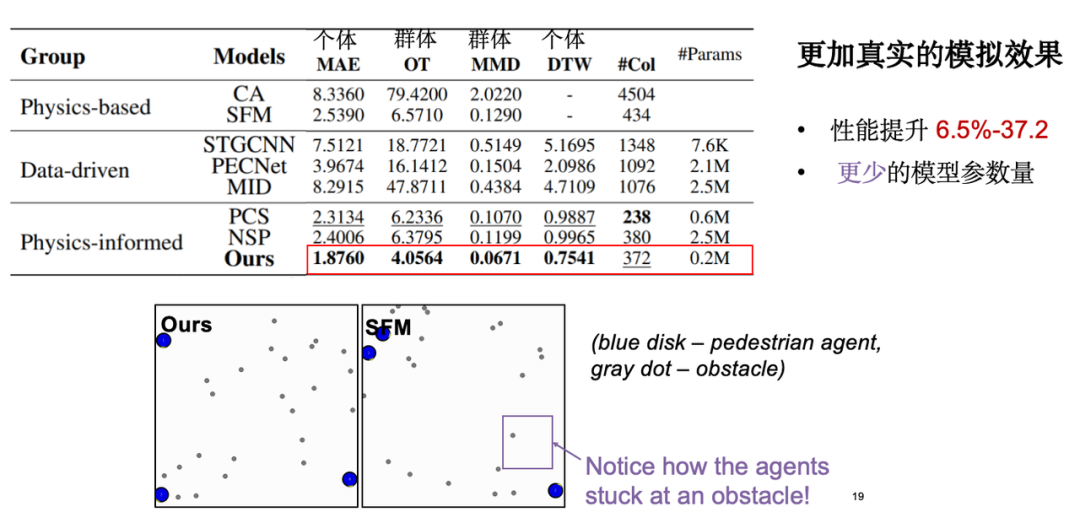
モデルの評価では、主に次の種類の指標に焦点を当てます。1 つ目は個々の移動誤差、つまりシミュレーションで生成された軌道と実際の観測軌道の間の絶対誤差です。2 つ目はグループ分布指数で、シミュレーションで生成された軌道がそれに近いことが期待されることを意味します。ディストリビューションレベルの実際のデータ。さらに、視覚分析も実施しました。その結果、古典的な社会力モデルと比較して、私たちのモデルは障害物回避効果においてより合理的に機能することがわかりました。物理知識を導入すると、モデルのパラメーターの数が大幅に削減され、モデルの効率が最適化されることは注目に値します。
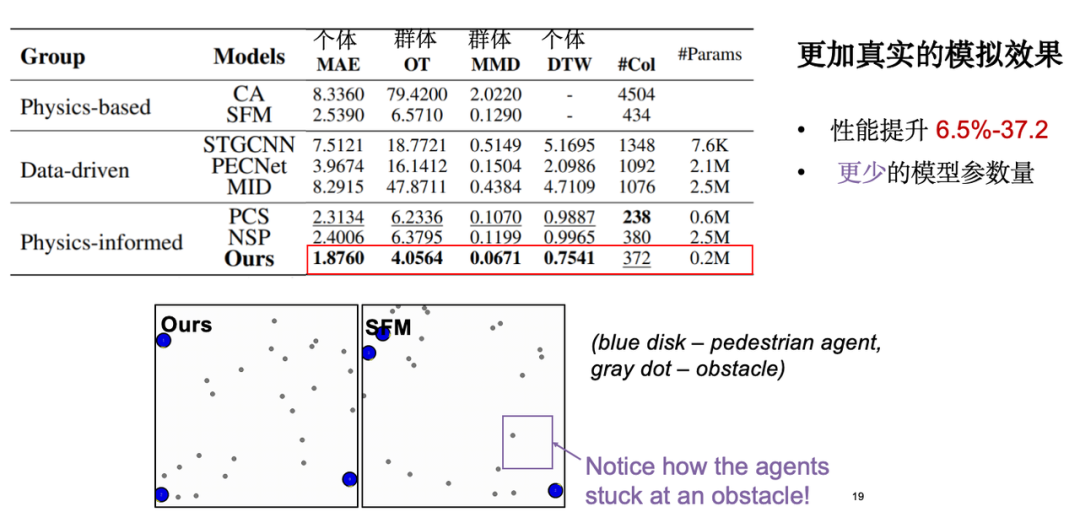
物理的知識の導入をさらに検討したところ、小規模サンプルの学習において等分散性がモデルに利点をもたらすことがわかりました。前述したように、回転と平行移動後の移動軌跡は基本的に対称になります。したがって、モデルは効果的な学習を完了するために少数のデータ サンプルのみを必要とします。実験によると、トレーニング データの量が 5% に減っても、モデルの効果は依然として完全なデータ セットのパフォーマンスに近いことがわかります。
「群集シミュレーションのための社会物理学に基づく拡散モデル」および「現実的な群衆シミュレーションのための衝突回避行動の理解とモデリング」と題された関連研究は、それぞれ AAAI 2024 と CIKM 2023 で発表され、コードとデータはオープンソース化されました。
用紙のアドレス:https://arxiv.org/abs/2402.06680
オープンソース プロジェクトのアドレス:https://github.com/tsinghua-fib-lab/SPDiff
用紙のアドレス:https://dl.acm.org/doi/10.1145/3583780.3615098
オープンソース プロジェクトのアドレス:https://github.com/tsinghua-fib-lab/TECRL
システム復元力の予測 - ネットワークダイナミクスによって強化された拡散モデル
復元力とは、システムが内部障害や外部障害を受けたときに基本的なシステム機能を維持する能力を指します。たとえば、生態系の場合、レジリエンスとは、環境変化の影響下で生物学的多様性を維持する能力を指します。人間の社会システムにおいては、サプライチェーンネットワークなどの多くのエンジニアリングシステムが、特殊な状況下でも生産者と消費者の間の正常な生産・販売関係を確保し、それによって経済の正常な運営を維持できるような回復力を備えていることが望まれます。

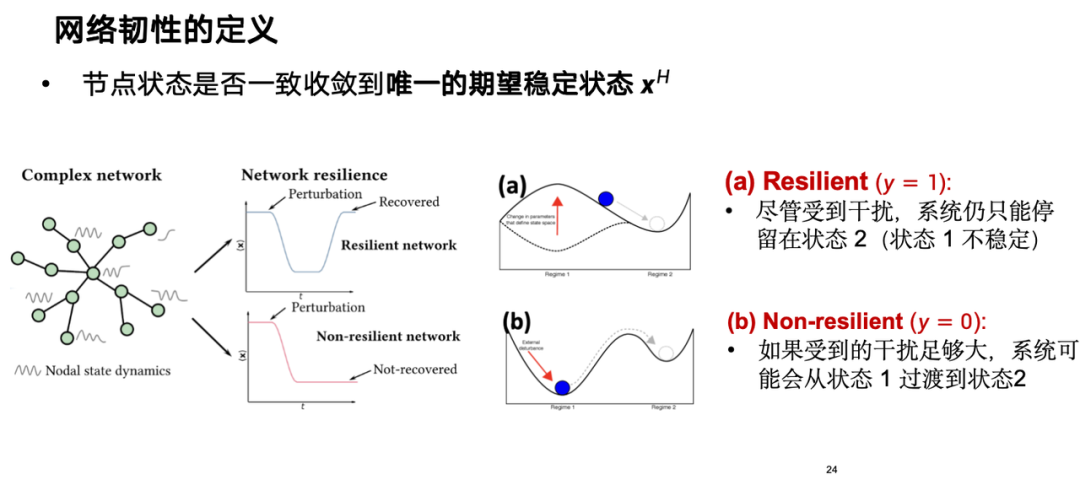
理論的な観点から見ると、サイバー レジリエンスにはいくつかの古典的な定義があります。回復力は、x で表されるノード状態とみなすことができ、ノードに外乱が加えられた後、システムが期待される唯一の安定状態に収束できるかどうかを反映します。システムに障害が発生しても、回復力があれば一定時間以内に期待した状態に回復できますが、回復力がなければ回復は困難です。以下の図に示すように、復元力のあるシステムは外乱後に安定した状態に戻ることができますが、復元力のないシステムは回復できない可能性があります。
2017 年には、Nature の論文で、基本的に n 次元の高次元システムを研究する理論的モデリング手法が提案されました。このようなシステム内のノードの数は、数万、さらには数百万に達する場合もあります。理論的には、この方法は、次元削減を通じて高次元システムを 1 次元に単純化し、システムの復元力を表現します。
ただし、この理論上のツールには実際のシステムでは制限があり、学位の関連性が低いシステムにのみ適しています。ただし、実際のシステムには等同類効果が存在することがよくあります。つまり、エッジで接続された 2 つのノードの次数の値が高度に相関している可能性があるため、このツールは実際のシステムの復元力を評価する際にまだいくつかの問題を抱えています。
用紙のアドレス:https://www.nature.com/articles/nature16948
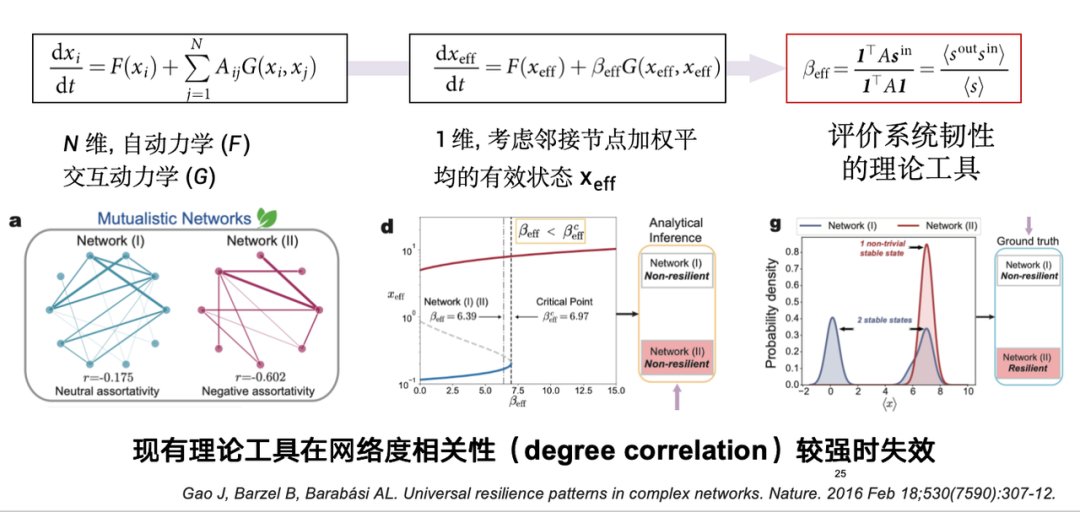
これに基づいて、私たちのチームはデータ駆動型ネットワークシステムの復元力モデリング手法を提案しました。前述したように、復元力はノード状態の進化とネットワーク トポロジの複合的な影響によって影響を受けます。データ駆動型または機械学習の観点からのモデリングを通じて、問題を 2 つの次元に分割します。一方で、ノード状態の動的変化プロセスは、状態進化の軌跡によって特徴付けられます。ネットワーク トポロジも考慮する必要があります。これらの役割は複雑なシステムの回復力を生み出すため、それに応じてデータ駆動型の回復力予測モデルを設計します。
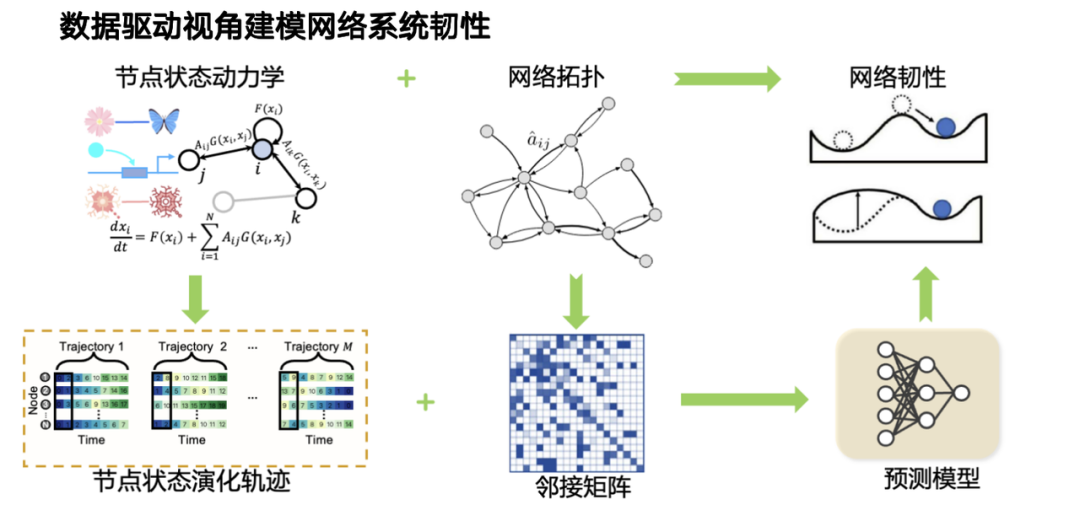
モデル アーキテクチャの観点からは、グラフ ニューラル ネットワークと Transformer を組み合わせた構造を設計しました。動的進化の部分では、Transformer を使用してタイミング関係をモデル化し、複雑なトポロジー関係については、グラフ ニューラル ネットワークを導入してシステム間の高次の相互作用をモデル化します。この 2 つが連携して、システムの回復力に関する観察結果が形成されます。
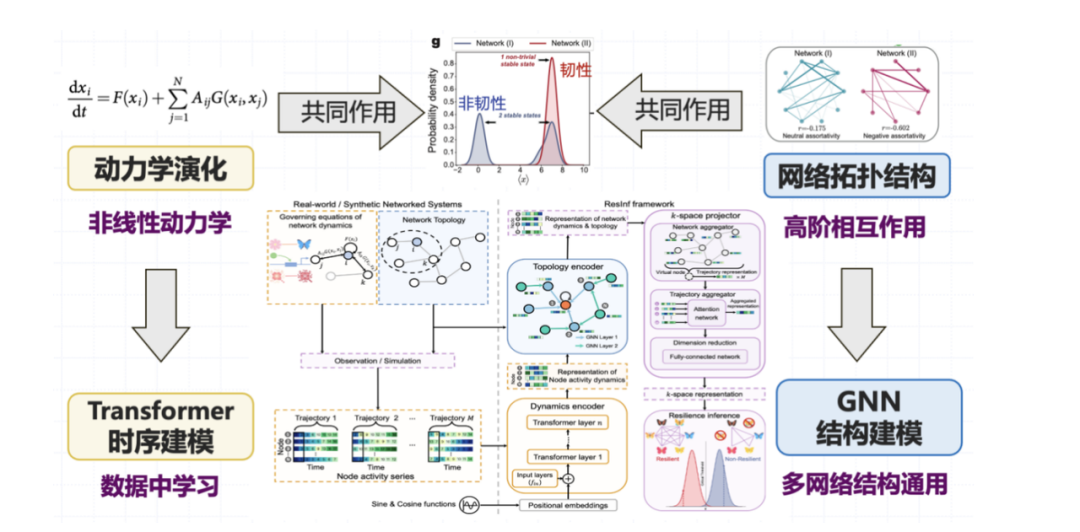
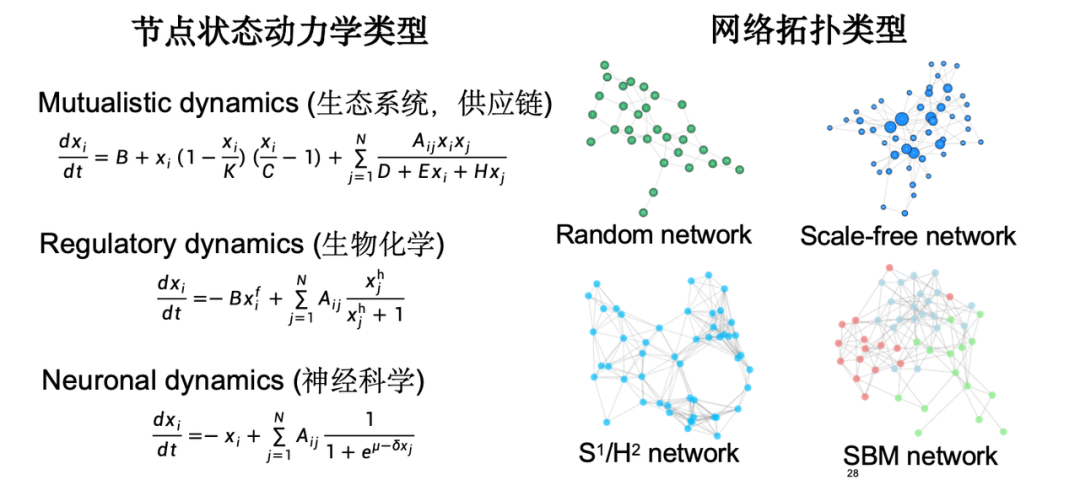
実験では、生態系のサプライチェーン、生化学における遺伝子制御のダイナミクス、神経科学における神経信号伝達のダイナミクスなど、さまざまなノード状態ダイナミクスのタイプをトポロジとして考慮しましたが、古典的なネットワーク トポロジ タイプを選択しました。
実験結果は、私たちのモデルが予測精度を大幅に向上させ、高い F1 スコアを持ち、一定の解釈可能性を持ち、決定平面の次元削減視覚化を達成することを示しています。
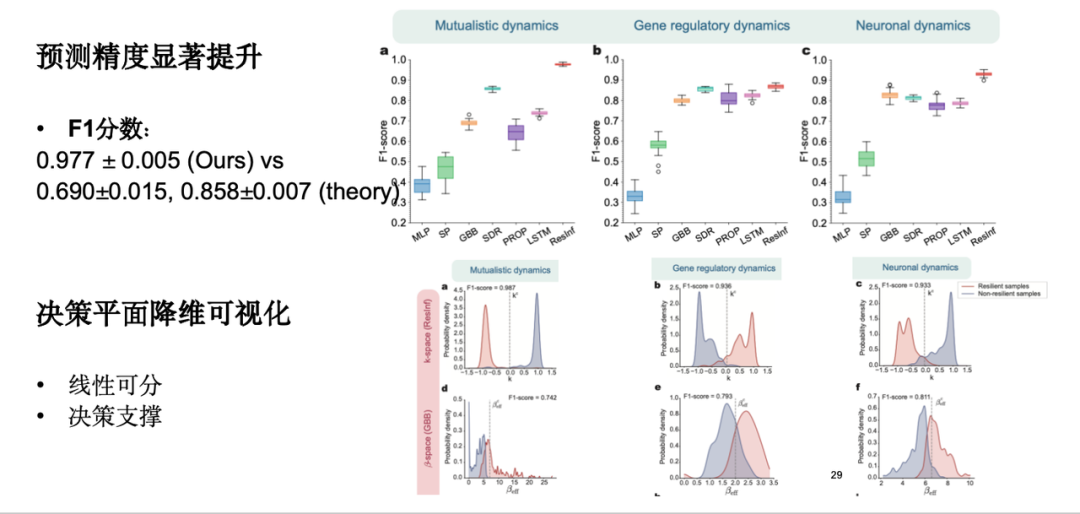
しかし、実際のアプリケーションでは、ほとんどのシステムの復元力が不明であり、復元力があるかどうかを判断することが困難であるため、復元力マーカーのデータが不足し、モデルの予測に偏りが生じることがわかりました。この目的を達成するために、サンプル レベルからモデルを強化して、サンプルが小さい状況でより堅牢になるようにします。
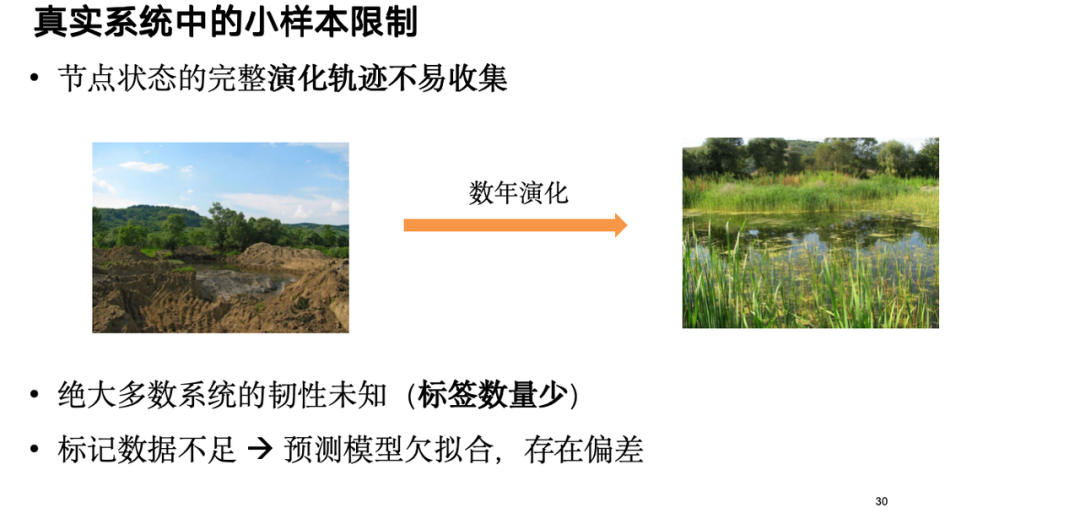
具体的な戦略は、拡散モデルに基づいて復元力のあるシステムと復元力のないシステムの観察サンプルを生成し、予測モデルを強化することです。これらのサンプルは、ノード トポロジとその状態の進化の軌跡をカバーしています。まず、データ強化が実行され、強化されたサンプルによって回復力予測モジュールがより適切にトレーニングされ、予測結果によって逆にデータ強化モジュールがより価値のあるサンプルを生成し、正のフィードバック ループが形成されます。
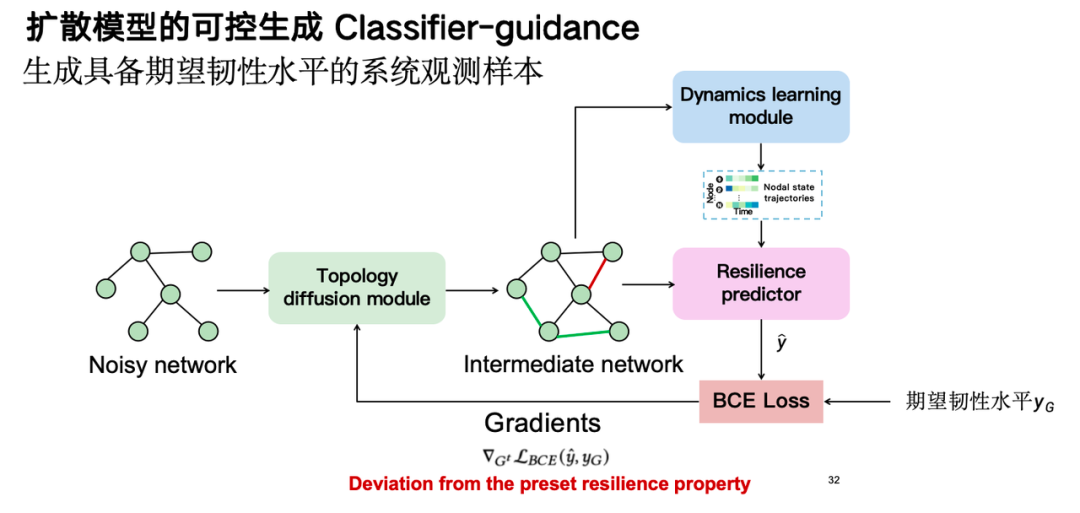
拡散モデルの制御可能な生成機能、つまり分類子ガイダンス技術を通じて、望ましいレベルの回復力を持つサンプルを生成し、それによってデータの強化を実現します。
小規模サンプルのテスト結果は、わずか 20 サンプルを使用して拡散モデルを強化した後、モデルの予測精度が 87% に達することができることを示しています。データ拡張を行わない場合、モデルの予測精度はわずか 62% です。状態進化軌跡のより短い観測期間でも同様の予測精度を達成できることは言及する価値があり、これは実際の観測では長時間観測できないシステムにとって非常に重要です。

「複雑なネットワークシステムのための深層学習レジリエンス推論」と「TDNetGen: トポロジーとダイナミクスの生成拡張による複雑なネットワークレジリエンス予測の強化」というタイトルの関連研究は、それぞれ Nature Communications と KDD 2024 で発表され、コードとデータはオープンソースでした。
用紙のアドレス:
https://www.nature.com/articles/s41467-024-53303-4
オープンソース プロジェクトのアドレス:
https://github.com/tsinghua-fib-lab/ResInf
用紙のアドレス:
https://arxiv.org/abs/2408.09825
オープンソース プロジェクトのアドレス:
https://github.com/tsinghua-fib-lab/TDNetGen
普遍的な時空間予測 - 学習のヒント 強化された時空間 GPT
2017 年以降、時空間予測問題はディープラーニングの分野で徐々に注目を集めています。現在の研究手法は主に 2 つのカテゴリに分類されます。1 つは、特定のデータ型またはソースの時空間特性に基づいて、対応する深層学習モデルを設計するもので、もう 1 つは、複雑なシステムやソースの観点からリザーブプール計算などの動的システム手法を使用するものです。応用数学。これら 2 種類のメソッドに共通するのは、どちらも単一のサブシステムをモデル化することです。
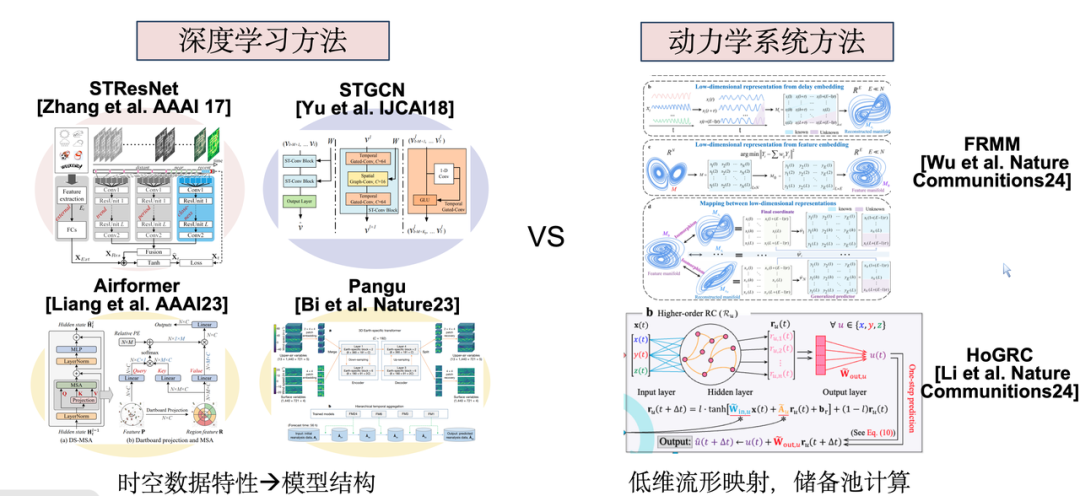
ただし、都市システムの場合、実際のサブシステム間の相関性が高いため、1 + 1 > 2 の相乗効果を達成するために共同モデリングを実現することが期待されます。これは私たちの研究活動の中核目標でもあります。
この枠組みの中で、私たちのアイデアは、さまざまなタイプの時空間データがさまざまな組織形態と分布を持っているにもかかわらず、本質的にはすべて人間の生産と都市での生活から来ており、さまざまな次元で具現化されたいくつかの根底にある普遍的なメカニズムであるという実現可能性に基づいています。したがって、適切な方法が見つかれば、これらの異種データを融合して 1 + 1 > 2 の相乗効果を達成することができます。
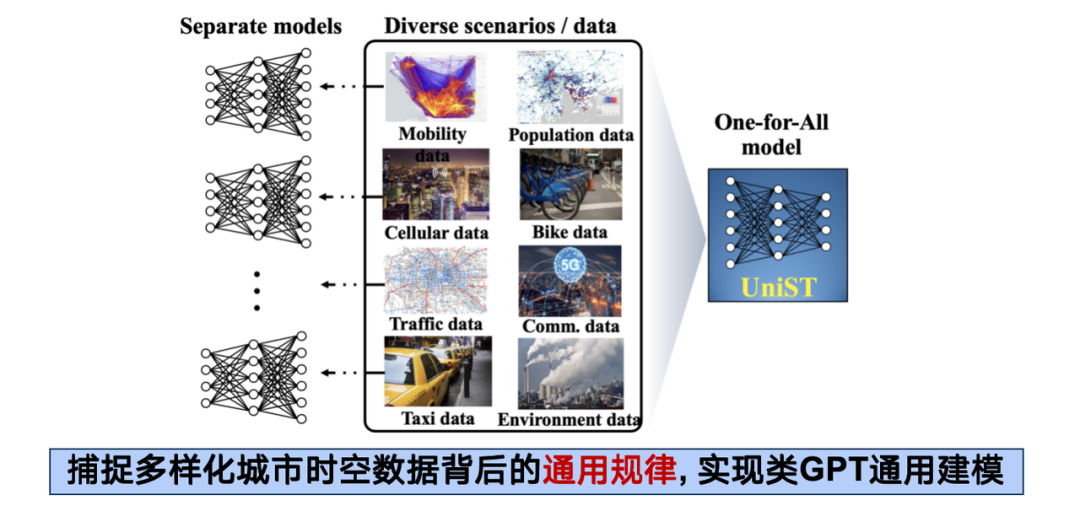
実際の運用では、交通、携帯電話ネットワーク、大気汚染などの 5 つのサブシステムをカバーし、国内外 14 都市をカバーする 1 億 3,000 万以上のサンプル ポイントを持つ 20 以上の時空間データ セットを収集しました。
モデル設計に関しては、Transformer アーキテクチャを継続し、さまざまな形式の時空間データを高次元テンソルにモデル化し、ViT (Vision Transformer) と同様の方法で処理します。最後に、普遍的な時空間予測モデル UniST が形成されました。
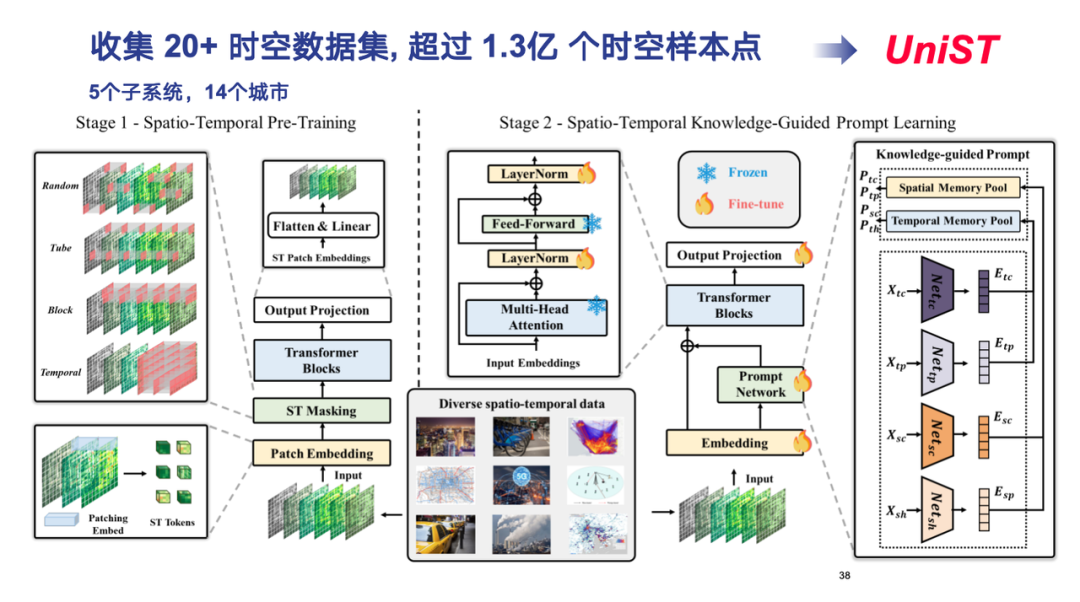
モデルトレーニングの最初の段階では、私たちはさまざまな時空間データをトークン化し、高次元テンソルを小さな正方形に分解し、各正方形がトークンに対応し、さまざまなマスク戦略を使用してさまざまな時空間相関特性をキャプチャします。
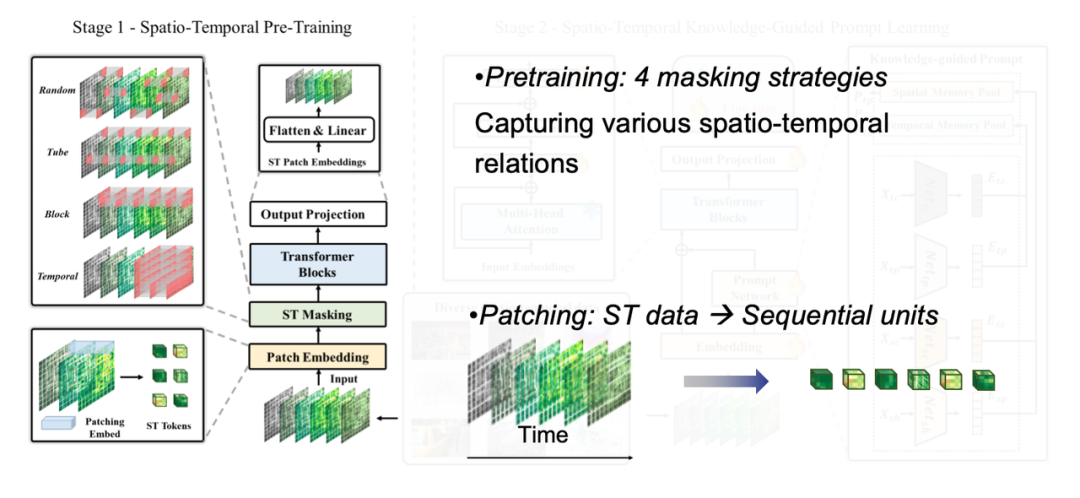
モデルトレーニングの第 2 段階では、私たちは、さまざまな形式の時空間データの背後にある普遍的な法則を探索する必要があります。ここでの「知識」とは、時間的近接性、周期性、傾向、空間的近接性、階層性など、時空間データに一般的に見られる古典的な進化パターンを指します。これらの時空間領域の知識を抽出し、対応するパターンを定義することで、実際のデータの次元をいくつかのパターン空間に削減し、大規模なデータに対して事前トレーニングを実行します。このようにして、新しいデータを処理するときに、モデルは RAG のような方法を使用して、対応するパターンと迅速に照合し、小さなサンプルまたはゼロ サンプルでも正確な予測を達成できます。

モデルの有効性を評価するとき、私たちは主に 2 つのタスクに焦点を当てます。1 つは長期予測機能と短期予測機能で、2 番目は最も重要なゼロショット機能です。つまり、モデルは、影響を受けずに直接処理できます。特定のタスクまたはタスクのデータ。たとえば、モデルが北京のデータセットに基づいてトレーニングされた場合、トレーニングに含まれていない上海のデータについても、モデルは上海の時空間シーケンスに基づいて正確な予測を達成できます。
下の図に示すように、赤い点線はゼロサンプル条件での私たちの方法の予測効果を表します。一番左の赤い長方形は、1%/5% サンプル条件での私たちの方法の予測結果を示しています。ゼロサンプル移行の点で、私たちの方法は 1%/5% サンプルを使用したベースライン方法よりも大幅に優れていることがわかります。
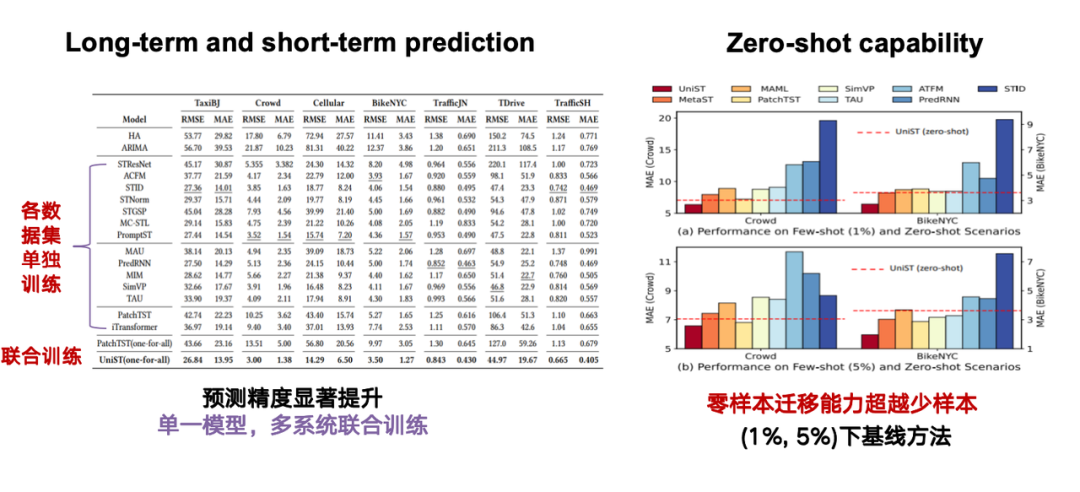
なぜこのような影響が起こるのでしょうか?図の北京と上海のデータの類似性を比較すると、即時計算後、北京長安街と上海静安区のデータは非常に類似していることがわかります。この高い類似性は、モデルが上海のデータでトレーニングしなくても、北京のデータでのトレーニングに基づいて同様の予測パターンを形成できることを説明しています。

また、スケーリング則の観点から時空間データのパフォーマンス、つまりデータ量の増加によりモデルの機能が大幅に向上するかどうかについても調査しました。ただし、既存のデータ量とデータ型の制限により、明らかなスケーリング効果はまだ観察されていないため、データ型をさらに強化する必要があります。

「UniST: 都市の時空間予測のための迅速な強化型ユニバーサルモデル」と題された関連研究が KDD 2024 に選ばれました。
用紙のアドレス:
https://arxiv.org/abs/2402.11838
オープンソース プロジェクトのアドレス:
https://github.com/tsinghua-fib-lab/UniST
物理的な知識に基づいて、複雑な都市システムをモデル化するための新しいアイデアを提供します。
最後に、都市複合システムモデリングの将来の方向性と、私のチーム(清華大学電子工学部都市科学コンピューティング研究センター)の最新の進歩についてお話したいと思います。
私たちは、物理的な知識をさらに組み合わせることで、モデルの堅牢性と一般化能力を向上させることができると考えています。多くのメカニズムの探索が不十分な都市のシステムの場合、シンボリック回帰やネットワークダイナミクス推論などの手法を包括的に使用して、実際のデータからシステムの進化規則を記述するシンボリック式の抽出を試みることができます。

関連する研究は、「グラフ構造の物理メカニズムのための記号モデルの学習」というタイトルで ICLR 2023 に掲載されました。
用紙のアドレス:https://openreview.net/pdf?id=f2wN4v_2__W
大規模複雑ネットワークの分野では、繰り込み群などの統計物理学における理論ベースの次元削減ツールがすでに存在しており、これを実際の大規模ネットワーク予測に適用して、ネットワークの低次元の「骨格」を特定するのに役立ちます。進化のダイナミクスと長期的な発展の予測を実現します。これは私たちの最近の研究の焦点でもあります。

関連する研究は「双曲空間におけるスケルトンの識別による複雑なネットワークの長期ダイナミクスの予測」と題され、KDD 2024 で発表されました。
用紙のアドレス:https://arxiv.org/abs/2408.09845
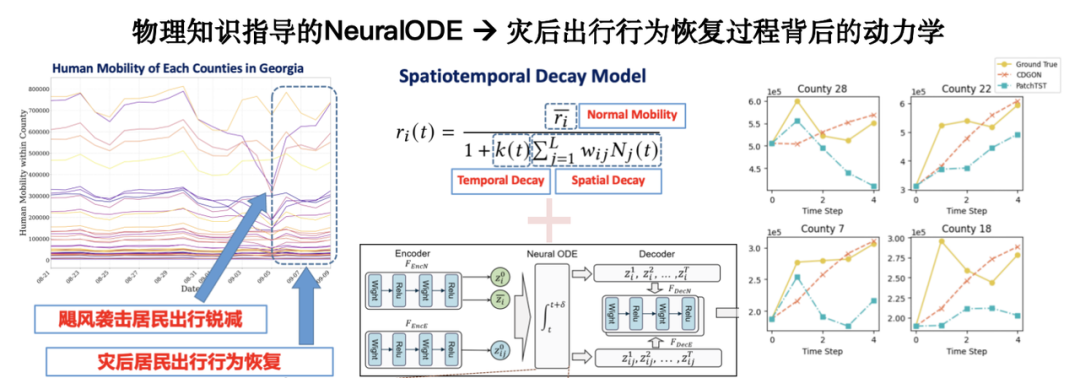
さらに、小規模サンプル学習をサポートするために物理的知識を導入すると、モデルの汎化能力が大幅に向上します。災害後の緊急事態を例にとると、このシナリオに関する歴史的データは不足していますが、一部の学者はメカニズムの観点から災害後の人間の行動の動的な方程式を構築しています。これらの方程式を実際のデータ モデルと組み合わせることで、限られたサンプルでより堅牢な予測が可能になります。
関連する研究は、「災害後のモビリティ回復のための物理学に基づいたニューラル ODE」というタイトルで KDD 2024 に発表されました。
用紙のアドレス:https://dl.acm.org/doi/10.1145/3637528.3672027
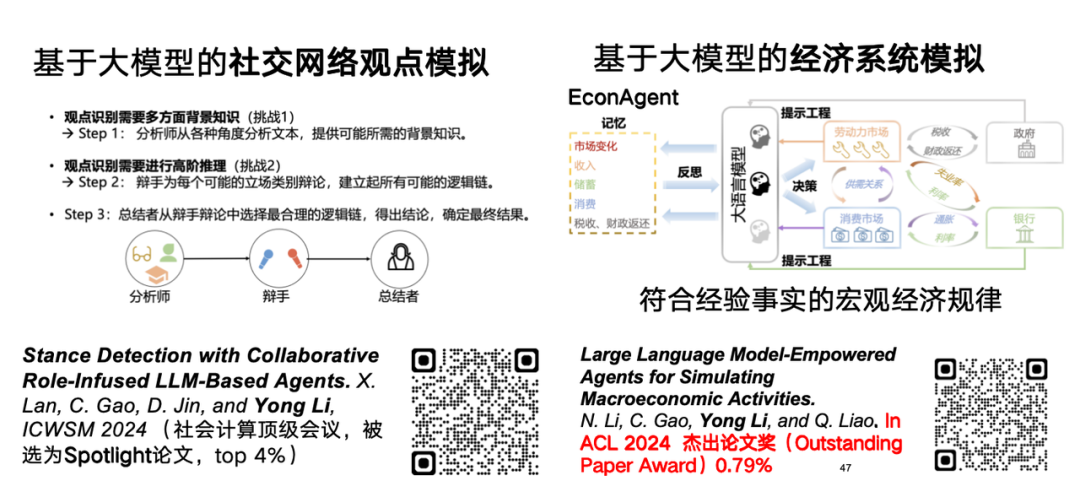
また、大規模な言語モデルには、時空間データの分野での推論とシミュレーションの可能性があると考えています。たとえば、大規模な言語モデルを使用して、ネットワーク概念や経済システムをシミュレートできます。大規模言語モデル シミュレーション ネットワークの観点に関する研究については、「協調的な役割を注入した LLM ベースのエージェントによるスタンス検出」というタイトルの関連論文が ICWSM 2024 で発表されました。
用紙のアドレス:https://arxiv.org/abs/2310.10467
経済システムの大規模言語モデルのシミュレーションの研究では、大規模言語モデル エージェントを使用して、経験則に準拠したマクロ経済モデルを効果的にシミュレートします。関連する研究は「EconAgent: マクロ経済活動をシミュレートするための大規模言語モデルを強化したエージェント」と題され、ACL 2024 優秀論文賞を受賞しました。
用紙のアドレス:https://arxiv.org/abs/2310.10436
大規模な言語モデルは人間が生成した大量の言語データに基づいてトレーニングされ、人間のような推論と意思決定の機能を備えているため、私たちのチームは人間の行動の生成またはシミュレーションへの応用を模索しています。生成モデルに基づく従来の方法と比較して、大規模なモデルの事前トレーニング知識の助けを借りて、わずか 200 個のサンプルを使用して 100,000 個のトレーニング サンプルと同様の効果を得ることができ、特定のシナリオで迅速な一般化を達成できることがわかりました。
関連研究「計画された行動の連鎖ワークフローが LLM における少数ショットのモビリティ生成を引き出す」は、プレプリント Web サイト arXiv にアップロードされました。
用紙のアドレス:https://arxiv.org/abs/2402.09836
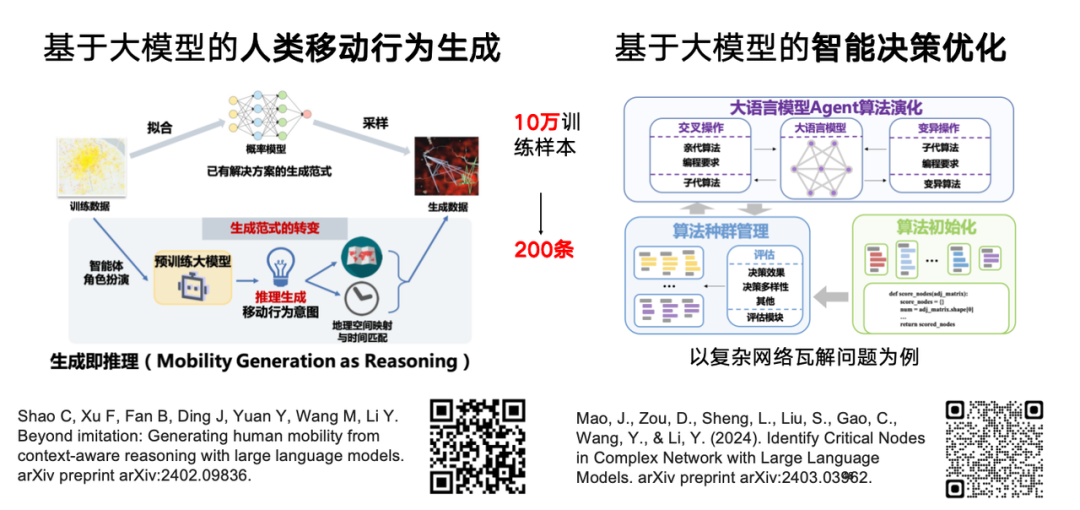
私たちのチームは、大規模な言語モデルをさらにインテリジェントな意思決定の最適化に使用できるかどうかも調査しています。関連研究「大規模言語モデルを使用した複雑なネットワーク内の重要なノードの識別」は、プレプリント Web サイト arXiv にアップロードされました。
用紙のアドレス:https://arxiv.org/abs/2403.03962
FIB LABについて
今回のゲストは清華大学電子工学部都市科学コンピューティング研究センター(FIB LAB)の丁静濤博士です。この研究センターは、都市科学とコンピューティング研究の方向性に焦点を当てており、都市科学を基礎的な研究課題とし、複雑系や計算社会学などの理論に基づいて研究を行い、新世代の「認知人工知能」とデータを組み合わせます。科学と機械学習をコアテクノロジーとして、都市の双子、都市ガバナンス、ワイヤレスネットワークツイン、および国家の主要なニーズに直面しているその他のアプリケーション分野にサービスを提供します。現在、チームには6人の教師と60人以上の生徒がいます。

このチームは、Nature のサブジャーナルなどの一流の国際ジャーナルや、KDD、NeurIPS、WWW、UbiComp などのトップの国際会議で 150 以上の学術論文を発表しています (サブジャーナルに 7 件の論文、CCF カテゴリ A に 100 件以上の論文)。論文は 25,000 回以上引用され、国際会議最優秀論文賞/ノミネート賞を 7 回受賞しています。同チームは科学技術省の主要な研究開発計画や中国国家自然科学財団など15以上のプロジェクトを主催または参加しており、関連する成果は国家科学技術進歩賞の二等賞を受賞した。
研究センターは常に産学連携を堅持しており、近年ではファーウェイ、テンセント、アリババ、マイクロソフト・リサーチ・アジア、美団、快手、オートナビ、センスタイム、トヨタ、モバイル通信事業者と良好な協力関係を築いている。企業協力やインターンシップの機会も豊富です。
研究室ホームページ:https://fi.ee.tsinghua.edu.cn/
個人ホームページ:https://fi.ee.tsinghua.edu.cn/~dingjingtao/









